# 前言
之前講了DeepLabV1,V2,V3三個算法宣旱,DeepLab系列語義分割還剩下最后一個DeepLabV3+,以后有沒有++,+++現(xiàn)在還不清楚山析,我們先來解讀一下這篇論文并分析一下源碼吧骏融。論文地址:https://arxiv.org/pdf/1802.02611.pdf
# 背景
語義分割主要面臨兩個問題析苫,第一是物體的多尺度問題,第二是DCNN的多次下采樣會造成特征圖分辨率變小潭千,導(dǎo)致預(yù)測精度降低谱姓,邊界信息丟失。DeepLab V3設(shè)計的ASPP模塊較好的解決了第一個問題刨晴,而這里要介紹的DeepLabv3+則主要是為了解決第2個問題的屉来。
我們知道從DeepLabV1系列引入空洞卷積開始路翻,我們就一直在解決第2個問題呀,為什么現(xiàn)在還有問題呢奶躯?
我們考慮一下前面的代碼解析推文的DeepLab系列網(wǎng)絡(luò)的代碼實現(xiàn)帚桩,地址如下:https://mp.weixin.qq.com/s/0dS0Isj2oCo_CF7p4riSCA 。對于DeepLabV3嘹黔,如果Backbone為ResNet101账嚎,Stride=16將造成后面9層的特征圖變大,后面9層的計算量變?yōu)樵瓉淼?倍大儡蔓。而如果采用Stride=8郭蕉,則后面78層的計算量都會變得很大。這就造成了DeepLabV3如果應(yīng)用在大分辨率圖像時非常耗時喂江。所以為了改善這個缺點召锈,DeepLabV3+來了。
# 算法原理
DeepLabV3+主要有兩個創(chuàng)新點获询。
## 編解碼器
為了解決上面提到的DeepLabV3在分辨率圖像的耗時過多的問題涨岁,DeepLabV3+在DeepLabV3的基礎(chǔ)上加入了編碼器。具體操作見論文中的下圖:
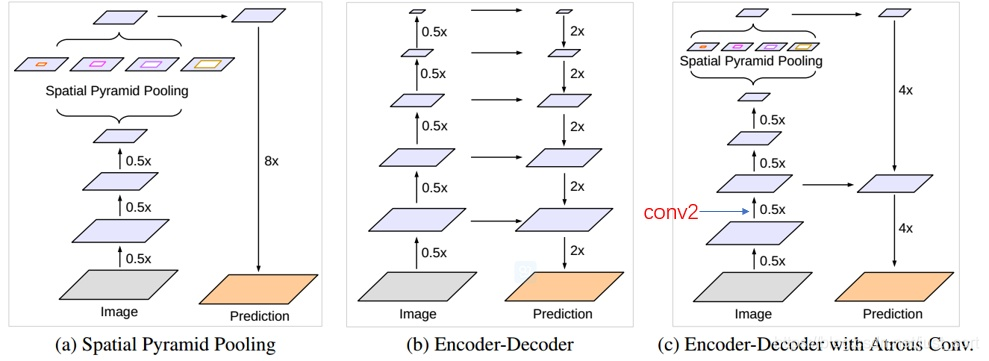其中吉嚣,(a)代表SPP結(jié)構(gòu)梢薪,其中的8x是直接雙線性插值操作,不用參與訓(xùn)練尝哆。(b)是編解碼器秉撇,融集合了高層和低層信息。(c)是DeepLabv3+采取的結(jié)構(gòu)秋泄。
我們來看一下DeepLabV3+的完整網(wǎng)絡(luò)結(jié)構(gòu)來更好的理解這點:
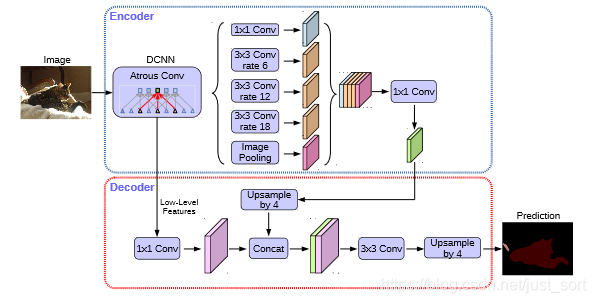
對于編碼器部分琐馆,實際上就是DeepLabV3網(wǎng)絡(luò)。首先選一個低層級的feature用1 * 1的卷積進行通道壓縮(原本為256通道恒序,或者512通道)瘦麸,目的是減少低層級的比重。論文認為編碼器得到的feature具有更豐富的信息歧胁,所以編碼器的feature應(yīng)該有更高的比重瞎暑。 這樣做有利于訓(xùn)練。
對于解碼器部分与帆,直接將編碼器的輸出上采樣4倍了赌,使其分辨率和低層級的feature一致。舉個例子玄糟,如果采用resnet `conv2` 輸出的feature勿她,則這里要$\times 4$上采樣。將兩種feature連接后阵翎,再進行一次$3 \times 3$的卷積(細化作用)逢并,然后再次上采樣就得到了像素級的預(yù)測之剧。
實驗結(jié)果表明,這種結(jié)構(gòu)在Stride=16時有很高的精度速度又很快砍聊。stride=8相對來說只獲得了一點點精度的提升背稼,但增加了很多的計算量。
