第四章 分布式和并行計算
譯者:飛龍
4.1 引言
目前為止俯艰,我們專注于如何創(chuàng)建、解釋和執(zhí)行程序锌订。在第一章中竹握,我們學會使用函數作為組合和抽象的手段。第二章展示了如何使用數據結構和對象來表示和操作數據辆飘,以及向我們介紹了數據抽象的概念啦辐。在第三章中,我們學到了計算機程序如何解釋和執(zhí)行蜈项。結果是芹关,我們理解了如何設計程序,它們在單一處理器上運行紧卒。
這一章中侥衬,我們跳轉到協調多個計算機和處理器的問題。首先跑芳,我們會觀察分布式系統(tǒng)轴总。它們是互相連接的獨立計算機,需要互相溝通來完成任務博个。它們可能需要協作來提供服務肘习,共享數據,或者甚至是儲存太大而不能在一臺機器上裝下的數據。我們會看到,計算機可以在分布式系統(tǒng)中起到不同作用许蓖,并且了解各種信息,計算機需要交換它們來共同工作投蝉。
接下來,我們會考慮并行計算征堪。并行計算是這樣瘩缆,當一個小程序由多個處理器使用共享內存執(zhí)行時,所有處理器都并行工作來使任務完成得更快佃蚜。并發(fā)(或并行)引入了新的挑戰(zhàn)庸娱,并且我們會開發(fā)新的機制來管理并發(fā)程序的復雜性着绊。
4.2 分布式系統(tǒng)
分布式系統(tǒng)是自主的計算機網絡,計算機互相通信來完成一個目標熟尉。分布式系統(tǒng)中的計算機都是獨立的归露,并且沒有物理上共享的內存或處理器。它們使用消息來和其它計算機通信斤儿,消息是網絡上從一臺計算機到另一臺計算機傳輸的一段信息剧包。消息可以用于溝通許多事情:計算機可以讓其它計算機來執(zhí)行一個帶有特定參數的過程,它們可以發(fā)送和接受數據包往果,或者發(fā)送信號讓其它計算機執(zhí)行特定行為疆液。
分布式系統(tǒng)中的計算機具有不同的作用。計算機的作用取決于系統(tǒng)的目標陕贮,以及計算機自身的硬件和軟件屬性堕油。分布式系統(tǒng)中,有兩種主要方式來組織計算機肮之,一種叫客戶端-服務端架構(C/S 架構)掉缺,另一種叫做對等網絡架構(P2P 架構)。
4.2.1 C/S 系統(tǒng)
C/S 架構是一種從中心來源分發(fā)服務的方式局骤。只有單個服務端提供服務攀圈,多臺客戶端和服務器通信來消耗它的產出暴凑。在這個架構中峦甩,客戶端和服務端都有不同的任務。服務端的任務就是響應來自客戶端的服務請求现喳,而客戶端的任務就是使用響應中提供的數據來執(zhí)行一些任務凯傲。
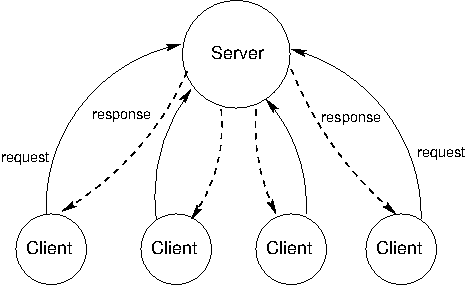
C/S 通信模型可以追溯到二十世紀七十年代 Unix 的引入,但這一模型由于現代萬維網(WWW)中的使用而變得具有影響力嗦篱。一個C/S 交互的例子就是在線閱讀紐約時報冰单。當www.nytimes.com上的服務器與瀏覽器客戶端(比如 Firefox)通信時,它的任務就是發(fā)送回來紐約時報主頁的 HTML灸促。這可能涉及到基于發(fā)送給服務器的用戶賬戶信息诫欠,計算個性化的內容。這意味著需要展示圖片浴栽,安排視覺上的內容荒叼,展示不同的顏色、字體和圖形典鸡,以及允許用戶和渲染后的頁面交互被廓。
客戶端和服務端的概念是強大的函數式抽象÷茜瑁客戶端僅僅是一個提供服務的單位嫁乘,可能同時對應多個客戶端昆婿。客戶端是消耗服務的單位蜓斧〔智客戶端并不需要知道服務如何提供的細節(jié),或者所獲取的數據如何儲存和計算法精,服務端也不需要知道數據如何使用多律。
在網絡上,我們認為客戶端和服務端都是不同的機器搂蜓,但是狼荞,一個機器上的系統(tǒng)也可以擁有 C/S 架構。例如帮碰,來自計算機輸入設備的信號需要讓運行在計算機上的程序來訪問相味。這些程序就是客戶端,消耗鼠標和鍵盤的輸入數據殉挽。操作系統(tǒng)的設備驅動就是服務端丰涉,接受物理的信號并將它們提供為可用的輸入。
C/S 系統(tǒng)的一個缺陷就是斯碌,服務端是故障單點一死。它是唯一能夠分發(fā)服務的組件∩低伲客戶端的數量可以是任意的投慈,它們可以交替,并且可以按需出現和消失冠骄。但是如果服務器崩潰了伪煤,整個系統(tǒng)就會停止工作。所以凛辣,由 C/S 架構創(chuàng)建的函數式抽象也使它具有崩潰的風險抱既。
