在優(yōu)酷调限,我們使用 Redis Cluster 構(gòu)建了一套內(nèi)存存儲系統(tǒng)凿宾,項目代號為藍(lán)鯨麻捻。藍(lán)鯨的設(shè)計目標(biāo)是高效讀寫纲仍,所有數(shù)據(jù)都在內(nèi)存中。藍(lán)鯨的主要應(yīng)用場景是 cookie 和大數(shù)據(jù)團(tuán)隊計算的數(shù)據(jù)贸毕,都具有較強(qiáng)的時效性郑叠,因此所有的數(shù)據(jù)都有過期時間。更準(zhǔn)確的說藍(lán)鯨是一個全內(nèi)存的臨時存儲系統(tǒng)明棍。
到目前為止集群規(guī)模逐漸增長到 700+ 節(jié)點(diǎn)乡革,即將達(dá)到作者建議的最大集群規(guī)模 1,000 節(jié)點(diǎn)。我們發(fā)現(xiàn)隨著集群規(guī)模的擴(kuò)大摊腋,帶寬壓力不斷突出沸版,并且響應(yīng)時間 RT 方面也會略微升高。與一致性哈希構(gòu)建的 Redis 集群不一樣兴蒸,Redis Cluster 不能做成超大規(guī)模的集群视粮,它比較適合作為中等規(guī)模集群的解決方案。
運(yùn)維期間类咧,吞吐量與 RT 一直作為衡量集群穩(wěn)定性的重要指標(biāo)馒铃,這里在本文中,我們碰到的影響集群吞吐量與 RT 的一些問題與探索記錄下來痕惋,希望對大家有所幫助。
1 - Redis Cluster 工作原理
Redis 采用單進(jìn)程模型娃殖,除去 bgsave 與 aof rewrite 會另外新建進(jìn)程外值戳,所有的請求與操作都在主進(jìn)程內(nèi)完成。其中比較重量級的請求與操作類型有:
- 客戶端請求
- 集群通訊
- 從節(jié)同步
- AOF 文件
- 其它定時任務(wù)
Redis 服務(wù)端采用Reactor 設(shè)計模式炉爆,它是一種基于事件的編程模型堕虹,主要思想是將請求的處理流程劃分成有序的事件序列,比如對于網(wǎng)絡(luò)請求通常劃分為:Accept new connections芬首、Read input to buffer赴捞、Process request、 Response等幾個事件郁稍。并在一個無限循環(huán)的 EventLoop 中不斷的處理這些事件赦政。更多關(guān)于Reactor,請參考 https://en.wikipedia.org/wiki/Reactor 。
比較特別的是恢着,Redis 中還存在一種時間事件桐愉,它其實(shí)是定時任務(wù),與請求事件一樣掰派,它同樣在 EventLoop 中處理从诲。Redis 主線程的主要處理流程如下圖:
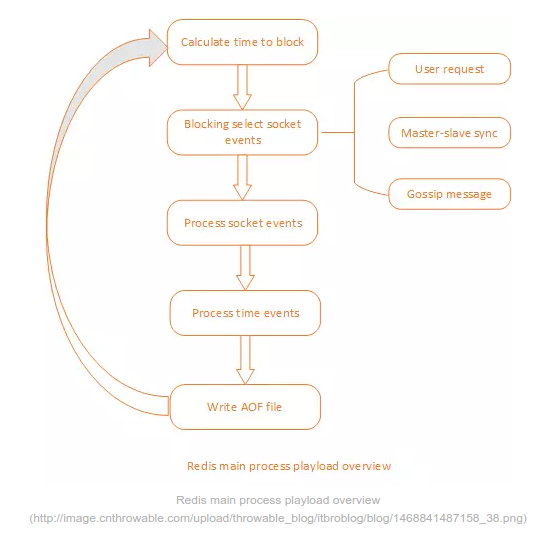
理解了 Redis 的單進(jìn)程模型與主要負(fù)載情況,很容易明白靡羡,想要增加 Redis 吞吐量系洛,只需要盡量降低其它任務(wù)的負(fù)載量就行了,所以提高 Redis 集群吞吐量的方式主要有:
A) - 提高 Redis 集群吞吐的方法
- 適當(dāng)調(diào)大
cluster-node-timeout參數(shù)
我們發(fā)現(xiàn)當(dāng)集群規(guī)模達(dá)到一定程度時略步,集群間消息通訊開銷的帶寬是極其可觀的描扯。
集群通信機(jī)制
