一、碎碎念
因?yàn)楣ぷ魃嫌杏玫紼xcel做數(shù)據(jù)分析罢艾,之后慢慢接觸到了Python做分析伞矩,做挖掘等脸哀。再然后就遇到了Kaggle這個(gè)網(wǎng)站,發(fā)現(xiàn)這里真是讓人提升技能的圣地扭吁。一直在找些可以提升自己數(shù)據(jù)分析技能撞蜂、思維的項(xiàng)目來(lái)練習(xí),下面主要會(huì)展示一些自己的分析思路侥袜,可視化圖表蝌诡,以及代碼。我的分析環(huán)境是win7 64位 枫吧,anaconda-spyder(Python3.6)
看了kaggle上這個(gè)項(xiàng)目各路大神的代碼思路浦旱,然后自己也躍躍欲試要操刀一練。分析完這個(gè)項(xiàng)目九杂,給自己的領(lǐng)悟是對(duì)于部分的語(yǔ)法颁湖,函數(shù),有個(gè)進(jìn)一步的理解例隆,對(duì)于分析項(xiàng)目應(yīng)該怎么一步步的分析也有了更新甥捺,在初識(shí)這個(gè)項(xiàng)目的時(shí)候是直接杠正面各種嘗試,各種推理镀层,畢竟一個(gè)人閉門造車有時(shí)候會(huì)造不出車镰禾。
寫(xiě)這篇文章也算是對(duì)這個(gè)項(xiàng)目的一個(gè)回顧和總結(jié)。
提醒一點(diǎn)唱逢,在kaggle上注冊(cè)賬號(hào)是可以的吴侦,但是要通過(guò)郵箱激活賬戶的時(shí)候需要一個(gè)VPN。(我用的163的郵箱)?
二坞古、項(xiàng)目背景
本文中用到的數(shù)據(jù)文件:? tmdb_5000_movies.csv 备韧、? tmdb_5000_credits.csv是Kaggle平臺(tái)上的項(xiàng)目TMDB(The Movie Database),共計(jì)4803部電影痪枫,主要為美國(guó)地區(qū)一百年間(1916-2017)的電影作品织堂。
本文通過(guò)對(duì)電影數(shù)據(jù)的分析,利用數(shù)據(jù)可視化的方法听怕,發(fā)現(xiàn)流行趨勢(shì)捧挺,找到投資方向,為本行業(yè)新入局者提供一定參考建議尿瞭。同時(shí)也為了提升自己的數(shù)據(jù)分析能力,在遇到類似項(xiàng)目可以觸類旁通翅睛。
三声搁、項(xiàng)目概覽
點(diǎn)擊下圖可以直接鏈接到Kaggle對(duì)應(yīng)的項(xiàng)目:
[ ](https://www.kaggle.com/tmdb/tmdb-movie-metadata) 下面是官網(wǎng)內(nèi)容簡(jiǎn)介:
BackgroundWhat can we say about the success of a movie before it is released? Are therecertain companies (Pixar?) that have found a consistent formula? Given thatmajor films costing over $100 million to produce can still flop, this questionis more important than ever to the industry. Film aficionados might havedifferent interests. Can we predict which films will be highly rated, whetheror not they are a commercial success?
This is a great place to start digging in to those questions, with data on theplot, cast, crew, budget, and revenues of several thousand films.
We (Kaggle) have removed the original version of this dataset per a DMCA takedownrequest from IMDB. In order to minimize the impact, we're replacing it with asimilar set of films and data fields from The Movie Database (TMDb) inaccordance with their terms of use . The bad news isthat kernels built on the old dataset will most likely no longer work.
The good news is that:
You can port your existing kernels over with a bit of editing. This kernel offers functions and examples for doing so. You can also find a general introduction to the new format here .
The new dataset contains full credits for both the cast and the crew, rather than just the first three actors.
Actor and actresses are now listed in the order they appear in the credits. It's unclear what ordering the original dataset used; for the movies I spot checked it didn't line up with either the credits order or IMDB's stars order.
The revenues appear to be more current. For example, IMDB's figures for Avatar seem to be from 2010 and understate the film's global revenues by over $2 billion.
Some of the movies that we weren't able to port over (a couple of hundred) were just bad entries. For example, this IMDB entry has basically no accurate information at all. It lists Star Wars Episode VII as a documentary.
Several of the new columns contain json. You can save a bit of time by porting the load data functions from this kernel.
Even in simple fields like runtime may not be consistent across versions. For example, previous dataset shows the duration for Avatar's extended cut while TMDB shows the time for the original version.
There's now a separate file containing the full credits for both the cast and crew.
All fields are filled out by users so don't expect them to agree on keywords, genres, ratings, or the like.
Your existing kernels will continue to render normally until they are re-run.
If you are curious about how this dataset was prepared, the code to access TMDb's API is posted here .