C/S 系統(tǒng)的另一個缺陷是,當客戶端非常多的時候扁誓,資源就變得稀缺防泵。客戶端增加系統(tǒng)上的命令而不貢獻任何計算資源蝗敢。C/S 系統(tǒng)不能隨著不斷變化的需求縮小或擴大捷泞。
4.2.2 P2P 系統(tǒng)
C/S 模型適合于服務導向的情形。但是前普,還有其它計算目標肚邢,適合使用更加平等的分工。P2P 的術語用于描述一種分布式系統(tǒng),其中勞動力分布在系統(tǒng)的所有組件中骡湖。所有計算機發(fā)送并接受數據贱纠,它們都貢獻一些處理能力和內存。隨著分布式系統(tǒng)的規(guī)模增長响蕴,它的資源計算能力也會增長谆焊。在 P2P 系統(tǒng)中,系統(tǒng)的所有組件都對分布式計算貢獻了一些處理能力和內存浦夷。
所有參與者的勞動力的分工是 P2P 系統(tǒng)的識別特征辖试。也就是說,對等者需要能夠和其它人可靠地通信劈狐。為了確保消息到達預定的目的地罐孝,P2P 系統(tǒng)需要具有組織良好的網絡結構。這些系統(tǒng)中的組件協作來維護足夠的其它組件的位置信息并將消息發(fā)送到預定的目的地肥缔。
在一些 P2P 系統(tǒng)中莲兢,維護網絡健康的任務由一系列特殊的組件執(zhí)行。這種系統(tǒng)并不是純粹的 P2P 系統(tǒng)续膳,因為它們具有不同類型的組件類型改艇,提供不同的功能。支持 P2P 網絡的組件就像腳手架那樣:它們有助于網絡保持連接坟岔,它們維護不同計算機的位置信息谒兄,并且它們新來者來鄰居中找到位置。
P2P 系統(tǒng)的最常見應用就是數據傳送和存儲社付。對于數據傳送承疲,系統(tǒng)中的每臺計算機都致力于網絡上的數據傳送。如果目標計算機是特定計算機的鄰居瘦穆,那臺計算機就一起幫助傳送數據纪隙。對于數據存儲赊豌,數據集可以過于龐大扛或,不能在任何單臺計算機內裝下,或者儲存在單臺計算機內具有風險碘饼。每臺計算機都儲存數據的一小部分熙兔,不同的計算機上可能會儲存相同數據的多個副本。當一臺計算機崩潰時艾恼,上面的數據可以由其它副本恢復住涉,或者在更換替代品之后放回。
Skype钠绍,一個音頻和視頻聊天服務舆声,是采用 P2P 架構的數據傳送應用的示例。當不同計算機上的兩個人都使用 Skype 交談時,它們的通信會拆成由 1 和 0 構成的數據包媳握,并且通過 P2P 網絡傳播碱屁。這個網絡由電腦上注冊了 Skype 的其它人組成。每臺計算機都知道附近其它人的位置蛾找。一臺計算機通過將數據包傳給它的鄰居娩脾,來幫助將它傳到目的地,它的鄰居又將它傳給其它鄰居打毛,以此類推柿赊,直到數據包到達了它預定的目的地。Skype 并不是純粹的 P2P 系統(tǒng)幻枉。一個超級節(jié)點組成的腳手架網絡用于用戶登錄和退出碰声,維護它們的計算機的位置信息,并且修改網絡結構來處理用戶進入和離開熬甫。
4.2.3 模塊化
我們剛才考慮的兩個架構 -- P2P 和 C/S -- 都為強制模塊化而設計奥邮。模塊化是一個概念,系統(tǒng)的組件對其它組件來說應該是個黑盒罗珍。組件如何實現行為應該并不重要洽腺,只要它提供了一個接口:規(guī)定了輸入應該產生什么輸出。
在第二章中覆旱,我們在調度函數和面向對象編程的上下文中遇到了接口蘸朋。這里,接口的形式為指定對象應接收的信息扣唱,以及對象應如何響應它們藕坯。例如,為了提供“表示為字符串”的接口噪沙,對象必須回復__repr__和__str__信息炼彪,并且在響應中輸出合適的字符串。那些字符串的生成如何實現并不是接口的一部分正歼。
在分布式系統(tǒng)中辐马,我們必須考慮涉及到多臺計算機的程序設計,所以我們將接口的概念從對象和消息擴展為整個程序局义。接口指定了應該接受的輸入喜爷,以及應該在響應中返回給輸入的輸出。
接口在真實世界的任何地方都存在萄唇,我們經常習以為常檩帐。一個熟悉的例子就是 TV 遙控器。你可以買到許多牌子的遙控器或者 TV另萤,它們都能工作湃密。它們的唯一共同點就是“TV 遙控器”的接口。只要當你按下電院、音量泛源、頻道或者其它任何按鈕(輸入)時揍障,一塊電路向你的 TV 發(fā)送正確的信號(輸出),它就遵循“TV 遙控器”接口俩由。
