CNN on TensorFlow
本文大部分內(nèi)容均參考于:
An Intuitive Explanation of Convolutional Neural Networks
知乎:「為什么 ReLU 要好過(guò)于 tanh 和 sigmoid function?」
Deep MNIST for Experts
TensorFlow Python API 「tf.nn」
Build a Multilayer Convolutional Network
在 TensorFlow 官方的 tutorials 中抵赢,我們使用 softmax 模型在 MNIST 數(shù)據(jù)集上得到的結(jié)果只有 91% 的正確率杆煞,實(shí)在太糟糕没炒。所以会油,我們將使用一個(gè)稍微復(fù)雜的模型:CNN(卷積神經(jīng)網(wǎng)絡(luò))來(lái)改善實(shí)驗(yàn)效果。在 CNN 主要有四個(gè)操作:
- 卷積
- 非線性處理(ReLU)
- 池化或者亞采樣
- 分類(全連接層)
這些操作對(duì)于各個(gè)卷積神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō)都是基本組件滓玖,因此理解它們的工作原理有助于充分了解卷積神經(jīng)網(wǎng)絡(luò)行瑞。下面我們將會(huì)嘗試?yán)斫飧鞑讲僮鞅澈蟮脑怼?/p>
What's CNN
Convolution
卷積的主要目的是為了從輸入圖像中提取特征蔬啡。卷積可以通過(guò)從輸入的一小塊數(shù)據(jù)中學(xué)到圖像的特征,并可以保留像素間的空間關(guān)系诵肛。讓我們舉個(gè)例子來(lái)嘗試?yán)斫庖幌戮矸e是如何處理圖像的:
正如我們上面所說(shuō)屹培,每張圖像都可以看作是像素值的矩陣默穴。考慮一下一個(gè) 5 x 5 的圖像褪秀,它的像素值僅為 0 或者 1(注意對(duì)于灰度圖像而言蓄诽,像素值的范圍是 0 到 255,下面像素值為 0 和 1 的綠色矩陣僅為特例):
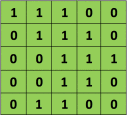
同時(shí)媒吗,考慮下另一個(gè) 3 x 3 的矩陣仑氛,如下所示:

接下來(lái),5 x 5 的圖像和 3 x 3 的矩陣的卷積可以按下圖所示的動(dòng)畫一樣計(jì)算:
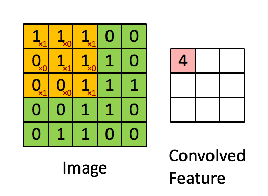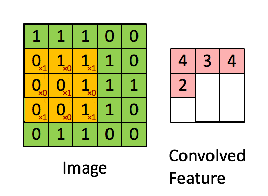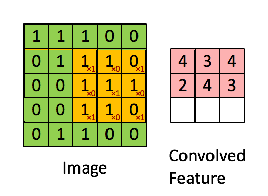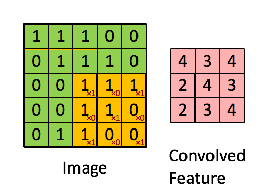
現(xiàn)在停下來(lái)好好理解下上面的計(jì)算是怎么完成的闸英。我們用橙色的矩陣在原始圖像(綠色)上滑動(dòng)锯岖,每次滑動(dòng)一個(gè)像素(也叫做「步長(zhǎng)」),在每個(gè)位置上甫何,我們計(jì)算對(duì)應(yīng)元素的乘積(兩個(gè)矩陣間)出吹,并把乘積的和作為最后的結(jié)果,得到輸出矩陣(粉色)中的每一個(gè)元素的值辙喂。注意捶牢,3 x 3 的矩陣每次步長(zhǎng)中僅可以看到輸入圖像的一部分莹捡。