## 更改主干網(wǎng)絡(luò)
論文受到近期MSRA組在Xception上改進工作可變形卷積([Deformable-ConvNets](https://arxiv.org/pdf/1703.06211.pdf))啟發(fā)玻蝌,Deformable-ConvNets對Xception做了改進蟹肘,能夠進一步提升模型學(xué)習(xí)能力,新的結(jié)構(gòu)如下:
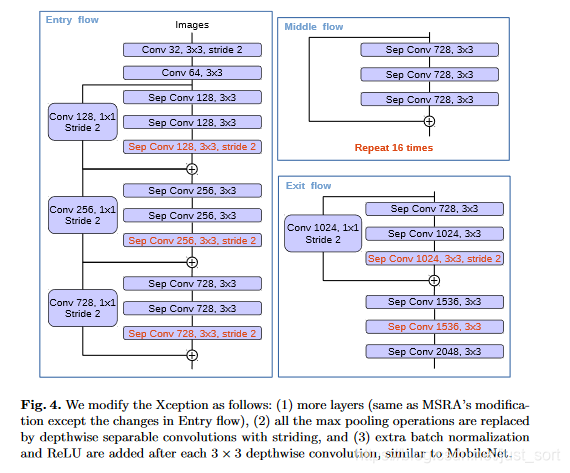
最終俯树,論文使用了如下的改進:
- 更深的Xception結(jié)構(gòu)帘腹,不同的地方在于不修改entry flow network的結(jié)構(gòu),為了快速計算和有效的使用內(nèi)存
- 所有的max pooling結(jié)構(gòu)被stride=2的深度可分離卷積代替
- 每個3x3的depthwise convolution都跟BN和Relu
最后將改進后的Xception作為encodet主干網(wǎng)絡(luò)许饿,替換原本DeepLabv3的ResNet101阳欲。
# 實驗
論文使用modified aligned Xception改進后的ResNet-101,在ImageNet-1K上做預(yù)訓(xùn)練陋率,通過擴張卷積做密集的特征提取球化。采用DeepLabv3的訓(xùn)練方式(poly學(xué)習(xí)策略,crop$513\times 513$)瓦糟。注意在decoder模塊同樣包含BN層筒愚。
## 使用1*1卷積少來自低級feature的通道數(shù)
上面提到過,為了評估在低級特征使用1*1卷積降維到固定維度的性能狸页,做了如下對比實驗:

實驗中取了$Conv2$尺度為$[3\times3,256]$的輸出,降維后的通道數(shù)在32和48之間最佳扯再,最終選擇了48芍耘。
## 使用3*3卷積逐步獲取分割結(jié)果
編解碼特征圖融合后經(jīng)過了$3\times 3$卷積,論文探索了這個卷積的不同結(jié)構(gòu)對結(jié)果的影響:
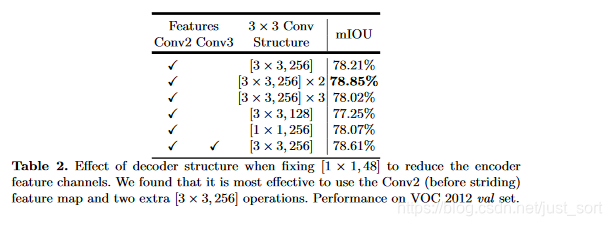
最終熄阻,選擇了使用兩組$3\times 3$卷積斋竞。這個表格的最后一項代表實驗了如果使用$Conv2$和$Conv3$同時預(yù)測,$Conv2$上采樣2倍后與$Conv3$結(jié)合秃殉,再上采樣2倍的結(jié)果對比坝初,這并沒有提升顯著的提升性能,考慮到計算資源的限制钾军,論文最終采樣簡單的decoder方案鳄袍,即我們看到的DeepLabV+的網(wǎng)絡(luò)結(jié)構(gòu)圖。
# Backbone為ResNet101
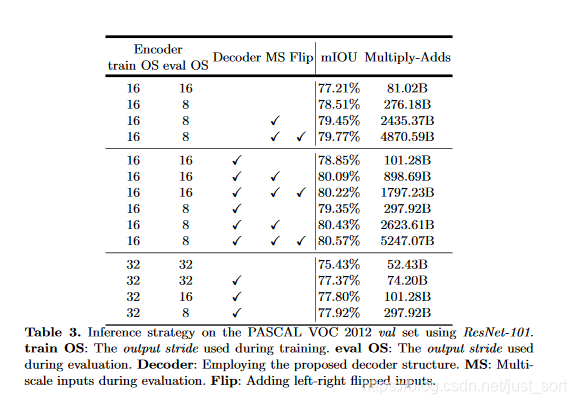
# Backbone為Xception
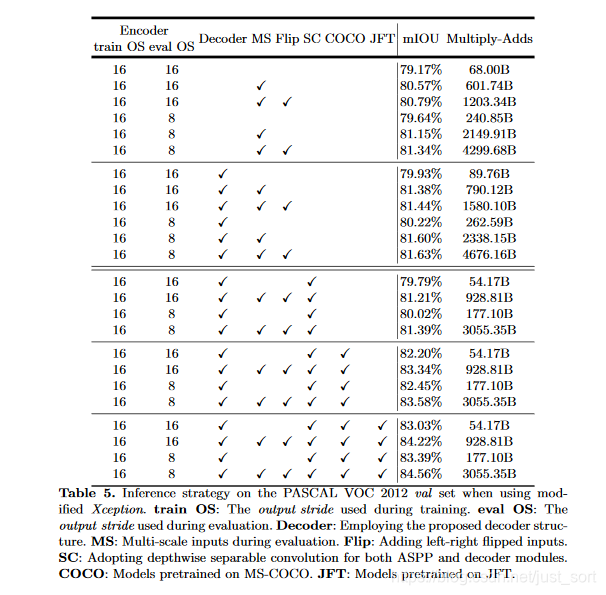
這里可以看到使用深度分離卷積可以顯著降低計算消耗吏恭。
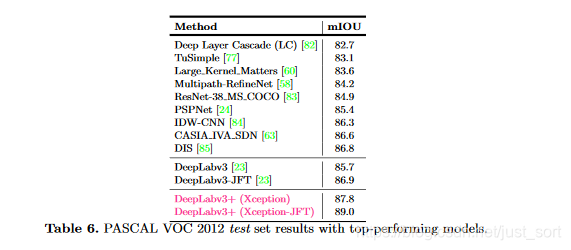
與其他先進模型在VOC12的測試集上對比:
在目標邊界上的提升拗小,使用trimap實驗?zāi)P驮诜指钸吔绲臏蚀_度。計算邊界周圍擴展頻帶(稱為trimap)內(nèi)的mIoU樱哼。結(jié)果如下:
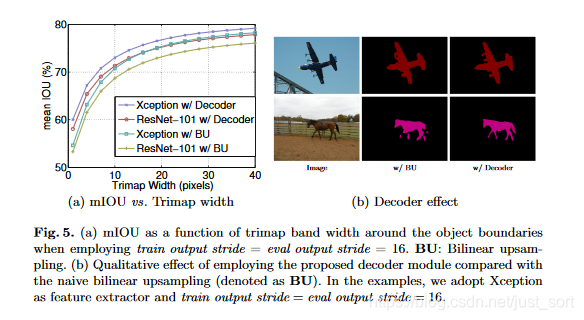
與雙線性上采樣相比哀九,加decoder的有明顯的提升剿配。trimap越小效果越明顯。Fig5右圖可視化了結(jié)果阅束。
