編譯過程
如果需要弄清整個(gè)編譯過程盗温,那還得好好復(fù)習(xí)下編譯原理符相。這里只是通過一個(gè)小例子討論大致過程。
準(zhǔn)備好一個(gè)helloworld的c文件阻问。內(nèi)容最好簡單如下:
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("Hello World!\n");
return 0;
}
編譯命令
$ gcc helloworld.c // 編譯
$ ./a.out // 執(zhí)行
Hello World!
gcc命令其實(shí)依次執(zhí)行了四步操作:
-
預(yù)處理(Preprocessing)
- 預(yù)處理用于將所有的#include頭文件以及宏定義替換成其真正的內(nèi)容拭抬,預(yù)處理之后得到的仍然是文本文件部默,但文件體積會(huì)大很多。
- 命令:
gcc -E -I./ helloworld.c -o helloworld.i或者直接用cpp helloworld.c -I./ -o helloworld.i - 參數(shù)說明:
-
-E是讓編譯器在預(yù)處理之后就退出玖喘,不進(jìn)行后續(xù)編譯過程甩牺; -
-I指定頭文件目錄蘑志,這里指定的是我們自定義的頭文件目錄累奈; -
-o指定輸出文件名。
-
- 經(jīng)過預(yù)處理之后代碼體積會(huì)大很多急但。如下是預(yù)處理之后的部分內(nèi)容澎媒。
# 1 "helloworld.c" # 1 "<built-in>" 1 # 1 "<built-in>" 3 # 330 "<built-in>" 3 # 1 "<command line>" 1 # 1 "<built-in>" 2 # 1 "helloworld.c" 2 typedef unsigned char __uint8_t; typedef short __int16_t; typedef unsigned short __uint16_t; typedef int __int32_t; typedef unsigned int __uint32_t; typedef long long __int64_t; typedef unsigned long long __uint64_t; typedef struct _opaque_pthread_attr_t __darwin_pthread_attr_t; typedef struct _opaque_pthread_cond_t __darwin_pthread_cond_t; typedef struct _opaque_pthread_condattr_t __darwin_pthread_condattr_t; typedef unsigned long __darwin_pthread_key_t; typedef struct _opaque_pthread_mutex_t __darwin_pthread_mutex_t; typedef struct _opaque_pthread_mutexattr_t __darwin_pthread_mutexattr_t; FILE *fopen(const char * restrict __filename, const char * restrict __mode) __asm("_" "fopen" ); int fprintf(FILE * restrict, const char * restrict, ...) __attribute__((__format__ (__printf__, 2, 3))); int fputc(int, FILE *); int fputs(const char * restrict, FILE * restrict) __asm("_" "fputs" ); size_t fread(void * restrict __ptr, size_t __size, size_t __nitems, FILE * restrict __stream); FILE *freopen(const char * restrict, const char * restrict, FILE * restrict) __asm("_" "freopen" ); int fscanf(FILE * restrict, const char * restrict, ...) __attribute__((__format__ (__scanf__, 2, 3))); int fseek(FILE *, long, int); int fsetpos(FILE *, const fpos_t *); long ftell(FILE *); size_t fwrite(const void * restrict __ptr, size_t __size, size_t __nitems, FILE * restrict __stream) __asm("_" "fwrite" ); int getc(FILE *); int getchar(void); char *gets(char *); void perror(const char *); int printf(const char * restrict, ...) __attribute__((__format__ (__printf__, 1, 2))); int putc(int, FILE *); int putchar(int); int puts(const char *); int remove(const char *); int rename (const char *__old, const char *__new); void rewind(FILE *); int scanf(const char * restrict, ...) __attribute__((__format__ (__scanf__, 1, 2))); void setbuf(FILE * restrict, char * restrict); int setvbuf(FILE * restrict, char * restrict, int, size_t); int sprintf(char * restrict, const char * restrict, ...) __attribute__((__format__ (__printf__, 2, 3))) __attribute__((__availability__(swift, unavailable, message="Use snprintf instead."))); int sscanf(const char * restrict, const char * restrict, ...) __attribute__((__format__ (__scanf__, 2, 3))); FILE *tmpfile(void); __attribute__((__availability__(swift, unavailable, message="Use mkstemp(3) instead."))) __attribute__((deprecated("This function is provided for compatibility reasons only. Due to security concerns inherent in the design of tmpnam(3), it is highly recommended that you use mkstemp(3) instead."))) ... 中間很多內(nèi)容這里省略 extern int __vsnprintf_chk (char * restrict, size_t, int, size_t, const char * restrict, va_list); # 499 "/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.12.sdk/usr/include/stdio.h" 2 3 4 # 2 "helloworld.c" 2 int main(){ printf("Hello World!\n"); return 0; } -
編譯(Compilation),
- 這里的編譯不是指程序從源文件到二進(jìn)制程序的全部過程,而是指將經(jīng)過預(yù)處理之后的程序轉(zhuǎn)換成特定匯編代碼(assembly code)的過程波桩。
- 命令:gcc -S -I./ helloworld.c -o helloworld.s
- 參數(shù):
-S為了編譯之后停止戒努。后面的兩個(gè)參數(shù)含義和預(yù)處理的時(shí)候一樣 - 經(jīng)過編譯之后的內(nèi)容如下。
.section __TEXT,__text,regular,pure_instructions .macosx_version_min 10, 12 .globl _main .p2align 4, 0x90 _main: ## @main .cfi_startproc ## BB#0: pushq %rbp Ltmp0: .cfi_def_cfa_offset 16 Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp Ltmp2: .cfi_def_cfa_register %rbp subq $16, %rsp leaq L_.str(%rip), %rdi movl $0, -4(%rbp) movb $0, %al callq _printf xorl %ecx, %ecx movl %eax, -8(%rbp) ## 4-byte Spill movl %ecx, %eax addq $16, %rsp popq %rbp retq .cfi_endproc .section __TEXT,__cstring,cstring_literals L_.str: ## @.str .asciz "Hello World!\n" .subsections_via_symbols -
匯編(Assemble),
- 匯編過程將上一步的匯編代碼轉(zhuǎn)換成機(jī)器碼(machine code)镐躲,這一步產(chǎn)生的文件叫做目標(biāo)文件储玫,是二進(jìn)制格式。如果有多個(gè)文件需要為每一個(gè)源文件產(chǎn)生一個(gè)目標(biāo)文件萤皂。
- 命令:as helloworld.s -o helloworld.o 或者 gcc -c helloworld.s -o helloworld.o
-
鏈接(Linking)撒穷。
- 鏈接過程將多個(gè)目標(biāo)文以及所需的庫文件(.so等)鏈接成最終的可執(zhí)行文件(executable file)。
- 命令:ld -o helloworld.out helloworld.o
**.o**.o裆熙。格式其實(shí)就是ld(選項(xiàng))(參數(shù))參數(shù)就是需要連接的目標(biāo)文件端礼。由于這里沒有生成其他目標(biāo)文件禽笑,所以這段不會(huì)連接成功的。具體的命令可以看這里ld命令
走完上面的步驟可以得到如下幾個(gè)文件蛤奥。

