一些聚類算法
Birch層次聚類 贰健,KMeans原形算法 贱勃,AGNES層次算法昂勒, DBSCAN密度算法蜀细, LVQ原形算法
簡單做一個個人想法記錄,其實聚類算法來說大體上的思路都非常簡單戈盈,無非是找點(diǎn)或者區(qū)域奠衔,計算它們之間的距離(這個距離為抽象意義上的距離,不同的內(nèi)容有不同的距離表示方式),然后根據(jù)一定規(guī)則(一般都是以最近為相鄰)涣觉,然后疊加在一起痴荐。
簡單來說:聚類就是如何確認(rèn)某些點(diǎn)或區(qū)域,再根據(jù)這些選好的點(diǎn)與區(qū)域再進(jìn)行距離計算官册,從而進(jìn)行劃分生兆。
簡單代碼可見:https://github.com/AresAnt/ML-DL
Kmeans算法:(原形聚類方法)
最簡單的Kmeans算法的思路,首先我們要確定劃分幾個類(即K值)膝宁。
假設(shè)這里需要劃分3個類:
- 先初始化三個隨機(jī)樣本點(diǎn)鸦难。(隨機(jī)點(diǎn)一定是要在樣本范圍之內(nèi)矗愧,一般來說可以以隨機(jī)挑選三個樣本點(diǎn)作為起始樣本點(diǎn))
- 對全樣本進(jìn)行遍歷形葬,與三個隨機(jī)點(diǎn)進(jìn)行計算,與哪個隨機(jī)點(diǎn)近就劃分進(jìn)入哪個隨機(jī)點(diǎn)的區(qū)域內(nèi)费封。
- 一次劃分完畢后介返,對區(qū)域內(nèi)所有的點(diǎn)間距離進(jìn)行平均計算拴事。假設(shè)當(dāng)前區(qū)域內(nèi)劃分進(jìn)來了m-1個樣本點(diǎn),加上隨機(jī)點(diǎn)圣蝎,總共為m個樣本在這片區(qū)域內(nèi)刃宵。兩兩計算它們之間的距離,總共需要循環(huán)計算 m (m-1) 次徘公,然后除以這片區(qū)域內(nèi)的樣本數(shù)量牲证。即
$$ {\frac{1}{m}}{\sum^{m}_{i=1,i<j}λ_iλ_j}$$ - 算出后的點(diǎn),即為新的隨機(jī)樣本點(diǎn)(也稱為算質(zhì)心)关面,然后重復(fù)以上的過程坦袍,不斷的更替質(zhì)心直到最后確定。
LVQ算法:(原形聚類方法)
LVQ算法是假設(shè)數(shù)據(jù)樣本帶有類別標(biāo)記的等太,學(xué)習(xí)過程中利用樣本的這些監(jiān)督信息來輔助聚類捂齐。
(簡單描述,其實它的做法與KMeans類似澈驼,也是相當(dāng)于是一個找質(zhì)心點(diǎn)的過程辛燥,這里為找原形向量,每一行的向量其實對應(yīng)的就是上述所提到的質(zhì)心點(diǎn))
算法流程:
輸入:樣本集D = {(x1,y1),(x2,y2),....,(xm,ym)} (設(shè) D1 = (x1,y1))
原形向量的個數(shù)q缝其,各原形向量的類別標(biāo)記 { t1,t2,t3,t4,..,tq } 【這個劃分的意思是指挎塌,假設(shè)我上述樣本集中的 yi 為兩類,即 0内边,1, 那么我可以設(shè)置原形向量的類別為 { 1,1,0,0,1} (意思為1分類的樣本最后會劃分為3個簇榴都,0分類的樣本最后會劃分為2個簇】
學(xué)習(xí)率 α (0~1)
過程:
- 初始化一組原形向量 P = {(p1,t1),(p2,t2) ,...,(pq,tq)} (這個初始化一般以隨機(jī)改 ti
分類下的樣本作為 pi)
# 初始化原形向量,這里做簡單操作漠其,假設(shè)希望找到 3個好瓜的簇嘴高,2個壞瓜的簇竿音,總共五個簇
good = np.where(rowdata_y == 1)[0]
bad = np.where(rowdata_y == 0)[0]
vectorlist = random.sample(list(good),3) + random.sample(list(bad),2)
P_x = np.zeros((k,rowdata_x.shape[1]))
P_y = np.zeros((k,rowdata_y.shape[1]))
for i in range(len(vectorlist)):
P_x[i] = rowdata_x[vectorlist[i]]
