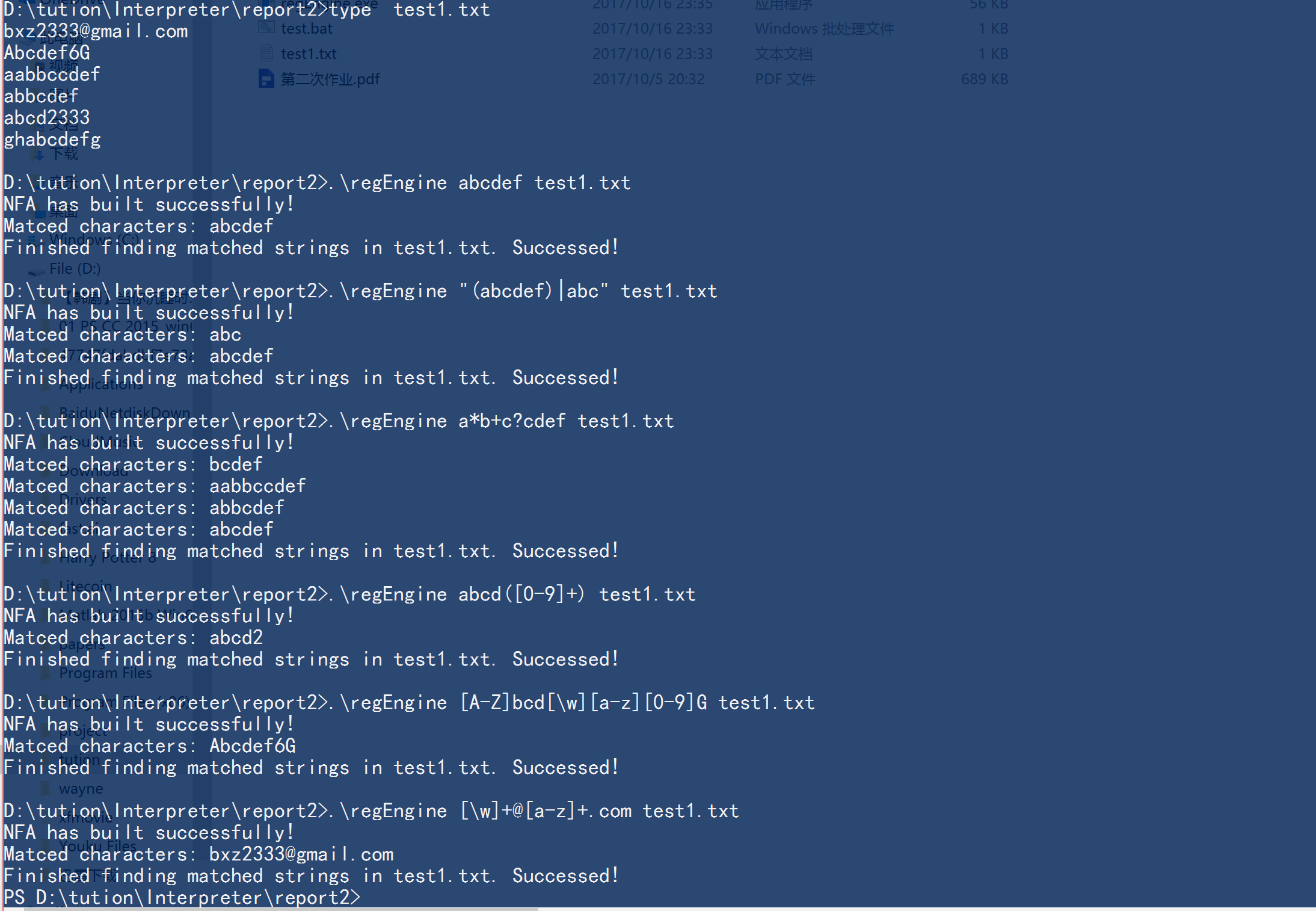
本文介紹了一個(gè)簡單的正則表達(dá)式引擎的實(shí)現(xiàn)老虫,總共用了四百五十行左右的代碼咕缎,完整的code可以在碼云上找到郭蕉。
基本的數(shù)據(jù)結(jié)構(gòu)定義
核心思路是讀取正則表達(dá)式以后生成對應(yīng)的NFA劝赔,NFA中有邊和狀態(tài)兩個(gè)結(jié)構(gòu)烘豹。邊的結(jié)構(gòu)記錄了它的起點(diǎn)和終點(diǎn)瓜贾,同時(shí)通過枚舉類型記錄匹配的其他需求。
//用于處理‘^’字符
enum { NEXCLUDED = false, EXCLUDED = true };
//用于處理預(yù)處理類型携悯,0-128以內(nèi)ASCII字符直接匹配
enum { LCASES=256, UCASES=257, NUM=258, EPSILON=259, ANY=260, WS=261 };
class Edge
{
public:
State *start;
State *end;
int type;
int exclude;
Edge(State *s, State *e, int t, bool ex = NEXCLUDED) :start(s), end(e), type(t), exclude(ex) {};
}
狀態(tài)有預(yù)備祭芦,成功和失敗三種,同時(shí)每個(gè)狀態(tài)維護(hù)兩個(gè)向量憔鬼,向量存儲了出邊和入邊的指針龟劲。
enum { READY = -1, SUCCESS = 1, FAIL = 0};
class State
{
public:
int status;
std::list<Edge *> InEdges;
std::list<Edge *> OutEdges;
}
Nfa類會(huì)存儲一個(gè)正則表達(dá)式,同時(shí)存儲NFA的起點(diǎn)和終點(diǎn)轴或,并使用了兩個(gè)鏈表來維護(hù)NFA的邊和狀態(tài)昌跌,同時(shí)用一個(gè)鏈表來存儲匹配成功的字符串。兩個(gè)靜態(tài)的字符串指針用于記錄文件和正則表達(dá)式字符串的讀取狀態(tài)照雁,靜態(tài)常量避矢,使得最終函數(shù)只會(huì)對文件內(nèi)容和正則表達(dá)式掃描一次,避免在匹配成功的字符串中再匹配子串囊榜。
char *regex;
State *Start;
State *End;
std::list<Edge *> edgeList;
std::list<State *> stateList;
std::list<char> matchedChar;
static char *regRead;
static char *fileRead;
}
生成NFA的過程中审胸,通過currentEnd和currentStart兩個(gè)指針分別指向當(dāng)前字符讀取完成后生成的最后一個(gè)狀態(tài)和當(dāng)前字符讀取之前的開始狀態(tài),維護(hù)這兩個(gè)指針的目的是為了記錄NFA的生成過程卸勺,在處理‘*’砂沛、‘+’、‘曙求?’等字符的時(shí)候起到了重要的作用碍庵。同時(shí)我們利用list內(nèi)置的迭代器對鏈表進(jìn)行遍歷映企,這個(gè)方式在匹配過程中也用到了。
