<h3>簡介</h3>
Kafka是一個分布式的流平臺调违。這意味著什么?
我們認(rèn)為流平臺有3個核心的能力
- 允許發(fā)布和訂閱記錄流沈矿。在這方面類似消息隊列和企業(yè)級的消息系統(tǒng)惦辛。
- 允許以容錯的方式存儲記錄流。
- 允許以流的形式處理記錄悦穿。
Kafka擅長于做什么攻礼?
它被用于兩大類應(yīng)用:
- 在應(yīng)用間構(gòu)建實(shí)時的數(shù)據(jù)流通道
- 構(gòu)建傳輸或處理數(shù)據(jù)流的實(shí)時流式應(yīng)用
幾個概念:
- Kafka以集群模式運(yùn)行在1或多臺服務(wù)器上
- Kafka以topics的形式存儲數(shù)據(jù)流
- 每一個記錄包含一個key、一個value和一個timestamp
Kafka有4個核心API:
- Producer API:用于應(yīng)用程序?qū)?shù)據(jù)流發(fā)送到一個或多個Kafka topics
- Consumer API:用于應(yīng)用程序訂閱一個或多個topics并處理被發(fā)送到這些topics中的數(shù)據(jù)
- Streams API:允許應(yīng)用程序作為流處理器栗柒,處理來自一個或多個topics的數(shù)據(jù)并將處理結(jié)果發(fā)送到一個或多個topics中礁扮,有效的將輸入流轉(zhuǎn)化為輸出流
- Connector API:用于構(gòu)建和運(yùn)行將Kafka topics和現(xiàn)有應(yīng)用或數(shù)據(jù)系統(tǒng)連接的可重用的produers和consumers。例如瞬沦,如鏈接到關(guān)系數(shù)據(jù)庫的連接器可能會捕獲某個表所有的變更
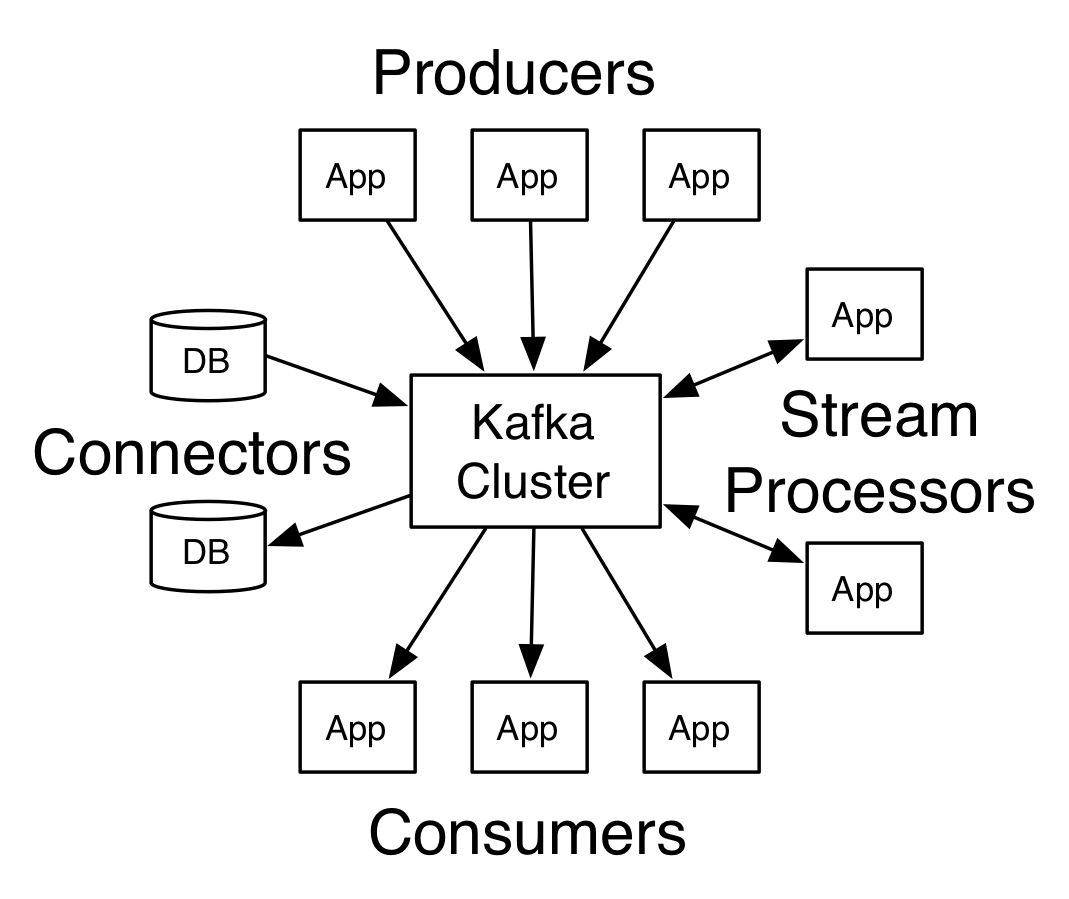
Kafka客戶端和服務(wù)端之間的通信是建立在簡單的太伊、高效的、語言無關(guān)的TCP協(xié)議上的逛钻。此協(xié)議帶有版本且向后兼容僚焦。我們?yōu)镵afka提供了Java客戶端,但是客戶端可以使用多種語言绣的。
<h4>Topics and Logs</h4>
Topic是發(fā)布記錄的類別叠赐。Kafka中的Topics一般是多訂閱者的,也就是一個Topic可以有0個或多個Consumer訂閱它的數(shù)據(jù)屡江。
