1、決策樹算法
決策樹(decision tree)又叫判定樹牵啦,是基于樹結(jié)構(gòu)對樣本屬性進(jìn)行分類的分類算法茎活。以二分類為例,當(dāng)對某個(gè)問題進(jìn)行決策時(shí)辖众,會(huì)進(jìn)行一系列的判斷或者“子決策”舍杜,將每個(gè)判定問題可以簡單理解為“開”或“關(guān)”,當(dāng)達(dá)到一定條件的時(shí)候赵辕,就進(jìn)行“開”或“關(guān)”的操作,操作就是對決策樹的這個(gè)問題進(jìn)行的測試概龄。所有的“子決策”都完成的時(shí)候还惠,就構(gòu)建出了一顆完整的決策樹。
一顆典型的決策樹包括根結(jié)點(diǎn)私杜、若干個(gè)內(nèi)部結(jié)點(diǎn)和若干個(gè)葉結(jié)點(diǎn)蚕键;葉結(jié)點(diǎn)對應(yīng)著決策結(jié)果,其它每個(gè)結(jié)點(diǎn)對應(yīng)于一個(gè)屬性測試衰粹;每個(gè)結(jié)點(diǎn)包含的樣本集合根據(jù)屬性測試的結(jié)果被劃分到子結(jié)點(diǎn)中锣光;根結(jié)點(diǎn)包含樣本全集。
決策樹學(xué)習(xí)的目的在于產(chǎn)生一顆泛化能力強(qiáng)铝耻,即處理未見示例能力強(qiáng)的決策樹誊爹,基本流程遵循簡單直觀的“分而治之”(divide-and-conquer)策略蹬刷。
一般而言,隨著劃分過程的不斷進(jìn)行频丘,我們希望決策樹的分支節(jié)點(diǎn)所包含的樣本盡可能屬于同一類別办成,即結(jié)點(diǎn)的“純度”(purity)越來越高。
-
信息熵(information entropy)
信息熵是度量樣本集合純度最常用的一種指標(biāo)搂漠。在樣本集合D中迂卢,第k 類樣本所占比例為 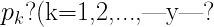)則D的信息熵為:=-\sum_{k=1}^{|y|}p_klog_2p_k $$)
Ent(D)的值越小,D的純度越高桐汤。
-
信息增益(information gain)
離散屬性a中有V個(gè)可能取值使用a對樣本集D進(jìn)行劃分而克,則產(chǎn)生V個(gè)分支結(jié)點(diǎn),其中第v個(gè)分支結(jié)點(diǎn)包含了D中所有在屬性a上取值為av的樣本怔毛,記作Dv员萍,Dv信息熵即為Ent(Dv)
考慮到不同分支結(jié)點(diǎn)包含樣本數(shù)不同,則給分支結(jié)點(diǎn)賦權(quán)最后可計(jì)算出屬性a對樣本集D進(jìn)行劃分所得到的信息增益:=Ent(D)-\sum_{v=1}{V}\frac{|Dv|}{|D|}Ent(D^v)$$)
著名的ID3算法就是基于信息增益構(gòu)建的馆截。
一般信息增益越大充活,則意味使用屬性a進(jìn)行劃分所獲得的“純度提升”越大。
-
信息增益率(gain ratio)
信息增益準(zhǔn)則對可數(shù)數(shù)目較多屬性有所偏好蜡娶。這里考慮一個(gè)特殊情況混卵,若分支數(shù)目就為樣本數(shù),則信息增益就為樣本集信息熵窖张,此時(shí)信息增益亦越大幕随,此時(shí)決策樹并不具有泛化能力,無法對新樣本進(jìn)行有效預(yù)測宿接。
信息增益率就是為了解決上述問題而產(chǎn)生的赘淮。信息增益率的計(jì)算公式為:=\frac{Gain(D,a)}{IV(a)} $$)其中=-\sum_{v=1}^V \frac{|Dv|}{|D|}log_2\frac{|Dv|}{|D|} $$)稱為屬性a的“固有值”(intrinsic value),屬性a的可能取值數(shù)目越多(即V越大)睦霎,則IV(a)通常會(huì)越大梢卸。
基于ID3算法改進(jìn)的C4.5算法就是基于信息增益率構(gòu)建的。
需要注意的是副女,信息增益率對于可取值數(shù)目較少的屬性有所偏好蛤高。
-
基尼指數(shù)(gini index)
基尼指數(shù)是常用于CART決策樹的一種劃分準(zhǔn)則,樣本集D的“純度”也可通過這個(gè)指數(shù)進(jìn)行確定碑幅〈鞫福基尼指數(shù):=\sum_{k=1}{|y|}\sum_{k{'}\neq{k}}p_kp_{k{'}}=1-\sum_{k=1}{|y|}p_k^2 $$)
它反映了從樣本集D中隨機(jī)抽取兩個(gè)樣本,其類別標(biāo)記不一致的概率沟涨。
因此Gini(D)越小恤批,樣本集D純度越高。
定義屬性a的基尼指數(shù)為:=\sum_{v=1}{|V|}\frac{|Dv|}{|D|}Gini(D^v) $$)在候選屬性集合A中裹赴,選擇使得劃分后基尼指數(shù)最小的屬性做為最優(yōu)劃分屬性喜庞。
2诀浪、算法實(shí)現(xiàn)
本文采用以下樣本集(data.txt)實(shí)現(xiàn)決策樹