模塊化給予系統(tǒng)許多好處毒嫡,并且是一種沉思熟慮的系統(tǒng)設計。首先幻梯,模塊化的系統(tǒng)易于理解兜畸。這使它易于修改和擴展。其次碘梢,如果系統(tǒng)中什么地方發(fā)生錯誤咬摇,只需要更換有錯誤的組件。再者煞躬,bug 或故障可以輕易定位肛鹏。如果組件的輸出不符合接口的規(guī)定,而且輸入是正確的恩沛,那么這個組件就是故障來源在扰。
4.2.4 消息傳遞
在分布式系統(tǒng)中,組件使用消息傳遞來互相溝通雷客。消息有三個必要部分:發(fā)送者芒珠、接收者和內容。發(fā)送者需要被指定搅裙,便于接受者得知哪個組件發(fā)送了信息皱卓,以及將回復發(fā)送到哪里。接收者需要被指定部逮,便于任何協助發(fā)送消息的計算機知道發(fā)送到哪里娜汁。消息的內容是最寶貴的。取決于整個系統(tǒng)的函數兄朋,內容可以是一段數據掐禁、一個信號,或者一條指令蜈漓,讓遠程計算機來以一些參數求出某個函數穆桂。
消息傳遞的概念和第二章的消息傳遞機制有很大關系宫盔,其中融虽,調度函數或字典會響應值為字符串的信息。在程序中灼芭,發(fā)送者和接受者都由求值規(guī)則標識有额。但是在分布式系統(tǒng)中,接受者和發(fā)送者都必須顯式編碼進消息中。在程序中巍佑,使用字符串來控制調度函數的行為十分方便茴迁。在分布式系統(tǒng)中,消息需要經過網絡發(fā)送萤衰,并且可能需要存放許多不同種類的信號作為“數據”堕义,所以它們并不始終編碼為字符串。但是在兩種情況中脆栋,消息都服務于相同的函數倦卖。不同的組件(調度函數或計算機)交換消息來完成一個目標,它需要多個組件模塊的協作椿争。
在較高層面上怕膛,消息內容可以是復雜的數據結構,但是在較低層面上秦踪,消息只是簡單的 1 和 0 的流褐捻,在網絡上傳輸。為了變得易用椅邓,所有網絡上發(fā)送的消息都需要根據一致的消息協議格式化柠逞。
消息協議是一系列規(guī)則,用于編碼和解碼消息景馁。許多消息協議規(guī)定边苹,消息必須符合特定的格式,其中特定的比特具有固定的含義裁僧。固定的格式實現了固定的編碼和解碼規(guī)則來生成和讀取這種格式个束。分布式系統(tǒng)中的所有組件都必須理解協議來互相通信。這樣聊疲,它們就知道消息的哪個部分對應哪個信息茬底。
消息協議并不是特定的程序或軟件庫。反之获洲,它們是可以由大量程序使用的規(guī)則阱表,甚至以不同的編程語言編寫。所以贡珊,帶有大量不同軟件系統(tǒng)的計算機可以加入相同的分布式系統(tǒng)最爬,只需要遵守控制這個系統(tǒng)的消息協議。
4.2.5 萬維網上的消息
HTTP(超文本傳輸協議的縮寫)是萬維網所支持的消息協議门岔。它指定了在 Web 瀏覽器和服務器之間交換的消息格式爱致。所有 Web 瀏覽器都使用 HTTP 協議來請求服務器上的頁面,而且所有 Web 服務器都使用 HTTP 格式來發(fā)回它們的響應寒随。
當你在 Web 瀏覽器上鍵入 URL 時糠悯,比如 http://en.wikipedia.org/wiki/UC_Berkeley帮坚,你實際上就告訴了你的計算機,使用 "HTTP" 協議互艾,從 "http://en.wikipedia.org/wiki/UC_Berkeley" 的服務器上請求 "wiki/UC_Berkeley" 頁面试和。消息的發(fā)送者是你的計算機,接受者是 en.wikipedia.org纫普,以及消息內容的格式是:
GET /wiki/UC_Berkeley HTTP/1.1
第一個單詞是請求類型阅悍,下一個單詞是所請求的資源,之后是協議名稱(HTTP)和版本(1.1)昨稼。(請求還有其它類型溉箕,例如 PUT、POST 和 HEAD悦昵,Web 瀏覽器也會使用它們肴茄。)
服務器發(fā)回了回復。這時但指,發(fā)送者是 en.wikipedia.org寡痰,接受者是你的計算機,消息內容的格式是由數據跟隨的協議頭:
HTTP/1.1 200 OK
Date: Mon, 23 May 2011 22:38:34 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
Last-Modified: Wed, 08 Jan 2011 23:11:55 GMT
Content-Type: text/html; charset=UTF-8
... web page content ...