# 結(jié)論
論文提出的DeepLabv3+是encoder-decoder架構(gòu)呼胚,其中encoder架構(gòu)采用Deeplabv3,decoder采用一個簡單卻有效的模塊用于恢復(fù)目標邊界細節(jié)息裸。并可使用空洞卷積在指定計算資源下控制feature的分辨率蝇更。論文探索了Xception和深度分離卷積在模型上的使用,進一步提高模型的速度和性能界牡。模型在VOC2012上獲得了SOAT簿寂。Google出品,必出精品宿亡,這網(wǎng)絡(luò)真的牛常遂。
# 代碼實現(xiàn)
結(jié)合一下網(wǎng)絡(luò)結(jié)構(gòu)圖還有我上次的代碼解析[點這里](https://mp.weixin.qq.com/s/0dS0Isj2oCo_CF7p4riSCA) 看,就很容易了挽荠。
```python
from __future__ import absolute_import, print_function
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from .deeplabv3 import _ASPP
from .resnet import _ConvBnReLU, _ResLayer, _Stem
class DeepLabV3Plus(nn.Module):
? ? """
? ? DeepLab v3+: Dilated ResNet with multi-grid + improved ASPP + decoder
? ? """
? ? def __init__(self, n_classes, n_blocks, atrous_rates, multi_grids, output_stride):
? ? ? ? super(DeepLabV3Plus, self).__init__()
? ? ? ? # Stride and dilation
? ? ? ? if output_stride == 8:
? ? ? ? ? ? s = [1, 2, 1, 1]
? ? ? ? ? ? d = [1, 1, 2, 4]
? ? ? ? elif output_stride == 16:
? ? ? ? ? ? s = [1, 2, 2, 1]
? ? ? ? ? ? d = [1, 1, 1, 2]
? ? ? ? # Encoder
? ? ? ? ch = [64 * 2 ** p for p in range(6)]
? ? ? ? self.layer1 = _Stem(ch[0])
? ? ? ? self.layer2 = _ResLayer(n_blocks[0], ch[0], ch[2], s[0], d[0])
? ? ? ? self.layer3 = _ResLayer(n_blocks[1], ch[2], ch[3], s[1], d[1])
? ? ? ? self.layer4 = _ResLayer(n_blocks[2], ch[3], ch[4], s[2], d[2])
? ? ? ? self.layer5 = _ResLayer(n_blocks[3], ch[4], ch[5], s[3], d[3], multi_grids)
? ? ? ? self.aspp = _ASPP(ch[5], 256, atrous_rates)
? ? ? ? concat_ch = 256 * (len(atrous_rates) + 2)
