更多干貨就在我的個人博客 http://blackblog.tech 歡迎關(guān)注幻碱!
這一篇雖然叫做:十分鐘上手sklearn:特征提取,常用模型细溅,但是寫著寫著我就想把每一個模型都詳細(xì)說一下褥傍,所以也可以看作是機(jī)器學(xué)習(xí)算法概述了。
上一篇我們講解了如何安裝sklearn,導(dǎo)入自帶數(shù)據(jù)集喇聊,創(chuàng)建數(shù)據(jù)恍风,對數(shù)據(jù)進(jìn)行預(yù)處理,通過上一篇的講解誓篱,相信大家能夠感受到sklearn的強(qiáng)大之處朋贬。
這一篇,我們將對sklearn中有關(guān)特征提取窜骄,常用模型進(jìn)行講解兄世。
主要內(nèi)容包括:
1.PCA算法
2.LDA算法
3.線性回歸
4.邏輯回歸
5.樸素貝葉斯
6.決策樹
7.SVM
8.神經(jīng)網(wǎng)絡(luò)
9.KNN算法
是不是感覺干貨滿滿啊啊研!Let's get moving!!!
特征提取
我們獲取的數(shù)據(jù)中很多數(shù)據(jù)往往有很多維度御滩,但并不是所有的維度都是有用的,有意義的党远,所以我們要將對結(jié)果影響較小的維度舍去削解,保留對結(jié)果影響較大的維度。
PCA(主成分分析)與LDA(線性評價分析)是特征提取的兩種經(jīng)典算法沟娱。PCA與LDA本質(zhì)上都是學(xué)習(xí)一個投影矩陣氛驮,使樣本在新的坐標(biāo)系上的表示具有相應(yīng)的特性,樣本在新坐標(biāo)系的坐標(biāo)相當(dāng)于新的特征济似,保留下的新特征應(yīng)當(dāng)是對結(jié)果有較大影響的特征矫废。
PCA(主成分分析)
最大方差理論:信號具有較大的方差,噪聲具有較小的方差
PCA的目標(biāo):新坐標(biāo)系上數(shù)據(jù)的方差越大越好
PCA是無監(jiān)督的學(xué)習(xí)方法
PCA實(shí)現(xiàn)起來并不復(fù)雜(過幾天寫一篇使用NumPy實(shí)現(xiàn)的PCA)砰蠢,但是在sklearn就更為簡單了蓖扑,直接食用skleran.decomposition即可
import sklearn.decomposition as sk_decomposition
pca = sk_decomposition.PCA(n_components='mle',whiten=False,svd_solver='auto')
pca.fit(iris_X)
reduced_X = pca.transform(iris_X) #reduced_X為降維后的數(shù)據(jù)
print('PCA:')
print ('降維后的各主成分的方差值占總方差值的比例',pca.explained_variance_ratio_)
print ('降維后的各主成分的方差值',pca.explained_variance_)
print ('降維后的特征數(shù)',pca.n_components_)
參數(shù)說明:
n_components:指定希望PCA降維后的特征維度數(shù)目(>1), 指定主成分的方差和所占的最小比例閾值(0-1)台舱,'mle'用MLE算法根據(jù)特征的方差分布情況自己去選擇一定數(shù)量的主成分特征來降維
whiten: 判斷是否進(jìn)行白化律杠。白化:降維后的數(shù)據(jù)的每個特征進(jìn)行歸一化,讓方差都為1
svd_solver:奇異值分解SVD的方法{‘a(chǎn)uto’, ‘full’, ‘a(chǎn)rpack’, ‘randomized’}
打印結(jié)果:
下面打印的內(nèi)容只是幫助大家理解pca的參數(shù),就不打印降維后的數(shù)據(jù)了柜去,打印出來并沒有什么意義灰嫉。
PCA:
降維后的各主成分的方差值占總方差值的比例 [ 0.92461621 0.05301557 0.01718514]
降維后的各主成分的方差值 [ 4.22484077 0.24224357 0.07852391]
降維后的特征數(shù) 3
LDA(線性評價分析)
LDA基于費(fèi)舍爾準(zhǔn)則,即同一類樣本盡可能聚合在一起嗓奢,不同類樣本應(yīng)該盡量擴(kuò)散讼撒;或者說,同雷洋被具有較好的聚合度股耽,類別間具有較好的擴(kuò)散度椿肩。