** 四黑竞、前置思路? **
“運(yùn)籌帷幄,決勝千里疏旨『芑辏”古時(shí)候老司機(jī)的話對(duì)我們進(jìn)行數(shù)據(jù)分析時(shí)依然有用惋砂。?
我的習(xí)慣看到一個(gè)項(xiàng)目饱溢,先打開(kāi)數(shù)據(jù)文件看看其中的數(shù)據(jù)是什么樣子的,大概有多少字段码泞,每個(gè)字段里的數(shù)據(jù)是個(gè)什么類型谁榜。?
俗話說(shuō)得好幅聘,讓自己有點(diǎn)B數(shù)。
Kaggle平臺(tái)上下載2個(gè)原始數(shù)據(jù)集: tmdb_5000_movies.csv 和 tmdb_5000_credits.csv窃植,前者存放電影的基本信息帝蒿,后者存放電影的演職員名單。?
不管怎么樣的數(shù)據(jù)分析任務(wù)都需要遵從一個(gè)標(biāo)準(zhǔn)流程巷怜,有了流程指導(dǎo)葛超,分析思路和處理過(guò)程才不會(huì)讓自己進(jìn)入迷失森林。
數(shù)據(jù)分析的流程:1.提出問(wèn)題2.理解數(shù)據(jù)3.數(shù)據(jù)清洗4.建立模型5.數(shù)據(jù)可視化? 6.形成數(shù)據(jù)分析報(bào)告
五延塑、提出問(wèn)題
如果我是電影行業(yè)的數(shù)據(jù)分析師 绣张,一定要讓自己身臨其境站在制作公司的角度出發(fā)去思考。(這一點(diǎn)很關(guān)鍵)
現(xiàn)在公司要制作電影关带,想知道電影預(yù)算胖替、評(píng)分與票房的關(guān)系,各種電影類型隨時(shí)間變化的趨勢(shì)圖豫缨,電影產(chǎn)量独令、票房的趨勢(shì),哪些風(fēng)格電影最受歡迎等問(wèn)題好芭,則可提出如下問(wèn)題:
問(wèn)題1:電影風(fēng)格隨時(shí)間的變化趨勢(shì)
問(wèn)題2:不同風(fēng)格電影的收益能力
問(wèn)題3:比較行業(yè)內(nèi)Universal Pictures與Paramount Pictures兩家巨頭公司的業(yè)績(jī)
問(wèn)題4:票房收入與哪些因素最相關(guān)
六燃箭、理解數(shù)據(jù)
下面的變量名是數(shù)據(jù)中出現(xiàn)的,也是2個(gè)數(shù)據(jù)表格中的列名舍败。?
七招狸、數(shù)據(jù)清洗
數(shù)據(jù)清洗主要分三步:1.數(shù)據(jù)預(yù)處理;2.特征提攘谑怼裙戏;3.特征選取。
7.1 數(shù)據(jù)預(yù)處理
在數(shù)據(jù)預(yù)處理時(shí)厕诡,主要包括:? 發(fā)現(xiàn)和填補(bǔ)缺失值 累榜、? 數(shù)據(jù)類型轉(zhuǎn)換 、? 異常值刪除等。數(shù)據(jù)中release_date列缺失1條數(shù)據(jù)壹罚,runtime列缺失2條數(shù)據(jù)葛作,均可通過(guò)索引的方式找到具體是哪一部電影,然后上網(wǎng)搜索準(zhǔn)確的缺失數(shù)據(jù)猖凛,將其填補(bǔ)(詳見(jiàn)后續(xù)代碼)赂蠢。對(duì)于release_date列,需將其轉(zhuǎn)換為日期類型辨泳,然后提取出“年份”數(shù)據(jù)虱岂。
7.2 特征提取
在我們處理數(shù)據(jù)的過(guò)程中:通過(guò)json.loads先將JSON字符串轉(zhuǎn)換為 字典列表"[{},{},{}]"的形式,再遍歷每個(gè)字典菠红,取出鍵(key)為‘name’所對(duì)應(yīng)的值(value)第岖,并將這些值(value)用 “|”分隔,形成一個(gè)“多選題”的結(jié)構(gòu)途乃。在進(jìn)行具體問(wèn)題分析的時(shí)候绍傲,再將“多選題”編碼為虛擬變量,即所有多選題的每一個(gè)不重復(fù)的選項(xiàng)耍共,拿出來(lái)作為新變量烫饼,每一條觀測(cè)包含該選項(xiàng)則填1,否則填0试读。
7.3 特征選取
在分析每一個(gè)小問(wèn)題之前杠纵,最重要的步驟是需要通過(guò)特征選取,構(gòu)造出適合分析的結(jié)構(gòu)钩骇,只有結(jié)構(gòu)“造”對(duì)了比藻,后續(xù)的可視化才能得出正確的圖形。
這里的小竅門就是:? 分析每一個(gè)小問(wèn)題時(shí)倘屹,盡量新建一個(gè)數(shù)據(jù)框银亲,存放要分析的變量,而不是在原始數(shù)據(jù)框上“亂涂亂畫(huà)”? 纽匙,否則最后必定抓狂务蝠。
八、數(shù)據(jù)可視化
本次使用到的圖形類型有:柱狀圖烛缔、餅圖馏段、散點(diǎn)圖。
九践瓷、代碼部分
首先我們需要代入一些用到的包院喜,并不是一下子就要導(dǎo)入pandas、numpy晕翠、matplotlib等等喷舀,包是在寫(xiě)代碼的時(shí)候遇到問(wèn)題一個(gè)個(gè)添加的,然后寫(xiě)到最前面。
9.1理解數(shù)據(jù)
[/code]
?? import numpy as np
?? import pandas as pd
?? import matplotlib.pyplot as plt
?? import matplotlib
?? #%matplotlib inline
?? import json
?? import warnings
?? warnings.filterwarnings('ignore')
?? import seaborn as sns
?? sns.set(color_codes=True)
?? #設(shè)置表格用什么字體
?? font = {