其實(shí)我們平時(shí)寫代碼的到得到可執(zhí)行文件的整個(gè)過程可以用下圖來概括佳镜。
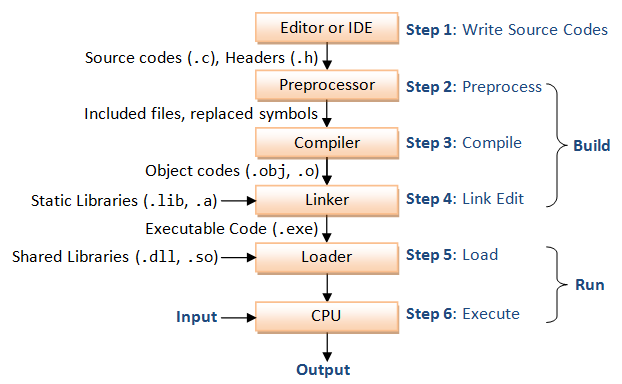
預(yù)處理器
上面把基本的編譯過程講完了,現(xiàn)在就開始進(jìn)入今天的正題凡桥。
預(yù)處理前的操作
再進(jìn)行預(yù)處理前蟀伸,編譯器會(huì)對(duì)源代碼記性一些翻譯過程。其中有幾點(diǎn)需要知道:
- 源代碼中的資費(fèi)映射到元字符集缅刽。使得C外觀更加國際化
- 預(yù)處理表達(dá)式的長度為一邏輯行望蜡。
- 查找反斜杠后緊跟換行符的實(shí)例并刪除。也即是預(yù)處理會(huì)刪除反斜杠和換行符的組合拷恨。
-
類似
printf("Hello, \ World!\n");兩行物理行變?yōu)橐恍?code>printf("Hello,World!\n");經(jīng)過測試在Xcode中會(huì)上面的形式會(huì)比項(xiàng)目多很多空格脖律。
其實(shí)這就是為什么我們能夠用宏定義定義函數(shù)的原理。
文本劃分為預(yù)處理語言符號(hào)腕侄、空白字符及注釋序列小泉。注意編譯器會(huì)有空格代替注釋
-
預(yù)處理指令
所有預(yù)處理指令都是以#開頭。關(guān)于#define和const定義常量的區(qū)別也是需要值得注意的地方冕杠。#define做的是暴力替換微姊,而const是針對(duì)性的。
語言符號(hào)及字符型符號(hào)
- 字符型符號(hào):額外的空格當(dāng)成替換文本的一部分,空格也是主體的一部分分预。
- 語言符號(hào):空格只是分隔主體的符號(hào)兢交。
例子#define TEST 4 * 8
- 字符型符號(hào)將TEST替換為
4 * 8 - 語言符號(hào)將TEST替換為
4 * 8
C編譯器把宏主體當(dāng)成的是字符型符號(hào)
判斷宏定義想不相同通過語言定義符號(hào)來確定。比如#define TEST 48和上面的就不是相同的宏定義因?yàn)樗挥幸粋€(gè)語言符號(hào)4*8笼痹。上面有三個(gè)分別是4配喳、空格、8*
define中使用參數(shù)
使用參數(shù)很簡單凳干,就是#define TEST(X) X*X晴裹。規(guī)則如下:

