首先我想說(shuō)下為什么會(huì)去學(xué)習(xí)cs224d蛛碌,原先我一直是做工程的瞻颂,做了大概3年,產(chǎn)品做了好多粹舵,但是大多不幸夭折了册烈,上線沒(méi)多久就下線戈泼,最后實(shí)在是經(jīng)受不住心靈的折磨,轉(zhuǎn)行想做大數(shù)據(jù)赏僧,機(jī)器學(xué)習(xí)的大猛,前不久自己學(xué)習(xí)完了Udacity的深度學(xué)習(xí),課程挺好次哈,但是在實(shí)際工作中胎署,發(fā)現(xiàn)課程中的數(shù)據(jù)都是給你準(zhǔn)備好的,實(shí)踐中哪來(lái)這么多好的數(shù)據(jù)窑滞,只能自己去通過(guò)各種手段搞數(shù)據(jù)琼牧,苦不堪言。在找數(shù)據(jù)的過(guò)程中哀卫,發(fā)現(xiàn)做多的數(shù)據(jù)還是文本數(shù)據(jù)巨坊,不懂個(gè)nlp怎么處理呢,于是就來(lái)學(xué)習(xí)cs224d這門(mén)課程此改,希望在學(xué)習(xí)過(guò)程中能快速將課程所學(xué)應(yīng)用到工作中趾撵,fighting!
以下文字都是從一個(gè)初學(xué)者角度來(lái)寫(xiě)的共啃,如有不嚴(yán)肅不正確的占调,請(qǐng)嚴(yán)肅指出。
語(yǔ)言模型
剛接觸nlp的時(shí)候移剪,經(jīng)尘可海看到有個(gè)詞叫 language model,于是先回答下什么語(yǔ)言模型纵苛?語(yǔ)言模型簡(jiǎn)單點(diǎn)說(shuō)就是評(píng)價(jià)一句話是不是正常人說(shuō)出來(lái)的剿涮,然后如果用一個(gè)數(shù)學(xué)公式來(lái)描述就是:
舉一個(gè)具體例子來(lái)說(shuō)明上面公式的含義:
我喜歡自然語(yǔ)言處理言津,這句話分詞后是:"我/喜歡/自然/語(yǔ)言/處理",于是上面的公式就變?yōu)椋?/p>
P(我取试,喜歡悬槽,自然,語(yǔ)言瞬浓,處理)=p(我)p(喜歡 | 我)p(自然 | 我, 喜歡)p(語(yǔ)言 | 我初婆,喜歡,自然)p(處理 | 我瑟蜈,喜歡烟逊,自然,語(yǔ)言)
上面的p(喜歡 | 我)表示”喜歡“出現(xiàn)在”我“之后的概率铺根,然后將所有概率乘起來(lái)就是整句話出現(xiàn)的概率宪躯。
我們對(duì)上面的公式做一個(gè)更一般化的表示,將wt出現(xiàn)的前面一大堆條件統(tǒng)一記為Context位迂,于是就有了下面的公式:
下面我們針對(duì)Context的具體形式介紹一種常見(jiàn)的語(yǔ)言模型N-Gram.
N-Gram
上面的介紹的公式考慮到詞和詞之間的依賴關(guān)系访雪,但是比較復(fù)雜,對(duì)于4個(gè)詞的語(yǔ)料庫(kù)掂林,我們就需要計(jì)算 4!+3!+2!+1! 個(gè)情況臣缀,稍微大點(diǎn),在實(shí)際生活中幾乎沒(méi)辦法使用泻帮,于是我們就想了很多辦法去近似這個(gè)公式精置,于是就有了下面要介紹的N-Gram模型。
上面的 context 都是這句話中這個(gè)詞前面的所有詞作為條件的概率锣杂,N-gram 就是只管這個(gè)詞前面的 n-1 個(gè)詞脂倦,加上它自己,總共 n 個(gè)詞元莫,于是上面的公式就簡(jiǎn)化為:
當(dāng)n=1時(shí)赖阻,單詞只和自己有關(guān),模型稱為一元模型踱蠢,n=2時(shí)就是bigram火欧,n=3,trigram茎截,據(jù)統(tǒng)計(jì)在英文語(yǔ)料庫(kù)IBM, Brown中苇侵,三四百兆的語(yǔ)料,其測(cè)試語(yǔ)料14.7%的trigram和2.2%的bigram在訓(xùn)練語(yǔ)料中竟未出現(xiàn)企锌!因此在實(shí)際中我們應(yīng)該根據(jù)實(shí)際情況正確的選擇n衅檀,如果n很大,參數(shù)空間過(guò)大霎俩,也無(wú)法實(shí)用哀军。