? ? ?? 'family' : 'SimHei'
?? }
?? matplotlib.rc('font', **font)
?? #導(dǎo)入數(shù)據(jù)
?? movies = pd.read_csv('C:\\kaggle_from0\\tmdb_5000_movies\\tmdb_5000_movies.csv')
?? creditss = pd.read_csv('C:\\kaggle_from0\\tmdb_5000_movies\\tmdb_5000_credits.csv')
?? #查看movies中數(shù)據(jù)
?? movies.head()
?? #查看movies中所有列名元咙,以字典形式存儲(chǔ)
?? movies.columns
?? ##查看creditss中數(shù)據(jù)
?? creditss.head()
?? #查看creditss中所有列名梯影,以字典形式存儲(chǔ),一共4個(gè)列名
?? creditss.columns
?? #兩個(gè)數(shù)據(jù)框中的title列重復(fù)了巫员,刪除credits中的title列庶香,還剩3個(gè)列名
?? del creditss['title']
?? #movies中的id列與credits中的movie_id列實(shí)際上等同,可當(dāng)做主鍵合并數(shù)據(jù)框
?? full = pd.merge(movies, creditss, left_on='id', right_on='movie_id', how='left')
?? #某些列不在本次研究范圍简识,將其刪除
?? full.drop(['homepage','original_title','overview','spoken_languages',
? ? ? ? ? ? ? 'status','tagline','movie_id'],axis=1,inplace=True)
?? #查看數(shù)據(jù)信息赶掖,每個(gè)字段數(shù)據(jù)量。
?? full.info()
[/code]
#####? 9.2數(shù)據(jù)清洗
首先七扰,判斷哪些列有缺失值奢赂,以Ture=缺失, False=不缺失颈走,得到? release_date? 膳灶,? runtime? 有缺失值。
```code
?? full.isnull().any()
[/code]
release_date列有1條缺失數(shù)據(jù)立由,將其查找出來(lái)
```code
?? full.loc[full['release_date'].isnull()==True]
[/code]
根據(jù)title經(jīng)上網(wǎng)搜索轧钓,該影片上映日期為2014年6月1日,填補(bǔ)該值
```code
?? full['release_date'] = full['release_date'].fillna('2014-06-01')
[/code]
runtime列有2條缺失數(shù)據(jù)锐膜,將其查找出來(lái)
```code
?? full.loc[full['runtime'].isnull()==True]
[/code]
根據(jù)title經(jīng)上網(wǎng)搜索毕箍,影片時(shí)長(zhǎng)分別為94分鐘和240分鐘,填補(bǔ)缺失值
```code
?? full['runtime'] = full['runtime'].fillna(94, limit=1)#limit=1道盏,限制每次只填補(bǔ)一個(gè)值
?? full['runtime'] = full['runtime'].fillna(240, limit=1)
[/code]
將release_date列轉(zhuǎn)換為日期類型
```code
?? full['release_date'] = pd.to_datetime(full['release_date'],
? ? ?? format='%Y-%m-%d', errors='coerce').dt.year
[/code]
genres,keywords,production_companies,production_countries,cast,crew列為json類型 ?
需要解析json數(shù)據(jù)而柑,分兩步: ?
1. json本身為字符串類型,先轉(zhuǎn)換為字典列表 ?
2. 再將字典列表轉(zhuǎn)換為荷逞,以'|'分割的字符串
定義一個(gè)json類型的列名列表 ?
```code
?? json_column = ['genres','keywords','production_companies',
? ? ? ? ? ? ? ? ? 'production_countries','cast','crew']
[/code]
將各json列轉(zhuǎn)換為字典列表
```code
?? for column in json_column:
? ? ?? full[column]=full[column].map(json.loads)
[/code]
函數(shù)功能:將字典內(nèi)的鍵‘name’對(duì)應(yīng)的值取出媒咳,生成用'|'分隔的字符串
```code
?? def getname(x):
? ? ?? list = []
? ? ?? for i in x:
? ? ? ? ?? list.append(i['name'])
? ? ?? return '|'.join(list)
[/code]
對(duì)genres,keywords,production_companies,production_countries列執(zhí)行函數(shù) ?