在 CNN 的術(shù)語(yǔ)中俩垃,3x3 的矩陣叫做「濾波器」(filter) 或「核」(kernel) 或者 「特征檢測(cè)器」(feature detector),通過(guò)在圖像上滑動(dòng)濾波器并計(jì)算點(diǎn)乘得到矩陣叫做「卷積特征」(Convolved Feature) 或者 「激活圖」(Activation Map) 或者 「特征圖」(Feature Map)膀钠。記住芍锦,濾波器在原始輸入圖像上的作用是特征檢測(cè)器竹勉。
從上面圖中的動(dòng)畫可以看出,對(duì)于同樣的輸入圖像娄琉,不同值的濾波器將會(huì)生成不同的特征圖次乓。比如,對(duì)于下面這張輸入圖像:

在下表中孽水,我們可以看到不同濾波器對(duì)上圖卷積的效果票腰。正如表中所示,通過(guò)在卷積操作前修改濾波矩陣的數(shù)值女气,我們可以進(jìn)行諸如邊緣檢測(cè)杏慰、銳化和模糊等操作 —— 這表明不同的濾波器可以從圖中檢測(cè)到不同的特征,比如邊緣炼鞠、曲線等缘滥。

另一個(gè)直觀理解卷積操作的好方法是看下面這張圖的動(dòng)畫:

濾波器(紅色框)在輸入圖像滑過(guò)(卷積操作),生成一個(gè)特征圖谒主。另一個(gè)濾波器(綠色框)在同一張圖像上卷積可以得到一個(gè)不同的特征圖朝扼。注意卷積操作可以從原圖上獲取局部依賴信息。同時(shí)注意這兩個(gè)不同的濾波器是如何從同一張圖像上生成不同的特征圖霎肯。記住上面的圖像和兩個(gè)濾波器僅僅是我們上面討論的數(shù)值矩陣擎颖。
在實(shí)踐中榛斯,CNN 會(huì)在訓(xùn)練過(guò)程中學(xué)習(xí)到這些濾波器的值(盡管我們依然需要在訓(xùn)練前指定諸如濾波器的個(gè)數(shù)、濾波器的大小搂捧、網(wǎng)絡(luò)架構(gòu)等參數(shù))驮俗。我們使用的濾波器越多,提取到的圖像特征就越多允跑,網(wǎng)絡(luò)所能在未知圖像上識(shí)別的模式也就越好意述。
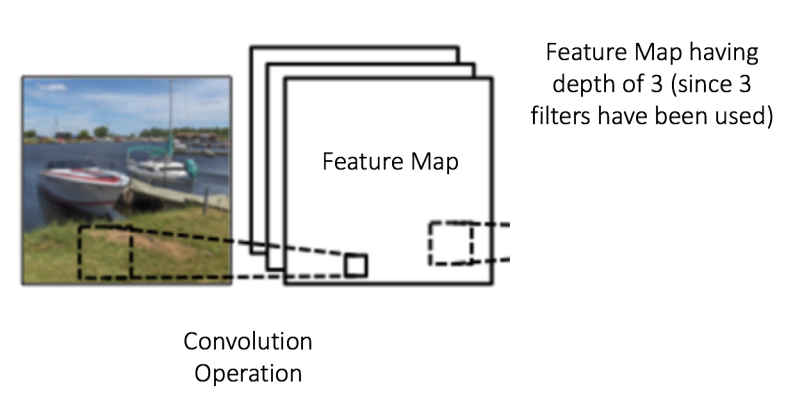
特征圖的大小(卷積特征)由下面三個(gè)參數(shù)控制吮蛹,我們需要在卷積前確定它們:
深度(Depth):深度對(duì)應(yīng)的是卷積操作所需的濾波器個(gè)數(shù)荤崇。在下圖的網(wǎng)絡(luò)中,我們使用三個(gè)不同的濾波器對(duì)原始圖像進(jìn)行卷積操作潮针,這樣就可以生成三個(gè)不同的特征圖术荤。你可以把這三個(gè)特征圖看作是堆疊的 2d 矩陣,那么每篷,特征圖的「深度」就是 3瓣戚。
步長(zhǎng)(Stride):步長(zhǎng)是我們?cè)谳斎刖仃嚿匣瑒?dòng)濾波矩陣的像素?cái)?shù)。當(dāng)步長(zhǎng)為 1 時(shí)焦读,我們每次移動(dòng)濾波器一個(gè)像素的位置子库。當(dāng)步長(zhǎng)為 2 時(shí),我們每次移動(dòng)濾波器會(huì)跳過(guò) 2 個(gè)像素矗晃。步長(zhǎng)越大仑嗅,將會(huì)得到更小的特征圖。
零填充(Zero-padding):有時(shí)张症,在輸入矩陣的邊緣使用零值進(jìn)行填充仓技,這樣我們就可以對(duì)輸入圖像矩陣的邊緣進(jìn)行濾波。零填充的一大好處是可以讓我們控制特征圖的大小俗他。使用零填充的也叫做泛卷積脖捻,不適用零填充的叫做嚴(yán)格卷積。