- 實(shí)際中,最多就用到trigram打却,再多計(jì)算量變大杉适,但是效果提升不明顯
- 更大的n,理論上能提供的信息會(huì)更多柳击,具有更多的信息
- 更小的n猿推,在語(yǔ)料中出現(xiàn)的次數(shù)會(huì)更多,具有更多的統(tǒng)計(jì)信息
word2vec
前面我們已經(jīng)有了計(jì)算概率公式p(w_i|Context_i)了捌肴,對(duì)于傳統(tǒng)的統(tǒng)計(jì)方法蹬叭,我們可以事先在語(yǔ)料上將所有可能的組合都計(jì)算出來(lái),那有沒(méi)有什么數(shù)學(xué)方法状知,能不通過(guò)語(yǔ)料統(tǒng)計(jì)方法秽五,直接將p(w_i|Context_i)計(jì)算出來(lái)呢?再說(shuō)的數(shù)學(xué)點(diǎn)饥悴,通過(guò)什么方法能夠?qū)⑵鋽M合出來(lái)坦喘,數(shù)學(xué)上的描述就是:
具體擬合的方法有各種各樣,其中一個(gè)比較厲害的就是通過(guò)神經(jīng)網(wǎng)絡(luò)來(lái)擬合西设,也就是本文要介紹的word2vec瓣铣。
word2vec的理論部分,網(wǎng)上已經(jīng)有很好的資料贷揽,推薦 word2vec 中的數(shù)學(xué)原理詳解(一)目錄和前言棠笑,我主要會(huì)以具體的實(shí)現(xiàn)為主,有喜歡看視頻的同學(xué)也可以看Udacity 課程視頻禽绪。
word2vec嘗試著將詞都映射到一個(gè)高維空間蓖救,每個(gè)詞都可以用一個(gè)稠密向量來(lái)表示,而這個(gè)詞向量怎么計(jì)算出來(lái)丐一,采用的方法是一種無(wú)監(jiān)督方法藻糖,假設(shè)是詞的含義由其周?chē)脑~來(lái)表示:相似的詞,會(huì)有相似的上下文库车。
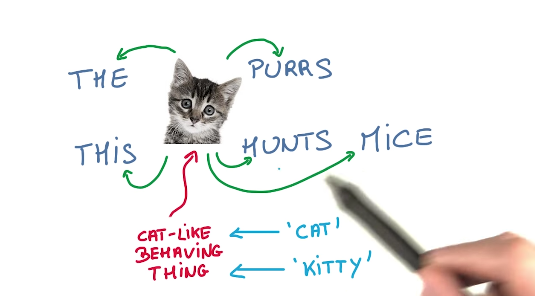
在具體計(jì)算詞向量的時(shí)候巨柒,有兩種模型:Skip-Gram 和 CBOW,
我們先介紹skip-gram的原理柠衍,其訓(xùn)練過(guò)程是:
把詞cat放進(jìn) Embeddings 向量空間洋满,然后做一次線性計(jì)算,然后取 softmax珍坊,得到一個(gè)一批 0-1 的數(shù)值牺勾,然后 cross_entropy,產(chǎn)出預(yù)測(cè)詞purr阵漏。跟目標(biāo)比對(duì)驻民,然后調(diào)整翻具。這就是訓(xùn)練過(guò)程。如下圖:
可能還是有點(diǎn)抽象回还,我們接著看代碼來(lái)詳細(xì)說(shuō)明上面的過(guò)程裆泳,代碼地址:5_word2vec.ipynb
生成Skip-Gram數(shù)據(jù)
Skip-Gram思想是通過(guò)單詞來(lái)預(yù)測(cè)其周?chē)膯卧~,此時(shí)柠硕,如果輸入數(shù)據(jù)是:data: ['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first']工禾,那輸出是:
with num_skips = 2 and skip_window = 1:
batch: ['originated', 'originated', 'as', 'as', 'a', 'a', 'term', 'term']
labels: ['as', 'anarchism', 'a', 'originated', 'term', 'as', 'a', 'of']