State *currentEnd, *currentStart;
State *alternate;
list<Edge *>::iterator itor;
NFA的生成
關(guān)鍵的部分在于匹配字符串時(shí)采取的思路静浴,尤其是特殊字符的生成NFA的方式堰氓,這個(gè)不同于課本上最開始的NFA生成算法,而是基于讀取字符串的過程苹享,同時(shí)避免了字符串的回退等双絮,讀取一個(gè)字符就生成一個(gè)對應(yīng)的邊并壓入鏈表中,對‘*’得问、‘+’囤攀,‘?’和特殊符號也是如此宫纬,使得處理更加簡單的同時(shí)避免生成過于冗余的狀態(tài)焚挠,兼顧了時(shí)間和空間效率。以下舉例說明漓骚。
邊和狀態(tài)的生成
邊的生成使用newEdge函數(shù),需要記錄起點(diǎn)和終點(diǎn)蝌衔,以及類型,同時(shí)在生成邊以后要用重載的兩個(gè)patch函數(shù)將狀態(tài)和邊完全連接起來蝌蹂。
void Nfa::newEdge(State * start, State * end, int type, int exclude = NEXCLUDED)
{
Edge *out = new Edge(start, end, type, exclude);
end->patch(out, end);
start->patch(start, out);
edgeList.push_back(out);
}
以普通字符的生成和‘.’字符的產(chǎn)生方式為例胚委,他們都是生成一條邊和一個(gè)新的狀態(tài)。
case '.': /* any */
currentStart = currentEnd;
currentEnd = new State();
newEdge(currentStart, currentEnd, ANY, NEXCLUDED);
stateList.push_back(currentEnd);
default:
currentStart = currentEnd;
currentEnd = new State();
newEdge(currentStart, currentEnd, *regRead, NEXCLUDED);
stateList.push_back(currentEnd);
break;
如下圖所示

接下來的符號處理都假定初始狀態(tài)如下圖所示
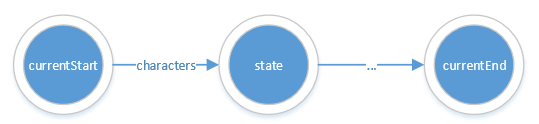
'|'的處理
以currentStart指向的狀態(tài)作為子NFA的起點(diǎn)叉信,同時(shí)將子NFA的終點(diǎn)狀態(tài)和原NFA的終點(diǎn)進(jìn)行合并亩冬。
case '|': // alternate
regRead++;
currentStart = start;
alternate= regex2nfa(regRead, start);
currentEnd->merge(alternate);
