歡迎訪問個人博客:blog.spursgo.com
關(guān)于pyhton2.x中編碼問題的一點小理解
大約在一年前泪酱,當(dāng)時接觸pyhton爬蟲時(那時還是在Windows上開發(fā)學(xué)習(xí))派殷,由于網(wǎng)頁中存在大量中文,自然不可避免的會涉及到編碼問題墓阀。剛剛?cè)腴T就遇到了python中的一個大麻煩:編碼問題毡惜,查了一些資料把手上的問題解決之后,就沒有去管編碼問題了斯撮。
一年后经伙,仍然習(xí)慣于python2.x。本來在macOS和ubuntu上寫得很順利得一個爬蟲程序勿锅,轉(zhuǎn)到windows 10上居然出現(xiàn)了大量的亂碼帕膜。
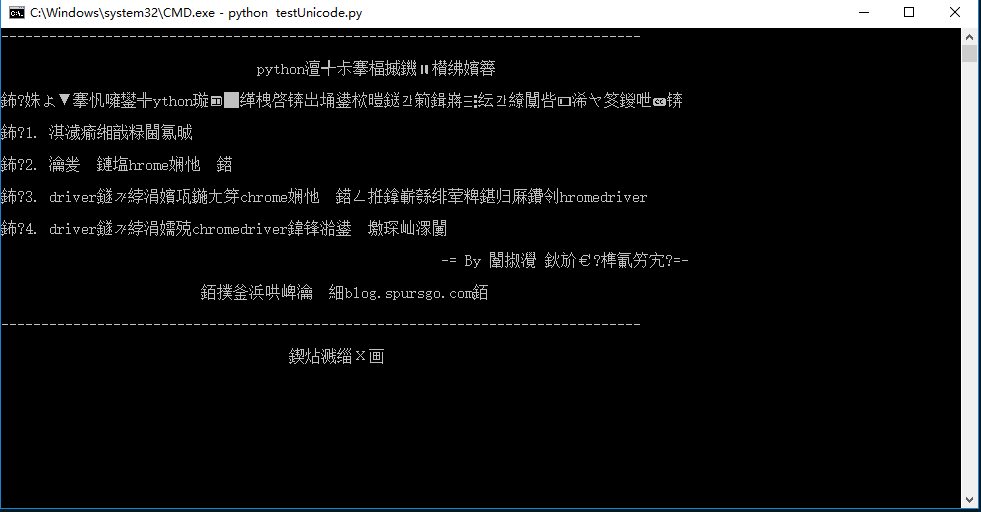
當(dāng)時真的很郁悶,為什么在其他操作系統(tǒng)上運行好好的程序粱甫,到Windows上就成這樣了呢泳叠?郁悶歸郁悶,問題還是要解決呀茶宵!
于是乎危纫,又開始和pyhton編碼問題打交道了。因為現(xiàn)在養(yǎng)成了寫博客的習(xí)慣乌庶,所以本次探究python編碼問題的過程我就詳細(xì)記錄了下來种蝶,以便以后再次遇到這個問題,可以很快的查看而不需要再次折騰瞒大。
各個擊破
1. Windows命令行的編碼
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
這是我程序中對pyhton腳本默認(rèn)編碼的處理螃征,python默認(rèn)的本來是ascii編碼,這里我改為了utf-8透敌。
因此盯滚,如果我在程序執(zhí)行這么一句:
print " "*25 + "〓個人博客:blog.spursgo.com〓"
那么踢械,打印出來的這句話就是默認(rèn)采用utf-8編碼格式,嗯哼魄藕,難道有什么不對嗎内列?
別忘了,我們還不知道Windows命令行窗口采取的編碼格式呢背率!
好的话瞧,趕快查閱一下!
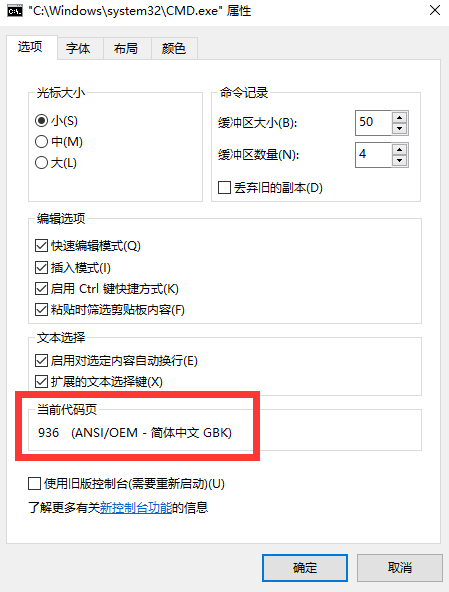
右擊命令行窗口標(biāo)題欄--選擇屬性--點擊選項寝姿,之后我們會看到GBK的字樣:
2. 編碼格式介紹
哦交排,原來如此,我打印的是utf-8編碼格式饵筑,但是他卻采用gbk編碼格式埃篓,命令行窗口當(dāng)然不能正常顯示喏!