對于每個主題芭概,Kafka會會維護(hù)一個如下所示的分區(qū)日志:
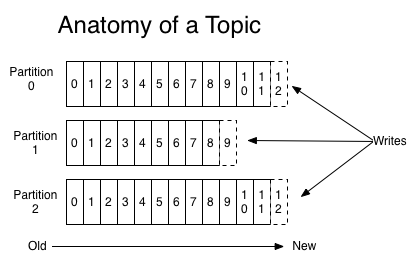
每個分區(qū)是一個有序的,以不可變的記錄順序追加的Commit Log惩嘉。分區(qū)中的每個記錄都有一個連續(xù)的ID罢洲,稱為Offset,唯一標(biāo)識分區(qū)內(nèi)的記錄。
Kafka集群使用記錄保存時間的配置來保存所有已發(fā)布的記錄(無論他們是否被消費(fèi))惹苗。例如殿较,配置策略為兩天,那么在一條記錄發(fā)布兩天內(nèi)桩蓉,這條記錄是可以被消費(fèi)的淋纲,之后將被丟棄以騰出空間。Kafka的性能和數(shù)據(jù)量無關(guān)院究,所以存儲長時間的數(shù)據(jù)并不會成為問題洽瞬。
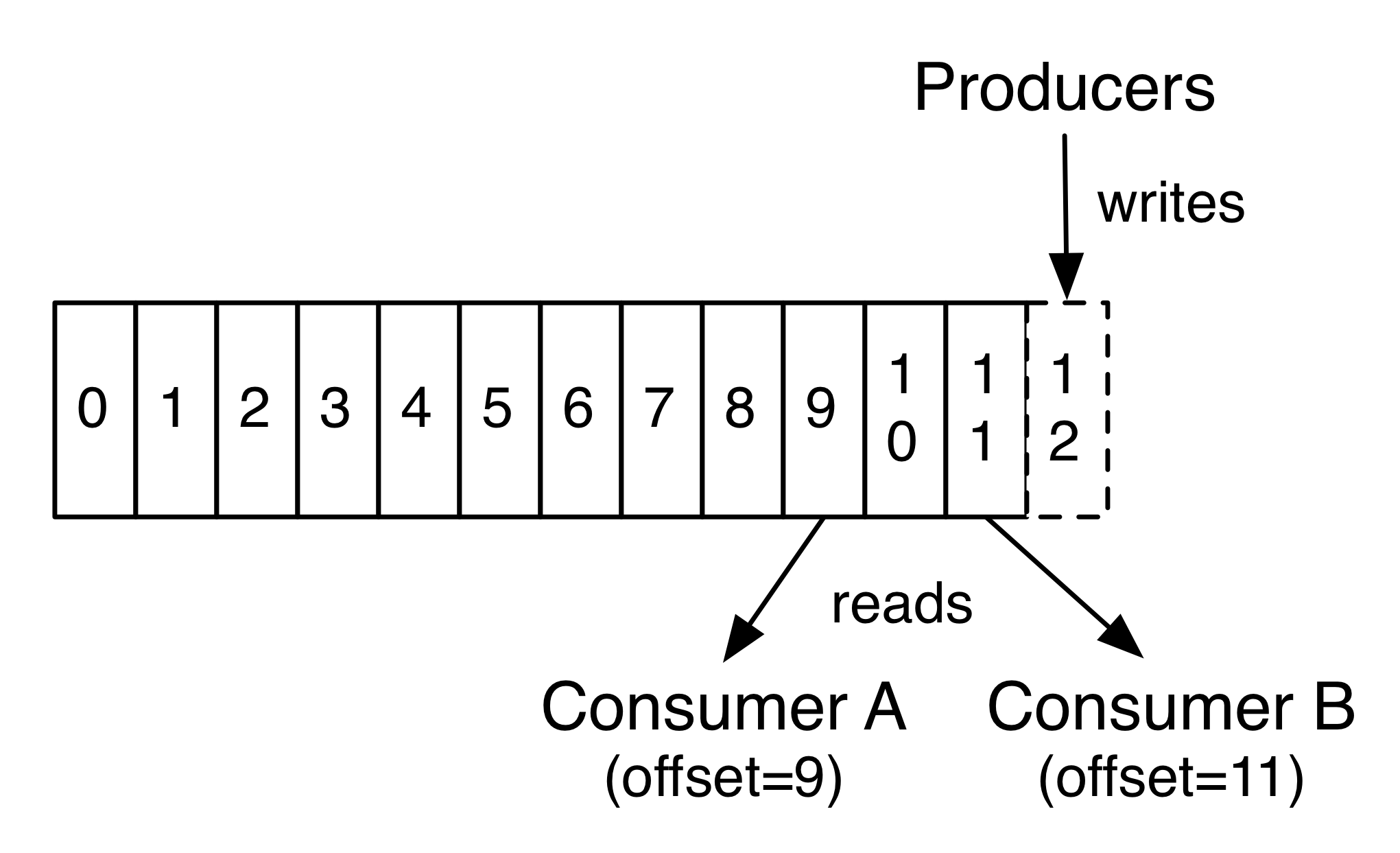
實(shí)際上唯一需要保存的元數(shù)據(jù)是消費(fèi)者的消費(fèi)進(jìn)度,即消費(fèi)日志的偏移量(Offset)业汰。這個Offset是由Consumer控制的:通常消費(fèi)者會在讀取記錄時以線性方式提升Offset伙窃,但是事實(shí)上,由于Offset由Consumer控制样漆,因此它可以以任何順序消費(fèi)記錄为障。例如一個Consumer可以通過重置Offset來處理過去的數(shù)據(jù)或者跳過部分?jǐn)?shù)據(jù)。
這個特征意味著Kafka的Consumer可以消費(fèi)“過去”和“將來”的數(shù)據(jù)而不對集群和其他Consumer不造成太大的影響放祟。例如鳍怨,可以使用命令行工具tail來獲取Topic尾部的內(nèi)容而不對已經(jīng)在消費(fèi)Consumer造成影響。
分區(qū)日志有幾個目的舞竿。第一京景,使服務(wù)器能承載日志的大小,每個分區(qū)的日志必須可以被保存在單個服務(wù)器上骗奖,但是一個Topic可以擁有多個分區(qū)确徙,那么它可以處理任意大小的數(shù)據(jù)量。第二执桌,它們作為并行度的單位(更多的是這點(diǎn)的考慮)鄙皇。
<h4>Distribution</h4>