P_y[i] = rowdata_y[vectorlist[i]]
- 循環(huán)迭代:
從樣本 D 中隨機(jī)抽取一個樣本(xi,yi)進(jìn)行向量校正(類似前面的移動質(zhì)心點(diǎn))
找出最小的原形向量 pj
if D.yi == P.tj:
P.pj = P.pj + α * ( D.xi - P.pj )
else:
P.pj = P.pj - α * ( D.xi - P.pj )
- 輸出原形向量 P
缺點(diǎn):LVQ算法的質(zhì)心點(diǎn)移動取決于進(jìn)來計算的隨機(jī)點(diǎn),這個點(diǎn)的進(jìn)來順序有關(guān)拴驮,如果進(jìn)來的點(diǎn)都過于的奇特春瞬,那么質(zhì)心點(diǎn)的改變也會特別的奇怪。需要一定量的迭代次數(shù)來進(jìn)行更正套啤。不過因為隨機(jī)點(diǎn)是隨機(jī)產(chǎn)生宽气,隨機(jī)產(chǎn)生符合正太分布,正態(tài)分布的點(diǎn)數(shù)為樣本中心點(diǎn)質(zhì)量有關(guān)潜沦。
AGNES 層次聚類算法:(層次聚類算法)
層次聚類算法可以有“自底向上”的聚合策略萄涯,也可以采用“自頂向下”的分拆策略。(2分-Kmeans就是“自頂向下”的策略)
AGNES是“自底向上”的聚合策略唆鸡,它簡單的先將每個樣本點(diǎn)看做是一個簇涝影,然后通過計算相應(yīng)的距離,選取最小的兩個簇合成為以個簇争占,以此反復(fù)燃逻,計算量龐大。
算法思路臂痕,對于數(shù)據(jù)集D唆樊,D={x_1,x_2,…,x_n}:
將數(shù)據(jù)集中的每個對象生成一個簇,得到簇列表C刻蟹,C={c_1,c_2,…,c_n}
a) 每個簇只包含一個數(shù)據(jù)對象:c_i={x_i};
重復(fù)如下步驟嘿辟,直到C中只有一個簇:
a) 從C中的簇中找到兩個“距離”最近的兩個簇:min?〖D(c_i,c_j)〗舆瘪;
b) 合并簇c_i和cj,形成新的簇c(i+j)红伦;
c) 從C中刪除簇c_i和cj英古,添加簇c(i+j)
稍微注意一下簇間距離運(yùn)算的方式:
在上面描述的算法中涉及到計算兩個簇之間的距離,對于簇C_1和C_2昙读,計算〖D(C_1,C〗_2)召调,有以下幾種計算方式:
單連鎖(Single link):
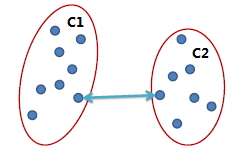
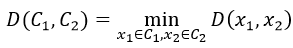
兩個簇之間最近的兩個點(diǎn)的距離作為簇之間的距離,該方式的缺陷是受噪點(diǎn)影響大蛮浑,容易產(chǎn)生長條狀的簇唠叛。
全連鎖(Complete link)
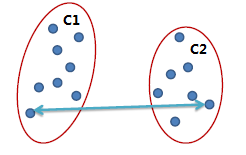

兩個簇之間最遠(yuǎn)的兩個點(diǎn)的距離作為簇之間的距離,采用該距離計算方式得到的聚類比較緊湊沮稚。
平均連鎖(Average link)


兩個簇之間兩兩點(diǎn)之間距離的平均值艺沼,該方式可以有效地排除噪點(diǎn)的影響。
Birch層次聚類算法:(層次聚類算法)
不做多余贅述蕴掏,可以查看該鏈接:http://www.reibang.com/p/e0c4f19f7ab1
DBSCAN密度聚類算法:(密度聚類算法)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise障般,具有噪聲的基于密度的聚類方法)是一種基于密度的空間聚類算法调鲸。該算法將具有足夠密度的區(qū)域劃分為簇,并在具有噪聲的空間數(shù)據(jù)庫中發(fā)現(xiàn)任意形狀的簇挽荡,它將簇定義為密度相連的點(diǎn)的最大集合藐石。
該算法利用基于密度的聚類的概念,即要求聚類空間中的一定區(qū)域內(nèi)所包含對象(點(diǎn)或其他空間對象)的數(shù)目不小于某一給定閾值定拟。DBSCAN算法的顯著優(yōu)點(diǎn)是聚類速度快且能夠有效處理噪聲點(diǎn)和發(fā)現(xiàn)任意形狀的空間聚類于微。但是由于它直接對整個數(shù)據(jù)庫進(jìn)行操作且進(jìn)行聚類時使用了一個全局性的表征密度的參數(shù),因此也具有兩個比較明顯的弱點(diǎn):