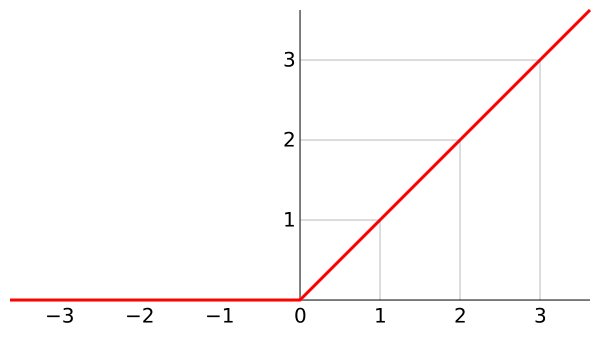
ReLU
ReLU表示修正線性單元(Rectified Linear Unit)兆衅,是一個(gè)非線性操作地沮。
-
為什么要引入非線性激勵(lì)函數(shù)?
如果不用激勵(lì)函數(shù)(其實(shí)相當(dāng)于激勵(lì)函數(shù)是 $f(x) = x$ )羡亩,在這種情況下你每一層輸出都是上層輸入的線性函數(shù)摩疑,很容易驗(yàn)證,無(wú)論你神經(jīng)網(wǎng)絡(luò)有多少層夕春,輸出都是輸入的線性組合未荒,與沒(méi)有隱層效果相當(dāng)专挪,這種情況就是最原始的感知機(jī)(Perceptron)了及志。
正因?yàn)樯厦娴脑蚱牛覀儧Q定引入非線性函數(shù)作為激勵(lì)函數(shù),這樣深層神經(jīng)網(wǎng)絡(luò)就有意義了(不再是輸入的線性組合速侈,可以逼近任意函數(shù))率寡。最早的想法是 sigmoid 函數(shù)或者 tanh 函數(shù),輸出有界倚搬,很容易充當(dāng)下一層輸入(以及一些人的生物解釋balabala)冶共。
-
為什么要引入 ReLU 而不是其他的非線性函數(shù)(例如 Sigmoid 函數(shù))?
- 采用 sigmoid 等函數(shù)每界,算激活函數(shù)時(shí)(指數(shù)運(yùn)算)捅僵,計(jì)算量大,反向傳播求誤差梯度時(shí)眨层,求導(dǎo)涉及除法庙楚,計(jì)算量相對(duì)大,而采用Relu激活函數(shù)趴樱,整個(gè)過(guò)程的計(jì)算量節(jié)省很多馒闷。
- 對(duì)于深層網(wǎng)絡(luò),sigmoid 函數(shù)反向傳播時(shí)叁征,很容易就會(huì)出現(xiàn)梯度消失的情況(在sigmoid接近飽和區(qū)時(shí)纳账,變換太緩慢,導(dǎo)數(shù)趨于0捺疼,這種情況會(huì)造成信息丟失)疏虫,從而無(wú)法完成深層網(wǎng)絡(luò)的訓(xùn)練。
- Relu 會(huì)使一部分神經(jīng)元的輸出為 0啤呼,這樣就造成了網(wǎng)絡(luò)的稀疏性议薪,并且減少了參數(shù)的相互依存關(guān)系,緩解了過(guò)擬合問(wèn)題的發(fā)生(以及一些人的生物解釋balabala)媳友。
當(dāng)然現(xiàn)在也有一些對(duì) relu 的改進(jìn)斯议,比如 prelu,random relu等醇锚,在不同的數(shù)據(jù)集上會(huì)有一些訓(xùn)練速度上或者準(zhǔn)確率上的改進(jìn)哼御,具體的可以找相關(guān)的paper看。
(多加一句焊唬,現(xiàn)在主流的做法恋昼,會(huì)多做一步 batch normalization,盡可能保證每一層網(wǎng)絡(luò)的輸入具有相同的分布赶促。而最新的 paper液肌,他們?cè)诩尤隻ypass connection 之后,發(fā)現(xiàn)改變 batch normalization 的位置會(huì)有更好的效果鸥滨。)
-
ReLU 的優(yōu)點(diǎn)與缺點(diǎn)嗦哆?
