序言(初衷)
設(shè)計該系統(tǒng)初衷是基于描繪業(yè)務(wù)(或機器集群)存儲模型腐魂,分析代理緩存服務(wù)器磁盤存儲與回源率的關(guān)系帐偎。系統(tǒng)意義是在騰訊云成本優(yōu)化過程中,量化指導機房設(shè)備擴容挤渔。前半部分是介紹背景肮街,對CDN緩存模型做一些理論思考。后半部分會實際操作搭建一個微型但是五臟俱全的分布式通用系統(tǒng)架構(gòu)判导,最后賦予該系統(tǒng)一些跟背景相關(guān)的功能嫉父,解決成本優(yōu)化中遇到的實際問題。
緩存服務(wù)器存儲模型架構(gòu)(背景):

圖1 存儲模型
騰訊CDN的線上路由是用戶à分布于各地區(qū)各運營商的OC->SOC->SMid->源站眼刃。各個層級節(jié)點部署的都是緩存服務(wù)器绕辖。來自用戶的部分請求流量命中服務(wù)器,另一部分產(chǎn)生回源流量擂红。
隨著業(yè)務(wù)帶寬自然增長仪际,用戶端帶寬增長,假設(shè)業(yè)務(wù)回源率不變的情況下昵骤,磁盤緩存淘汰更新(淘汰)速率變快树碱,表現(xiàn)為以下業(yè)務(wù)瓶頸(iowait變高、回源帶寬變高变秦,由于磁盤空間大小受限的緩存淘汰導致回源率變高)成榜。
為了說明這個原理。我們假設(shè)兩個極端:一個是設(shè)備磁盤容量無限大蹦玫,業(yè)務(wù)過來的流量緩存只受源站緩存規(guī)則受限赎婚。只要緩存沒過期,磁盤可以無限緩存樱溉,回源流量只需要首次訪問的流量挣输,所以這個回源量(率)只跟業(yè)務(wù)特性(重復率)有關(guān)系。另一個極端是磁盤極限懈U辍(歸零)撩嚼,那么無論業(yè)務(wù)設(shè)置緩存是否過期,客戶端訪問量都是1比1的回源量。假設(shè)業(yè)務(wù)平均的緩存周期是1個小時绢馍。那么這1個小時的首次緩存帶寬(同一cache key的多次訪問向瓷,我們認為是一次)將是這個硬盤的所需要的空間。這個大小是合理的舰涌,可以保證磁盤足夠容納業(yè)務(wù)的量。假設(shè)這個量達不到你稚,或者本來達到了瓷耙,但是由于業(yè)務(wù)自然增長了,1個小時內(nèi)地首次緩存帶寬變多刁赖,硬盤空間也不夠用搁痛。
設(shè)備擴容是個解決辦法。但是壓測系統(tǒng)在這之前宇弛,沒有客觀數(shù)據(jù)證明需要擴容多大設(shè)備鸡典。或者擴容多少設(shè)備沒有進行灰度驗證枪芒,設(shè)備到位拍腦袋直接線上部署機器彻况。我們在實驗機器進行線上日志的重放,模擬出存儲模擬曲線舅踪,來指導線上機房合理的設(shè)備存儲纽甘。這就是建設(shè)重放日志系統(tǒng)的意義。
麻雀雖小抽碌,五臟俱全的重放日志模型(總覽)
這一章悍赢,我們定義了下列模塊:
模擬日志服務(wù)器:下載線上某個機房的一段時間周期的訪問日志。一個日志存放10分鐘訪問記錄货徙。機房有幾臺機器就下載幾份日志左权。日志服務(wù)器同時提供任務(wù)分片信息的查詢服務(wù)。假設(shè)我們需要重放任務(wù)id為pig_120t的任務(wù)切片痴颊。下圖既為任務(wù)切片詳情赏迟。

圖2 日志服務(wù)器的日志分片文件
任務(wù)控制器:啟動任務(wù)或者結(jié)束任務(wù)總開關(guān)。任務(wù)分配均勻分配給具體的肉雞和代理服務(wù)器祷舀。插入任務(wù)到Task Pool中瀑梗,收集服務(wù)端的實時總流量、回源流量裳扯、總請求次數(shù)和回源次數(shù)數(shù)據(jù)并插入到回源率結(jié)果數(shù)據(jù)表抛丽。