| 編號 | 色澤 | 根蒂 | 敲聲 | 紋理 | 臍部 | 觸感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青綠 | 蜷縮 | 濁響 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 烏黑 | 蜷縮 | 沉悶 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 烏黑 | 蜷縮 | 濁響 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青綠 | 蜷縮 | 沉悶 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 淺白 | 蜷縮 | 濁響 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青綠 | 稍蜷 | 濁響 | 清晰 | 稍凹 | 軟粘 | 是 |
| 7 | 烏黑 | 稍蜷 | 濁響 | 稍糊 | 稍凹 | 軟粘 | 是 |
| 8 | 烏黑 | 稍蜷 | 濁響 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 烏黑 | 稍蜷 | 沉悶 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青綠 | 硬挺 | 清脆 | 清晰 | 平坦 | 軟粘 | 否 |
| 11 | 淺白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 淺白 | 蜷縮 | 濁響 | 模糊 | 平坦 | 軟粘 | 否 |
| 13 | 青綠 | 稍蜷 | 濁響 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 淺白 | 稍蜷 | 沉悶 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 烏黑 | 稍蜷 | 濁響 | 清晰 | 稍凹 | 軟粘 | 否 |
| 16 | 淺白 | 蜷縮 | 濁響 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青綠 | 蜷縮 | 沉悶 | 稍糊 | 稍凹 | 硬滑 | 否 |
通過以下代碼導(dǎo)入樣本集數(shù)據(jù)
import pandas as pd#導(dǎo)入pandas庫
import numpy as np#導(dǎo)入numpy庫
data = pd.read_csv('data.txt', '\t', index_col='編號')
labels = list(data.columns)
dataSet = np.array(data).tolist()#處理讀入數(shù)據(jù)為list類型,方便后續(xù)計(jì)算
2.1赋荆、計(jì)算信息熵
導(dǎo)入樣本集笋妥,通過下面代碼實(shí)現(xiàn)根結(jié)點(diǎn)信息熵的計(jì)算
from math import log
def calcShannonEnt(dataSet):
numEntries = len(dataSet)#計(jì)算樣本集的總樣本數(shù)量
labelCounts = {}#設(shè)置一個(gè)空的dict類型變量
for featVec in dataSet:#遍歷每行樣本集
currentLabel = featVec[-1]#選取樣本集最后一列,設(shè)置為labelCounts變量的key值
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0#key對應(yīng)value初始化
labelCounts[currentLabel] += 1#累計(jì)value窄潭,即計(jì)算同類別樣本數(shù)
shannonEnt = 0.0#初始化信息熵
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries#計(jì)算頻率
shannonEnt -= prob * log(prob, 2)#計(jì)算信息熵
return shannonEnt
print(calcShannonEnt(dataSet))
0.9975025463691153
可以得到是否“好瓜”春宣,即根結(jié)點(diǎn)的信息熵為0.9975025463691153
判斷是否“好瓜”的有{色澤,根蒂嫉你,敲聲月帝,紋理,臍部幽污,觸感}等6個(gè)子屬性嚷辅,同時(shí)以“色澤”屬性為例,它有3個(gè)可能取值{青綠距误,烏黑簸搞,淺白},分別記為D1(色澤=青綠)准潭、D2(色澤=烏黑)和D1(色澤=淺白)趁俊。
如果希望通過上面計(jì)算根結(jié)點(diǎn)的代碼計(jì)算不同子屬性信息熵,這里就需要對樣本集進(jìn)行劃分刑然,選擇相應(yīng)的子屬性寺擂。這里通過下面的代碼實(shí)現(xiàn)樣本集的劃分。
def splitDataSet(dataSet, axis, value):
#dataSet為樣本集
#axis為子屬性下標(biāo)泼掠,如0代表子屬性“色澤”
#value為上述子屬性取值
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
newdataSet1=splitDataSet(dataSet, 0, '青綠')#將為“青綠”的樣本集合劃分出來
[['蜷縮', '濁響', '清晰', '凹陷', '硬滑', '是'], ['蜷縮', '沉悶', '清晰', '凹陷', '硬滑', '是'], ['稍蜷', '濁響', '清晰', '稍凹', '軟粘', '是'], ['硬挺', '清脆', '清晰', '平坦', '軟粘', '否'], ['稍蜷', '濁響', '稍糊', '凹陷', '硬滑', '否'], ['蜷縮', '沉悶', '稍糊', '稍凹', '硬滑', '否']]