%matplotlib inline
import collections
import math
import numpy as np
import tensorflow as tf
import os
import random
import zipfile
from matplotlib import pylab
from six.moves import range
from six.moves.urllib.request import urlretrieve
from sklearn.manifold import TSNE
import jieba
import re
import sklearn
import multiprocessing
import seaborn as sns
from pyltp import SentenceSplitter
import pandas as pd
# sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看唄蝗柔!')
content = ""
with open("../input/人民的名義.txt",'r') as f:
for line in f:
line = line.strip("\n")
content += line
stop_words = []
with open("../input/stop-words.txt") as f:
for word in f:
stop_words.append(word.strip("\n"))
# 進(jìn)行分詞
accepted_chars = re.compile(r"[\u4E00-\u9FD5]+")
# 只取純中文的字符,并且不在沖用詞之中的
tokens = [ token for token in jieba.cut(content) if accepted_chars.match(token) and token not in stop_words]
# tokens = [ token for token in jieba.cut(content) if accepted_chars.match(token)]
count = collections.Counter(tokens)
len(count)
17136
vocabulary_size = 9000 # 總共18000左右的單詞
# 由于語(yǔ)料庫(kù)太小闻葵,所以大多數(shù)詞只出現(xiàn)了一次,我們應(yīng)該過(guò)濾掉出現(xiàn)次數(shù)少的單詞
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0 # dictionary['UNK']
unk_count = unk_count + 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(tokens)
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10])
Most common words (+UNK) [['UNK', 8137], ('說(shuō)', 1326), ('侯亮', 1315), ('平', 966), ('李達(dá)康', 735)]
Sample data [7540, 7541, 7542, 885, 7543, 3470, 7544, 4806, 207, 4807]
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
buffer = collections.deque(maxlen=span)
# 根據(jù)global data_index 產(chǎn)生數(shù)據(jù)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window # target label at the center of the buffer
targets_to_avoid = [ skip_window ]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index]) # 此處 buffer 是 deque 癣丧,容量是 span 槽畔,所以每次新增數(shù)據(jù)進(jìn)來(lái),都會(huì)擠掉之前的數(shù)
data_index = (data_index + 1) % len(data)
return batch, labels
print('data:', [reverse_dictionary[di] for di in data[:8]])
for num_skips, skip_window in [(2, 1), (4, 2)]:
data_index = 0
batch, labels = generate_batch(batch_size=8, num_skips=num_skips, skip_window=skip_window)
print('\nwith num_skips = %d and skip_window = %d:' % (num_skips, skip_window))
print(' batch:', [reverse_dictionary[bi] for bi in batch])
print(' labels:', [reverse_dictionary[li] for li in labels.reshape(8)])
data: ['書(shū)籍', '稻草人', '書(shū)屋', '名義', '作者', '周梅森', '內(nèi)容簡(jiǎn)介', '展現(xiàn)']
with num_skips = 2 and skip_window = 1:
batch: ['稻草人', '稻草人', '書(shū)屋', '書(shū)屋', '名義', '名義', '作者', '作者']
labels: ['書(shū)籍', '書(shū)屋', '稻草人', '名義', '書(shū)屋', '作者', '周梅森', '名義']
with num_skips = 4 and skip_window = 2:
batch: ['書(shū)屋', '書(shū)屋', '書(shū)屋', '書(shū)屋', '名義', '名義', '名義', '名義']
labels: ['稻草人', '名義', '書(shū)籍', '作者', '周梅森', '稻草人', '書(shū)屋', '作者']
batch_size = 128
embedding_size = 50 # Dimension of the embedding vector.
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
# We pick a random validation set to sample nearest neighbors. here we limit the
# validation samples to the words that have a low numeric ID, which by
# construction are also the most frequent.
valid_size = 8 # Random set of words to evaluate similarity on.
valid_window = 100 # Only pick dev samples in the head of the distribution.
valid_examples = np.array(random.sample(range(valid_window), valid_size))
num_sampled = 64 # Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default(), tf.device('/cpu:0'):
# Input data.
train_dataset = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Variables.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
softmax_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
softmax_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Model.
# Look up embeddings for inputs.
embed = tf.nn.embedding_lookup(embeddings, train_dataset)
# Compute the softmax loss, using a sample of the negative labels each time.
loss = tf.reduce_mean(
tf.nn.sampled_softmax_loss(weights=softmax_weights, biases=softmax_biases, inputs=embed,
labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size))
# Optimizer.
# Note: The optimizer will optimize the softmax_weights AND the embeddings.
# This is because the embeddings are defined as a variable quantity and the
# optimizer's `minimize` method will by default modify all variable quantities
# that contribute to the tensor it is passed.
# See docs on `tf.train.Optimizer.minimize()` for more details.
optimizer = tf.train.AdagradOptimizer(1.0).minimize(loss)