肉雞:輪詢Task Pool的任務(wù)表。如果有任務(wù)饰豺,則按照任務(wù)明細(時間亿鲜、線上機房ip)向日志服務(wù)器請求下載該分片的日志。重放請求到指定的代理服務(wù)器。
代理服務(wù)端:提供實時回源數(shù)據(jù)查詢服務(wù)蒿柳。并且安裝nws緩存服務(wù)器等組件饶套,該機器等同于線上機房的軟件模塊。
實時展示界面:可隨時查看實時回源率和一些任務(wù)異常狀態(tài)信息垒探。
圖3為客戶端和服務(wù)端的互動圖妓蛮。圖4是任務(wù)控制端在任務(wù)進行中和其他模塊的聯(lián)動過程。
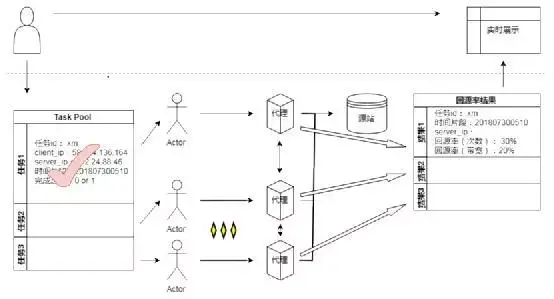
圖3 肉雞和代理服務(wù)端的架構(gòu)

圖4 控制端的任務(wù)聯(lián)動過程
分布式系統(tǒng)特點
日志重放模型核心是一個高性能壓測系統(tǒng)圾叼,但是需要添加一些邏輯:日志下載蛤克、日志分析重構(gòu)、結(jié)果數(shù)據(jù)收集夷蚊、數(shù)據(jù)上報展示构挤。分布式系統(tǒng)核心是:是否做到了可拓展、可恢復惕鼓、簡易搭建筋现、容錯、自動化箱歧。以下內(nèi)容會一一展開矾飞。
先說說高性能:在一個通用模型中。我們模擬線上日志叫胁,這個系統(tǒng)要做到高效凰慈、因為我們的重放日志速度要比線上的qps還要快。機器的重放速度決定了分析結(jié)果的速度驼鹅。同時更快的速度微谓,所需要的肉雞資源更少。筆者在python各個url請求庫和golang中输钩,最終敲定使用了golang實現(xiàn)肉雞豺型。golang做到了和原生c+epoll一樣快的速度,但是代碼實現(xiàn)容易多了买乃。理論上我們對一臺做過代理端性能瓶頸分析姻氨。線上日志比模擬日志更復雜,qps適度下降是必然的剪验。Golang這個客戶端達到預期目標肴焊。
可擴展:在我們可能會隨時增加模擬機器集群的肉雞數(shù)量,或者更多的閑置代理服務(wù)器資源加入壓測任務(wù)功戚。所以系統(tǒng)在可用機器數(shù)據(jù)表隨時加入新的機器娶眷。

圖5 系統(tǒng)的動態(tài)可擴展
可恢復:分布式系統(tǒng)不同于單機模式。不能避免可能有各種故障啸臀,有時候系統(tǒng)部分節(jié)點出錯了届宠,我們更傾向于不用這個節(jié)點,而不是繼續(xù)使用未處理完成的結(jié)果。即非0即1豌注,無中間狀態(tài)伤塌。還有分布式系統(tǒng)網(wǎng)絡(luò)傳輸延遲不可控。所以壓測系統(tǒng)設(shè)計了一套容錯機制:包括心跳檢測失敗轧铁,自動在數(shù)據(jù)表剔除肉雞服務(wù)端每聪。接口異常容錯。超時過期未完成任務(wù)去除齿风。crontab定時拉取退出進程等熊痴。
簡易搭建:使用ajs接口,和批處理安裝腳本聂宾。自動化部署肉雞和服務(wù)端。配置dns解析ip(日志服務(wù)器诊笤,任務(wù)池系谐、回源率結(jié)果所在的數(shù)據(jù)庫ip),tcp time_wait狀態(tài)的復用讨跟,千萬別忘了還有一些系統(tǒng)限制放開(放開ulimit fd limit纪他,這里設(shè)置100000,永久設(shè)置需要編輯/etc/security/limits.conf)晾匠。如果肉雞有依賴程序運行庫需要同時下載茶袒。在肉雞機器下載肉雞客戶端和配置、在服務(wù)端機器下載服務(wù)端和配置凉馆,下載定時拉起程序腳本薪寓,并添加到crontab定時執(zhí)行。以上都用批處理腳本自動執(zhí)行澜共。
一些設(shè)計范式的思考
Single-productor and Multi-consumer