Redis 集群采用無中心的方式,為了維護(hù)集群狀態(tài)統(tǒng)一纳像,節(jié)點(diǎn)之間需要互相交換消息荆烈。Redis采用交換消息的方式被稱為 Gossip ,基本思想是節(jié)點(diǎn)之間互相交換信息最終所有節(jié)點(diǎn)達(dá)到一致竟趾,更多關(guān)于 Gossip 可參考 https://en.wikipedia.org/wiki/Gossip_protocol 憔购。
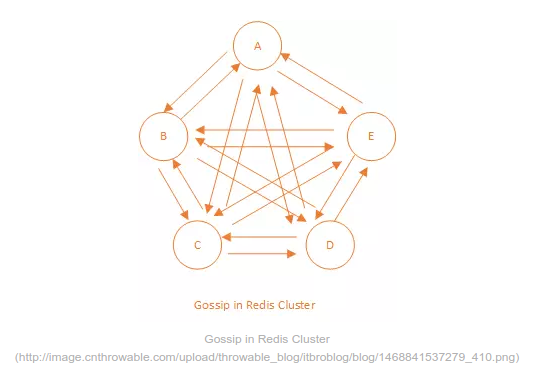
總結(jié)集群通信機(jī)制的一些要點(diǎn):
- Who:集群中每個節(jié)點(diǎn)
- When:定時發(fā)送,默認(rèn)每隔一秒
- What:一個長度為 16,384 的 Bitmap 與集群中其它節(jié)點(diǎn)狀態(tài)的十分之一
如何理解集群中節(jié)點(diǎn)狀態(tài)的十分之一岔帽?假如集群中有 700 個節(jié)點(diǎn)玫鸟,十分之一就是 70 個節(jié)點(diǎn)狀態(tài),節(jié)點(diǎn)狀態(tài)具體數(shù)據(jù)結(jié)構(gòu)見下邊代碼:
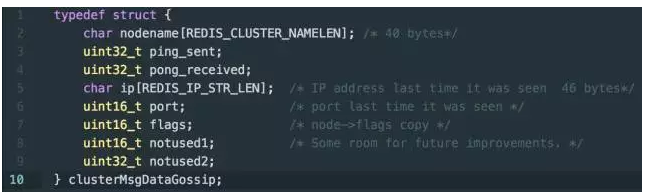
我們將注意力放在數(shù)據(jù)包大小與流量上犀勒,每個節(jié)點(diǎn)狀態(tài)大小為 104 byte屎飘,所以對于 700 個節(jié)點(diǎn)的集群,這部分消息的大小為 70 * 104 = 7280贾费,大約為 7KB钦购。另外每個 Gossip 消息還需要攜帶一個長度為 16,384 的 Bitmap,大小為 2KB褂萧,所以每個 Gossip 消息大小大約為 9KB押桃。
隨著集群規(guī)模的不斷擴(kuò)大,每臺主機(jī)的流量不斷增長导犹,我們懷疑集群間通信的流量已經(jīng)大于前端請求產(chǎn)生的流量唱凯,所以做了以下實(shí)驗(yàn)以明確集群流量狀況。
實(shí)驗(yàn)過程
實(shí)驗(yàn)環(huán)境為:節(jié)點(diǎn) 704谎痢,物理主機(jī) 40 臺磕昼,每臺物理主機(jī)有 16 個節(jié)點(diǎn),集群采用一主一從模式节猿,集群中節(jié)點(diǎn) cluster-node-timeout 設(shè)置為 30 秒票从。
實(shí)驗(yàn)的大概思路為,分別截取一分鐘時間內(nèi)一個節(jié)點(diǎn),在集群通信端口上纫骑,進(jìn)入方向與出去方向的流量蝎亚,并統(tǒng)計出消息條數(shù),并最終計算出臺主機(jī)因?yàn)榧洪g通訊產(chǎn)生的帶寬開銷先馆。實(shí)驗(yàn)具體過程如下:
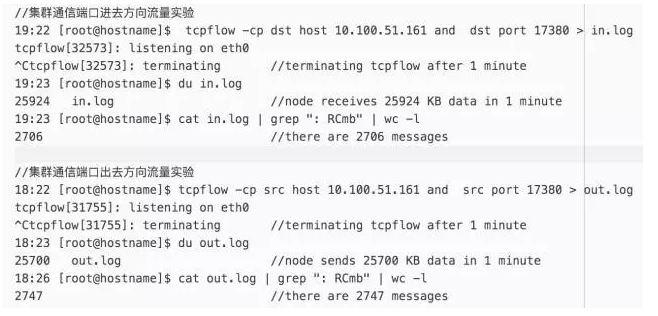
通過實(shí)驗(yàn)?zāi)芸吹竭M(jìn)入方向與出去方向在 60s 內(nèi)收到的數(shù)據(jù)包數(shù)量為 2,700 多個发框。因?yàn)?Redis 規(guī)定每個節(jié)點(diǎn)每一秒只向一個節(jié)點(diǎn)發(fā)送數(shù)據(jù)包,所以正常情況每個節(jié)點(diǎn)平均 60s 會收到 60 個數(shù)據(jù)包煤墙,為什么會有這么大的差距梅惯?