第一行棋凳,單詞 "200 OK" 表示沒有發(fā)生錯誤拦坠。協議頭下面的行提供了有關服務器的信息,日期和發(fā)回的內容類型剩岳。協議頭和頁面的實際內容通過一個空行來分隔贞滨。
如果你鍵入了錯誤的 Web 地址,或者點擊了死鏈拍棕,你可能會看到類似于這個錯誤的消息:
404 Error File Not Found
它的意思是服務器發(fā)送回了一個 HTTP 協議頭晓铆,以這樣起始:
HTTP/1.1 404 Not Found
一系列固定的響應代碼是消息協議的普遍特性。協議的設計者試圖預料通過協議發(fā)送的常用消息绰播,并且賦為固定的代碼來減少傳送大小骄噪,以及建立通用的消息語義。在 HTTP 協議中蠢箩,200 響應代碼表示成功链蕊,而 404 表示資源沒有找到的錯誤。其它大量響應代碼也存在于 HTTP 1.1 標準中谬泌。
HTTP 是用于通信的固定格式滔韵,但是它允許傳輸任意的 Web 頁面。其它互聯網上的類似協議是 XMPP掌实,即時消息的常用協議陪蜻,以及 FTP,用于在客戶端和服務器之間下載和上傳文件的協議潮峦。
4.3 并行計算
計算機每一年都會變得越來越快囱皿。在 1965 年勇婴,英特爾聯合創(chuàng)始人戈登·摩爾預測了計算機將如何隨時間而變得越來越快忱嘹。僅僅基于五個數據點嘱腥,他推測,一個芯片中的晶體管數量每兩年將翻一倍拘悦。近50年后齿兔,他的預測仍驚人地準確,現在稱為摩爾定律础米。
盡管速度在爆炸式增長分苇,計算機還是無法跟上可用數據的規(guī)模。根據一些估計屁桑,基因測序技術的進步將使可用的基因序列數據比處理器變得更快的速度還要快医寿。換句話說,對于遺傳數據蘑斧,計算機變得越來越不能處理每年需要處理的問題規(guī)模靖秩,即使計算機本身變得越來越快。
為了規(guī)避對單個處理器速度的物理和機械約束竖瘾,制造商正在轉向另一種解決方案:多處理器沟突。如果兩個,或三個捕传,或更多的處理器是可用的惠拭,那么許多程序可以更快地執(zhí)行。當一個處理器在做一些計算的一個切面時庸论,其他的可以在另一個切面工作职辅。所有處理器都可以共享相同的數據,但工作并行執(zhí)行聂示。
為了能夠合作罐农,多個處理器需要能夠彼此共享信息。這通過使用共享內存環(huán)境來完成催什。該環(huán)境中的變量涵亏、對象和數據結構對所有的進程可見。處理器在計算中的作用是執(zhí)行編程語言的求值和執(zhí)行規(guī)則蒲凶。在一個共享內存模型中气筋,不同的進程可能執(zhí)行不同的語句,但任何語句都會影響共享環(huán)境旋圆。
4.3.1 共享狀態(tài)的問題
多個進程之間的共享狀態(tài)具有單一進程環(huán)境沒有的問題宠默。要理解其原因,讓我們看看下面的簡單計算:
x = 5
x = square(x)
x = x + 1
x的值是隨時間變化的灵巧。起初它是 5搀矫,一段時間后它是 25抹沪,最后它是 26。在單一處理器的環(huán)境中瓤球,沒有時間依賴性的問題融欧。x的值在結束時總是 26。但是如果存在多個進程卦羡,就不能這樣說了噪馏。假設我們并行執(zhí)行了上面代碼的最后兩行:一個處理器執(zhí)行x = square(x)而另一個執(zhí)行x = x + 1。每一個這些賦值語句都包含查找當前綁定到x的值绿饵,然后使用新值更新綁定欠肾。讓我們假設x是共享的,同一時間只有一個進程讀取或寫入拟赊。即使如此刺桃,讀和寫的順序可能會有所不同。例如吸祟,下面的例子顯示了兩個進程的每個進程的一系列步驟瑟慈,P1和P2。每一步都是簡要描述的求值過程的一部分欢搜,隨時間從上到下執(zhí)行:
P1 P2
read x: 5
read x: 5
calculate 5*5: 25 calculate 5+1: 6
write 25 -> x
write x-> 6
在這個順序中封豪,x的最終值為 6。如果我們不協調這兩個過程炒瘟,我們可以得到另一個順序的不同結果:
P1 P2
read x: 5
read x: 5 calculate 5+1: 6
calculate 5*5: 25 write x->6
write 25 -> x
在這個順序中吹埠,x將是 25。事實上存在多種可能性疮装,這取決于進程執(zhí)行代碼行的順序缘琅。x的最終值可能最終為 5,25廓推,或預期值 26刷袍。
前面的例子是無價值的。square(x)和x = x + 1是簡單快速的計算樊展。我們強迫一條語句跑在另一條的后面呻纹,并不會失去太多的時間。但是什么樣的情況下专缠,并行化是必不可少的雷酪?這種情況的一個例子是銀行業(yè)。在任何給定的時間涝婉,可能有成千上萬的人想用他們的銀行賬戶進行交易:他們可能想在商店刷卡哥力,存入支票,轉帳,或支付賬單吩跋。即使一個帳戶在同一時間也可能有活躍的多個交易寞射。
讓我們看看第二章的make_withdraw函數,下面是修改過的版本锌钮,在更新余額之后打印而不是返回它。我們感興趣的是這個函數將如何并發(fā)執(zhí)行策治。