```code
?? for column in json_column[0:4]:
? ? ?? full[column] = full[column].map(getname)
[/code]
定義提取2名主演的函數(shù):
```code
?? def getcharacter(x):
? ? ?? list = []
? ? ?? for i in x:
? ? ? ? ?? list.append(i['character'])
? ? ?? return '|'.join(list[0:2])
[/code]
對(duì)cast列執(zhí)行函數(shù)
```code
?? full['cast']=full['cast'].map(getcharacter)
[/code]
定義提取導(dǎo)演的函數(shù):
```code
?? def getdirector(x):
? ? ?? list=[]
? ? ?? for i in x:
? ? ? ? ?? if i['job']=='Director':
? ? ? ? ? ? ?? list.append(i['name'])
? ? ?? return "|".join(list)
[/code]
對(duì)crew列執(zhí)行函數(shù)
```code
?? full['crew']=full['crew'].map(getdirector)
[/code]
重命名列
```code
?? rename_dict = {'release_date':'year','cast':'actor','crew':'director'}
?? full.rename(columns=rename_dict, inplace=True)
[/code]
查看full表格中前2行數(shù)據(jù)
```code
?? full.head(2)
[/code]
備份原始數(shù)據(jù)框original_df
```code
?? original_df = full.copy()
[/code]
###? 到此為止,我們的數(shù)據(jù)預(yù)處理告一段落种远。
###? 9.3數(shù)據(jù)可視化
**9.3.1問(wèn)題1:** 研究電影風(fēng)格隨時(shí)間的變化趨勢(shì)涩澡,提取所有的電影風(fēng)格,存儲(chǔ)在有去重功能的集合中院促。 ?
```code
?? genre_set = set() ? #設(shè)置空集合
?? for x in full['genres']:
? ? ?? genre_set.update(x.split('|'))? #genres數(shù)據(jù)以'|'來(lái)分隔
?? genre_set.discard('')? #刪除''字符
[/code]
對(duì)各種電影風(fēng)格genre筏养,進(jìn)行one-hot編碼 ?
```code
?? genre_df = pd.DataFrame()? # 創(chuàng)建空的數(shù)據(jù)框
?? for genre in genre_set:
? ? ?? #如果一個(gè)值中包含特定內(nèi)容,則編碼為1常拓,否則編碼為0
? ? ?? genre_df[genre] = full['genres'].str.contains(genre).map(lambda x:1 if x else 0)
[/code]
將原數(shù)據(jù)集中的year列渐溶,添加至genre_df數(shù)據(jù)框中
```code
?? genre_df['year']=full['year']
[/code]
將genre_df按year分組,計(jì)算每組之和弄抬。groupby之后茎辐,year列通過(guò)默認(rèn)參數(shù)as_index=True自動(dòng)轉(zhuǎn)化為df.index
```code
?? genre_by_year = genre_df.groupby('year').sum() ?