stateList.remove(alternate);
regRead--;
如下圖所示
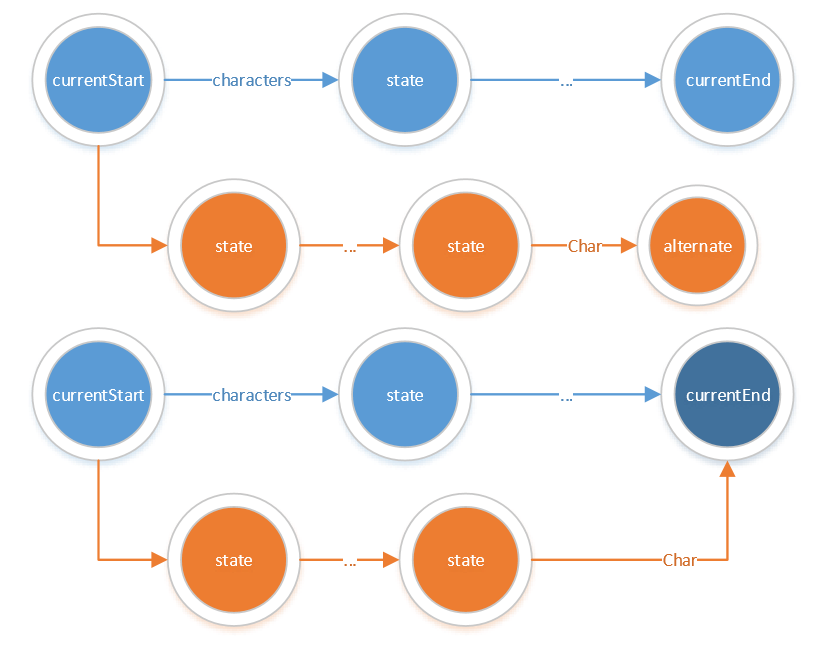
'?' & '*' & '+'的處理
讀取到問號只需要在上一條邊的基礎(chǔ)上繼續(xù)連接原有的邊即可。
case '?': // zero or one
newEdge(currentStart, currentEnd, EPSILON, NEXCLUDED);
break;
讀取到''后硼身,直接將currentStart和currentEnd*進(jìn)行合并成環(huán)
case '*': // zero or more
alternate = currentEnd;
currentStart->merge(alternate);
stateList.remove(alternate);
currentEnd = currentStart;
break;
讀取到‘+’后硅急,只需添加若干條邊從currentEnd狀態(tài)指向currentStart狀態(tài)的下一個(gè)狀態(tài)即可。
case '+': /* one or more */
itor = currentStart->OutEdges.begin();
for (;itor != currentStart->OutEdges.end();itor++)
newEdge(currentEnd, (*itor)->end, (*itor)->type, (*itor)->exclude);
break;
如下圖所示:
簡單的分組支持
對于中括號和括號進(jìn)行了一定的支持佳遂,括號直接遞歸調(diào)用NFA的生成函數(shù)营袜,中括號和預(yù)定義字符都有其對應(yīng)的函數(shù)進(jìn)行支持。
NFA匹配
匹配過程采用了遞歸的方式丑罪,step函數(shù)調(diào)用match函數(shù)匹配邊和文件字符荚板,匹配成功后即遞歸調(diào)用進(jìn)入下一個(gè)狀態(tài)。
if (End->status == SUCCESS)
return SUCCESS;
for(;itor != current->OutEdges.end();itor++)
{
if ((*itor)->match(fileRead))
{
(*itor)->end->status = SUCCESS;
matchedChar.push_back(*fileRead);
++fileRead;
if (step((*itor)->end))
return SUCCESS;
--fileRead;
matchedChar.pop_back();
}
if ((*itor)->type == EPSILON && step((*itor)->end))
return SUCCESS;
}
return FAIL;
結(jié)果
較好的通過了測試用例,但是沒有進(jìn)一步拓展功能,只是一個(gè)簡單的正則表達(dá)式纫溃,同時(shí)也有些取巧崎岂,都只對字符進(jìn)行了一次掃描染乌,沒有進(jìn)行完整的詞法分析和語法分析,程序在四百五十行左右的情況下,其實(shí)是不夠健壯的窒舟。