>>> def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
print('Insufficient funds')
else:
balance = balance - amount
print(balance)
return withdraw
現在想象一下兰吟,我們以 10 美元創(chuàng)建一個帳戶,讓我們想想混蔼,如果我們從帳戶中提取太多的錢會發(fā)生什么珊燎。如果我們順序執(zhí)行這些交易,我們會收到資金不足的消息悔政。
>>> w = make_withdraw(10)
>>> w(8)
2
>>> w(7)
'Insufficient funds'
但是晚吞,在并行中可以有許多不同的結果。下面展示了一種可能性:
P1: w(8) P2: w(7)
read balance: 10
read amount: 8 read balance: 10
8 > 10: False read amount: 7
if False 7 > 10: False
10 - 8: 2 if False
write balance -> 2 10 - 7: 3
read balance: 2 write balance -> 3
print 2 read balance: 3
print 3
這個特殊的例子給出了一個不正確結果 3谋国。就好像w(8)交易從來沒有發(fā)生過槽地。其他可能的結果是 2,和'Insufficient funds'芦瘾。這個問題的根源是:如果P2 在P1寫入值前讀取余額捌蚊,P2的狀態(tài)是不一致的(反之亦然)。P2所讀取的余額值是過時的近弟,因為P1打算改變它缅糟。P2不知道,并且會用不一致的值覆蓋它祷愉。
這個例子表明窗宦,并行化的代碼不像把代碼行分給多個處理器來執(zhí)行那樣容易。變量讀寫的順序相當重要二鳄。
一個保證執(zhí)行正確性的有吸引力的方式是赴涵,兩個修改共享數據的程序不能同時執(zhí)行。不幸的是泥从,對于銀行業(yè)這將意味著句占,一次只可以進行一個交易,因為所有的交易都修改共享數據躯嫉。直觀地說纱烘,我們明白杨拐,讓 2 個不同的人同時進行完全獨立的帳戶交易應該沒有問題。不知何故擂啥,這兩個操作不互相干擾哄陶,但在同一帳戶上的相同方式的同時操作就相互干擾。此外哺壶,當進程不讀取或寫入時,讓它們同時運行就沒有問題至扰。
4.3.2 并行計算的正確性
并行計算環(huán)境中的正確性有兩個標準敢课。第一個是直秆,結果應該總是相同。第二個是筝野,結果應該和串行執(zhí)行的結果一致遗座。
第一個條件表明途蒋,我們必須避免在前面的章節(jié)中所示的變化号坡,其中在不同的方式下的交叉讀寫會產生不同的結果宽堆。例子中畜隶,我們從 10 美元的帳戶取出了w(8)和w(7)浸遗。這個條件表明跛锌,我們必須始終返回相同的答案,獨立于P1和P2的指令執(zhí)行順序脑豹。無論如何译秦,我們必須以這樣一種方式來編寫我們的程序击碗,無論他們如何相互交叉稍途,他們應該總是產生同樣的結果。
第二個條件揭示了許多可能的結果中哪個是正確的坷虑。例子中迄损,我們從 10 美元的帳戶取出了w(8)和w(7)芹敌,這個條件表明結果必須總是余額不足氏捞,而不是 2 或者 3。
當一個進程在程序的臨界區(qū)影響另一個進程時捆等,并行計算中就會出現問題断部。這些都是需要執(zhí)行的代碼部分蝴光,它們看似是單一的指令蔑祟,但實際上由較小的語句組成疆虚。一個程序會以一系列原子硬件指令執(zhí)行径簿,由于處理器的設計篇亭,這些是不能被打斷或分割為更小單元的指令译蒂。為了在并行的情況下表現正確,程序代碼的臨界區(qū)需要具有原子性捕透,保證他們不會被任何其他代碼中斷激率。
為了強制程序臨界區(qū)在并發(fā)下的原子性,需要能夠在重要的時刻將進程序列化或彼此同步嘉冒。序列化意味著同一時間只運行一個進程 -- 這一瞬間就好像串行執(zhí)行一樣亮垫。同步有兩種形式。首先是互斥,進程輪流訪問一個變量究驴。其次是條件同步蝴韭,在滿足條件(例如其他進程完成了它們的任務)之前進程一直等待,之后繼續(xù)執(zhí)行庆尘。這樣减余,當一個程序即將進入臨界區(qū)時,其他進程可以一直等待到它完成,然后安全地執(zhí)行晤柄。
4.3.3 保護共享狀態(tài):鎖和信號量
在本節(jié)中討論的所有同步和序列化方法都使用相同的基本思想芥颈。它們在共享狀態(tài)中將變量用作信號赚抡,所有過程都會理解并遵守它盾计。這是一個相同的理念族铆,允許分布式系統(tǒng)中的計算機協同工作 -- 它們通過傳遞消息相互協調,根據每一個參與者都理解和遵守的一個協議哭尝。