既然涉及到了類別,那么LDA肯定是一個有監(jiān)督算法豺谈,其實(shí)LDA既可以做特征提取液可以做分類郑象。
LDA具體的實(shí)現(xiàn)流程這里就不再贅述了,直接看skleran如何實(shí)現(xiàn)LDA茬末。
import sklearn.discriminant_analysis as sk_discriminant_analysis
lda = sk_discriminant_analysis.LinearDiscriminantAnalysis(n_components=2)
lda.fit(iris_X,iris_y)
reduced_X = lda.transform(iris_X) #reduced_X為降維后的數(shù)據(jù)
print('LDA:')
print ('LDA的數(shù)據(jù)中心點(diǎn):',lda.means_) #中心點(diǎn)
print ('LDA做分類時的正確率:',lda.score(X_test, y_test)) #score是指分類的正確率
print ('LDA降維后特征空間的類中心:',lda.scalings_) #降維后特征空間的類中心
參數(shù)說明:
n_components:指定希望PCA降維后的特征維度數(shù)目(>1)
svd_solver:奇異值分解SVD的方法{‘a(chǎn)uto’, ‘full’, ‘a(chǎn)rpack’, ‘randomized’}
打印結(jié)果:
下面打印的內(nèi)容只是幫助大家理解lda的參數(shù)厂榛,就不打印降維后的數(shù)據(jù)了,打印出來并沒有什么意義丽惭。
LDA:
LDA的數(shù)據(jù)中心點(diǎn):
[[ 5.006 3.418 1.464 0.244]
[ 5.936 2.77 4.26 1.326]
[ 6.588 2.974 5.552 2.026]]
LDA做分類時的正確率: 0.980952380952
LDA降維后特征空間的類中心:
[[-0.81926852 0.03285975]
[-1.5478732 2.15471106]
[ 2.18494056 -0.93024679]
[ 2.85385002 2.8060046 ]]
常用模型
好了击奶,好了,終于可以開始講模型了责掏,其實(shí)這才是我想講的重點(diǎn)啊柜砾,沒想到前面的內(nèi)容都講了這么多。换衬。痰驱。
機(jī)器學(xué)習(xí)常用的算法也就那幾個,sklearn中對其都做了實(shí)現(xiàn)瞳浦,我們只需要調(diào)用即可担映。下面每一個算法的原理我就不細(xì)講了,只講怎么用叫潦,以后會寫這些算法的具體原理與實(shí)現(xiàn)方式蝇完。
干貨要來了,準(zhǔn)備好矗蕊!
首先sklearn中所有的模型都有四個固定且常用的方法短蜕,其實(shí)在PCA與LDA中我們已經(jīng)用到了這些方法中的fit方法。
# 擬合模型
model.fit(X_train, y_train)
# 模型預(yù)測
model.predict(X_test)
# 獲得這個模型的參數(shù)
model.get_params()
# 為模型進(jìn)行打分
model.score(data_X, data_y) # 回歸問題:以R2參數(shù)為標(biāo)準(zhǔn) 分類問題:以準(zhǔn)確率為標(biāo)準(zhǔn)
線性回歸
線性回歸是利用數(shù)理統(tǒng)計中回歸分析傻咖,來確定兩種或兩種以上變量間相互依賴的定量關(guān)系的一種統(tǒng)計分析方法朋魔,運(yùn)用十分廣泛。其表達(dá)形式為y = w'x+e没龙,e為誤差服從均值為0的正態(tài)分布铺厨。
回歸分析中,只包括一個自變量和一個因變量硬纤,且二者的關(guān)系可用一條直線近似表示解滓,這種回歸分析稱為一元線性回歸分析。如果回歸分析中包括兩個或兩個以上的自變量筝家,且因變量和自變量之間是線性關(guān)系洼裤,則稱為多元線性回歸分析。
其實(shí)溪王,說白了腮鞍,就是用一條直線去擬合一大堆數(shù)據(jù),最后把系數(shù)w和截距b算出來莹菱,直線也就算出來了移国, 就可以拿去做預(yù)測了。
sklearn中線性回歸使用最小二乘法實(shí)現(xiàn)道伟,使用起來非常簡單迹缀。
線性回歸是回歸問題,score使用R2系數(shù)做為評價標(biāo)準(zhǔn)蜜徽。