(1)當(dāng)數(shù)據(jù)量增大時办素,要求較大的內(nèi)存支持I/O消耗也很大角雷;
(2)當(dāng)空間聚類的密度不均勻、聚類間距差相差很大時性穿,聚類質(zhì)量較差
DBSCAN密度聚類算法從樣本的密度角度來考察樣本之間的可連接性勺三。簡單來說,就是對一個樣本點(diǎn)它需曾,以它為中心吗坚,它周邊一定區(qū)域內(nèi)所含樣本數(shù)達(dá)到閾值,則該樣本點(diǎn)就屬于一個領(lǐng)域內(nèi)呆万,且該樣本所含區(qū)域范圍內(nèi)的樣本點(diǎn)即為一個密度云商源,然后進(jìn)行向外擴(kuò)充。
基本定義:
- 領(lǐng)域:對于 xj 屬于 數(shù)據(jù)集D谋减,其領(lǐng)域包含樣本集與xj的距離不大于 γ 的樣本牡彻,即 N(xj) = { xj屬于D | dist ( xi , xj ) <= γ }
- 核心對象: 若 xj 的領(lǐng)域中至少包含 MinPts 個樣本,即 | N(xj)| >= MinPts 出爹,則 xj 為一個核心對象
- 密度直達(dá): 若xj位于xi的領(lǐng)域中庄吼,且xi也是一個核心對象,則稱xj有xi密度直達(dá)
- 密度可達(dá): 對xi與xj严就,若存在樣本序列 p1,p2,..,pn,其中 p1 = xi , pn = xj ,且 pi+1 是由 pi 密度直達(dá)总寻,則稱xj由xi密度可達(dá)
- 密度相連:對xi與xj,若存在xk使得xi,xj均有xk密度可達(dá)梢为,則xi,xj密度相連【我們做聚類主要就是找到一個樣本點(diǎn)(簡稱密度云)的最大密度相連】
算法流程:
輸入:樣本集 D = { x1,x2,x3,...,xn }
領(lǐng)域參數(shù) { γ 渐行, MinPts}
過程:
- 先找出整個樣本中的核心對象集合 T
- 隨機(jī)選取核心對象集合中的一個對象作為起始對象,尋找它的領(lǐng)域樣本點(diǎn)集 L
- 對尋找出來的樣本點(diǎn)集 L 做核心對象判斷铸董,符合核心對象的形成一個新的小核心對象點(diǎn)集 P祟印,再對 P 重復(fù)第二步,直到循環(huán)結(jié)束輸出一個全體的樣本點(diǎn)集 E
- 原來的核心對象集合 T - E 袒炉,留下來的為剩下的核心對象集合旁理, E 為分好的簇,重復(fù)第二步直到核心對象集合 T 中沒有核心對象
高斯混合聚類(概率模型聚類)
簡單來說這個聚類方式就是我磁,我事先告訴算法有需要有幾個分類孽文,然后通過隨機(jī)樣本驻襟,然后以隨機(jī)后的樣本求其后驗分布。求出其后驗分布后(簇的劃分即為后驗概率最大的一方)芋哭。再通過求出的后驗概率去對原先假設(shè)的樣本進(jìn)行更新迭代沉衣,使其趨向于最優(yōu)解(這時候就是通過極大似然估計去逼近最優(yōu)值,來更新樣本)這里我們可以假設(shè)我們的分類概率是一個隱變量减牺,那么這樣子的求解方式就是EM算法:詳見(另一篇文章)
其實EM算法與反向傳播的概念基本上是相同豌习,在反向傳播中,我們先假設(shè)一個參數(shù)求出一個 y值解拔疚,將這個解值去與真實值比較肥隆,后會產(chǎn)生一個損失函數(shù),目的是使損失函數(shù)不斷的減小從而更新假設(shè)值稚失。EM算法其實也是相同的栋艳,稍微不同的是,這里沒有真實值去進(jìn)行逼近句各,而是通過對每次的假設(shè)與極大似然估計進(jìn)行逼近吸占,在兩者達(dá)到一定閾值或者到一定迭代次數(shù)時候即為最佳。
算法流程:
輸入:樣本集 D = { x1,x2,x3,...,xm }
高斯混合成分個數(shù)k
過程:
初始化高斯混合分布函數(shù) a,u,Z
a = 1 / k
u = 隨機(jī)的選擇連續(xù)函數(shù)在高斯分布中的值
Z = (還有待研究)
- 先計算其所有的樣本K的對于D中每個樣本的后驗概率
- 更新a,u,Z的值(通過極大似然估計)凿宾,迭代循環(huán)到第一步
- 根據(jù)后驗概率選擇分類