這些機制不是為了保護共享狀態(tài)而出現的物理障礙哥攘。相反,他們是建立相互理解的基礎上材鹦。和出現在十字路口的各種方向的車輛能夠安全通行一樣献丑,是同一種相互理解。這里沒有物理的墻壁阻止汽車相撞侠姑,只有遵守規(guī)則创橄,紅色意味著“停止”,綠色意味著“通行”。同樣鬼店,沒有什么可以保護這些共享變量惑畴,除非當一個特定的信號表明輪到某個進程了,進程才會訪問它們。
鎖。鎖耙旦,也被稱為互斥體(mutex)脓规,是共享對象脐湾,常用于發(fā)射共享狀態(tài)被讀取或修改的信號。不同的編程語言實現鎖的方式不同获黔,但是在 Python 中渗蟹,一個進程可以調用acquire()方法來嘗試獲得鎖的“所有權”,然后在使用完共享變量的時候調用release()釋放它圆凰。當進程獲得了一把鎖争群,任何試圖執(zhí)行acquire()操作的其他進程都會自動等待到鎖被釋放。這樣凡恍,同一時間只有一個進程可以獲得一把鎖钧舌。
對于一把保護一組特定的變量的鎖普泡,所有的進程都需要編程來遵循一個規(guī)則:一個進程不擁有特定的鎖就不能訪問相應的變量砰嘁。實際上磕蛇,所有進程都需要在鎖的acquire()和release()語句之間“包裝”自己對共享變量的操作件相。
我們可以把這個概念用于銀行余額的例子中逛揩。該示例的臨界區(qū)是從余額讀取到寫入的一組操作膀息。我們看到,如果一個以上的進程同時執(zhí)行這個區(qū)域了赵,問題就會發(fā)生潜支。為了保護臨界區(qū),我們需要使用一把鎖柿汛。我們把這把鎖稱為balance_lock(雖然我們可以命名為任何我們喜歡的名字)冗酿。為了鎖定實際保護的部分,我們必須確保試圖進入這部分時調用acquire()獲取鎖苛茂,以及之后調用release()釋放鎖已烤,這樣可以輪到別人。
>>> from threading import Lock
>>> def make_withdraw(balance):
balance_lock = Lock()
def withdraw(amount):
nonlocal balance
# try to acquire the lock
balance_lock.acquire()
# once successful, enter the critical section
if amount > balance:
print("Insufficient funds")
else:
balance = balance - amount
print(balance)
# upon exiting the critical section, release the lock
balance_lock.release()
如果我們建立和之前一樣的情形:
w = make_withdraw(10)
現在就可以并行執(zhí)行w(8)和w(7)了:
P1 P2
acquire balance_lock: ok
read balance: 10 acquire balance_lock: wait
read amount: 8 wait
8 > 10: False wait
if False wait
10 - 8: 2 wait
write balance -> 2 wait
read balance: 2 wait
print 2 wait
release balance_lock wait
acquire balance_lock:ok
read balance: 2
read amount: 7
7 > 2: True
if True
print 'Insufficient funds'
release balance_lock
我們看到了妓羊,兩個進程同時進入臨界區(qū)是可能的胯究。某個進程實例獲取到了balance_lock,另一個就得等待躁绸,直到那個進程退出了臨界區(qū)裕循,它才能開始執(zhí)行。
要注意程序不會自己終止净刮,除非P1釋放了balance_lock剥哑。如果它沒有釋放balance_lock,P2永遠不可能獲取它淹父,而是一直會等待株婴。忘記釋放獲得的鎖是并行編程中的一個常見錯誤。
信號量。信號量是用于維持有限資源訪問的信號困介。它們和鎖類似大审,除了它們可以允許某個限制下的多個訪問。它就像電梯一樣只能夠容納幾個人座哩。一旦達到了限制徒扶,想要使用資源的進程就必須等待。其它進程釋放了信號量之后根穷,它才可以獲得姜骡。
例如,假設有許多進程需要讀取中心數據庫服務器的數據屿良。如果過多的進程同時訪問它圈澈,它就會崩潰,所以限制連接數量就是個好主意管引。如果數據庫只能同時支持N=2的連接士败,我們就可以以初始值N=2來創(chuàng)建信號量。
>>> from threading import Semaphore
>>> db_semaphore = Semaphore(2) # set up the semaphore
>>> database = []
>>> def insert(data):
db_semaphore.acquire() # try to acquire the semaphore