在肉雞客戶端的設(shè)計中:讀日志文件一行一條記錄向叉,添加到消息管道,然后多個執(zhí)行worker從消息管道取url嗦董,執(zhí)行模擬請求母谎。消息管道傳送的是一條待執(zhí)行的日志url。IO消耗型程序指的是如果consumer執(zhí)行訪問日志并瞬間完成結(jié)果京革,但是productor需要對日志進行復雜的字符串處理(例如正則之類的)奇唤,那么它下次取不到數(shù)據(jù),就會被管道block住匹摇。另外一種是CPU消耗型程序咬扇,如果日志url已經(jīng)預先處理好了,productor只是簡單的copy數(shù)據(jù)給消息管道来惧。而consumer訪問url冗栗,經(jīng)過不可預知的網(wǎng)絡(luò)延遲。那么多個consumer(因為是包括網(wǎng)絡(luò)訪問時間,consumer個數(shù)設(shè)計超過cpu核數(shù)隅居,比如2倍)同時訪問钠至,讀端速度慢于寫端數(shù)度。在對一個日志文件進行實驗胎源,我們發(fā)現(xiàn)處理18w條記錄日志的時間是0.3s棉钧,而執(zhí)行完這些url的訪問任務(wù)則需要3分鐘。那么很顯然這是一個CPU消耗性進程涕蚤。如果是IO消耗型的程序宪卿。Golang有種叫fan out的消息模型。我們可以這樣設(shè)計:多個讀端去讀取多個chan list的chan万栅,一個寫端寫一個chan佑钾。Fanou
Map-reduce
們有時會做一個地理位置一個運營商的機房日志分析。一個機房包含數(shù)臺機器ip烦粒。合理的調(diào)度多個肉雞客戶端并行訪問日志休溶,可以更快速得到合并回源率數(shù)據(jù)。
并行機制扰她,經(jīng)典的map-reduce兽掰,日志文件按機房機器ip緯度切片分發(fā)任務(wù),啟動N個肉雞同時并行訪問徒役,等最后一臺肉雞完成任務(wù)時孽尽,歸并各個肉雞數(shù)據(jù)按成功請求數(shù)量、成功請求流量忧勿、失敗請求數(shù)量杉女、失敗請求流量等方式做統(tǒng)計。同時用于和線上日志做校樣狐蜕。這里的mapper就是肉雞宠纯,產(chǎn)生的數(shù)據(jù)表,我們按照關(guān)注的類型去提取就是reducer层释。
簡化的map-reducer(不基于分布式文件系統(tǒng))婆瓜,map和reduce中間的數(shù)據(jù)傳遞用數(shù)據(jù)表實現(xiàn)焊虏。每個mapper產(chǎn)生的日志數(shù)據(jù)先放在本地蟀瞧,然后再上報給數(shù)據(jù)表。但是數(shù)據(jù)表大小的限制乖菱,我們只能上傳頭部訪問url乖寒。所以如果用這個辦法實現(xiàn)猴蹂,數(shù)據(jù)是不完整的,或者不完全正確的數(shù)據(jù)楣嘁。因為也許兩臺肉雞合并的頭部數(shù)據(jù)正好就包括了某肉雞未上傳的日志(該日志因為沒有到達單機肉雞訪問量top的標準)磅轻。
那么如何解決這個問題呢珍逸,根本原因在于匯總數(shù)據(jù)所在的文件系統(tǒng)是本地的,不是分布式的(hadoop的hdfs大概就是基于這種需求發(fā)明的把)聋溜。如果是狀態(tài)碼緯度谆膳,這種思路是沒問題的,因為http狀態(tài)碼總量就那么少撮躁。那么如果是url緯度漱病,比如說某機房給單肉雞的單次任務(wù)在10分鐘的url總數(shù)據(jù)量達到18萬條。只看日志重復數(shù)>100的肉雞數(shù)據(jù)把曼。這樣誤差最大值是100*肉雞數(shù)杨帽,所以對于10臺肉雞的機房,只要是綜合合并結(jié)果>1000嗤军。都是可信任的注盈。如果是域名緯度,少數(shù)頭部客戶流量占比大多數(shù)帶寬叙赚。 這也就是所謂的hot-key当凡,少數(shù)的hot-key占據(jù)了大多數(shù)比例的流量。所以域名緯度時纠俭,這個時候可以把關(guān)注點縮放在指定域名的url列表。如果本地上報給數(shù)據(jù)表的數(shù)據(jù)量太大浪慌,url也可以考慮進行短地址壓縮冤荆。當然如果不想彎道超車的話,需要硬解決這個問題权纤,那可能得需要hdfs這種分布式文件系統(tǒng)钓简。