原來考慮到 Redis 發(fā)送對象節(jié)點(diǎn)的選取是隨機(jī)的,所以存在兩個節(jié)點(diǎn)很久都沒有交換消息的情況仿野,為了保證集群狀態(tài)能在較短時間內(nèi)達(dá)到一致性铣减,Redis 規(guī)定當(dāng)兩個節(jié)點(diǎn)超過 cluster-node-timeout 的一半時間沒有交換消息時,下次心跳交換消息脚作。
解決了這個疑惑葫哗,接下來看帶寬情況。先看 Redis Cluster 集群通信端口進(jìn)入方向每臺主機(jī)的每秒帶寬為:
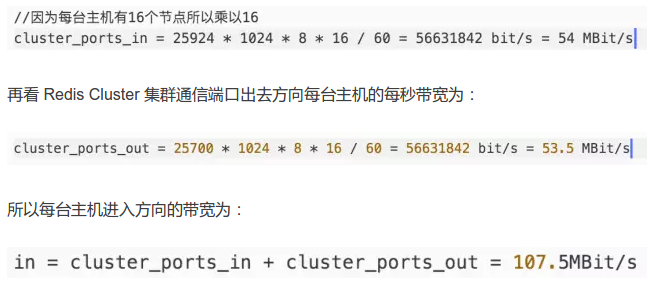
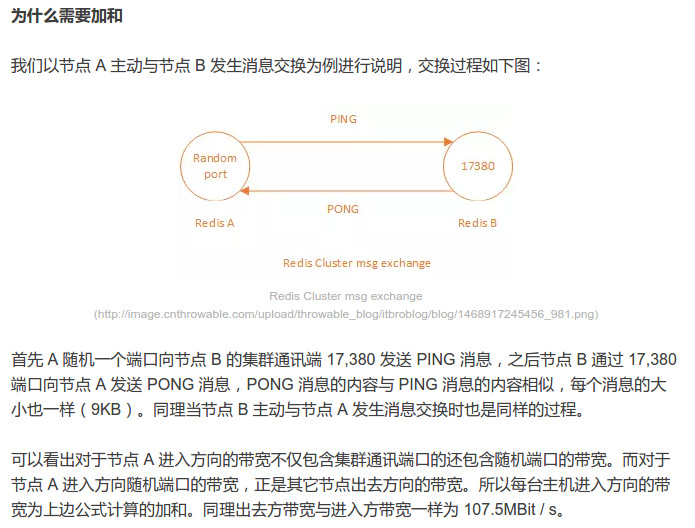
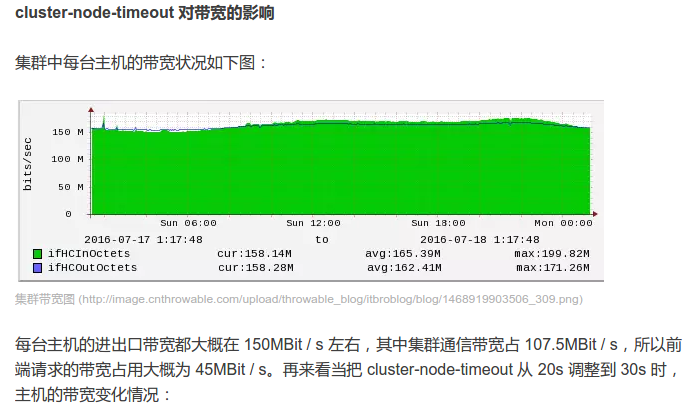
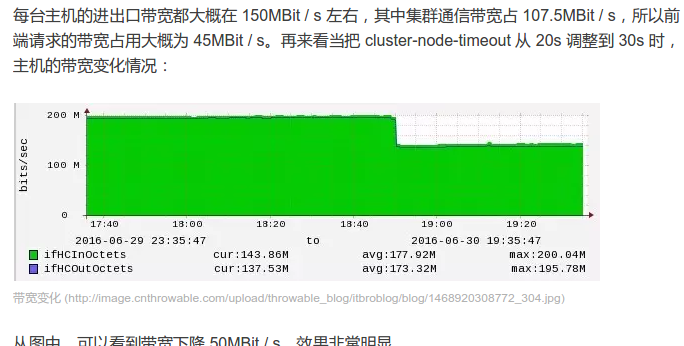
經(jīng)過以上實(shí)驗(yàn)我們能得出兩個結(jié)論:
集群間通信占用大量帶寬資源
調(diào)整 cluster-node-timeout 參數(shù)能有效降低帶寬
Redis Cluster 判定節(jié)點(diǎn)為 fail 的機(jī)制
但是并不是 cluster-node-timeout 越大越好球涛。當(dāng) cluster-node-timeou 增大的時候集群判斷節(jié)點(diǎn) fail 的時間會增加劣针,從而 failover 的時間窗口會增加。集群判定節(jié)點(diǎn)為fail所需時間的計算公式如下:
當(dāng)節(jié)點(diǎn)向失敗節(jié)點(diǎn)發(fā)出 PING 消息亿扁,并且在 cluster-node-timeout 時間內(nèi)還沒有收到失敗節(jié)點(diǎn)的 PONG 消息捺典,此時判定它為 pfail 。pfail 即部分失敗从祝,它是一種中間狀態(tài)襟己,該狀態(tài)隨著集群心跳不斷傳播。再經(jīng)過一半 cluster-node-timeout 時間后牍陌,所有節(jié)點(diǎn)都與失敗的節(jié)點(diǎn)發(fā)生過心跳并且把它標(biāo)記為 pfail 擎浴。當(dāng)然也可能不需要這么長時間,因?yàn)槠渌?jié)點(diǎn)之間的心跳同樣會傳遞 pfail 狀態(tài)毒涧,這里姑且以最大時間計算退客。