# Compute the similarity between minibatch examples and all embeddings.
# We use the cosine distance:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))
上面定義了模型坎缭,下面是具體的優(yōu)化步驟
num_steps = 100001
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print('Initialized')
average_loss = 0
for step in range(num_steps):
batch_data, batch_labels = generate_batch(
batch_size, num_skips, skip_window)
feed_dict = {train_dataset : batch_data, train_labels : batch_labels}
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
if step % 2000 == 0:
if step > 0:
average_loss = average_loss / 2000
# The average loss is an estimate of the loss over the last 2000 batches.
print('Average loss at step %d: %f' % (step, average_loss))
average_loss = 0
# note that this is expensive (~20% slowdown if computed every 500 steps)
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log = 'Nearest to %s:' % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log = '%s %s,' % (log, close_word)
print(log)
final_embeddings = normalized_embeddings.eval()
Initialized
Average loss at step 0: 4.637629
Nearest to 書(shū)記: 一整瓶, 倒好, 一把, 裊裊, 不到, 三姐, 不低, 坦承,
Nearest to 局長(zhǎng): 遞到, 報(bào)紙, 國(guó)旗, 網(wǎng)上, 對(duì)此, 吼, 既有, 幸虧,
Nearest to 問(wèn): 幾遍, 就業(yè), 商販, 口水, 親近, 周, 手槍, 莊嚴(yán),
Nearest to 季: 屈來(lái), 天花板, 韓劇, 栽倒, 判人, 審視, 有意, 內(nèi)容簡(jiǎn)介,
Nearest to 工作: 阻力, 親密, 大人物, 外柔內(nèi)剛, 準(zhǔn), 萬(wàn)元, 諷刺, 草根,
Nearest to 陳清泉: 菏澤, 梁山, 鐵板一塊, 前腳, 運(yùn)來(lái), 酒量, 四十萬(wàn), 黑色,
Nearest to 省委: 市委書(shū)記, 酒量, 交代問(wèn)題, 外號(hào), 漏洞, 虛報(bào), 那輪, 走到,
Nearest to 太: 早已, 紋, 推開(kāi), 黨, 命運(yùn), 始終, 情景, 處處長(zhǎng),
Average loss at step 2000: 3.955496
Average loss at step 4000: 3.414563
Average loss at step 6000: 3.149207
Average loss at step 8000: 2.955826
Average loss at step 10000: 2.786807
Nearest to 書(shū)記: 市長(zhǎng), 老道, 建設(shè), 大鬼, 咬住, 坦承, 調(diào)過(guò)來(lái), 特立獨(dú)行,
Nearest to 局長(zhǎng): 座位, 跳腳, 殺人, 第二天, 頂天立地, 報(bào)紙, 眼眶, 背書(shū),
Nearest to 問(wèn): 凄涼, 料到, 點(diǎn)頭稱是, 空降, 彌漫, 裝, 猜, 幾遍,
Nearest to 季: 韓劇, 愉快, 天花板, 民不聊生, 提供, 親, 那雙, 金礦,
Nearest to 工作: 代價(jià), 外柔內(nèi)剛, 珍藏, 提醒, 大人物, 不小, 諷刺, 激化矛盾,
Nearest to 陳清泉: 沒(méi)能, 鷹, 威風(fēng)凜凜, 雞蛋, 冤枉, 四十萬(wàn), 大鬼, 木板,
Nearest to 省委: 代表, 三級(jí), 影像, 敏銳, 鑄下, 研究, 板, 暗星,
Nearest to 太: 印記, 推開(kāi), 抖動(dòng), 托盤(pán), 不放過(guò), 虛假, 刻下, 稻草人,
Average loss at step 12000: 2.638048
Average loss at step 14000: 2.519046
Average loss at step 16000: 2.441717
Average loss at step 18000: 2.324694
Average loss at step 20000: 2.235700