分區(qū)日志分布在集群中服務(wù)器中,每個服務(wù)器處理一部分分區(qū)的數(shù)據(jù)和請求仰挣。每個分區(qū)可以配置分布的服務(wù)器伴逸,以實(shí)現(xiàn)容錯。
每個分區(qū)擁有一個Leader節(jié)點(diǎn)膘壶,和零或多個Follower错蝴。Leader處理該分區(qū)所有的讀寫請求,F(xiàn)ollower復(fù)制Leader數(shù)據(jù)颓芭。如果Leader節(jié)點(diǎn)宕機(jī)顷锰,將會有一個Follower節(jié)點(diǎn)自動的轉(zhuǎn)化為Leader。每個節(jié)點(diǎn)成為其部分分區(qū)的Leader亡问,并成為剩余分區(qū)的Follower官紫,這樣整個集群的負(fù)載將比較均衡。
<h4>Producers</h4>
Producer發(fā)送數(shù)據(jù)到它選擇的Topic。Producer負(fù)責(zé)決定將數(shù)據(jù)發(fā)送到Topic的那個分區(qū)上束世。這可以通過簡單的循環(huán)方式來平衡負(fù)載酝陈,或則可以根據(jù)某些語義來決定分區(qū)(例如基于數(shù)據(jù)中一些關(guān)鍵字)。
<h4>Consumers</h4>
Consumer使用一個group name來標(biāo)識自己的身份毁涉,每條被發(fā)送到一個Topic的消息都將被分發(fā)到屬于同一個group的Consumer的一個實(shí)例中(group name相同的Consumer屬于一個組沉帮,一個Topic的一條消息會被這個組中的一個Consumer實(shí)例消費(fèi))。Consumer實(shí)例可以在單獨(dú)的進(jìn)程中或者單獨(dú)的機(jī)器上薪丁。
如果所有的Consumer實(shí)例都是屬于一個group的遇西,那么所有的消息將被均衡的分發(fā)給每個實(shí)例馅精。
如果所有的Consumer都屬于不同的group严嗜,那么每條消息將被廣播給所有的Consumer。
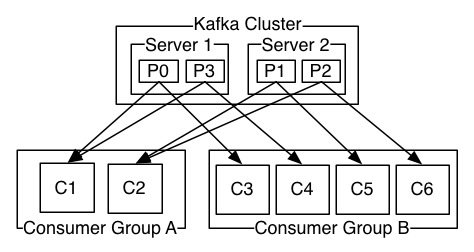
(上圖)一個包含兩個Server的Kafka集群洲敢,擁有四個分區(qū)(P0-P3)漫玄,有兩個Consumer group:Group A和Group B。Group有C1压彭、C2兩個Consumer睦优,GroupB有C3、C4壮不、C5汗盘、C6四個Consumer。