newdataSet2=splitDataSet(dataSet, 0, '烏黑')#將為“青綠”的樣本集合劃分出來
[['蜷縮', '沉悶', '清晰', '凹陷', '硬滑', '是'], ['蜷縮', '濁響', '清晰', '凹陷', '硬滑', '是'], ['稍蜷', '濁響', '稍糊', '稍凹', '軟粘', '是'], ['稍蜷', '濁響', '清晰', '稍凹', '硬滑', '是'], ['稍蜷', '沉悶', '稍糊', '稍凹', '硬滑', '否'], ['稍蜷', '濁響', '清晰', '稍凹', '軟粘', '否']]
newdataSet3=splitDataSet(dataSet, 0, '淺白')#將為“青綠”的樣本集合劃分出來
[['蜷縮', '濁響', '清晰', '凹陷', '硬滑', '是'], ['硬挺', '清脆', '模糊', '平坦', '硬滑', '否'], ['蜷縮', '濁響', '模糊', '平坦', '軟粘', '否'], ['稍蜷', '沉悶', '稍糊', '凹陷', '硬滑', '否'], ['蜷縮', '濁響', '模糊', '平坦', '硬滑', '否']]
由上面的劃分可以看出“色澤=青綠”的正類為3/6怔软,反類為3/6,“色澤=烏黑”的正類為4/6择镇,反類為2/6挡逼,“色澤=淺白”的正類為1/5,反類為4/5腻豌。
通過上文代碼計(jì)算每個(gè)取值的熵值:
print(calcShannonEnt(newdataSet1))
print(calcShannonEnt(newdataSet2))
print(calcShannonEnt(newdataSet3))
1.0
0.9182958340544896
0.7219280948873623
可以得到D1(色澤=青綠)的信息熵為:1.0挚瘟,D2(色澤=烏黑)的信息熵:為0.9182958340544896,D1(色澤=淺白)的信息熵為:0.7219280948873623饲梭。
2.2、計(jì)算信息增益及最優(yōu)劃分屬性選取
由下面的代碼可以實(shí)現(xiàn)信息增益的計(jì)算
numFeatures = len(dataSet[0]) - 1#計(jì)算子屬性的數(shù)量
baseEntropy = calcShannonEnt(dataSet)#計(jì)算根結(jié)點(diǎn)信息熵
columns=['色澤','根蒂','敲聲','紋理','臍部','觸感']#子屬性
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
#根據(jù)子屬性及其取值劃分樣本子集
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))#權(quán)值
newEntropy += prob * calcShannonEnt(subDataSet)
print(value,'的信息熵為:',calcShannonEnt(subDataSet))#不同取值的信息熵
infoGain = baseEntropy - newEntropy#計(jì)算信息增益
print(columns[i],'信息增益為:',infoGain)
print('----------------------------------')
青綠 的信息熵為: 1.0
烏黑 的信息熵為: 0.9182958340544896
淺白 的信息熵為: 0.7219280948873623
色澤 信息增益為: 0.10812516526536531
----------------------------------
蜷縮 的信息熵為: 0.9544340029249649
硬挺 的信息熵為: 0.0
稍蜷 的信息熵為: 0.9852281360342516
根蒂 信息增益為: 0.14267495956679288
----------------------------------
清脆 的信息熵為: 0.0
濁響 的信息熵為: 0.9709505944546686
沉悶 的信息熵為: 0.9709505944546686
敲聲 信息增益為: 0.14078143361499584
----------------------------------
模糊 的信息熵為: 0.0
清晰 的信息熵為: 0.7642045065086203
稍糊 的信息熵為: 0.7219280948873623
紋理 信息增益為: 0.3805918973682686
----------------------------------
稍凹 的信息熵為: 1.0
平坦 的信息熵為: 0.0
凹陷 的信息熵為: 0.863120568566631
臍部 信息增益為: 0.28915878284167895
----------------------------------
硬滑 的信息熵為: 1.0
軟粘 的信息熵為: 0.9709505944546686
觸感 信息增益為: 0.006046489176565584
----------------------------------
一般某個(gè)子屬性的信息增益越大焰檩,意味著使用該屬性進(jìn)行劃分的“純度提升”越大憔涉,下面通過改造上述代碼,選取最優(yōu)的劃分屬性析苫。