import sklearn.linear_model as sk_linear
model = sk_linear.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #返回預(yù)測的確定系數(shù)R2
print('線性回歸:')
print('截距:',model.intercept_) #輸出截距
print('系數(shù):',model.coef_) #輸出系數(shù)
print('線性回歸模型評價:',acc)
參數(shù)說明:
fit_intercept:是否計算截距祝懂。False-模型沒有截距
normalize: 當(dāng)fit_intercept設(shè)置為False時,該參數(shù)將被忽略拘鞋。 如果為真砚蓬,則回歸前的回歸系數(shù)X將通過減去平均值并除以l2-范數(shù)而歸一化。
copy_X:是否對X數(shù)組進(jìn)行復(fù)制,默認(rèn)為True
n_jobs:指定線程數(shù)
打印結(jié)果:
線性回歸:
截距: -0.379953866745
系數(shù): [-0.02744885 0.01662843 0.17780211 0.65838886]
線性回歸模型評價: 0.913431360638
邏輯回歸
logistic回歸是一種廣義線性回歸(generalized linear model)盆色,因此與多重線性回歸分析有很多相同之處灰蛙。它們的模型形式基本上相同,都具有 w‘x+b隔躲,其中w和b是待求參數(shù)缕允,其區(qū)別在于他們的因變量不同,多重線性回歸直接將w‘x+b作為因變量蹭越,即y =w‘x+b障本,而logistic回歸則通過函數(shù)L將w‘x+b對應(yīng)一個隱狀態(tài)p,p =L(w‘x+b),然后根據(jù)p 與1-p的大小決定因變量的值响鹃。如果L是logistic函數(shù)驾霜,就是logistic回歸,如果L是多項(xiàng)式函數(shù)就是多項(xiàng)式回歸买置。
說人話:線性回歸是回歸粪糙,邏輯回歸是分類。邏輯回歸通過logistic函數(shù)算概率忿项,然后算出來一個樣本屬于一個類別的概率蓉冈,概率越大越可能是這個類的樣本城舞。
sklearn對于邏輯回歸的實(shí)現(xiàn)也非常簡單,直接上代碼了寞酿。
邏輯回歸是分類問題家夺,score使用準(zhǔn)確率做為評價標(biāo)準(zhǔn)。
import sklearn.linear_model as sk_linear
model = sk_linear.LogisticRegression(penalty='l2',dual=False,C=1.0,n_jobs=1,random_state=20,fit_intercept=True)
model.fit(X_train,y_train) #對模型進(jìn)行訓(xùn)練
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print('邏輯回歸模型評價:',acc)
參數(shù)說明:
penalty:使用指定正則化項(xiàng)(默認(rèn):l2)
dual: n_samples > n_features取False(默認(rèn))
C:正則化強(qiáng)度的反伐弹,值越小正則化強(qiáng)度越大
n_jobs: 指定線程數(shù)
random_state:隨機(jī)數(shù)生成器
fit_intercept: 是否需要常量
打印結(jié)果:
邏輯回歸模型評價: 0.8
樸素貝葉斯
貝葉斯分類是一類分類算法的總稱拉馋,這類算法均以貝葉斯定理為基礎(chǔ),故統(tǒng)稱為貝葉斯分類惨好。
而樸素樸素貝葉斯分類是貝葉斯分類中最簡單煌茴,也是常見的一種分類方法
首先根據(jù)樣本中心定理,概率等于頻率日川,所以下文的P是可以統(tǒng)計出來的
樸素貝葉斯的核心便是貝葉斯公式:P(B|A)=P(A|B)P(B)/P(A) 即在A條件下蔓腐,B發(fā)生的概率
換個角度:P(類別|特征)=P(特征|類別)P(類別)/P(特征)
而我們最后要求解的就是P(類別|特征)
舉一個生活中的例子:

最后一個公式中的所有概率都是可以統(tǒng)計出來的,所以P(B|A)可以計算龄句!
那么合住!我感覺我都寫偏題了,這明明是機(jī)器學(xué)習(xí)算法概述嘛
那么sklearn中怎么實(shí)現(xiàn)呢撒璧?