Nearest to 書(shū)記: 老道, 建設(shè), 咬住, 特立獨(dú)行, 握住, 市長(zhǎng), 提議, 順利,
Nearest to 局長(zhǎng): 座位, 殺人, 跳腳, 放風(fēng), 一段, 第二天, 眼眶, 號(hào)子,
Nearest to 問(wèn): 喜出望外, 詢問(wèn), 料到, 凄涼, 咱老, 反復(fù)無(wú)常, 你別, 打造,
Nearest to 季: 韓劇, 天花板, 愉快, 那雙, 躬, 提供, 我敢, 檢察院,
Nearest to 工作: 代價(jià), 珍藏, 外柔內(nèi)剛, 女婿, 激化矛盾, 諷刺, 打死, 送往,
Nearest to 陳清泉: 沒(méi)能, 鷹, 威風(fēng)凜凜, 別弄, 笑呵呵, 木板, 奪走, 作品,
Nearest to 省委: 三級(jí), 敏銳, 代表, 一票, 謝謝您, 放鞭炮, 婦聯(lián), 研究,
Nearest to 太: 印記, 刻下, 原件, 抖動(dòng), 不放過(guò), 推開(kāi), 事替, 托盤(pán),
Average loss at step 22000: 2.161899
Average loss at step 24000: 2.134306
Average loss at step 26000: 2.040577
Average loss at step 28000: 1.986363
Average loss at step 30000: 1.935009
Nearest to 書(shū)記: 清, 選擇, 建設(shè), 大鬼, 跺腳, 打仗, 咬住, 滿是,
Nearest to 局長(zhǎng): 跳腳, 放風(fēng), 一段, 殺人, 座位, 情感, 口中, 頂天立地,
Nearest to 問(wèn): 喜出望外, 詢問(wèn), 料到, 半真半假, 干什么, 咱老, 海子, 反復(fù)無(wú)常,
Nearest to 季: 天花板, 韓劇, 那雙, 檢察院, 對(duì)視, 我敢, 趙東, 滾落,
Nearest to 工作: 代價(jià), 珍藏, 外柔內(nèi)剛, 女婿, 送往, 打死, 領(lǐng)導(dǎo), 諷刺,
Nearest to 陳清泉: 鷹, 沒(méi)能, 應(yīng)承, 笑呵呵, 別弄, 持股會(huì), 威風(fēng)凜凜, 服從,
Nearest to 省委: 三級(jí), 敏銳, 代表, 婦聯(lián), 舉重若輕, 一票, 澳門(mén), 行管,
Nearest to 太: 刻下, 抖動(dòng), 師生, 溫和, 原件, 進(jìn)屋, 海底, 印記,
Average loss at step 32000: 1.944882
Average loss at step 34000: 1.865572
Average loss at step 36000: 1.827617
Average loss at step 38000: 1.789619
Average loss at step 40000: 1.817634
Nearest to 書(shū)記: 清, 跺腳, 選擇, 包庇, 順利, 目光如炬, 握住, 老同事,
Nearest to 局長(zhǎng): 放風(fēng), 一段, 跳腳, 座位, 殺人, 頂天立地, 濕潤(rùn), 情感,
Nearest to 問(wèn): 掏出, 喜出望外, 半真半假, 干什么, 海子, 撕, 度假村, 道,
Nearest to 季: 對(duì)視, 天花板, 那雙, 韓劇, 檢察院, 吃驚, 我敢, 室內(nèi),
Nearest to 工作: 代價(jià), 領(lǐng)導(dǎo), 外柔內(nèi)剛, 打死, 珍藏, 記起, 田野, 女婿,
Nearest to 陳清泉: 笑呵呵, 沒(méi)能, 應(yīng)承, 鷹, 作品, 撞倒, 瞇, 服從,
Nearest to 省委: 三級(jí), 舉重若輕, 敏銳, 人事, 代表, 行管, 謝謝您, 一票,
Nearest to 太: 刻下, 抖動(dòng), 溫和, 原件, 問(wèn)得, 進(jìn)屋, 海底, 師生,
Average loss at step 42000: 1.743098
Average loss at step 44000: 1.720936
Average loss at step 46000: 1.694092
Average loss at step 48000: 1.734099
Average loss at step 50000: 1.663270
Nearest to 書(shū)記: 清, 選擇, 打仗, 跺腳, 老同事, 老道, 順利, 建設(shè),
Nearest to 局長(zhǎng): 放風(fēng), 一段, 跳腳, 座位, 泡, 近乎, 滾圓, 排除,
Nearest to 問(wèn): 半真半假, 幫幫, 度假村, 聊生, 干什么, 順勢(shì), 大為, 喜出望外,
Nearest to 季: 天花板, 對(duì)視, 檢察院, 韓劇, 那雙, 吃驚, 室內(nèi), 挽回,
Nearest to 工作: 領(lǐng)導(dǎo), 打死, 新臺(tái)階, 外柔內(nèi)剛, 張圖, 陷阱, 田野, 規(guī)劃圖,
Nearest to 陳清泉: 沒(méi)能, 應(yīng)承, 作品, 鷹, 風(fēng)云, 撞倒, 別弄, 請(qǐng)問(wèn),