Redis Cluster 規(guī)定當(dāng)集群中超過一半以上節(jié)點(diǎn)認(rèn)為一個節(jié)點(diǎn)為 pfail 狀態(tài)時,會把它標(biāo)記為 fail 狀態(tài)链嘀,并廣播給其他所有節(jié)點(diǎn)。對于每個節(jié)點(diǎn)而言平均一秒鐘收到一個心跳包档玻,每次心跳都會攜帶隨機(jī)的十分之一的節(jié)點(diǎn)個數(shù)怀泊。所以現(xiàn)在問題抽像為經(jīng)過多長時間一個節(jié)點(diǎn)會積累到一半的 pfail 狀態(tài)數(shù)。這是一個概率問題误趴,因?yàn)閭€人并不擅長概率計算霹琼,這里直接取了一個較大概率能滿足條件的數(shù)值 10。
所以上述公式不是達(dá)到這么長時間一定會判定節(jié)點(diǎn)為 fail,而是經(jīng)過這么長時間集群有很大概率會判定節(jié)點(diǎn) fail 枣申。
Redis Cluster 默認(rèn) cluster-node-timeout 為 15s售葡,我們將它設(shè)置成了 30s。也就是說 700 節(jié)點(diǎn)的集群忠藤,集群間帶寬開銷為 104.5MBit / s挟伙,判定節(jié)點(diǎn)失敗時間窗口大概為 55s,實(shí)際上大多數(shù)情況都小于 55s模孩,因?yàn)樯线叺挠嬎愣际前凑崭呶粫r間估算的尖阔。
總而言之,對于大的 Redis 集群 cluster-node-timeout 參數(shù)的需要謹(jǐn)慎設(shè)定榨咐。
提高 Redis 集群吞吐的方法
- 控制主節(jié)點(diǎn)寫命令傳播
Redis 中主節(jié)點(diǎn)的每個寫命令傳播到以下三個地方:
本地 AOF 文件介却,以持久化持?jǐn)?shù)據(jù)
主節(jié)點(diǎn)的所有從節(jié)點(diǎn),以保持主從數(shù)據(jù)同步
本節(jié)點(diǎn)的 repl_backlog 緩存块茁,主要為了支持部分同步功能齿坷,詳見官網(wǎng) Replcation 文檔 Partial resynchronization 部分:http://redis.io/topics/replication
其中 repl_backlog 部分傳播在 replicationFeedSlaves 函數(shù)中完成。
減少從節(jié)點(diǎn)的數(shù)量
高可用的集群不應(yīng)該出現(xiàn)單點(diǎn)数焊,所以 Redis 集群一般都會是主從模式永淌。Redis 的主從同步機(jī)制是所有的主節(jié)點(diǎn)的寫請求,會同步到所有的從節(jié)點(diǎn)昌跌。如果沒有從節(jié)點(diǎn)仰禀,對于主節(jié)點(diǎn)來說,它只需要處理該請求即可蚕愤。但對于有 N 個從節(jié)點(diǎn)的主節(jié)點(diǎn)來說答恶,它需要額外的將請求傳播給 N 個從節(jié)點(diǎn)。請注意這里是對于每個寫請求都會這樣處理萍诱。顯而易見從節(jié)點(diǎn)的數(shù)量對主節(jié)點(diǎn)的吞吐量的影響是比較大的悬嗓,我們采用的是一主一從模式。