更常見的是询一,Topic有少量的Consumer group隐孽,每一個都是“一個邏輯上的訂閱者”。每個group包含多個Consumer實(shí)例健蕊,為了可伸縮性和容錯性菱阵。這就是一個發(fā)布-訂閱模式,只是訂閱方是一個集群缩功。
Kafka中消費(fèi)的實(shí)現(xiàn)方式是“公平”的將分區(qū)分配給Consumer晴及,每一個時刻分區(qū)都擁有它唯一的消費(fèi)者。Consumer成員關(guān)系有Kafka程度動態(tài)維護(hù)嫡锌。如果新的Consumer加入了分區(qū)虑稼,那么它會從這個分區(qū)其他的Consumer中分配走一部分分區(qū);如果部分Consumer實(shí)例宕機(jī)势木,它的分區(qū)會被其他Consumer實(shí)例接管蛛倦。
Kafka只保證同一個分區(qū)內(nèi)記錄的順序,而不是同一個Topic的不同分區(qū)間數(shù)據(jù)的順序跟压。每個分區(qū)順序結(jié)合按Key分配分區(qū)的能力胰蝠,能滿足大多數(shù)程序的需求。如果需要全局的順序,可以使用只有一個分區(qū)的Topic茸塞,這意味著每個group只能有一個Consumer實(shí)例(因為一個分區(qū)同一時刻只能被一份Consumer消費(fèi)——多加的Consumer只能用于容錯)躲庄。
<h4>Guarantees</h4>
Kafka高級API中提供一些能力:
被一個Producer發(fā)送到特定Topic分區(qū)的消息將按照他們的發(fā)送順序被添加到日志中。這意味著钾虐,如果M1噪窘、M2是被同一個Producer發(fā)送出來的,且M1先發(fā)送效扫,那么M1擁有更小的Offset倔监,在日志中的位置更靠前。
Consumer按照消息的存儲順序在日志文件中查找消息菌仁。
對于復(fù)制配置參數(shù)為N的Topic浩习,我們能容忍N(yùn)-1的服務(wù)器故障,而不會丟失已經(jīng)Commit的數(shù)據(jù)济丘。有關(guān)這些保證更詳細(xì)的信息谱秽,參見文檔的設(shè)計部分。
<h4>Kafka as a Messaging System</h4>
Kafka的流模式和傳統(tǒng)的消息系統(tǒng)有什么區(qū)別摹迷?
