一恢恼、KNN算法概述
KNN是Machine Learning領(lǐng)域一個簡單又實用的算法民傻,與之前討論過的算法主要存在兩點不同:
- 它是一種非參方法。即不必像線性回歸厅瞎、邏輯回歸等算法一樣有固定格式的模型饰潜,也不需要去擬合參數(shù)初坠。
- 它既可用于分類和簸,又可應(yīng)用于回歸。
KNN的基本思想有點類似“物以類聚碟刺,人以群分”锁保,打個通俗的比方就是“如果你要了解一個人,可以從他最親近的幾個朋友去推測他是什么樣的人”半沽。
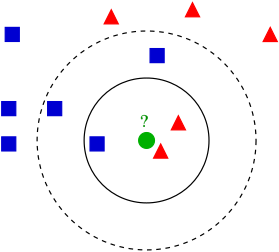
在分類領(lǐng)域爽柒,對于一個未知點,選取K個距離(可以是歐氏距離者填,也可以是其他相似度度量指標(biāo))最近的點浩村,然后統(tǒng)計這K個點,在這K個點中頻數(shù)最多的那一類就作為分類結(jié)果占哟。比如下圖心墅,若令K=4,則?處應(yīng)分成紅色三角形榨乎;若令K=6怎燥,則?處應(yīng)分類藍(lán)色正方形。
在回歸(簡單起見蜜暑,這里討論一元回歸)領(lǐng)域铐姚,如果只知道某點的預(yù)測變量$x$,要回歸響應(yīng)變量$y$肛捍,只需要在橫坐標(biāo)軸上(因為不知道縱坐標(biāo)的值隐绵,所以沒法計算歐氏距離)選取K個最近的點,然后平均(也可以加權(quán)平均)這些點的響應(yīng)值拙毫,作為該點的響應(yīng)值即可依许。比如下圖中,已知前5個點的橫縱坐標(biāo)值恬偷,求$x=6.5$時悍手,$y$為多少帘睦?若令K=2,則距6.5最近的2個點是(5.1, 8)和(4, 27)坦康,把這兩個點的縱坐標(biāo)平均值17.5就可以當(dāng)作回歸結(jié)果竣付,認(rèn)為$x=6.5時,y=17.5滞欠。$

KNN具體的算法步驟可參考延伸閱讀文獻(xiàn)1古胆。
二、KNN性能討論
KNN的基本思想與計算過程很簡單筛璧,你只需要考慮兩件事:
- K預(yù)設(shè)值取多少逸绎?
- 如何定義距離?
其中如何定義距離這個需要結(jié)合具體的業(yè)務(wù)應(yīng)用背景夭谤,本文不細(xì)致討論棺牧,距離計算方法可參看延伸閱讀文獻(xiàn)2。這里只討論K取值時對算法性能的影響朗儒。

在上圖中颊乘,紫色虛線是貝葉斯決策邊界線,也是最理想的分類邊界醉锄,黑色實線是KNN的分類邊界乏悄。
可以發(fā)現(xiàn):K越小,分類邊界曲線越光滑恳不,偏差越小檩小,方差越大;K越大烟勋,分類邊界曲線越平坦规求,偏差越大,方差越小神妹。
所以即使簡單如KNN颓哮,同樣要考慮偏差和方差的權(quán)衡問題,表現(xiàn)為K的選取鸵荠。
KNN的優(yōu)點就是簡單直觀冕茅,無需擬合參數(shù),在樣本本身區(qū)分度較高的時候效果會很不錯蛹找;但缺點是當(dāng)樣本量大的時候姨伤,找出K個最鄰近點的計算代價會很大,會導(dǎo)致算法很慢庸疾,此外KNN的可解釋性較差乍楚。
KNN的一些其他問題的思考可參看延伸閱讀文獻(xiàn)3。
三届慈、實戰(zhàn)案例
1徒溪、KNN在保險業(yè)中挖掘潛在用戶的應(yīng)用
這里應(yīng)用ISLR包里的Caravan數(shù)據(jù)集忿偷,先大致瀏覽一下:
> library(ISLR)
> str(Caravan)
'data.frame': 5822 obs. of 86 variables:
$ Purchase: Factor w/ 2 levels "No","Yes": 1 1 1 1 1 1 1 1 1 1 ...