?? genresum_by_year = genre_by_year.sum().sort_values(ascending=False)
[/code]
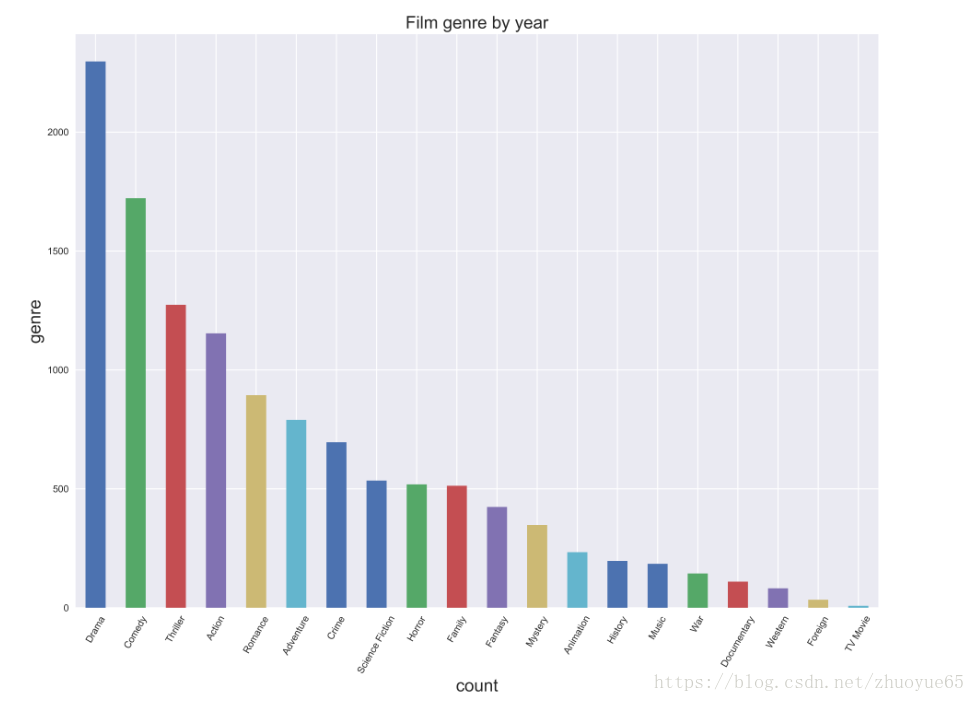
計(jì)算每個(gè)風(fēng)格genre的電影總數(shù)目,并降序排列,再可視化
```code
?? fig = plt.figure(figsize=(15,11)) ? #設(shè)置畫(huà)圖框的大小
?? ax = plt.subplot(1,1,1) ? ? #設(shè)置框的位置
?? ax = genresum_by_year.plot.bar()
?? plt.xticks(rotation=60)
?? plt.title('Film genre by year', fontsize=18) ?? #設(shè)置標(biāo)題的字體大小拖陆,標(biāo)題名
?? plt.xlabel('count', fontsize=18) ?? #X軸名及軸名大小
?? plt.ylabel('genre', fontsize=18) ?? #y軸名及軸名大小
?? plt.show()? #可以用查看數(shù)據(jù)畫(huà)的圖弛槐。
?? #保存圖片
?? fig.savefig('film genre by year.png',dpi=600)
[/code]
 ?
篩選出電影風(fēng)格TOP8
```code
?? genre_by_year = genre_by_year[['Drama','Comedy','Thriller','Romance',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 'Adventure','Crime', 'Science Fiction',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 'Horror']].loc[1960:,:]
?? year_min = full['year'].min() ? #最小年份
?? year_max = full['year'].max() ? #最大年份
[/code]
可視化電影風(fēng)格genre隨時(shí)間的變化趨勢(shì)(1960年至今)
```code
?? fig = plt.figure(figsize=(10,8))
?? ax1 = plt.subplot(1,1,1)
?? plt.plot(genre_by_year)
?? plt.xlabel('Year', fontsize=12)
?? plt.ylabel('Film count', fontsize=12)
?? plt.title('Film count by year', fontsize=15)
?? plt.xticks(range(1960, 2017, 10))? #橫坐標(biāo)每隔10年一個(gè)刻度
?? #plt.legend(loc='best',ncol=2) #https://blog.csdn.net/you_are_my_dream/article/details/53440964
?? plt.legend(['Drama(戲劇類)','Comedy(喜劇類)','Thriller(驚悚類)','Romance(浪漫類)',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 'Adventure(Adventure)','Crime(犯罪類)', 'Science Fiction(科幻類)',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 'Horror(驚恐類)'], loc='best',ncol=2) #設(shè)置說(shuō)明標(biāo)簽
?? fig.savefig('film count by year.png',dpi=200)
[/code]
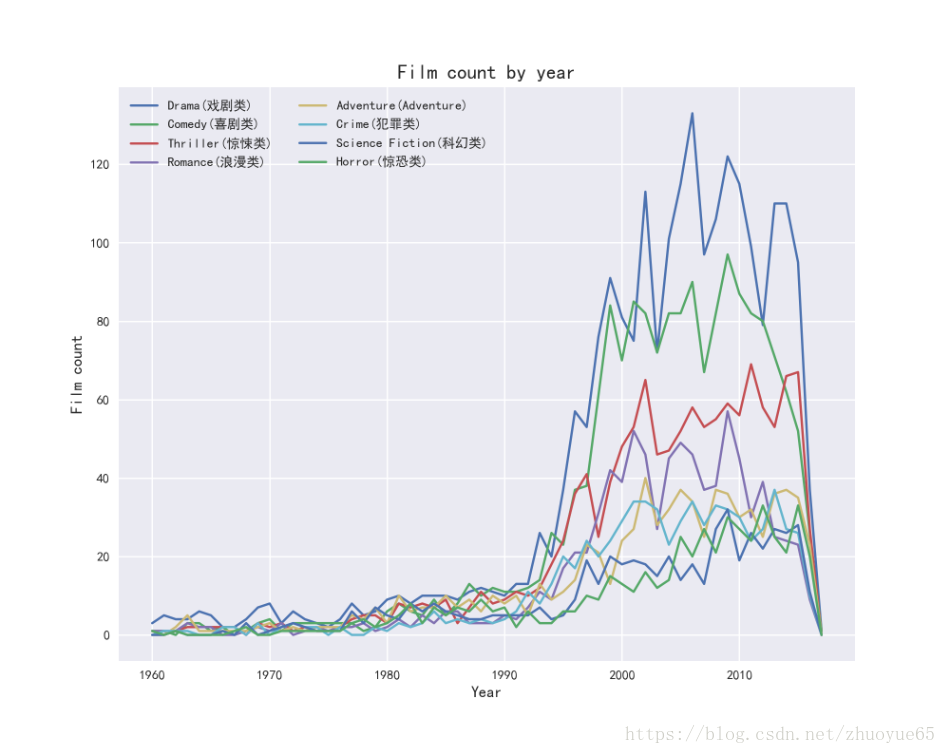 ?