特別需要注意的是宏參數(shù)和函數(shù)參數(shù)的區(qū)別,宏參數(shù)是進(jìn)行嚴(yán)格的特?fù)Q救赐。這如果使用不懂就會(huì)出現(xiàn)非常嚴(yán)重的錯(cuò)誤涧团。
使用#參數(shù):宏參數(shù)創(chuàng)建字符串
| 宏定義 | 調(diào)用 | 結(jié)果 |
|---|---|---|
#define TESTPF(x) printf("test "#x" * "#x"=%d\n",(x)*(x)); |
TESTPF(5 + 5) |
test 5 + 5 * 5 + 5=100 |
#define TESTPF(x) printf("test x * x=%d\n",(x)*(x)); |
TESTPF(5 + 5); |
test x * x=100 |
可以看到#參數(shù)的作用就是把字符串中的x也進(jìn)行了替換。
使用##參數(shù):預(yù)處理粘合劑
##作用是把兩個(gè)語言符號(hào)組合為單個(gè)語言符號(hào)经磅。
例子:
#define XNAME(n) x##n
#define PRINT_XN(n) printf("x"#n" = %d \n");
int XNAME(1) = 1;
int XNAME(2) = 2;
PRINT_XN(1);
PRINT_XN(2);
結(jié)果:
x1 = 1606416096
x2 = 4352
...和__VA_ARGS__:可變宏
這個(gè)其實(shí)在iOS開發(fā)中還是用得挺多的泌绣。
例子
#define PR(...) printf(__VA_ARGS__)
PR("DD");
PR("D=%d,F=%d\n",12,22);
結(jié)果:
DDD=12,F=22
特別注意。省略號(hào)必須在最后一個(gè)參數(shù)位置预厌。根據(jù)這個(gè)道理阿迈,有些同學(xué)可能就能聯(lián)想到某些語言可變參數(shù)的位置為什么一定要在最后把。比如python
文件包含
預(yù)處理器發(fā)現(xiàn)#include指令后配乓,會(huì)尋找跟在后面的文件仿滔,把這個(gè)文件中的內(nèi)容包含到當(dāng)前文件中惠毁。

頭文件
OC中有.h和.m文件,這和C里面的.h和.c是同一個(gè)道理崎页。所以這里就不多說了鞠绰。具體看圖。

其他預(yù)處理指令
-
#undef取消已定義的宏 -
#if如果給定條件為真飒焦,則編譯下面代碼 -
#elif如果前面的#if給定條件不為真蜈膨,當(dāng)前條件為真,則編譯下面代碼 -
#endif結(jié)束一個(gè)#if……#else條件編譯塊 -
#ifdef如果宏已經(jīng)定義牺荠,則編譯下面代碼 -
#ifndef如果宏沒有定義翁巍,則編譯下面代碼 -
#pragma指令沒有正式的定義。編譯器可以自定義其用途休雌。典型的用法是禁止或允許某些煩人的警告信息灶壶。
上面這些預(yù)處理指令,用得比較頻繁杈曲。大家應(yīng)該不陌生驰凛。還多一些平時(shí)用得不多的。
-
#line指令可以改變編譯器用來指出警告和錯(cuò)誤信息的文件號(hào)和行號(hào)担扑。 -
#error停止編譯并顯示錯(cuò)誤信息
預(yù)處理宏
C標(biāo)準(zhǔn)制定的一些預(yù)處理宏恰响。

額外補(bǔ)充一個(gè)__func__預(yù)定義標(biāo)識(shí)符。這個(gè)是C99標(biāo)準(zhǔn)提供的涌献。用于標(biāo)識(shí)當(dāng)前函數(shù)胚宦。
上面這些預(yù)處理宏經(jīng)常用于打印一些日志信息。
擴(kuò)展閱讀
C programming Tutorial Introduction to C Programming (for Novices & First-Time Programmers)
C/C++預(yù)處理指令#define,#ifdef,#ifndef,#endif…