消息傳統(tǒng)上有兩種模式:隊列和發(fā)布-訂閱疟赊。在隊列中,一群Consumer從一個Server讀取數(shù)據(jù)峡碉,每條消息被其中一個Consumer讀取近哟。在發(fā)布-訂閱中,消息被廣播給所有的Consumer鲫寄。這兩種模式有各自的優(yōu)缺點(diǎn)吉执。隊列模式的優(yōu)點(diǎn)是你可以在多個消費(fèi)者實(shí)例上分配數(shù)據(jù)處理,從而允許你對程序進(jìn)行“伸縮”塔拳。確定是隊列不是多用戶的鼠证,一旦消息被一個Consumer讀取就不會再給其他Consumer。發(fā)布訂閱模式允許廣播數(shù)據(jù)到多個Consumer靠抑,那么就沒辦法對單個Consumer進(jìn)行伸縮量九。
Kafka的Consumer group包含兩個概念。與隊列一樣颂碧,消費(fèi)組允許通過一些進(jìn)程來劃分處理(每個進(jìn)程處理一部分)荠列。與發(fā)布訂閱一樣,Kafka允許廣播消息到不同的Consumer group载城。
Kafka模式的優(yōu)勢是每個Topic都擁有隊列和發(fā)布-訂閱兩種模式肌似。
Kafka比傳統(tǒng)的消息系統(tǒng)有更強(qiáng)的順序保證。
傳統(tǒng)的消息系統(tǒng)在服務(wù)器上按順序保存消息诉瓦,如果多個Consumer從隊列中消費(fèi)消息川队,服務(wù)器按照存儲的順序輸出消息力细。然后服務(wù)器雖然按照順序輸出消息,但是消息將被異步的傳遞給Consumer固额,所以他們將以不確定的順序到達(dá)Consumer眠蚂。這意味著在并行消費(fèi)中將丟失消息順序。傳統(tǒng)消息系統(tǒng)通常采用“唯一消費(fèi)者”的概念只讓一個Consumer進(jìn)行消費(fèi)斗躏,但這就丟失了并行處理的能力逝慧。
Kafka做的更好一些。通過提供分區(qū)的概念啄糙,Kafka能提供消費(fèi)集群順序和負(fù)載的平衡笛臣。這是通過將分區(qū)分配個一個Consumer group中唯一的一個Consumer而實(shí)現(xiàn)的,一個分區(qū)只會被一個分組中的一個Consumer進(jìn)行消費(fèi)隧饼。通過這么實(shí)現(xiàn)沈堡,能讓一個Consumer消費(fèi)一個分區(qū)并按照順序處理消息。因為存在多個分區(qū)桑李,所有可以在多個Consumer實(shí)例上實(shí)現(xiàn)負(fù)載均衡踱蛀。注意,一個分組內(nèi)的Consumer實(shí)例數(shù)不能超過分區(qū)數(shù)贵白。
<h4>Kafka as a Storage System</h4>
任何將發(fā)送消息和消費(fèi)結(jié)構(gòu)的消息隊列都有效的用作一個消息的存儲系統(tǒng)。不同的是Kafka是一個更好的存儲系統(tǒng)禁荒。
被寫入到Kafka的數(shù)據(jù)將被寫入磁盤并復(fù)制以保證容錯。Kafka允許Producer等待確定角撞,以保證Producer可以確認(rèn)消息被成功持久化并復(fù)制完成呛伴。
Kafka使用的存儲結(jié)構(gòu),使其提供相同的能力谒所,無論是存儲50KB或者50TB持久化數(shù)據(jù)热康。
