昨天在github上閑逛空幻,發(fā)現(xiàn)了一個(gè)神器tpot课蔬。其操作簡單囱稽,只需要簡單幾行代碼就可以從原始數(shù)據(jù)集上生成機(jī)器學(xué)習(xí)代碼,它會自動幫你生成整個(gè)算法代碼二跋,好激動啊有木有战惊!。
TPOT github:https://github.com/rhiever/tpot
TPOT 官方文檔:http://rhiever.github.io/tpot/
TPOT介紹
TPOT是Python編寫的同欠,使用遺傳算法幫你對機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘問題進(jìn)行特征選擇和算法模型選擇的工具样傍。只要你寫幾行簡單的算法就可以得到不錯(cuò)的結(jié)果,神器啊有木有铺遂!
眾所周知,一個(gè)機(jī)器學(xué)習(xí)問題或者數(shù)據(jù)挖掘問題整體上有如下幾個(gè)處理步驟:從數(shù)據(jù)清洗茎刚、特征選取襟锐、特征重建、特征選擇膛锭、算法模型算法和算法參數(shù)優(yōu)化粮坞,以及最后的交叉驗(yàn)證。整個(gè)步驟異常繁瑣初狰,但使用TPOT可以輕松解決特征提取和算法模型選擇的問題莫杈,如下圖陰影部分所示。

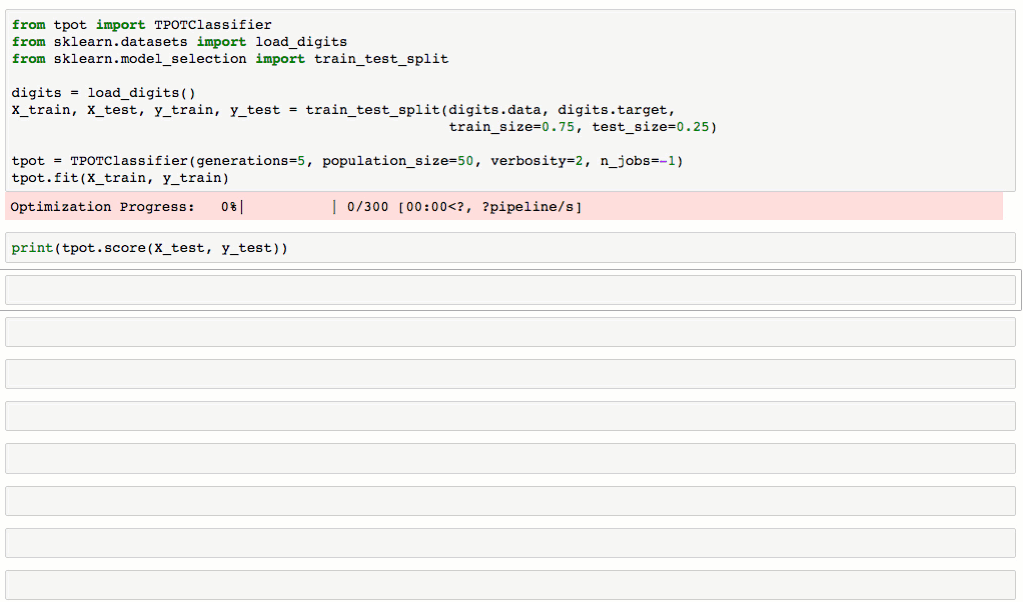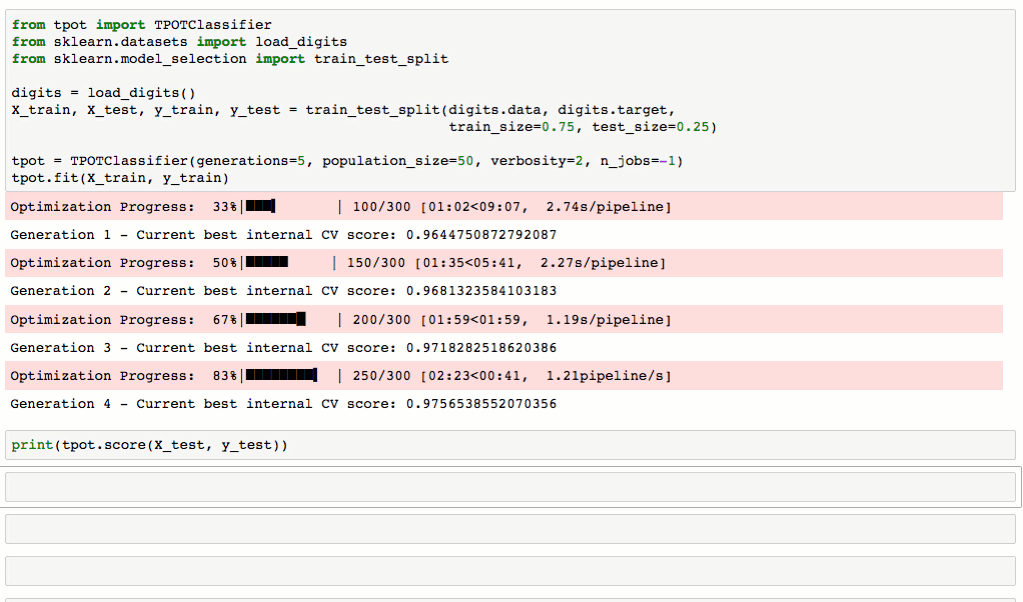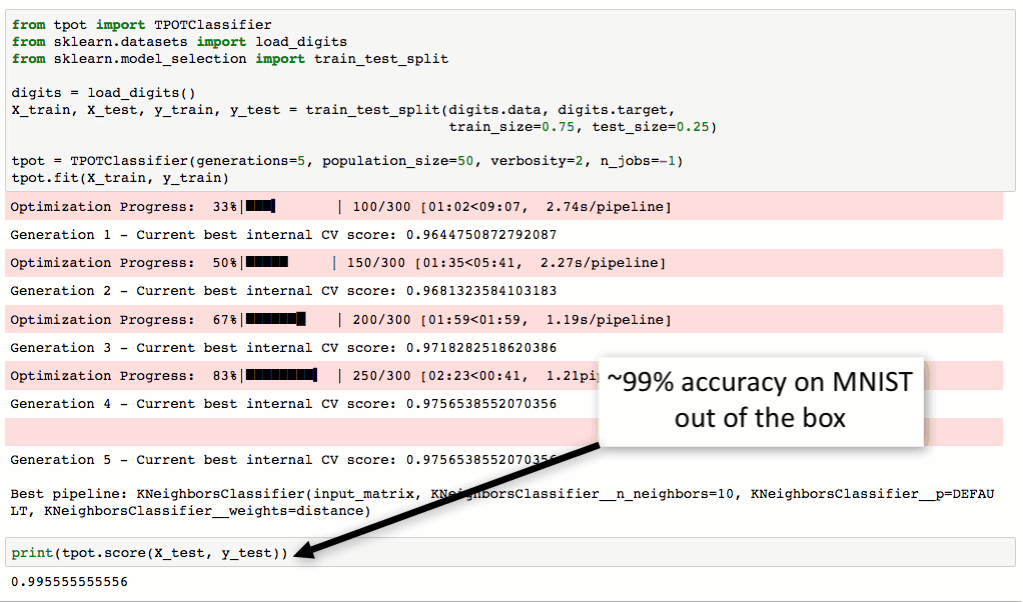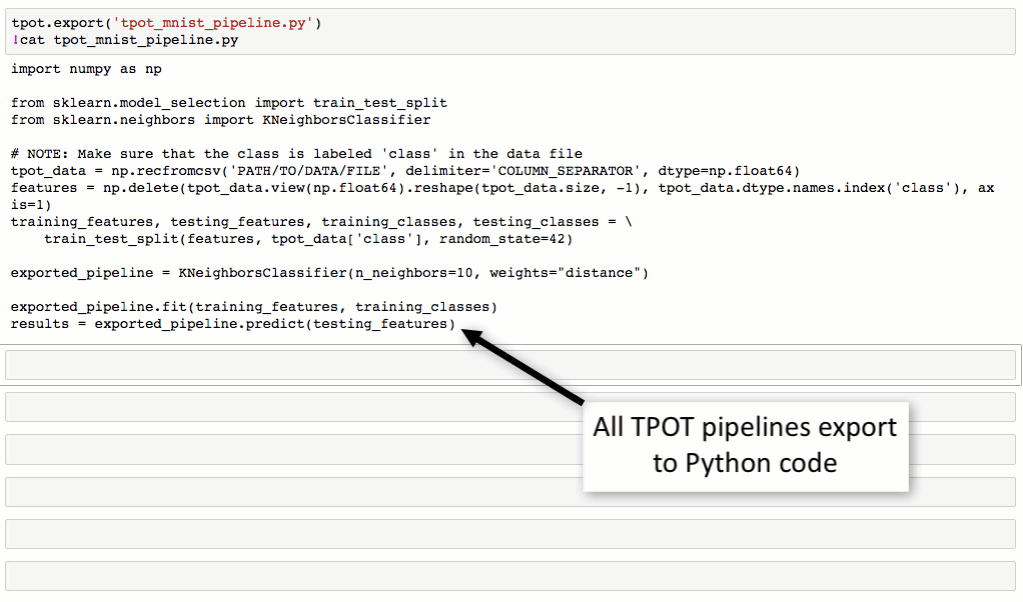
從下圖對MNIST數(shù)據(jù)集進(jìn)行處理的流程可以看到奢入,TPOT可以輕松取得98.4%的結(jié)果筝闹,這個(gè)結(jié)果還是很不錯(cuò)的(在傳統(tǒng)方法中,TPOT暫時(shí)沒有添加任何神經(jīng)網(wǎng)絡(luò)算法腥光,如CNN)关顷。最最重要的是TPOT還可以將整個(gè)的處理流程輸出為Python代碼,好激動啊有木有武福!Talk is simple议双,show you the code。
TPOT安裝
TPOT是運(yùn)行在Python環(huán)境下的捉片,所以你首先需要按照相應(yīng)的Python庫:
- NumPy
- SciPy
- scikit-learn
- DEAP
- update_checker
- tqdm
此外TPOT還支持xgboost模型平痰,所以你可以自行安裝xgboost汞舱。
pip install xgboost
最后安裝
pip install tpot
TPOT安裝可以參考官方文檔,也可以直接到github項(xiàng)目頁面提交issue宗雇。
TPOT例子
1.IRIS
TPOT使用起來很簡單:首先載入數(shù)據(jù)兵拢,聲明TPOTClassifier,fit逾礁,最后export代碼说铃。