import sklearn.naive_bayes as sk_bayes
model = sk_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None) #多項(xiàng)式分布的樸素貝葉斯
model = sk_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None) #伯努利分布的樸素貝葉斯
model = sk_bayes.GaussianNB()#高斯分布的樸素貝葉斯
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print(n樸素貝葉斯(高斯分布)模型評價:',acc)
參數(shù)說明:
alpha:平滑參數(shù)
fit_prior:是否要學(xué)習(xí)類的先驗(yàn)概率透葛;false-使用統(tǒng)一的先驗(yàn)概率
class_prior: 是否指定類的先驗(yàn)概率;若指定則不能根據(jù)參數(shù)調(diào)整
binarize: 二值化的閾值卿樱,若為None僚害,則假設(shè)輸入由二進(jìn)制向量組成
打印結(jié)果:
樸素貝葉斯(高斯分布)模型評價: 0.92380952381
決策樹
決策樹是解決分類問題
算法描述請見我之前的帖子(寫的很詳細(xì)了):http://blackblog.tech/2018/01/29/決策樹——ID3算法實(shí)現(xiàn)/
這里我們直接上代碼
import sklearn.tree as sk_tree
model = sk_tree.DecisionTreeClassifier(criterion='entropy',max_depth=None,min_samples_split=2,min_samples_leaf=1,max_features=None,max_leaf_nodes=None,min_impurity_decrease=0)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print('決策樹模型評價:',acc)
參數(shù)說明:
criterion :特征選擇準(zhǔn)則gini/entropy
max_depth:樹的最大深度,None-盡量下分
min_samples_split:分裂內(nèi)部節(jié)點(diǎn)繁调,所需要的最小樣本樹
min_samples_leaf:葉子節(jié)點(diǎn)所需要的最小樣本數(shù)
max_features: 尋找最優(yōu)分割點(diǎn)時的最大特征數(shù)
max_leaf_nodes:優(yōu)先增長到最大葉子節(jié)點(diǎn)數(shù)
min_impurity_decrease:如果這種分離導(dǎo)致雜質(zhì)的減少大于或等于這個值萨蚕,則節(jié)點(diǎn)將被拆分。
打印結(jié)果:
決策樹模型評價: 0.942857142857
SVM(支持向量機(jī))
支持向量機(jī)是解決分類問題
目的:求解最大化間隔
支持向量機(jī)將向量映射到一個更高維的空間里蹄胰,在這個空間里建立有一個最大間隔超平面岳遥。在分開數(shù)據(jù)的超平面的兩邊建有兩個互相平行的超平面。建立方向合適的分隔超平面使兩個與之平行的超平面間的距離最大化裕寨。其假定為浩蓉,平行超平面間的距離或差距越大,分類器的總誤差越小宾袜。
SVM的關(guān)鍵在于核函數(shù)
一句話講懂核函數(shù):低維無法線性劃分的問題放到高維就可以線性劃分捻艳,一般用高斯,因?yàn)樾Ч^對不會變差庆猫!
SVM算法思路很清晰认轨,但是實(shí)現(xiàn)起來很復(fù)雜,最近就在實(shí)現(xiàn)SVM月培,寫好了就發(fā)上來嘁字,在這里就不贅述這么多了恩急,我們直接用skleran解決問題。
import sklearn.svm as sk_svm
model = sk_svm.SVC(C=1.0,kernel='rbf',gamma='auto')
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print('SVM模型評價:',acc)
參數(shù)說明:
C:誤差項(xiàng)的懲罰參數(shù)C
kernel:核函數(shù)選擇 默認(rèn):rbf(高斯核函數(shù))纪蜒,可選:‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
gamma: 核相關(guān)系數(shù)衷恭。浮點(diǎn)數(shù),If gamma is ‘a(chǎn)uto’ then 1/n_features will be used instead.點(diǎn)將被拆分霍掺。
打印結(jié)果:
SVM模型評價: 0.961904761905
神經(jīng)網(wǎng)絡(luò)
還在感慨因?yàn)椴粫ensorflow而無法使用神經(jīng)網(wǎng)絡(luò)匾荆?還在羨慕神經(jīng)網(wǎng)絡(luò)的驚人效果?不需要tf拌蜘,不需要caffe杆烁,不需要pytorch!只要一句話简卧,便可以實(shí)現(xiàn)多層神經(jīng)網(wǎng)絡(luò)M没辍!举娩!
