1.什么是HashMap
基于哈希表的 Map 接口的實現(xiàn)。此實現(xiàn)提供所有可選的映射操作时鸵,并允許使用 null 值和 null 鍵筋搏。(除了非同步和允許使用 null 之外包蓝,HashMap 類與 Hashtable 大致相同。)此類不保證映射的順序绽淘,特別是它不保證該順序恒久不變涵防。 此實現(xiàn)假定哈希函數(shù)將元素適當(dāng)?shù)胤植荚诟魍爸g,可為基本操作(get 和 put)提供穩(wěn)定的性能。迭代 collection 視圖所需的時間與 HashMap 實例的“容量”(桶的數(shù)量)及其大凶吵亍(鍵-值映射關(guān)系數(shù))成比例偏瓤。所以,如果迭代性能很重要椰憋,則不要將初始容量設(shè)置得太高(或?qū)⒓虞d因子設(shè)置得太低)厅克。
2.HashMap和HashTable的區(qū)別
- HashTable的方法是同步的,在方法的前面都有synchronized來同步橙依,HashMap未經(jīng)同步证舟,所以在多線程場合要手動同步。
- HashTable不允許null值(key和value都不可以) ,HashMap允許null值(key和value都可以)窗骑。
- HashTable有一個contains(Object value)功能和containsValue(Object value)功能一樣女责。
- HashTable使用Enumeration進行遍歷,HashMap使用Iterator進行遍歷创译。
- HashTable中hash數(shù)組默認大小是11抵知,增加的方式是 old*2+1。HashMap中hash數(shù)組的默認大小是16软族,而且一定是2的指數(shù)刷喜。
- 哈希值的使用不同,HashTable直接使用對象的hashCode立砸,代碼是這樣的:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
而HashMap重新計算hash值掖疮,而且用與代替求模: ```java
int hash = hash(k);
int i = indexFor(hash, table.length);
static int hash(Object x) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
3. HashMap與HashSet的關(guān)系
- HashSet底層是采用HashMap實現(xiàn)的:
public HashSet() {
map = new HashMap<E,Object>();
}
2. 調(diào)用HashSet的add方法時,實際上是向HashMap中增加了一行(key-value對)仰禽,該行的key就是向HashSet增加的那個對象氮墨,該行的value就是一個Object類型的常量。
4. HashMap 和 ConcurrentHashMap 的關(guān)系
關(guān)于這部分內(nèi)容建議自己去翻翻源碼吐葵,
ConcurrentHashMap
也是一種線程安全的集合類规揪,他和HashTable也是有區(qū)別的,主要區(qū)別就是加鎖的粒度以及如何加鎖温峭,ConcurrentHashMap的加鎖粒度要比HashTable更細一點猛铅。將數(shù)據(jù)分成一段一段的存儲,然后給每一段數(shù)據(jù)配一把鎖凤藏,當(dāng)一個線程占用鎖訪問其中一個段數(shù)據(jù)的時候奸忽,其他段的數(shù)據(jù)也能被其他線程訪問。
5. HashMap實現(xiàn)原理分析
HashMap的數(shù)據(jù)結(jié)構(gòu) 數(shù)據(jù)結(jié)構(gòu)中有數(shù)組和鏈表來實現(xiàn)對數(shù)據(jù)的存儲揖庄,但這兩者基本上是兩個極端栗菜。
數(shù)組:數(shù)組必須事先定義固定的長度(元素個數(shù)),不能適應(yīng)數(shù)據(jù)動態(tài)地增減的情況蹄梢。當(dāng)數(shù)據(jù)增加時疙筹,可能超出原先定義的元素個數(shù);當(dāng)數(shù)據(jù)減少時,造成內(nèi)存浪費而咆。