可以看出,從上世紀(jì)90年代開(kāi)始依啰,整個(gè)電影市場(chǎng)呈現(xiàn)爆發(fā)式增長(zhǎng)乎串。其中,排名前五的戲劇類(Drama)速警、喜劇類(Comedy)叹誉、驚悚類(Thriller)、浪漫類(Romance)闷旧、冒險(xiǎn)類(Adventure)電影數(shù)量增長(zhǎng)顯著长豁。
**9.3.2問(wèn)題2:** 不同風(fēng)格電影的收益能力 ?
增加收益列 ?
```code
?? full['profit'] = full['revenue']-full['budget']
[/code]
創(chuàng)建收益數(shù)據(jù)框
```code
?? profit_df = pd.DataFrame()#創(chuàng)建空的數(shù)據(jù)框
?? profit_df = pd.concat([genre_df.iloc[:,:-1],full['profit']],axis=1)? #合并
?? profit_df.head()#查看新數(shù)據(jù)框信息
[/code]
創(chuàng)建一個(gè)Series,其index為各個(gè)genre忙灼,值為按genre分類計(jì)算的profit之和
```code
?? profit_by_genre = pd.Series(index=genre_set)
?? for genre in genre_set:
? ? ?? profit_by_genre.loc[genre]=profit_df.loc[:,[genre,'profit']].groupby(genre, as_index=False).sum().loc[1,'profit']
?? print(profit_by_genre)
[/code]
創(chuàng)建一個(gè)Series匠襟,其index為各個(gè)genre,值為按genre分類計(jì)算的budget之和 ?
```code
?? budget_df = pd.concat([genre_df.iloc[:,:-1],full['budget']],axis=1)
?? budget_df.head(2)
?? budget_by_genre = pd.Series(index=genre_set)
?? for genre in genre_set:
? ? ?? budget_by_genre.loc[genre]=budget_df.loc[:,[genre,'budget']].groupby(genre,as_index=False).sum().loc[1,'budget']
?? print(budget_by_genre)
[/code]
向合并數(shù)據(jù)框
```code
?? profit_rate = pd.concat([profit_by_genre, budget_by_genre],axis=1)
?? profit_rate.columns=['profit','budget'] ? #更改列名
[/code]
加收益率列
```code
?? profit_rate['profit_rate'] = (profit_rate['profit']/profit_rate['budget'])*100
?? profit_rate.sort_values(by=['profit','profit_rate'], ascending=False, inplace=True)
?? #print(profit_rate)
[/code]
x為索引長(zhǎng)度的序列
```code
?? x = list(range(len(profit_rate.index)))
[/code]
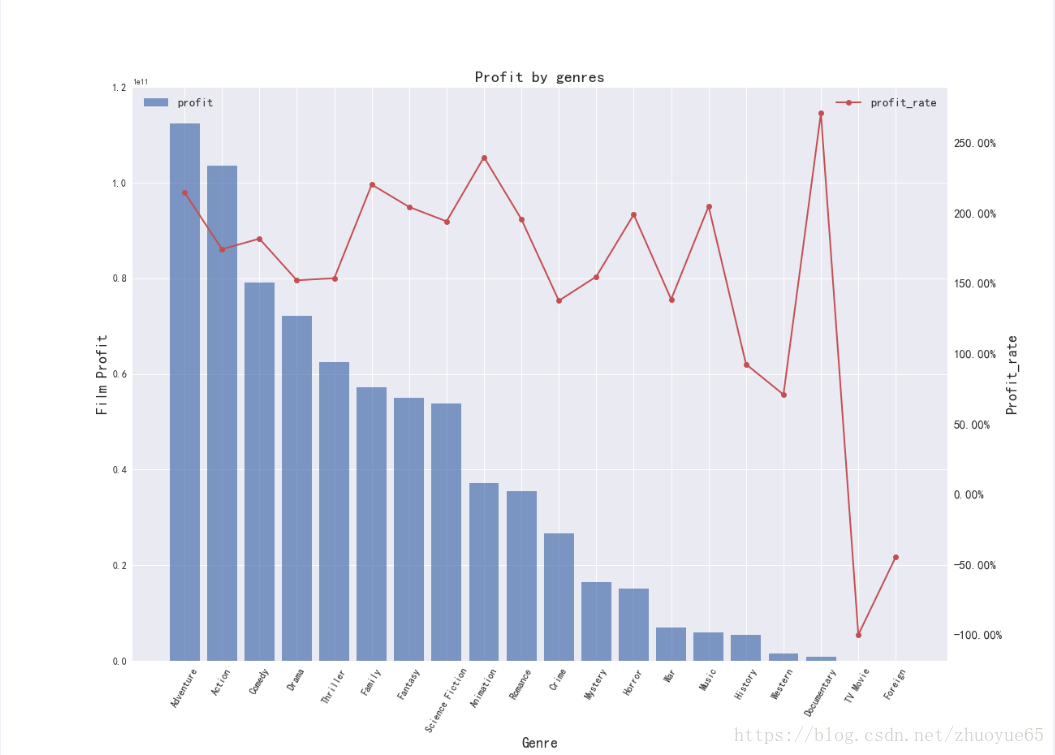
可視化不同風(fēng)格電影的收益(柱狀圖)和收益率(折線圖)
```code
?? fig = plt.figure(figsize=(18,13))
?? ax1 = fig.add_subplot(111)
?? plt.bar(x, profit_rate['profit'],label='profit',alpha=0.7)
?? plt.xticks(x,xl,rotation=60,fontsize=12)
?? plt.yticks(fontsize=12)
?? ax1.set_title('Profit by genres', fontsize=20)
?? ax1.set_ylabel('Film Profit',fontsize=18)
?? ax1.set_xlabel('Genre',fontsize=18)
?? ax1.set_ylim(0,1.2e11)
?? ax1.legend(loc=2,fontsize=15)
[/code]
次縱坐標(biāo)軸標(biāo)簽設(shè)置為百分比顯示
```code