Nearest to 省委: 舉重若輕, 人事, 三級(jí), 代表, 滑頭, 謝謝您, 澳門(mén), 敏銳,
Nearest to 太: 刻下, 抖動(dòng), 師生, 齊腰, 溫和, 清白, 喊道, 問(wèn)得,
Average loss at step 52000: 1.645000
Average loss at step 54000: 1.627952
Average loss at step 56000: 1.672146
Average loss at step 58000: 1.605531
Average loss at step 60000: 1.595123
Nearest to 書(shū)記: 清, 跺腳, 老同事, 握住, 沒(méi)數(shù), 目光如炬, 打仗, 選擇,
Nearest to 局長(zhǎng): 放風(fēng), 跳腳, 一段, 排除, 座位, 泡, 干掉, 情感,
Nearest to 問(wèn): 半真半假, 度假村, 幫幫, 大為, 聊生, 干什么, 喜出望外, 順勢(shì),
Nearest to 季: 對(duì)視, 檢察院, 天花板, 那雙, 吃驚, 韓劇, 室內(nèi), 同偉,
Nearest to 工作: 領(lǐng)導(dǎo), 陷阱, 張圖, 匯報(bào)會(huì), 新臺(tái)階, 打死, 田野, 著名作家,
Nearest to 陳清泉: 應(yīng)承, 沒(méi)能, 撞倒, 作品, 服從, 請(qǐng)問(wèn), 鷹, 風(fēng)云,
Nearest to 省委: 舉重若輕, 人事, 通氣, 灰燼, 滑頭, 婦聯(lián), 敏銳, 三級(jí),
Nearest to 太: 師生, 刻下, 喊道, 遺憾, 溫和, 抖動(dòng), 清白, 齊腰,
Average loss at step 62000: 1.579666
Average loss at step 64000: 1.627861
Average loss at step 66000: 1.564315
Average loss at step 68000: 1.556485
Average loss at step 70000: 1.545672
Nearest to 書(shū)記: 清, 跺腳, 打仗, 沒(méi)數(shù), 握住, 老同事, 包庇, 選擇,
Nearest to 局長(zhǎng): 放風(fēng), 一段, 跳腳, 泡, 排除, 近乎, 座位, 情感,
Nearest to 問(wèn): 半真半假, 度假村, 大為, 幫幫, 順勢(shì), 追問(wèn), 聊生, 海子,
Nearest to 季: 對(duì)視, 檢察院, 天花板, 同偉, 韓劇, 那雙, 吃驚, 室內(nèi),
Nearest to 工作: 匯報(bào)會(huì), 領(lǐng)導(dǎo), 陷阱, 新臺(tái)階, 著名作家, 規(guī)劃圖, 張圖, 送往,
Nearest to 陳清泉: 沒(méi)能, 撞倒, 風(fēng)云, 應(yīng)承, 鷹, 趕巧, 人員, 看不到,
Nearest to 省委: 舉重若輕, 人事, 灰燼, 婦聯(lián), 三級(jí), 謝謝您, 通氣, 講講,
Nearest to 太: 抖動(dòng), 海底, 遺憾, 喊道, 師生, 問(wèn)得, 溫和, 清白,
Average loss at step 72000: 1.596544
Average loss at step 74000: 1.530987
Average loss at step 76000: 1.524676
Average loss at step 78000: 1.514958
Average loss at step 80000: 1.569173
Nearest to 書(shū)記: 清, 沒(méi)數(shù), 跺腳, 目光如炬, 握住, 選擇, 打仗, 包庇,
Nearest to 局長(zhǎng): 放風(fēng), 跳腳, 一段, 泡, 排除, 領(lǐng)教, 干掉, 情感,
Nearest to 問(wèn): 度假村, 半真半假, 聊生, 大為, 海子, 順勢(shì), 道, 幫幫,
Nearest to 季: 對(duì)視, 檢察院, 同偉, 那雙, 吃驚, 韓劇, 天花板, 室內(nèi),
Nearest to 工作: 領(lǐng)導(dǎo), 匯報(bào)會(huì), 陷阱, 張圖, 新臺(tái)階, 著名作家, 女婿, 規(guī)劃圖,
Nearest to 陳清泉: 沒(méi)能, 風(fēng)云, 撞倒, 應(yīng)承, 人員, 鷹, 請(qǐng)問(wèn), 瞇,
Nearest to 省委: 人事, 舉重若輕, 通氣, 灰燼, 內(nèi)容, 冷不丁, 打電話, 謝謝您,
Nearest to 太: 問(wèn)得, 遺憾, 喊道, 清白, 抖動(dòng), 海底, 自學(xué), 溫和,
Average loss at step 82000: 1.505065
Average loss at step 84000: 1.498249
Average loss at step 86000: 1.494963
Average loss at step 88000: 1.545789
Average loss at step 90000: 1.484452
Nearest to 書(shū)記: 沒(méi)數(shù), 跺腳, 清, 打仗, 滿是, 老道, 若有所思, 超前,