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
生成的tpot_iris_pipeline.py是這樣的:
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import FunctionTransformer, PolynomialFeatures
tpot_data = np.recfromcsv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = np.delete(tpot_data.view(np.float64).reshape(tpot_data.size, -1), tpot_data.dtype.names.index('class'), axis=1)
training_features, testing_features, training_classes, testing_classes = \
train_test_split(features, tpot_data['class'], random_state=42)
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
LogisticRegression(C=0.9, dual=False, penalty="l2")
)
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)
2.Titanic Kaggle
由于TPOT并不包含數(shù)據(jù)清洗的功能,所以需要人工進(jìn)行數(shù)據(jù)清洗嘹履,整個(gè)例子代碼腻扇,最后生成的代碼如下:
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.preprocessing import PolynomialFeatures
# NOTE: Make sure that the class is labeled 'class' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', delimiter='COLUMN_SEPARATOR')
training_indices, testing_indices = train_test_split(tpot_data.index, stratify = tpot_data['class'].values, train_size=0.75, test_size=0.25)
result1 = tpot_data.copy()
# Use Scikit-learn's PolynomialFeatures to construct new features from the existing feature set
training_features = result1.loc[training_indices].drop('class', axis=1)
if len(training_features.columns.values) > 0 and len(training_features.columns.values) <= 700:
# The feature constructor must be fit on only the training data
poly = PolynomialFeatures(degree=2, include_bias=False)
poly.fit(training_features.values.astype(np.float64))
constructed_features = poly.transform(result1.drop('class', axis=1).values.astype(np.float64))
result1 = pd.DataFrame(data=constructed_features)
result1['class'] = result1['class'].values
else:
result1 = result1.copy()
result2 = result1.copy()
# Perform classification with an Ada Boost classifier
adab2 = AdaBoostClassifier(learning_rate=0.15, n_estimators=500, random_state=42)
adab2.fit(result2.loc[training_indices].drop('class', axis=1).values, result2.loc[training_indices, 'class'].values)
result2['adab2-classification'] = adab2.predict(result2.drop('class', axis=1).values)
TPOT Notes
- TPOTClassifier()
TPOT最核心的就是整個(gè)函數(shù),在使用TPOT的時(shí)候砾嫉,一定要弄清楚TPOTClassifier()函數(shù)中的重要參數(shù)幼苛。
-
generation:遺傳算法進(jìn)化次數(shù),可理解為迭代次數(shù) -
population_size:每次進(jìn)化中種群大小 -
num_cv_folds:交叉驗(yàn)證 -
scoring:也就是損失函數(shù)
generation和population_size共同決定TPOT的復(fù)雜度焕刮,還有其他參數(shù)可以在官方文檔中找到舶沿。
2.TPOT速度
TPOT在處理小規(guī)模數(shù)據(jù)非常快配并,結(jié)果很給力括荡。但處理大規(guī)模的數(shù)據(jù)問題,速度非常慢溉旋,很慢畸冲。所以在做數(shù)據(jù)挖掘問題,可以嘗試在數(shù)據(jù)清洗之后观腊,抽樣小部分?jǐn)?shù)據(jù)跑一下TPOT邑闲,最初能得到一個(gè)還不錯(cuò)的算法。