Stream-Processing
我們進行日志客戶端系統(tǒng),需要向日志服務(wù)器下載此次任務(wù)所需要的日志(一般是一個機器10分鐘的訪問日志)汹想。首先本地日志會去任務(wù)服務(wù)器查詢重放任務(wù)外邓。接著去日志服務(wù)器下載。如果該模擬集群是在DC網(wǎng)絡(luò)組建古掏,那么下載一個10分鐘(約150M左右的文件)日志幾乎在1兩秒內(nèi)搞定损话,但是如果這個分布式系統(tǒng)是組建于OC網(wǎng)絡(luò),那么OC網(wǎng)絡(luò)的肉雞服務(wù)器要去DC(考慮機房可靠性槽唾,日志服務(wù)器架設(shè)在DC網(wǎng)絡(luò))下載丧枪,經(jīng)過nat轉(zhuǎn)化內(nèi)網(wǎng)到外網(wǎng),下載則需要10s左右庞萍。如果為了等待日志服務(wù)器下載完拧烦,也是一筆時間開銷。
在分布式系統(tǒng)中钝计,所謂的stream-processing恋博,和batch processing不同的是齐佳,數(shù)據(jù)是無邊界的。你不知道什么時候日志下載完债沮。而batch processing的前后流程關(guān)系炼吴,好比生產(chǎn)流水線的工序,前一道完成秦士,后一道才開始缺厉,對于后一道是完全知道前一道的輸出結(jié)果有多少。
所謂的流式處理則需要在前一道部分輸出結(jié)果到達時隧土,啟動后一道工序提针,前一道工序繼續(xù)輸出,后一道則需要做出處理事件響應(yīng)曹傀。后一道需要頻繁調(diào)度程序辐脖。
消息系統(tǒng)(message broker):前一道的部分輸出,輸入給消息系統(tǒng)皆愉。消息系統(tǒng)檢測到是完整的一條日志嗜价,則可以產(chǎn)生后一道工序的輸入。這里我們會碰到一個問題幕庐。下載日志的速度(10s)會遠遠快于執(zhí)行重放這些日志的速度(3min)久锥。按照一個消息系統(tǒng)可能的動作是:無buffer則丟棄,按照隊列緩存住异剥,執(zhí)行流控同步后一道工序和前一道工序的匹配速度瑟由。這里我們選擇了按照隊列緩存住這個方案。當然在一個嚴謹?shù)姆植际綌?shù)據(jù)庫設(shè)計冤寿,message broker是一個能考率到數(shù)據(jù)丟失的節(jié)點歹苦。Broker會把完整數(shù)據(jù)發(fā)給后道工序,同時會把buffer數(shù)據(jù)緩存到硬盤備份督怜,以防程序core dump殴瘦。如果對于慢速前道工序,可以進行綜合方案配置号杠,丟棄或者流控蚪腋。這里消息broker不同于數(shù)據(jù)庫,他的中間未處理數(shù)據(jù)是暫時存儲姨蟋,處理過的消息要清除存儲辣吃。
總結(jié)
當然:現(xiàn)實中的生產(chǎn)線的分布式系統(tǒng)會遠比這個復雜,但是本文實現(xiàn)的從0到1的迷你麻雀分布式系統(tǒng)有一定的實踐意義芬探。它不是一蹴而就的神得,不斷地版本迭代。當然該系統(tǒng)也完成了作者的kpi-存儲模型分析偷仿,在中途遇到問題時哩簿,進行的設(shè)計思考和改良宵蕉,在此總結(jié)分享給大家。