Nearest to 局長(zhǎng): 放風(fēng), 跳腳, 一段, 泡, 排除, 滾圓, 近乎, 攔住,
Nearest to 問(wèn): 半真半假, 幫幫, 大為, 順勢(shì), 度假村, 聊生, 囑咐, 干什么,
Nearest to 季: 對(duì)視, 檢察院, 同偉, 吃驚, 天花板, 韓劇, 那雙, 公安廳,
Nearest to 工作: 領(lǐng)導(dǎo), 陷阱, 匯報(bào)會(huì), 起碼, 規(guī)劃圖, 著名作家, 新臺(tái)階, 張圖,
Nearest to 陳清泉: 沒(méi)能, 風(fēng)云, 撞倒, 應(yīng)承, 瞇, 請(qǐng)問(wèn), 鷹, 幾任,
Nearest to 省委: 舉重若輕, 人事, 灰燼, 謝謝您, 通氣, 老肖, 打電話, 講講,
Nearest to 太: 抖動(dòng), 問(wèn)得, 遺憾, 海底, 師生, 清白, 喊道, 刻下,
Average loss at step 92000: 1.480309
Average loss at step 94000: 1.481867
Average loss at step 96000: 1.527709
Average loss at step 98000: 1.466527
Average loss at step 100000: 1.464015
Nearest to 書(shū)記: 沒(méi)數(shù), 目光如炬, 握住, 清, 跺腳, 若有所思, 老同事, 打仗,
Nearest to 局長(zhǎng): 跳腳, 放風(fēng), 一段, 泡, 排除, 常理, 近乎, 干掉,
Nearest to 問(wèn): 半真半假, 幫幫, 順勢(shì), 大為, 聊生, 度假村, 后悔, 謝謝,
Nearest to 季: 對(duì)視, 檢察院, 同偉, 那雙, 吃驚, 公安廳, 韓劇, 天花板,
Nearest to 工作: 領(lǐng)導(dǎo), 匯報(bào)會(huì), 陷阱, 張圖, 著名作家, 起碼, 規(guī)劃圖, 送往,
Nearest to 陳清泉: 沒(méi)能, 應(yīng)承, 請(qǐng)問(wèn), 鷹, 撞倒, 風(fēng)云, 人員, 別弄,
Nearest to 省委: 人事, 舉重若輕, 灰燼, 國(guó)富, 謝謝您, 打電話, 內(nèi)容, 講講,
Nearest to 太: 遺憾, 海底, 問(wèn)得, 師生, 喊道, 刻下, 抖動(dòng), 齊腰,
階段性結(jié)論
通過(guò)上面的數(shù)據(jù)竟痰,我們很尷尬的發(fā)現(xiàn)效果不佳,樣本數(shù)據(jù)實(shí)在是太少了掏呼,我們需要更多的中文語(yǔ)料坏快。本文只是為了解釋原理,不做過(guò)多的訓(xùn)練憎夷。
下面我們用 gensim 庫(kù)來(lái)再走一遍我們訓(xùn)練過(guò)程
import gensim.models.word2vec as w2v
# Dimensionality of the resulting word vectors.
#more dimensions, more computationally expensive to train
#but also more accurate
#more dimensions = more generalized
num_features = 300
# Minimum word count threshold.
min_word_count = 3
# Number of threads to run in parallel.
#more workers, faster we train
num_workers = multiprocessing.cpu_count()
# Context window length.
context_size = 7
# Downsample setting for frequent words.
#0 - 1e-5 is good for this
downsampling = 1e-3
# Seed for the RNG, to make the results reproducible.
#random number generator
#deterministic, good for debugging
seed = 1
# By default (`sg=0`), CBOW is used.
# Otherwise (`sg=1`), skip-gram is employed.
# `sample` = threshold for configuring which higher-frequency words are randomly downsampled;
# default is 1e-3, useful range is (0, 1e-5).
rmmy2vec = w2v.Word2Vec(
sg=1, # 使用 skip-gram 算法
seed=seed, # 為了讓每次結(jié)果一致莽鸿,給予一個(gè)固定值
workers=num_workers,
size=num_features,
min_count=min_word_count,
window=context_size,
sample=downsampling
)
此處采用的作用,即參數(shù) downsampling的作用拾给,可以參看:How does sub-sampling of frequent words work in the context of Word2Vec?