數(shù)組是靜態(tài)分配內(nèi)存霍比,并且在內(nèi)存中連續(xù)。
數(shù)組利用下標(biāo)定位暴备,時間復(fù)雜度為O(1)
數(shù)組插入或刪除元素的時間復(fù)雜度O(n)
數(shù)組的特點是:尋址容易悠瞬,插入和刪除困難;
鏈表:鏈表存儲區(qū)間離散涯捻,占用內(nèi)存比較寬松浅妆。
鏈表是動態(tài)分配內(nèi)存,并不連續(xù)汰瘫。
鏈表定位元素時間復(fù)雜度O(n)
鏈表插入或刪除元素的時間復(fù)雜度O(1)
鏈表的特點是:尋址困難狂打,插入和刪除容易。
哈希表
那么我們能不能綜合兩者的特性混弥,做出一種尋址容易趴乡,插入刪除也容易的數(shù)據(jù)結(jié)構(gòu)?答案是肯定的蝗拿,這就是我們要提起的哈希表晾捏。
哈希表((Hash table)既滿足了數(shù)據(jù)的查找方便,同時不占用太多的內(nèi)容空間哀托,使用也十分方便惦辛。
哈希表有多種不同的實現(xiàn)方法,我接下來解釋的是最常用的一種方法—— 拉鏈法仓手,我們可以理解為“鏈表的數(shù)組” 胖齐,如圖:
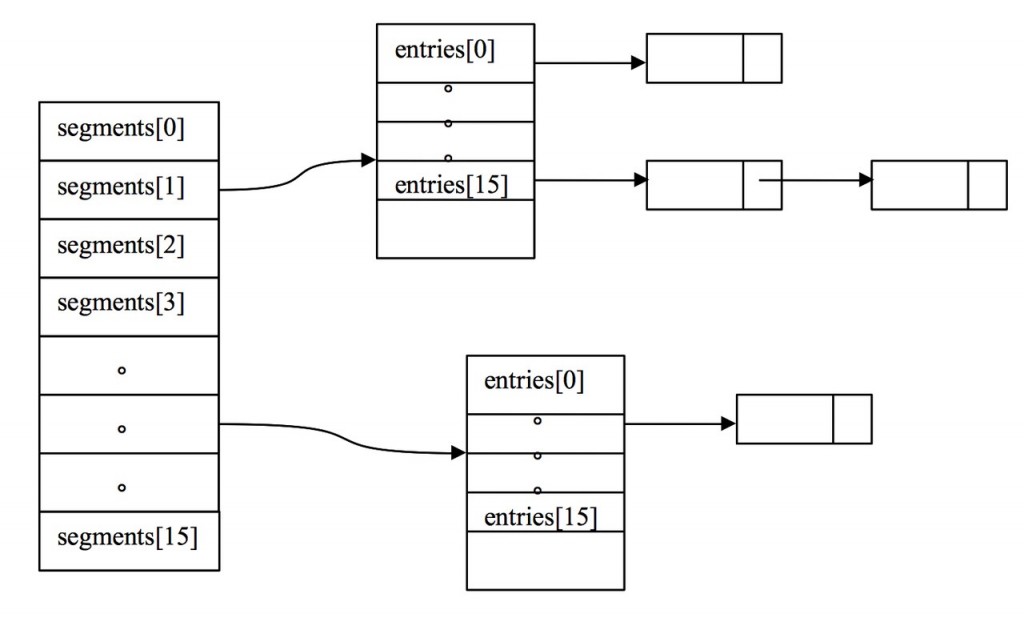
從上圖我們可以發(fā)現(xiàn)哈希表是由數(shù)組+鏈表組成的,一個長度為16的數(shù)組中嗽冒,每個元素存儲的是一個鏈表的頭結(jié)點呀伙。那么這些元素是按照什么樣的規(guī)則存儲到數(shù)組中呢。一般情況是通過hash(key)%len獲得添坊,也就是元素的key的哈希值對數(shù)組長度取模得到剿另。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12贬蛙。所以12雨女、28、108以及140都存儲在數(shù)組下標(biāo)為12的位置阳准。 HashMap其實也是一個線性的數(shù)組實現(xiàn)的,所以可以理解為其存儲數(shù)據(jù)的容器就是一個線性數(shù)組氛堕。這可能讓我們很不解,一個線性的數(shù)組怎么實現(xiàn)按鍵值對來存取數(shù)據(jù)呢野蝇?這里HashMap有做一些處理岔擂。 首先HashMap里面實現(xiàn)一個靜態(tài)內(nèi)部類Entry位喂,其重要的屬性有 key , value, next浪耘,從屬性key,value我們就能很明顯的看出來Entry就是HashMap鍵值對實現(xiàn)的一個基礎(chǔ)bean乱灵,我們上面說到HashMap的基礎(chǔ)就是一個線性數(shù)組,這個數(shù)組就是Entry[]七冲,Map里面的內(nèi)容都保存在Entry[]里面痛倚。
6. HashMap的存取實現(xiàn)
既然是線性數(shù)組,為什么能隨機存壤教伞蝉稳?這里HashMap用了一個小算法,大致是這樣實現(xiàn):
// 存儲時:
int hash = key.hashCode(); // 這個hashCode方法這里不詳述,只要理解每個key的hash是一個固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值時:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
- put
疑問:如果兩個key通過hash%Entry[].length得到的index相同掘鄙,會不會有覆蓋的危險耘戚?
這里HashMap里面用到鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu)的一個概念。上面我們提到過Entry類里面有一個next屬性操漠,作用是指向下一個Entry收津。