因為允許客戶端控制讀取的位置,可以將Kafka視為高性能劣领,低延遲的日志存儲姐军、復(fù)制、傳播的分布式系統(tǒng)尖淘。
<h4>Kafka for Stream Processing</h4>
僅僅是讀寫和存儲流數(shù)據(jù)是不夠的奕锌,Kafka的目標(biāo)是對流失數(shù)據(jù)的實(shí)時處理。
在Kafka中村生,Stream Producer從輸入的Topic中讀取數(shù)據(jù)惊暴,執(zhí)行一些操作,生成輸出流到輸出的Topic中趁桃。
例如辽话,零售的應(yīng)用程序?qū)⑹盏戒N售和出貨的輸入流肄鸽,并輸出根據(jù)該數(shù)據(jù)計算的重排序和價格調(diào)整后的數(shù)據(jù)流。
可以使用Producer和Consumer實(shí)現(xiàn)簡單的處理油啤。對于更復(fù)雜的轉(zhuǎn)換贴捡,Kafka提供的完成的Stream API,允許構(gòu)建將流中數(shù)據(jù)聚合或?qū)⒘鬟B接到一起的應(yīng)用村砂。
這用于解決以下的一些困難:處理無需的數(shù)據(jù)烂斋,執(zhí)行有狀態(tài)的計算等。
Stream API基于Kafka的核心函數(shù)古劍:使用Producer和Consumer API用于輸入础废,使用Kafka作為有狀態(tài)的存儲汛骂,使用group機(jī)制來實(shí)現(xiàn)Stream處理器的容錯。
<h4>Putting the Pieces Together</h4>
消息评腺、存儲和流處理這種組合看是不尋常帘瞭,但是Kafka作為流式平臺這是必須的。
類似HDFS的分布式文件系統(tǒng)存儲靜態(tài)的文件用于批處理蒿讥。這種的系統(tǒng)允許存儲和處理歷史數(shù)據(jù)蝶念。
傳統(tǒng)的企業(yè)消息系統(tǒng)允許處理在你訂閱之后的未來的數(shù)據(jù)口芍。以這種方式構(gòu)建的應(yīng)用程序在未來數(shù)據(jù)到達(dá)時進(jìn)行處理盈罐。
Kafka組合這些能力,并且組合這些對Kafka作為流應(yīng)用平臺和流數(shù)據(jù)通道至關(guān)重要郭宝。
通過組合存儲和低延遲的訂閱摔敛,流應(yīng)用程序能以相同的方式處理過去和未來的數(shù)據(jù)廷蓉。一個單一的程序可以處理過去的歷史數(shù)據(jù),并且不會在達(dá)到一個位置時停止马昙,而是能繼續(xù)處理將來到達(dá)的數(shù)據(jù)桃犬。這是一個廣泛的流處理的概念,其中包含批處理和消息驅(qū)動的應(yīng)用程序行楞。
同樣攒暇,對于數(shù)據(jù)流通道,組合訂閱機(jī)制和實(shí)時事件使Kafka成為非常低延遲的管道子房;數(shù)據(jù)的存儲能力使其能和可能會進(jìn)行停機(jī)維護(hù)的周期性處理數(shù)據(jù)的離線系統(tǒng)集成形用,或用于必須保證數(shù)據(jù)被確認(rèn)交付的場景。流處理程序可以在數(shù)據(jù)到達(dá)后進(jìn)行處理池颈。
其他關(guān)于Kafka提供的API尾序、功能,參閱其他文檔躯砰。