def sentence_to_wordlist(raw):
clean = re.sub("[^\u4E00-\u9FD5]"," ", raw)
words = jieba.cut(clean)
return list(words)
sentences = []
with open("../input/人民的名義.txt",'r') as f:
for line in f:
line = line.strip("\n")
sents = list(SentenceSplitter.split(line))
for sent in sents:
wordlist = sentence_to_wordlist(sent)
wordlist = [c for c in wordlist if c !=' ']
if wordlist:
sentences.append(wordlist)
token_count = sum([len(sentence) for sentence in sentences])
print("The book corpus contains {0:,} tokens".format(token_count))
The book corpus contains 135,583 tokens
rmmy2vec.build_vocab(sentences)
print("Word2Vec vocabulary length:", len(rmmy2vec.vocab))
Word2Vec vocabulary length: 5539
rmmy2vec.train(sentences)
488248
if not os.path.exists("trained"):
os.makedirs("trained")
rmmy2vec.save(os.path.join("trained", "rmmy2vec.w2v"))
探索下訓(xùn)練出來(lái)的模型
rmmy2vec = w2v.Word2Vec.load(os.path.join("trained", "rmmy2vec.w2v"))
rmmy2vec.most_similar('書(shū)記')
[('李', 0.9455972909927368),
('省委', 0.9354562163352966),
('政法委', 0.9347406625747681),
('田', 0.919845461845398),
('國(guó)富', 0.9158734679222107),
('育良', 0.896552562713623),
('易', 0.8955333232879639),
('省委書(shū)記', 0.8948370218276978),
('秘書(shū)', 0.8864266872406006),
('匯報(bào)', 0.8858834505081177)]
#my video - how to visualize a dataset easily
tsne = sklearn.manifold.TSNE(n_components=2, random_state=0)
all_word_vectors_matrix = rmmy2vec.syn0
all_word_vectors_matrix_2d = tsne.fit_transform(all_word_vectors_matrix)
points = pd.DataFrame(
[
(word, coords[0], coords[1])
for word, coords in [
(word, all_word_vectors_matrix_2d[rmmy2vec.vocab[word].index])
for word in rmmy2vec.vocab
]
],
columns=["word", "x", "y"]
)
sns.set_context("poster")
points.plot.scatter("x", "y", s=10, figsize=(20, 12))
<matplotlib.axes._subplots.AxesSubplot at 0x1161e5e48>
## 解決中文亂碼問(wèn)題
import matplotlib
matplotlib.rcParams['font.family'] = 'STFangsong'#用來(lái)正常顯示中文標(biāo)簽
# mpl.rcParams['font.sans-serif'] = [u'STKaiti']
matplotlib.rcParams['axes.unicode_minus'] = False #用來(lái)正常顯示負(fù)號(hào)
def plot_region(x_bounds, y_bounds):
slice = points[
(x_bounds[0] <= points.x) &
(points.x <= x_bounds[1]) &
(y_bounds[0] <= points.y) &
(points.y <= y_bounds[1])
]
ax = slice.plot.scatter("x", "y", s=35, figsize=(10, 8))
for i, point in slice.iterrows():
ax.text(point.x + 0.005, point.y + 0.005, point.word, fontsize=11)
plot_region(x_bounds=(-6, -5), y_bounds=(10, 11))
展示線性關(guān)系
def nearest_similarity_cosmul(start1, end1, end2):
similarities = rmmy2vec.most_similar_cosmul(
positive=[end2, start1],
negative=[end1]
)
start2 = similarities[0][0]
print("{start1} is related to {end1}, as {start2} is related to {end2}".format(**locals()))
return start2
nearest_similarity_cosmul("書(shū)記", "官員", "省委")
書(shū)記 is related to 官員, as 國(guó)富 is related to 省委
'國(guó)富'
以上例子只為說(shuō)明祥得,真正訓(xùn)練的時(shí)候我看大多數(shù)用的都是wiki的中文語(yǔ)料,有兩篇文檔講了這個(gè)過(guò)程蒋得,可以看:
中英文維基百科語(yǔ)料上的 Word2Vec 實(shí)驗(yàn)
參考
深度學(xué)習(xí) word2vec 筆記之基礎(chǔ)篇
