寫在前面
最近不停的google學習新的東西,看了很多文章,受益匪淺,也打算將自己學到的東西記錄下來方便分享.
cuda入門推薦
<<CUDA BY Example>>,簡單暴力的一本入門書籍.
New Features in CUDA 7.5
寫本文的時候CUDA 8.0已經(jīng)發(fā)布了,以后有時間再追加
16-bit Floating Point (FP16)
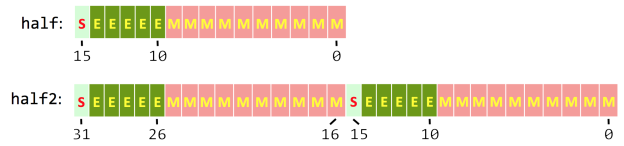
新增half(16bit)和half2(16bit x 2)兩種類型(參見cuda_f16.h API),能夠緩解ML的內存瓶頸,同時相對提升1/2的內存帶寬.
half2是否有SIMD類似的特性呢?
提供__half2float()和__float2half()等類型轉換接口.
“Mixed Precision” Computation
以FP16存儲,用FP32(single)或FP64(double)計算.
例如cublasSgemmEx()矩陣乘接口,以FP16 傳入?yún)?shù),32-bit計算,相對32bit的float擴張了一倍的數(shù)據(jù)吞吐.
針對Tegra X1 GPUs 和Pascal架構的GPU(我做實驗的時候貌似要求計算能力大于5.3(簡直買不起)的GPU才可以使用half,這里還是一個疑點),cuda_f16.h中定義了FP16的計算和比較函數(shù),cuBlas提供cublasHgemm() 對FP16的矩陣乘法.
稀疏矩陣
暫時沒有涉及到,以后追加吧.
Profile工具升級
這個是個好東西,有時間新開一篇文章學習一下吧
New Features in CUDA 8
全新的統(tǒng)一尋址(Unified Memory)
- 簡化編程和簡化內存模型,專注于并行,忽略內存分配和拷貝,簡化內存管理
cuda6.0 引入 Unified Memory,用一個統(tǒng)一的虛擬地址,cuda自動相互在CPU和GPU之間轉換內存.
在6.0中Unified Memory的大小受到顯存的限制,而在8.0中,cuda能夠尋址49bit長度的地址,遠超過CPU48bit的地址長度,所以Unified Memory不再受顯存的限制而和CPU的內存有關系.
6.0中采用特殊的內存池來管理Unifie Memory,而在8.0中,支持Unified Memory的GPU可以直接使用cpu內存指針訪問由操作系統(tǒng)分配的內存空間(如malloc).Unified Memory可以訪問整個OS的虛擬內存空間,這就意味著Unified Memory申請的空間可以超高CPU RAM的物理大小.
這么方便的東西肯定是需要OS級別的支持.好在NVIDIA和Red Hat合作,讓這一特性能夠在Linux社區(qū)能夠使用(難道沒有Windows的份?).
Page Faulting
結合統(tǒng)一尋址,CUDA不需要在cuda程序launch的時候同步GPU內存,當發(fā)生page fault的時候,cuda自動的將內存移動( PCIe 或NVLink會采用map方式,速度更快)到GPU或CPU內存之之中.這樣GPU和CPU能夠同時訪問Unified Memory,需要做好CPU和GPU對內存的同步和互斥,避免污染內存數(shù)據(jù).
Mixed-Precision Computing
- FP16和Int8
主要用于DeepLearning,低精度的數(shù)值能夠更快的load和更快的計算,在cuBLAS, cuDNN, 和 cuFFT,FP16和Int8的計算性能明顯提升.

新的GPU還沒有合適的電源,暫時無法HelloWord --
hello world