# 基于信息增益選擇最優(yōu)劃分屬性
def chooseBestFeatureToSplit_Gain(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0#初始最優(yōu)信息增益
bestFeature = -1#初始最優(yōu)子屬性
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):#選擇最優(yōu)子屬性
bestInfoGain = infoGain
bestFeature = i
return bestFeature
chooseBestFeatureToSplit_Gain(dataSet)
3
上述結(jié)果表示在這個(gè)樣本集中兜叨,最優(yōu)的劃分子屬性是“紋理”穿扳,接下來根結(jié)點(diǎn)就通過該子屬性進(jìn)行劃分。在該劃分之后国旷,通過剩余的其它子屬性再進(jìn)行信息增益的計(jì)算得到下個(gè)最優(yōu)劃分子屬性矛物,迭代進(jìn)行,直到全部子屬性變量完成跪但。
2.3履羞、基于信息增益率最優(yōu)劃分屬性選取
計(jì)算信息增益率代碼與上文計(jì)算信息增益的代碼類似,同時(shí)下文基于該原則選擇最優(yōu)子屬性的代碼中有體現(xiàn)屡久,這里不過多贅述忆首。
同樣的,基于信息增益率原則也是選擇信息增益率最大的為最優(yōu)劃分結(jié)點(diǎn)被环,下面基于信息增益率劃分最優(yōu)子屬性糙及。
由于本文采用的樣本集是離散型特征的樣本,這里的信息增益率和基尼指數(shù)選擇劃分屬性的實(shí)現(xiàn)并未針對連續(xù)型特征進(jìn)行筛欢。后續(xù)會(huì)加以改進(jìn)浸锨。
# 基于信息增益率選擇最優(yōu)劃分屬性
def chooseBestFeatureToSplit_GainRatio(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestGainRatio = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
iv = 0.0#初始化“固有值”
GainRatio = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
iv -= prob * log(prob, 2)#計(jì)算每個(gè)子屬性“固有值”
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
GainRatio = infoGain / iv#計(jì)算信息增益率
if (GainRatio > bestGainRatio):#選擇最優(yōu)節(jié)點(diǎn)
bestGainRatio = GainRatio
bestFeature = i
return bestFeature
chooseBestFeatureToSplit_GainRatio(dataSet)
3
上述結(jié)果表示在這個(gè)樣本集中,最優(yōu)的劃分子屬性同樣是“紋理”版姑,接下來的劃分實(shí)現(xiàn)過程就由該結(jié)點(diǎn)開始柱搜。
2.4、計(jì)算基尼指數(shù)及最優(yōu)劃分屬性選取
以下代碼實(shí)現(xiàn)了基尼指數(shù)的計(jì)算漠酿。
# 計(jì)算基尼指數(shù)
def calcGini(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
Gini = 1.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
Gini -= prob * prob
return Gini
calcGini(dataSet)#根結(jié)點(diǎn)基尼指數(shù)
0.49826989619377154
上述結(jié)果為根結(jié)點(diǎn)的基尼指數(shù)值冯凹。下面是通過基尼指數(shù)選擇根結(jié)點(diǎn)的子結(jié)點(diǎn)代碼實(shí)現(xiàn)。
# 基于基尼指數(shù)選擇最優(yōu)劃分屬性(只能對離散型特征進(jìn)行處理)
def chooseBestFeatureToSplit_Gini(dataSet):
numFeatures = len(dataSet[0]) - 1
bestGini = 100000.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newGiniIndex = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newGiniIndex += prob * calcGini(subDataSet)
if (newGiniIndex < bestGini):
bestGini = newGiniIndex
bestFeature = i
return bestFeature
chooseBestFeatureToSplit_Gini(dataSet)
3
上述結(jié)果同樣表示在這個(gè)樣本集中炒嘲,最優(yōu)的劃分子屬性同樣是“紋理”宇姚,接下來的劃分實(shí)現(xiàn)過程也由該結(jié)點(diǎn)開始。
2.5夫凸、創(chuàng)建樹