優(yōu)點(diǎn):
- 解決了gradient vanishing問(wèn)題 (在正區(qū)間)
- 計(jì)算速度非嘲妫快,只需要判斷輸入是否大于0
- 收斂速度遠(yuǎn)快于sigmoid和tanh
缺點(diǎn):
- ReLU 的輸出不是 zero-centered
- Dead ReLU Problem老速,指的是某些神經(jīng)元可能永遠(yuǎn)不會(huì)被激活粥喜,導(dǎo)致相應(yīng)的參數(shù)永遠(yuǎn)不能被更新。有兩個(gè)主要原因可能導(dǎo)致這種情況產(chǎn)生: (1) 非常不幸的參數(shù)初始化橘券,這種情況比較少見(jiàn) (2) learning rate 太高導(dǎo)致在訓(xùn)練過(guò)程中參數(shù)更新太大额湘,不幸使網(wǎng)絡(luò)進(jìn)入這種狀態(tài)。解決方法是可以采用 Xavier 初始化方法旁舰,以及避免將 learning rate 設(shè)置太大或使用 adagrad 等自動(dòng)調(diào)節(jié) learning rate 的算法锋华。
幾十年的機(jī)器學(xué)習(xí)發(fā)展中,我們形成了這樣一個(gè)概念:非線性激活函數(shù)要比線性激活函數(shù)更加先進(jìn)箭窜。
尤其是在布滿 Sigmoid 函數(shù)的 BP 神經(jīng)網(wǎng)絡(luò)供置,布滿徑向基函數(shù)的 SVM 神經(jīng)網(wǎng)絡(luò)中,往往有這樣的幻覺(jué)绽快,非線性函數(shù)對(duì)非線性網(wǎng)絡(luò)貢獻(xiàn)巨大芥丧。
該幻覺(jué)在 SVM 中更加嚴(yán)重。核函數(shù)的形式并非完全是 SVM 能夠處理非線性數(shù)據(jù)的主力功臣(支持向量充當(dāng)著隱層角色)坊罢。