> table(Caravan$Purchase)/sum(as.numeric(table(Caravan$Purchase)))
No Yes
0.94022673 0.05977327
5822行觀測,86個變量臊泌,其中只有Purchase是分類型變量鲤桥,其他全是數(shù)值型變量。Purchase兩個水平渠概,No和Yes分別表示不買或買保險茶凳。可見到有約6%的人買了保險播揪。
由于KNN算法要計算距離贮喧,這85個數(shù)值型變量量綱不同,相同兩個點在不同特征變量上的距離差值可能非常大猪狈。因此要歸一化箱沦,這是Machine Learning的常識。這里直接用scale()函數(shù)將各連續(xù)型變量進(jìn)行正態(tài)標(biāo)準(zhǔn)化罪裹,即轉(zhuǎn)化為服從均值為0饱普,標(biāo)準(zhǔn)差為1的正態(tài)分布运挫。
> standardized.X=scale(Caravan[,-86])
> mean(standardized.X[,sample(1:85,1)])
[1] -2.047306e-18
> var(standardized.X[,sample(1:85,1)])
[1] 1
> mean(standardized.X[,sample(1:85,1)])
[1] 1.182732e-17
> var(standardized.X[,sample(1:85,1)])
[1] 1
> mean(standardized.X[,sample(1:85,1)])
[1] -3.331466e-17
> var(standardized.X[,sample(1:85,1)])
[1] 1
可見隨機(jī)抽取一個標(biāo)準(zhǔn)化后的變量状共,基本都是均值約為0,標(biāo)準(zhǔn)差為1谁帕。
> #前1000觀測作為測試集峡继,其他當(dāng)訓(xùn)練集
> test <- 1:1000
> train.X <- standardized.X[-test,]
> test.X <- standardized.X[test,]
> train.Y <- Caravan$Purchase[-test]
> test.Y <- Caravan$Purchase[test]
> knn.pred <- knn(train.X,test.X,train.Y,k=)
> mean(test.Y!=knn.pred)
[1] 0.117
> mean(test.Y!="No")
[1] 0.059
當(dāng)K=1時,KNN總體的分類結(jié)果在測試集上的錯誤率約為12%匈挖。由于大部分的人都不買保險(先驗概率只有6%)碾牌,那么如果模型預(yù)測不買保險的準(zhǔn)確率應(yīng)當(dāng)很高,糾結(jié)于預(yù)測不買保險實際上卻買保險的樣本沒有意義儡循,同樣的也不必考慮整體的準(zhǔn)確率(Accuracy)舶吗。作為保險銷售人員,只需要關(guān)心在模型預(yù)測下會買保險的人中有多少真正會買保險择膝,這是精準(zhǔn)營銷的精確度(Precision)誓琼;因此,在這樣的業(yè)務(wù)背景中肴捉,應(yīng)該著重分析模型的Precesion腹侣,而不是Accuracy。
> table(knn.pred,test.Y)
test.Y
knn.pred No Yes
No 874 50
Yes 67 9
> 9/(67+9)
[1] 0.1184211
可見K=1時齿穗,KNN模型的Precision約為12%傲隶,是隨機(jī)猜測概率(6%)的兩倍!
下面嘗試K取不同的值:
> knn.pred <- knn(train.X,test.X,train.Y,k=3)
> table(knn.pred,test.Y)[2,2]/rowSums(table(knn.pred,test.Y))[2]
Yes
0.2
> knn.pred <- knn(train.X,test.X,train.Y,k=5)
> table(knn.pred,test.Y)[2,2]/rowSums(table(knn.pred,test.Y))[2]
Yes
0.2666667
可以發(fā)現(xiàn)當(dāng)K=3時窃页,Precision=20%跺株;當(dāng)K=5時复濒,Precision=26.7%。
作為對比乒省,這個案例再用邏輯回歸做一次芝薇!