決策樹的創(chuàng)建過程是迭代進(jìn)行的浑劳,下面的代碼是根據(jù)子屬性的取值數(shù)目大小來進(jìn)行每層根結(jié)點(diǎn)的選擇的實(shí)現(xiàn)過程。即簡單理解為選擇“下一個(gè)根結(jié)點(diǎn)”夭拌。
import operator
# 選擇下一個(gè)根結(jié)點(diǎn)
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0#初始化子屬性取值的計(jì)數(shù)
classCount[vote] += 1#累計(jì)
#根據(jù)第二個(gè)域魔熏,即dict的value降序排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]#返回子屬性取值
下面就是創(chuàng)建樹的過程。
# 創(chuàng)建樹
def createTree(dataSet, labels, chooseBestFeatureToSplit):
classList = [example[-1] for example in dataSet]#初始化根結(jié)點(diǎn)
if classList.count(classList[0]) == len(classList):#只存在一種取值情況
return classList[0]
if len(dataSet[0]) == 1:#樣本集只存在一個(gè)樣本情況
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)#最優(yōu)劃分屬性選取
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}#初始化樹
del (labels[bestFeat])#刪除已劃分屬性
featValues = [example[bestFeat] for example in dataSet]#初始化下層根結(jié)點(diǎn)
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
#遍歷實(shí)現(xiàn)樹的創(chuàng)建
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels, chooseBestFeatureToSplit)
return myTree
chooseBestFeatureToSplit=chooseBestFeatureToSplit_Gain#根據(jù)信息增益創(chuàng)建樹
# chooseBestFeatureToSplit=chooseBestFeatureToSplit_GainRatio#根據(jù)信息增益率創(chuàng)建樹
# chooseBestFeatureToSplit=chooseBestFeatureToSplit_Gini#根據(jù)基尼指數(shù)創(chuàng)建樹
myTree = createTree(dataSet, labels, chooseBestFeatureToSplit)
myTree
{'紋理': {'模糊': '否',
'清晰': {'根蒂': {'硬挺': '否',
'稍蜷': {'色澤': {'烏黑': {'觸感': {'硬滑': '是', '軟粘': '否'}}, '青綠': '是'}},
'蜷縮': '是'}},
'稍糊': {'觸感': {'硬滑': '否', '軟粘': '是'}}}}
我們需要將劃分好的決策樹加載出來進(jìn)行分類鸽扁,這里定義一個(gè)分類的代碼如下蒜绽。
#分類測試器
def classify(inputTree, featLabels, testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]#下一層樹
featIndex = featLabels.index(firstStr)#將Labels標(biāo)簽轉(zhuǎn)換為索引
for key in secondDict.keys():
if testVec[featIndex] == key:#判斷是否為與分支節(jié)點(diǎn)相同,即向下探索子樹
if type(secondDict[key]).__name__ == 'dict':
#遞歸實(shí)現(xiàn)
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel#返回判斷結(jié)果
classify(myTree, ['色澤','根蒂','敲聲','紋理','臍部','觸感'],['烏黑','稍蜷','沉悶','稍糊','稍凹','硬滑'])
'否'#得到分類結(jié)果為'否'
由于決策樹的訓(xùn)練是一件耗時(shí)的工作桶现,當(dāng)碰到較大的樣本集的時(shí)候躲雅,為了下次使用的方便,這里將決策樹保存起來骡和。
這里通過pickle模塊存儲(chǔ)和加載決策樹相赁。
#保存樹
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'wb+')
pickle.dump(inputTree,fw)
fw.close()
#加載樹
def grabTree(filename):
import pickle
fr = open(filename,'rb')
return pickle.load(fr)
storeTree(myTree,'myTree.txt')#保存到mytree.txt文件中
grabTree('myTree.txt')#加載保存的決策樹