那么在深度網(wǎng)絡(luò)中续担,對(duì)非線性的依賴程度就可以縮一縮。另外活孩,在上一部分提到物遇,稀疏特征并不需要網(wǎng)絡(luò)具有很強(qiáng)的處理線性不可分機(jī)制。
綜合以上兩點(diǎn)憾儒,在深度學(xué)習(xí)模型中询兴,使用簡(jiǎn)單、速度快的線性激活函數(shù)可能更為合適起趾。
ReLU 操作可以從下面的圖中理解诗舰。這里的輸出特征圖也可以看作是“修正”過(guò)的特征圖。

所謂麻雀雖小训裆,五臟俱全眶根,ReLU雖小,但也是可以改進(jìn)的边琉。
ReLU的種類
ReLU的區(qū)分主要在負(fù)數(shù)端属百,根據(jù)負(fù)數(shù)端斜率的不同來(lái)進(jìn)行區(qū)分,大致如下圖所示变姨。
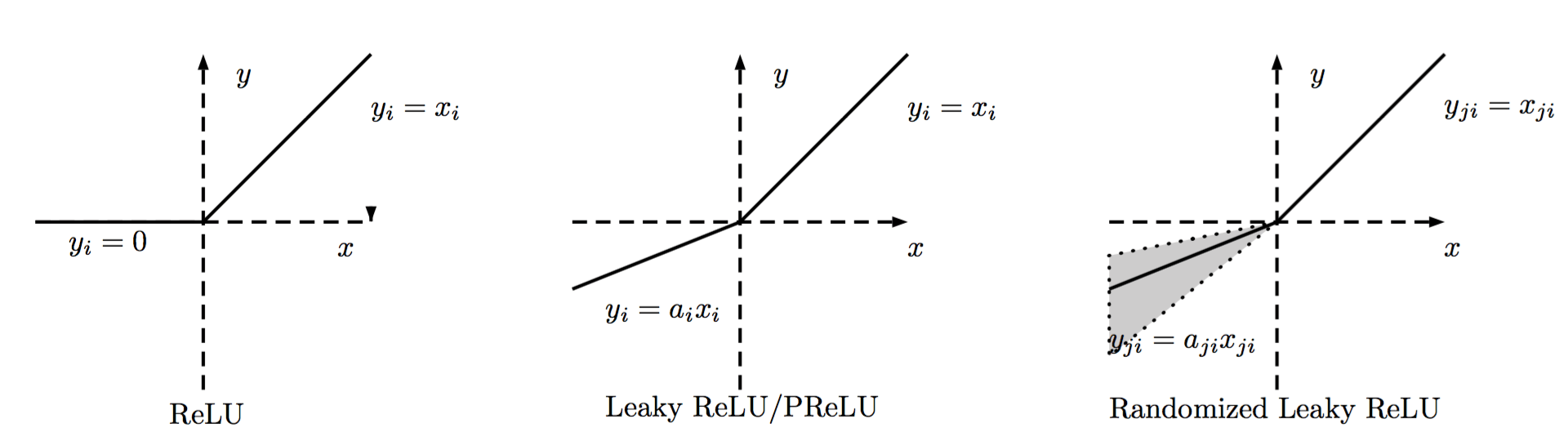
普通的ReLU負(fù)數(shù)端斜率是0族扰,Leaky ReLU則是負(fù)數(shù)端有一個(gè)比較小的斜率,而PReLU則是在后向傳播中學(xué)習(xí)到斜率。而Randomized Leaky ReLU則是使用一個(gè)均勻分布在訓(xùn)練的時(shí)候隨機(jī)生成斜率渔呵,在測(cè)試的時(shí)候使用均值斜率來(lái)計(jì)算怒竿。
效果
其中,NDSB 數(shù)據(jù)集是 Kaggle 的比賽厘肮,而 RReLU 正是在這次比賽中嶄露頭角的。
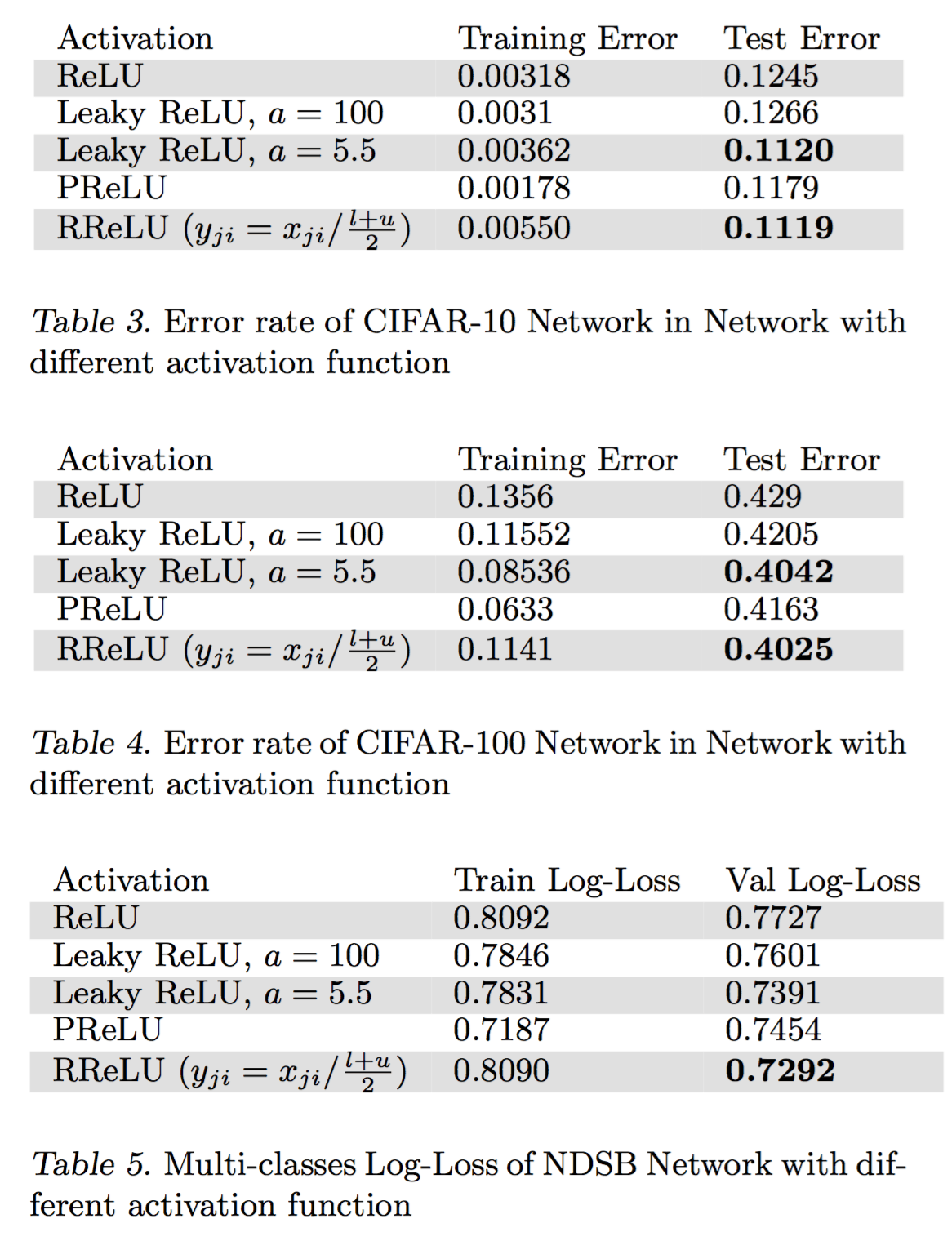
通過(guò)上述結(jié)果睦番,可以看到四點(diǎn):