> glm.fit <- glm(Purchase~.,data=Caravan,family = binomial,subset = -test)
Warning message:
glm.fit:擬合機(jī)率算出來是數(shù)值零或一
> glm.probs <- predict(glm.fit,Caravan[test,],type = "response")
> glm.pred <- ifelse(glm.probs >0.5,"Yes","No")
> table(glm.pred,test.Y)
test.Y
glm.pred No Yes
No 934 59
Yes 7 0
這個分類效果就差很多,Precision竟然是0作儿!事實上洛二,分類概率閾值為0.5是針對等可能事件,但買不買保險顯然不是等可能事件攻锰,把閾值降低到0.25再看看:
> glm.pred <- ifelse(glm.probs >0.25,"Yes","No")
> table(glm.pred,test.Y)
test.Y
glm.pred No Yes
No 919 48
Yes 22 11
這下子Precision就達(dá)到1/3了晾嘶,比隨機(jī)猜測的精確度高出5倍不止!
以上試驗都充分表明娶吞,通過機(jī)器學(xué)習(xí)算法進(jìn)行精準(zhǔn)營銷的精確度比隨機(jī)猜測的效果要強(qiáng)好幾倍垒迂!
2、KNN回歸
在R中妒蛇,KNN分類函數(shù)是knn()机断,KNN回歸函數(shù)是knnreg()。
> #加載數(shù)據(jù)集BloodBrain绣夺,用到向量logBBB和數(shù)據(jù)框bbbDescr
> library(caret)
> data(BloodBrain)
> class(logBBB)
[1] "numeric"
> dim(bbbDescr)
[1] 208 134
> #取約80%的觀測作訓(xùn)練集吏奸。
> inTrain <- createDataPartition(logBBB, p = .8)[[1]]
> trainX <- bbbDescr[inTrain,]
> trainY <- logBBB[inTrain]
> testX <- bbbDescr[-inTrain,]
> testY <- logBBB[-inTrain]
> #構(gòu)建KNN回歸模型
> fit <- knnreg(trainX, trainY, k = 3)
> fit
3-nearest neighbor regression model
> #KNN回歸模型預(yù)測測試集
> pred <- predict(fit, testX)
> #計算回歸模型的MSE
> mean((pred-testY)^2)
[1] 0.5821147
這個KNN回歸模型的MSE只有0.58,可見回歸效果很不錯陶耍,偏差很蟹芪怠!下面用可視化圖形比較一下結(jié)果烈钞。
> #將訓(xùn)練集泊碑、測試集和預(yù)測值結(jié)果集中比較
> df <-data.frame(class=c(rep("trainY",length(trainY)),rep("testY",length(testY)),rep("predY",length(pred))),Yval=c(trainY,testY,pred))
> ggplot(data=df,mapping = aes(x=Yval,fill=class))+
+ geom_dotplot(alpha=0.8)

這是dotplot,橫坐標(biāo)才是響應(yīng)變量的值毯欣,縱坐標(biāo)表頻率馒过。比較相鄰的紅色點和綠色點在橫軸上的差異,即表明測試集中預(yù)測值與實際值的差距酗钞。
> #比較測試集的預(yù)測值和實際值
> df2 <- data.frame(testY,pred)
> ggplot(data=df2,mapping = aes(x=testY,y=pred))+
+ geom_point(color="steelblue",size=3)+
+ geom_abline(slope = 1,size=1.5,linetype=2)

這張散點圖則直接將測試集中的實際值和預(yù)測值進(jìn)行對比腹忽,虛線是$y=x$。點離這條虛線越近算吩,表明預(yù)測值和實際值之間的差異就越小留凭。
參考文獻(xiàn)
Gareth James et al. <u>An Introduction to Statistical Learning</u>.
Wikipedia. k-nearest neighbors algorithm.
KNN for Smoothing and Prediction.