?? import matplotlib.ticker as mtick
?? ax2 = ax1.twinx()
?? ax2.plot(x, profit_rate['profit_rate'],'ro-',lw=2,label='profit_rate')
?? fmt='%.2f%%'
?? yticks = mtick.FormatStrFormatter(fmt)
?? ax2.yaxis.set_major_formatter(yticks)
?? plt.xticks(x,xl,fontsize=12,rotation=60)
?? plt.yticks(fontsize=15)
?? ax2.set_ylabel('Profit_rate',fontsize=18)
?? ax2.legend(loc=1,fontsize=15)
?? plt.grid(False)
?? #保存圖片
?? fig.savefig('profit by genres.png')
[/code]
**9.3.3問(wèn)題3:** 比較Universal Pictures與Paramount Pictures兩家巨頭公司的業(yè)績(jī) ?
創(chuàng)建公司數(shù)據(jù)框 ?
```code
?? company_list = ['Universal Pictures', 'Paramount Pictures']
?? company_df = pd.DataFrame()
?? for company in company_list:
? ? ?? company_df[company]=full['production_companies'].str.contains(company).map(lambda x:1 if x else 0)
?? company_df = pd.concat([company_df,genre_df.iloc[:,:-1],full['revenue']],axis=1)
[/code]
創(chuàng)建巨頭對(duì)比數(shù)據(jù)框
```code
?? Uni_vs_Para = pd.DataFrame(index=['Universal Pictures', 'Paramount Pictures'],
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? columns=company_df.columns[2:])
[/code]
計(jì)算兩家公司各自收益總額
```code
?? Uni_vs_Para.loc['Universal Pictures']=company_df.groupby('Universal Pictures',
? ? ? ? ? ? ? ? ? as_index=False).sum().iloc[1,2:]
?? Uni_vs_Para.loc['Paramount Pictures']=company_df.groupby('Paramount Pictures',
? ? ? ? ? ? ? ? ? as_index=False).sum().iloc[1,2:]
[/code]
可視化兩公司票房收入對(duì)比
```code
?? fig = plt.figure(figsize=(4,3))
?? ax = fig.add_subplot(111)
?? Uni_vs_Para['revenue'].plot(ax=ax,kind='bar')
?? plt.xticks(rotation=0)
?? plt.title('Universal VS. Paramount')
?? plt.ylabel('Revenue')
?? fig.savefig('Universal vs Paramount by revenue.png')
[/code]
"""Universal Pictrues總票房收入高于Paramount Pictures"""
```code
?? Uni_vs_Para = Uni_vs_Para.T
[/code]
分解兩公司數(shù)據(jù)框
```code
?? universal = Uni_vs_Para['Universal Pictures'].iloc[:-1]
?? paramount = Uni_vs_Para['Paramount Pictures'].iloc[:-1]
[/code]
將universal數(shù)量排名9之后的加和该园,命名為others
```code
?? universal['others']=universal.sort_values(ascending=False).iloc[8:].sum()
?? universal = universal.sort_values(ascending=True).iloc[-9:]
[/code]
將paramount數(shù)量排名9之后的加和酸舍,命名為others ?