{'紋理': {'模糊': '否',
'清晰': {'根蒂': {'硬挺': '否',
'稍蜷': {'色澤': {'烏黑': {'觸感': {'硬滑': '是', '軟粘': '否'}}, '青綠': '是'}},
'蜷縮': '是'}},
'稍糊': {'觸感': {'硬滑': '否', '軟粘': '是'}}}}
2.6相寇、繪制樹
上文已經(jīng)將樹創(chuàng)建出來了,下面可以通過這段代碼進(jìn)行決策樹的繪制
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#支持圖像顯示中文
#boxstyle為文本框的類型钮科,sawtooth是鋸齒形唤衫,fc是邊框線粗細(xì)
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
#定義箭頭的屬性
arrow_args = dict(arrowstyle="<-")
#繪制節(jié)點(diǎn)
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy = parentPt, xycoords = 'axes fraction',
xytext = centerPt, textcoords = 'axes fraction',
va = "center", ha = "center", bbox=nodeType,
arrowprops = arrow_args)
#獲取葉節(jié)點(diǎn)的數(shù)量
def getNumLeafs(myTree):
#定義葉子節(jié)點(diǎn)數(shù)目
numLeafs = 0
#獲取myTree的第一個(gè)鍵
firstStr = list(myTree.keys())[0]
#劃分第一個(gè)鍵對應(yīng)的值,即下層樹
secondDict = myTree[firstStr]
#遍歷secondDict
for key in secondDict.keys():
#如果secondDict[key]為字典绵脯,則遞歸計(jì)算其葉子節(jié)點(diǎn)數(shù)量
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
#是葉子節(jié)點(diǎn)累計(jì)
numLeafs +=1
return numLeafs
#獲取樹的層數(shù)
def getTreeDepth(myTree):
#定義樹的層數(shù)
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
#如果secondDict[key]為字典佳励,則遞歸計(jì)算其層數(shù)
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
#當(dāng)前層數(shù)大于最大層數(shù)
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#繪制節(jié)點(diǎn)文本
def plotMidText(cntrPt, parentPt, txtString):
#求中間點(diǎn)橫坐標(biāo)
xMid = (parentPt[0] - cntrPt[0])/2.0 + cntrPt[0]
#求中間點(diǎn)縱坐標(biāo)
yMid = (parentPt[1] - cntrPt[1])/2.0 + cntrPt[1]
#繪制結(jié)點(diǎn)
createPlot.ax1.text(xMid, yMid, txtString)
#繪制決策樹
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)#葉子節(jié)點(diǎn)數(shù)
# depth = getTreeDepth(myTree)#層數(shù)
firstStr = list(myTree.keys())[0]#第一層鍵
#計(jì)算坐標(biāo),
cntrPt=(plotTree.xOff + (1.0+float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
#繪制中間節(jié)點(diǎn)
plotMidText(cntrPt, parentPt, nodeTxt)
#繪制決策樹節(jié)點(diǎn)
plotNode(firstStr,cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff-1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
#遞歸繪制決策樹
plotTree(secondDict[key], cntrPt, str(key))
else:
#葉子節(jié)點(diǎn)橫坐標(biāo)
plotTree.xOff = plotTree.xOff+1.0/plotTree.totalW
#繪制葉子節(jié)點(diǎn)
plotNode(secondDict[key], (plotTree.xOff,plotTree.yOff), cntrPt,leafNode)
plotMidText((plotTree.xOff,plotTree.yOff), cntrPt, str(key))
#縱坐標(biāo)