可能你覺得對python的各種編碼格式不是很了解翻翩,沒關(guān)系都许,網(wǎng)上有很多介紹編碼格式的文章,這里我推薦兩篇:
在Python中正確使用Unicode 這篇側(cè)重介紹在python中正確使用編碼
Python字符編碼詳解 這篇側(cè)重介紹編碼格式
看完這兩篇文章后嫂冻,相信你會對pyhton中的編碼會有很深刻的認(rèn)識胶征。
這里,主要記錄一下我個人的一些理解和實驗操作:
2.1 python中的字節(jié)串和字符串
對java比較了解的同學(xué)桨仿,應(yīng)該會知道在java中不需要嚴(yán)格區(qū)分所謂的字節(jié)串和字符串睛低,java這門語言把編碼問題處理的非常好!
但是,在python2.x中服傍,這兩個概念卻是一定要理解的钱雷,不然各種編碼問題可能就會找上門來。
以下概念來自于自己的理解吹零,可能不是很嚴(yán)謹(jǐn)罩抗。
字節(jié)串:以字節(jié)為單位,它的每一個個體是字節(jié)灿椅,因此我們統(tǒng)計字節(jié)串的長度時套蒂,結(jié)果一定是所有字節(jié)的數(shù)量。
字符串:以字符為單位茫蛹,它的每一個個體是字符操刀,因此我們統(tǒng)計字符串的長度時,結(jié)果一定是所有字符的數(shù)量婴洼。
咦骨坑!怎么兩句話好像差不多? 是的,我們要區(qū)分的就是字符和字節(jié):一個字符可以包含多個字節(jié)柬采。
說了這么多欢唾,還是來驗證一下吧:

從圖片中且警,我們可以可以清楚的看到,一個‘人’字礁遣,由于它的類型不一樣振湾,當(dāng)我們?nèi)¢L度時,得到的結(jié)果不一樣亡脸。
現(xiàn)在是不是對字節(jié)和字符有了更好的認(rèn)識了呢?
3. 編碼格式的互相轉(zhuǎn)換
decode :解碼树酪,實現(xiàn)其他編碼格式到unicode的轉(zhuǎn)換
encode :編碼浅碾,實現(xiàn)unicode到的轉(zhuǎn)換其他編碼格式
常見的其他編碼格式:utf-8,gbk,gb2312
這是有一個問題我們一定要重視:decode既然是其他編碼格式到unicode的轉(zhuǎn)換,達到解碼的目的续语,也就是說unicode本身不是一種編碼格式垂谢。因此,我們在進行編碼與解碼的時候疮茄,我們要弄清楚滥朱,這個被操作的對象是誰?否則力试,出現(xiàn)編碼問題的幾率會大大增加徙邻。
4. unicode的深刻理解
unicode實際上是一種字符集,神奇之處在于所有語言的字符都用這一種字符集來表示畸裳,它是全人類都承認(rèn)的一種統(tǒng)一標(biāo)準(zhǔn)缰犁。unicode映射了各種字符應(yīng)該用哪種方式來表示,而沒有指明具體的傳輸和儲存方式怖糊,這個工作是由utf來完成的帅容,如utf-8,utf-16。
5. 編碼解碼前后的差別
一個str類型的字節(jié)串解碼后就成了unicode的字符串伍伤,相反并徘,一個unicode類型的字符串解碼后就成了str的字節(jié)串。
以下是我的實驗代碼:
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
country = '中國'
print type(country)
print country
country = country.decode('utf-8')
print type(country)
print country
country = country.encode('gbk')
print type(country)
print country
下面是執(zhí)行結(jié)果:

實驗結(jié)果很好的驗證了剛剛的結(jié)論扰魂。
6. 建議
6.1 更改文本編碼格式
#coding:utf-8
6.2 更改程序默認(rèn)編碼格式
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
6.3 盡可能的采用unicode作為過渡麦乞,輸出時編碼為需要的編碼格式
文/淺斟低唱