```code
?? paramount['others']=paramount.sort_values(ascending=False).iloc[8:].sum()
?? paramount = paramount.sort_values(ascending=True).iloc[-9:]
[/code]
可視化兩公司電影風(fēng)格數(shù)量占比
```code
?? fig = plt.figure(figsize=(13,6))
?? ax1 = plt.subplot(1,2,1)
?? ax1 = plt.pie(universal, labels=universal.index, autopct='%.2f%%',startangle=90,pctdistance=0.75)
?? plt.title('Universal Pictures',fontsize=15)
?? ax2 = plt.subplot(1,2,2)
?? ax2 = plt.pie(paramount, labels=paramount.index, autopct='%.2f%%',startangle=90,pctdistance=0.75)
?? plt.title('Paramount Pictures',fontsize=15)
[/code]
###? 9.3.4問(wèn)題4:? 看看票房與哪些因素有關(guān)
計(jì)算相關(guān)系數(shù)矩陣
```code
?? full[['runtime','popularity','vote_average',
? ? ? ?? 'vote_count','budget','revenue']].corr()
[/code]
受歡迎度和票房相關(guān)性:0.64 ?
評(píng)價(jià)次數(shù)和票房相關(guān)性:0.78 ?
電影預(yù)算和票房相關(guān)性:0.73
創(chuàng)建票房收入數(shù)據(jù)框 ?
```code
?? revenue = full[['popularity','vote_count','budget','revenue']]
[/code]
可視化票房收入分別與受歡迎度(藍(lán))、評(píng)價(jià)次數(shù)(綠)爬范、電影預(yù)算(紅)的相關(guān)性散點(diǎn)圖父腕,并配線性回歸線。
```code
?? fig = plt.figure(figsize=(17,5))
?? ax1 = plt.subplot(1,3,1)
?? ax1 = sns.regplot(x='popularity', y='revenue', data=revenue, x_jitter=.1)
?? ax1.text(400,2e9,'r=0.64',fontsize=15)
?? plt.title('revenue by popularity',fontsize=15)
?? plt.xlabel('popularity',fontsize=13)
?? plt.ylabel('revenue',fontsize=13)
?? ax2 = plt.subplot(1,3,2)
?? ax2 = sns.regplot(x='vote_count', y='revenue', data=revenue, x_jitter=.1,color='g',marker='+')
?? ax2.text(6800,1.1e9,'r=0.78',fontsize=15)
?? plt.title('revenue by vote_count',fontsize=15)
?? plt.xlabel('vote_count',fontsize=13)
?? plt.ylabel('revenue',fontsize=13)
?? ax3 = plt.subplot(1,3,3)
?? ax3 = sns.regplot(x='budget', y='revenue', data=revenue, x_jitter=.1,color='r',marker='^')
?? ax3.text(1.6e8,2.2e9,'r=0.73',fontsize=15)
?? plt.title('revenue by budget',fontsize=15)
?? plt.xlabel('budget',fontsize=13)
?? plt.ylabel('revenue',fontsize=13)
?? fig.savefig('revenue.png')
[/code]
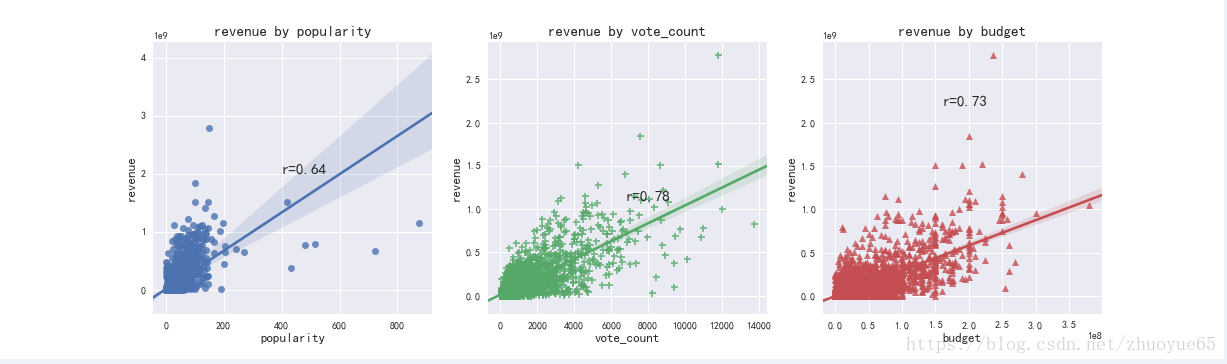
電影評(píng)次與票房收入最相關(guān)(綠色)青瀑,電影預(yù)算與票房收入高度相關(guān)(紅色)璧亮,受歡迎度與評(píng)次高度相關(guān),因此與票房收入相關(guān)性較高斥难。 ?
建議:增加電影預(yù)算 用于電影本身枝嘶、多用于渠道宣傳
十、一些分析中用到的語(yǔ)法哑诊,當(dāng)時(shí)查閱了資料整理一下群扶。
(下次補(bǔ)充)