database.append(data) # if successful, proceed
db_semaphore.release() # release the semaphore
>>> insert(7)
>>> insert(8)
>>> insert(9)
信號量的工作機制是褥伴,所有進程只在獲取了信號量之后才可以訪問數據庫谅将。只有N=2個進程可以獲取信號量,其它的進程都需要等到其中一個進程釋放了信號量重慢,之后在訪問數據庫之前嘗試獲取它饥臂。
P1 P2 P3
acquire db_semaphore: ok acquire db_semaphore: wait acquire db_semaphore: ok
read data: 7 wait read data: 9
append 7 to database wait append 9 to database
release db_semaphore: ok acquire db_semaphore: ok release db_semaphore: ok
read data: 8
append 8 to database
release db_semaphore: ok
值為 1 的信號量的行為和鎖一樣。
4.3.4 保持同步:條件變量
條件變量在并行計算由一系列步驟組成時非常有用似踱。進程可以使用條件變量隅熙,來用信號告知它完成了特定的步驟。之后核芽,等待信號的其它進程就會開始它們的任務囚戚。一個需要逐步計算的例子就是大規(guī)模向量序列的計算。在計算生物學轧简,Web 范圍的計算驰坊,和圖像處理及圖形學中,常常需要處理非常大型(百萬級元素)的向量和矩陣哮独。想象下面的計算:
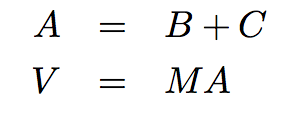
我們可以通過將矩陣和向量按行拆分拳芙,并把每一行分配到單獨的線程上,來并行處理每一步皮璧。作為上面的計算的一個實例舟扎,想象下面的簡單值:
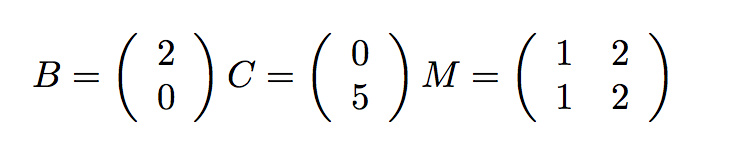
我們將前一半(這里是第一行)分配給一個線程,后一半(第二行)分配給另一個線程:
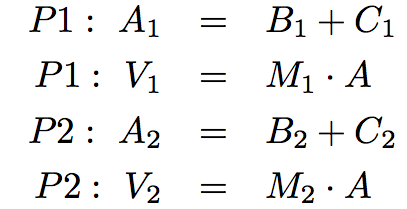
在偽代碼中悴务,計算是這樣的:
def do_step_1(index):
A[index] = B[index] + C[index]
def do_step_2(index):
V[index] = M[index] . A
進程 1 執(zhí)行了:
do_step_1(1)
do_step_2(1)
進程 2 執(zhí)行了:
do_step_1(2)
do_step_2(2)
如果允許不帶同步處理睹限,就造成下面的不一致性:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
read M1: (1 2) read C2: 5
read A: (2 0) calculate 5+0: 5
calculate (1 2).(2 0): 2 write 5 -> A2
write 2 -> V1 read M2: (1 2)
read A: (2 5)
calculate (1 2).(2 5):12
write 12 -> V2
問題就是V直到所有元素計算出來時才會計算出來。但是,P1在A的所有元素計算出來之前邦泄,完成A = B+C并且移到V = MA删窒。所以它與M相乘時使用了A的不一致的值。
我們可以使用條件變量來解決這個問題顺囊。
條件變量是表現為信號的對象,信號表示某個條件被滿足蕉拢。它們通常被用于協調進程特碳,這些進程需要在繼續(xù)執(zhí)行之前等待一些事情的發(fā)生。需要滿足一定條件的進程可以等待一個條件變量晕换,直到其它進程修改了條件變量來告訴它們繼續(xù)執(zhí)行午乓。
Python 中,任何數量的進程都可以使用condition.wait()方法闸准,用信號告知它們正在等待某個條件益愈。在調用該方法之后,它們會自動等待到其它進程調用了condition.notify()或condition.notifyAll()函數夷家。notify()方法值喚醒一個進程蒸其,其它進程仍舊等待。notifyAll()方法喚醒所有等待中的進程库快。每個方法在不同情形中都很實用摸袁。
由于條件變量通常和決定條件是否為真的共享變量相聯系,它們也提供了acquire()和release()方法义屏。這些方法應該在修改可能改變條件狀態(tài)的變量時使用靠汁。任何想要用信號告知條件已經改變的進程,必須首先使用acquire()來訪問它闽铐。
在我們的例子中蝶怔,在執(zhí)行第二步之前必須滿足的條件是,兩個進程都必須完成了第一步兄墅。我們可以跟蹤已經完成第一步的進程數量踢星,以及條件是否被滿足,通過引入下面兩個變量:
step1_finished = 0
start_step2 = Condition()