在這里還是簡單說一下M-P神經(jīng)元的原理:
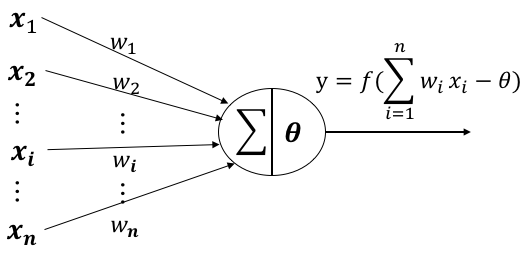
???? 來自第??個神經(jīng)元的輸入
???? 第??個神經(jīng)元的連接權(quán)重
?? 閾值(threshold)或稱為偏置(bias)
?? 為激活函數(shù)析校,常用:sigmoid,relu铜涉,tanh等等
對于一個神經(jīng)元來說智玻,有i個輸入,每一個輸入都對應(yīng)一個權(quán)重(w)芙代,神經(jīng)元具有一個偏置(閾值)吊奢,將所有的i*w求和后減去閾值得到一個值,這個值就是激活函數(shù)的參數(shù)纹烹,激活函數(shù)將根據(jù)這個參數(shù)來判定這個神經(jīng)元是否被激活页滚。
本質(zhì)上, M-P神經(jīng)元=線性二分類器
那么什么是多層神經(jīng)網(wǎng)絡(luò)?
線性不可分:一個超平面沒法解決問題铺呵,就用兩個超平面來解決裹驰,什么?還不行片挂!那就再增加超平面直到解決問題為止幻林。 ——多層神經(jīng)網(wǎng)絡(luò)
沒錯,多層神經(jīng)元就是用來解決線性不可分問題的音念。
那么滋将,sklearn中如何實(shí)現(xiàn)呢?
import sklearn.neural_network as sk_nn
model = sk_nn.MLPClassifier(activation='tanh',solver='adam',alpha=0.0001,learning_rate='adaptive',learning_rate_init=0.001,max_iter=200)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print('神經(jīng)網(wǎng)絡(luò)模型評價:',acc)
參數(shù)說明:
hidden_layer_sizes: 元祖
activation:激活函數(shù) {‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默認(rèn) ‘relu’
solver :優(yōu)化算法{‘lbfgs’, ‘sgd’, ‘Adam’}
alpha:L2懲罰(正則化項(xiàng))參數(shù)
learning_rate:學(xué)習(xí)率 {‘constant’, ‘invscaling’, ‘a(chǎn)daptive’}
learning_rate_init:初始學(xué)習(xí)率症昏,默認(rèn)0.001
max_iter:最大迭代次數(shù) 默認(rèn)200
特別:
學(xué)習(xí)率中參數(shù):
constant: 有‘learning_rate_init’給定的恒定學(xué)習(xí)率
incscaling:隨著時間t使用’power_t’的逆標(biāo)度指數(shù)不斷降低學(xué)習(xí)率
adaptive:只要訓(xùn)練損耗在下降随闽,就保持學(xué)習(xí)率為’learning_rate_init’不變
優(yōu)化算法參數(shù):
lbfgs:quasi-Newton方法的優(yōu)化器
sgd:隨機(jī)梯度下降
adam: Kingma, Diederik, and Jimmy Ba提出的機(jī)遇隨機(jī)梯度的優(yōu)化器
打印結(jié)果:(神經(jīng)網(wǎng)絡(luò)的確牛逼)
神經(jīng)網(wǎng)絡(luò)模型評價: 0.980952380952
KNN(K-近鄰算法)
KNN可以說是非常好用,也非常常用的分類算法了肝谭,也是最簡單易懂的機(jī)器學(xué)習(xí)算法掘宪,沒有之一蛾扇。由于算法先天優(yōu)勢,KNN甚至不需要訓(xùn)練就可以得到非常好的分類效果了魏滚。
在訓(xùn)練集中數(shù)據(jù)和標(biāo)簽已知的情況下镀首,輸入測試數(shù)據(jù),將測試數(shù)據(jù)的特征與訓(xùn)練集中對應(yīng)的特征進(jìn)行相互比較鼠次,找到訓(xùn)練集中與之最為相似的前K個數(shù)據(jù)更哄,則該測試數(shù)據(jù)對應(yīng)的類別就是K個數(shù)據(jù)中出現(xiàn)次數(shù)最多的那個分類。
其算法的描述為:
1.計算測試數(shù)據(jù)與各個訓(xùn)練數(shù)據(jù)之間的距離腥寇;
2.按照距離的遞增關(guān)系進(jìn)行排序成翩;
3.選取距離最小的K個點(diǎn);
4.確定前K個點(diǎn)所在類別的出現(xiàn)頻率赦役;
5.返回前K個點(diǎn)中出現(xiàn)頻率最高的類別作為測試數(shù)據(jù)的預(yù)測分類麻敌。
(感覺又說多了...... - -!)