plotTree.yOff = plotTree.yOff+1.0/plotTree.totalD
def createPlot(inTree):
#定義圖像界面
fig = plt.figure(1, facecolor='white', figsize = (10,8))
#初始化
fig.clf()
#定義橫縱坐標(biāo)軸
axprops = dict(xticks = [],yticks = [])
#初始化圖像
createPlot.ax1 = plt.subplot(111, frameon = False,**axprops)
#寬度
plotTree.totalW = float(getNumLeafs(inTree))
#高度
plotTree.totalD = float(getTreeDepth(inTree))
#起始橫坐標(biāo)
plotTree.xOff = -0.5/plotTree.totalW
#起始縱坐標(biāo)
plotTree.yOff = 1.0
#繪制決策樹
plotTree(inTree,(0.5,1.0), '')
#顯示圖像
plt.show()
createPlot(myTree)

2.7桨嫁、使用Scikit - Learn庫實(shí)現(xiàn)決策樹
Scikit-Learn庫是Python一個(gè)第三方的機(jī)器學(xué)習(xí)模塊植兰,它基于NumPy,Scipy璃吧,Matplotlib的基礎(chǔ)構(gòu)建的楣导,是一個(gè)高效、簡便的數(shù)據(jù)挖掘畜挨、數(shù)據(jù)分析的模塊筒繁。在后續(xù)的學(xué)習(xí)過程中,我也通過其進(jìn)行機(jī)器學(xué)習(xí)的實(shí)例實(shí)現(xiàn)巴元。
下面是基于信息熵簡單得到該決策樹的代碼實(shí)現(xiàn)毡咏。
import numpy as np
import pandas as pd
from sklearn import tree
'''由于在此庫中需要使用數(shù)值進(jìn)行運(yùn)算,這里需要對樣本集進(jìn)行處理'''
data = pd.read_csv('data1.txt', '\t', index_col='Idx')
labels = np.array(data['label'])
dataSet = np.array(data[data.columns[:-1]])
clf = tree.DecisionTreeClassifier(criterion = 'entropy')#參數(shù)criterion = 'entropy'為基于信息熵逮刨,‘gini’為基于基尼指數(shù)
clf.fit(dataSet, labels)#訓(xùn)練模型
with open("tree.dot", 'w') as f:#將構(gòu)建好的決策樹保存到tree.dot文件中
f = tree.export_graphviz(clf,feature_names = np.array(data.columns[:-1]), out_file = f)
這里我們需要通過Graphviz將保存好的tree.dot文件繪制出來呕缭,在這之前,需要安裝Graphviz這個(gè)軟件修己。
安裝步驟如下:
-
打開http://www.graphviz.org/Download_windows.php 恢总,下載此文件;
-
打開下載好的文件graphviz-2.38睬愤,一直next安裝完成片仿;
-
打開系統(tǒng)屬性,編輯環(huán)境變量尤辱,添加graphviz-2.38的安裝目錄下的\bin文件夾路徑到新變量中砂豌,確定即可;
-
打開命令提示符光督,輸入:dot -version查看環(huán)境變量是否設(shè)置成功阳距;
-
命令提示符轉(zhuǎn)到tree.dot文件所在位置,鍵入以下命令:dot tree.dot -Tpng -o tree.png结借,將決策樹文件轉(zhuǎn)化為圖像文件娄涩。
經(jīng)過上述過程,我們得到了決策樹圖像。







上述代碼只是基于Scikit-Learn庫簡單實(shí)現(xiàn)決策樹蓄拣,不能體現(xiàn)這個(gè)機(jī)器學(xué)習(xí)庫的強(qiáng)大之處,后續(xù)會(huì)介紹如何使用這個(gè)庫訓(xùn)練模型努隙、測試模型等球恤。
2.8、不足及改進(jìn)
本文研究了基于信息增益荸镊、信息增益率和基尼指數(shù)三種劃分準(zhǔn)則進(jìn)行決策樹的構(gòu)造咽斧,通過“西瓜”樣本集實(shí)現(xiàn)了其決策樹的構(gòu)造。但是決策樹的構(gòu)造過程中還存在過擬合躬存,即生成的樹需要剪枝的情況张惹,以及對于連續(xù)變量的處理問題,在下一篇文章中岭洲,將針對這兩個(gè)問題改進(jìn)相應(yīng)的代碼宛逗,從而使構(gòu)建出的決策樹更為嚴(yán)謹(jǐn)準(zhǔn)確。
3盾剩、參考資料
[1] 周志華. 機(jī)器學(xué)習(xí).清華大學(xué)出版社雷激,2016
[2] Peter Harrington. 機(jī)器學(xué)習(xí)實(shí)戰(zhàn). 人民郵電出版社,2013
[3] http://m.blog.csdn.net/article/details?id=51057311
[4] http://www.tuicool.com/articles/uUry2uq