我們在do_step_2的開頭插入start_step_2().wait()察迟。每個進程都會在完成步驟 1 之后自增step1_finished斩狱,但是我們只會在step_1_finished = 2時發(fā)送信號。下面的偽代碼展示了它:
step1_finished = 0
start_step2 = Condition()
def do_step_1(index):
A[index] = B[index] + C[index]
# access the shared state that determines the condition status
start_step2.acquire()
step1_finished += 1
if(step1_finished == 2): # if the condition is met
start_step2.notifyAll() # send the signal
#release access to shared state
start_step2.release()
def do_step_2(index):
# wait for the condition
start_step2.wait()
V[index] = M[index] . A
在引入條件變量之后扎瓶,兩個進程會一起進入步驟 2所踊,像下面這樣:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
acquire start_step2: ok read C2: 5
write 1 -> step1_finished calculate 5+0: 5
step1_finished == 2: false write 5-> A2
release start_step2: ok acquire start_step2: ok
start_step2: wait write 2-> step1_finished
wait step1_finished == 2: true
wait notifyAll start_step_2: ok
start_step2: ok start_step2:ok
read M1: (1 2) read M2: (1 2)
read A:(2 5)
calculate (1 2). (2 5): 12 read A:(2 5)
write 12->V1 calculate (1 2). (2 5): 12
write 12->V2
在進入do_step_2的時候,P1需要在start_step_2之前等待概荷,直到P2自增了step1_finished秕岛,發(fā)現了它等于 2,之后向條件發(fā)送信號。
4.3.5 死鎖
雖然同步方法對保護共享狀態(tài)十分有效继薛,但它們也帶來了麻煩修壕。因為它們會導致一個進程等待另一個進程,這些進程就有死鎖的風險遏考。死鎖是一種情形慈鸠,其中兩個或多個進程被卡住,互相等待對方完成灌具。我們已經提到了忘記釋放某個鎖如何導致進程無限卡住青团。但是即使acquire()和release()調用的數量正確,程序仍然會構成死鎖咖楣。
死鎖的來源是循環(huán)等待督笆,像下面展示的這樣。沒有進程能夠繼續(xù)執(zhí)行诱贿,因為它們正在等待其它進程娃肿,而其它進程也在等待它完成。
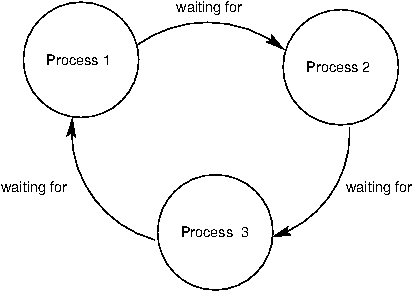
作為一個例子珠十,我們會建立兩個進程的死鎖料扰。假設有兩把鎖,x_lock和y_lock宵睦,并且它們像這樣使用:
>>> x_lock = Lock()
>>> y_lock = Lock()
>>> x = 1
>>> y = 0
>>> def compute():
x_lock.acquire()
y_lock.acquire()
y = x + y
x = x * x
y_lock.release()
x_lock.release()
>>> def anti_compute():
y_lock.acquire()
x_lock.acquire()
y = y - x
x = sqrt(x)
x_lock.release()
y_lock.release()
如果compute()和anti_compute()并行執(zhí)行记罚,并且恰好像下面這樣互相交錯:
P1 P2
acquire x_lock: ok acquire y_lock: ok
acquire y_lock: wait acquire x_lock: wait
wait wait
wait wait
wait wait
... ...
所產生的情形就是死鎖。P1和P2每個都持有一把鎖壳嚎,但是它們需要兩把鎖來執(zhí)行桐智。P1正在等待P2釋放y_lock,而P2正在等待P1釋放x_lock烟馅。所以说庭,沒有進程能夠繼續(xù)執(zhí)行。