因?yàn)閺墓?jié)點(diǎn)不需要同步數(shù)據(jù)裕坊,生產(chǎn)環(huán)境中觀察主節(jié)點(diǎn)的 CPU 占用率要比從節(jié)點(diǎn)機(jī)器要高包竹,這對這條結(jié)論起到了佐證的作用。
關(guān)閉 AOF 功能
如果開啟 AOF 功能籍凝,每個寫請求都會 Append 到本地 AOF 文件中周瞎,雖然 Linux 中寫文件操作會利用到操作系統(tǒng)緩存機(jī)制,但是如果關(guān)閉 AOF 功能主線程中省去了寫 AOF 文件的操作饵蒂,顯然會對吞吐量的增加有幫助声诸。
AOF 是 Redis 的一種持久化方式,如果關(guān)閉了 AOF 功能怎么保證數(shù)據(jù)的安全性退盯。我們的做法是定時在從節(jié)點(diǎn) BGSAVE彼乌。當(dāng)然具體采用何種策略需要結(jié)合具體情況來決定泻肯。
去掉頻繁的 Cluster nodes 命令
在運(yùn)維過程中發(fā)現(xiàn)前端請求的平均 RT 增加不少,大概 50% 左右慰照。通過一番調(diào)研灶挟,發(fā)現(xiàn)是頻繁的 cluster nodes 命令導(dǎo)致。
當(dāng)時集群規(guī)模為 500+ 節(jié)點(diǎn)毒租,cluster nodes 命令返回的結(jié)果大小有 103KB稚铣。cluster nodes 命令的頻率為:每隔 20s 向集群所有節(jié)點(diǎn)發(fā)送。
提高 Redis 集群吞吐的方法
- 調(diào)優(yōu) hz 參數(shù)
Redis 會定時做一些任務(wù)蝌衔,任務(wù)頻率由 hz 參數(shù)規(guī)定榛泛,定時任務(wù)主要包含:
主動清除過期數(shù)據(jù)
對數(shù)據(jù)庫進(jìn)行漸式Rehash
處理客戶端超時
更新請求統(tǒng)計信息
發(fā)送集群心跳包
發(fā)送主從心跳
以下是作者對于 hz 參數(shù)的介紹:

我們沒有修改 hz 參數(shù)的經(jīng)驗(yàn),由于其復(fù)雜性噩斟,并且在 hz 默認(rèn)值 10 的情況下曹锨,理論上不會對 Redis 吞吐量產(chǎn)生太大影響,建議沒有經(jīng)驗(yàn)的情況下不要修改該參數(shù)剃允。
參考資料
關(guān)于 Redis Cluster 可以參考官方的兩篇文檔:
Redis cluster tutorial: http://www.redis.io/topics/cluster-tutorial
Redis Cluster specification: http://www.redis.io/topics/cluster-spec