其實(shí)這個算法自己實(shí)現(xiàn)起來也就只有幾行代碼,這里我們還是使用sklearn來實(shí)現(xiàn)掂摔。
sklearn中的KNN可以做分類也可以做回歸
import sklearn.neighbors as sk_neighbors
#KNN分類
model = sk_neighbors.KNeighborsClassifier(n_neighbors=5,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #根據(jù)給定數(shù)據(jù)與標(biāo)簽返回正確率的均值
print('KNN模型(分類)評價:',acc)
#KNN回歸
model = sk_neighbors.KNeighborsRegressor(n_neighbors=5,n_jobs=1)
model.fit(X_train,y_train)
acc=model.score(X_test,y_test) #返回預(yù)測的確定系數(shù)R2
print('KNN模型(回歸)評價:',acc)
參數(shù)說明:
n_neighbors: 使用鄰居的數(shù)目
n_jobs:并行任務(wù)數(shù)
打印結(jié)果:
KNN模型(分類)評價: 0.942857142857
KNN模型(回歸)評價: 0.926060606061
交叉驗(yàn)證
好的术羔,終于說完了常用模型,感覺完全是一個算法概述啊hhhhh
既然我們現(xiàn)在已經(jīng)完成了數(shù)據(jù)的獲取乙漓,模型的建立级历,那么最后一步便是驗(yàn)證我們的模型
其實(shí)交叉驗(yàn)證應(yīng)該放在數(shù)據(jù)集的劃分那里,但是他又與模型的驗(yàn)證緊密相關(guān)叭披,所以我就按照編寫代碼的順序進(jìn)行講解了寥殖。
首先,什么是交叉驗(yàn)證趋观?
這里完全引用西瓜書扛禽,因?yàn)槲矣X得書上寫的非常清楚!V逄场编曼!
交叉驗(yàn)證法先將數(shù)據(jù)集D劃分為k個大小相似的互斥子集,每個子集Di都盡可能保持?jǐn)?shù)據(jù)分布的一致性剩辟,即從D中通過分層采樣得到掐场。然后每次用k-1個子集的并集做為訓(xùn)練集,余下的子集做為測試集贩猎,這樣就可以獲得K組訓(xùn)練/測試集熊户,從而可以進(jìn)行k次訓(xùn)練和測試,最終返回的是這個k個測試結(jié)果的均值吭服。k通常的取值是10嚷堡,其他常用取值為2,5艇棕,20等蝌戒。
這里使用KNN做為訓(xùn)練模型串塑,采用十折交叉驗(yàn)證。
model = sk_neighbors.KNeighborsClassifier(n_neighbors=5,n_jobs=1) #KNN分類
import sklearn.model_selection as sk_model_selection
accs=sk_model_selection.cross_val_score(model, iris_X, y=iris_y, scoring=None,cv=10, n_jobs=1)
print('交叉驗(yàn)證結(jié)果:',accs)
參數(shù)說明:
model:擬合數(shù)據(jù)的模型
cv : 子集個數(shù) 就是k
scoring: 打分參數(shù) 默認(rèn)‘a(chǎn)ccuracy’北苟、可選‘f1’桩匪、‘precision’、‘recall’ 友鼻、‘roc_auc’傻昙、'neg_log_loss'
打印結(jié)果:
交叉驗(yàn)證結(jié)果:
[ 1. 0.93333333 1. 1. 0.86666667 0.93333333
0.93333333 1. 1. 1. ]
模型的保存和載入
模型的保存和載入方便我們將訓(xùn)練好的模型保存在本地或發(fā)送在網(wǎng)上,載入模型方便我們在不同的環(huán)境下進(jìn)行測試彩扔。
使用pickle可以進(jìn)行保存與載入
也可以使用sklearn自帶的函數(shù)
import sklearn.externals as sk_externals
sk_externals.joblib.dump(model,'model.pickle') #保存
model = sk_externals.joblib.load('model.pickle') #載入
小結(jié)
兩篇帖子基本完成了對于sklearn的基礎(chǔ)講解妆档,看似內(nèi)容雖多,但是使用起來其實(shí)非常簡單借杰。不小心寫成一個算法概述过吻,也沒什么太大的問題进泼,相信我不寫蔗衡,大家也會去百度這些算法的含義,我就當(dāng)這是為大家省時間了吧哈哈哈乳绕。
sklearn是一個非常好用的機(jī)器學(xué)習(xí)工具包绞惦,掌握好它會在機(jī)器學(xué)習(xí)的道路上祝我們一臂之力的!
與君共勉洋措!