? ? ? ? self.add_module("fc1", _ConvBnReLU(concat_ch, 256, 1, 1, 0, 1))
? ? ? ? # Decoder
? ? ? ? self.reduce = _ConvBnReLU(256, 48, 1, 1, 0, 1)
? ? ? ? self.fc2 = nn.Sequential(
? ? ? ? ? ? OrderedDict(
? ? ? ? ? ? ? ? [
? ? ? ? ? ? ? ? ? ? ("conv1", _ConvBnReLU(304, 256, 3, 1, 1, 1)),
? ? ? ? ? ? ? ? ? ? ("conv2", _ConvBnReLU(256, 256, 3, 1, 1, 1)),
? ? ? ? ? ? ? ? ? ? ("conv3", nn.Conv2d(256, n_classes, kernel_size=1)),
? ? ? ? ? ? ? ? ]
? ? ? ? ? ? )
? ? ? ? )
? ? def forward(self, x):
? ? ? ? h = self.layer1(x)
? ? ? ? h = self.layer2(h)
? ? ? ? h_ = self.reduce(h)
? ? ? ? h = self.layer3(h)
? ? ? ? h = self.layer4(h)
? ? ? ? h = self.layer5(h)
? ? ? ? h = self.aspp(h)
? ? ? ? h = self.fc1(h)
? ? ? ? h = F.interpolate(h, size=h_.shape[2:], mode="bilinear", align_corners=False)
? ? ? ? h = torch.cat((h, h_), dim=1)
? ? ? ? h = self.fc2(h)
? ? ? ? h = F.interpolate(h, size=x.shape[2:], mode="bilinear", align_corners=False)
? ? ? ? return h
if __name__ == "__main__":
? ? model = DeepLabV3Plus(
? ? ? ? n_classes=21,
? ? ? ? n_blocks=[3, 4, 23, 3],
? ? ? ? atrous_rates=[6, 12, 18],
? ? ? ? multi_grids=[1, 2, 4],
? ? ? ? output_stride=16,
? ? )
? ? model.eval()
? ? image = torch.randn(1, 3, 513, 513)
? ? print(model)
? ? print("input:", image.shape)
print("output:", model(image).shape)
```
# 參考文章
https://blog.csdn.net/u011974639/article/details/79518175
---------------------------------------------------------------------------
歡迎關(guān)注我的微信公眾號GiantPadaCV克胳,期待和你一起交流機器學(xué)習(xí),深度學(xué)習(xí)圈匆,圖像算法漠另,優(yōu)化技術(shù),比賽及日常生活等跃赚。