打個比方, 第一個鍵值對A進來浊伙,通過計算其key的hash得到的index=0撞秋,記做:Entry[0] = A。一會后又進來一個鍵值對B嚣鄙,通過計算其index也等于0吻贿,現(xiàn)在怎么辦?HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等于0,那么C.next = B,Entry[0] = C哑子;這樣我們發(fā)現(xiàn)index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性鏈接在一起舅列。所以疑問不用擔(dān)心。也就是說數(shù)組中存儲的是最后插入的元素卧蜓。到這里為止帐要,HashMap的大致實現(xiàn),我們應(yīng)該已經(jīng)清楚了烦却。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null總是放在數(shù)組的第一個鏈表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍歷鏈表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在鏈表中已存在宠叼,則替換為新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //參數(shù)e, 是Entry.next
//如果size超過threshold,則擴充table大小其爵。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
當(dāng)然HashMap里面也包含一些優(yōu)化方面的實現(xiàn)冒冬,這里也說一下。比如:Entry[]的長度一定后摩渺,隨著map里面數(shù)據(jù)的越來越長简烤,這樣同一個index的鏈就會很長,會不會影響性能摇幻?HashMap里面設(shè)置一個因子横侦,隨著map的size越來越大挥萌,Entry[]會以一定的規(guī)則加長長度。
- get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到數(shù)組元素枉侧,再遍歷該元素處的鏈表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
- null key的存取
null key總是存放在Entry[]數(shù)組的第一個元素引瀑。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
- 確定數(shù)組index:hashcode % table.length取模
HashMap存取時,都需要計算當(dāng)前key應(yīng)該對應(yīng)Entry[]數(shù)組哪個元素榨馁,即計算數(shù)組下標(biāo)憨栽;算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相當(dāng)于取模mod或者取余%翼虫。 這意味著數(shù)組下標(biāo)相同屑柔,并不表示hashCode相同。
- table初始大小
public HashMap(int initialCapacity, float loadFactor) {
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
7. 解決hash沖突的辦法
開放定址法(線性探測再散列珍剑,二次探測再散列掸宛,偽隨機探測再散列) 再哈希法 鏈地址法 建立一個公共溢出區(qū) Java中hashmap的解決辦法就是采用的鏈地址法。
8. 再散列rehash過程
當(dāng)哈希表的容量超過默認容量時招拙,必須調(diào)整table的大小唧瘾。當(dāng)容量已經(jīng)達到最大可能值時,那么該方法就將容量調(diào)整到Integer.MAX_VALUE返回迫像,這時劈愚,需要創(chuàng)建一張新表,將原表的映射到新表中闻妓。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新計算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