- 對(duì)于 Leaky ReLU 來(lái)說(shuō)类茂,如果斜率很小,那么與 ReLU 并沒(méi)有大的不同托嚣,當(dāng)斜率大一些時(shí)巩检,效果就好很多。
- 在訓(xùn)練集上示启,PReLU 往往能達(dá)到最小的錯(cuò)誤率兢哭,說(shuō)明 PReLU 容易過(guò)擬合。
- 在 NSDB 數(shù)據(jù)集上 RReLU 的提升比 cifar10 和 cifar100 上的提升更加明顯夫嗓,而 NSDB 數(shù)據(jù)集比較小迟螺,從而可以說(shuō)明,RReLU在與過(guò)擬合的對(duì)抗中更加有效舍咖。
- 對(duì)于 RReLU 來(lái)說(shuō)矩父,還需要研究一下隨機(jī)化得斜率是怎樣影響訓(xùn)練和測(cè)試過(guò)程的。
參考文獻(xiàn)
[1]. Xu B, Wang N, Chen T, et al. Empirical evaluation of rectified activations in convolutional network[J]. arXiv preprint arXiv:1505.00853, 2015.
Pooling
空間池化(Spatial Pooling)(也叫做亞采用或者下采樣)降低了各個(gè)特征圖的維度排霉,但可以保持大部分重要的信息窍株。空間池化有下面幾種方式:最大化攻柠、平均化球订、加和等等。
對(duì)于最大池化(Max Pooling)瑰钮,我們定義一個(gè)空間鄰域(比如冒滩,2x2 的窗口),并從窗口內(nèi)的修正特征圖中取出最大的元素浪谴。除了取最大元素旦部,我們也可以取平均(Average Pooling)或者對(duì)窗口內(nèi)的元素求和。在實(shí)際中较店,最大池化被證明效果更好一些士八。
下面的圖展示了使用 2x2 窗口在修正特征圖(在卷積 + ReLU 操作后得到)使用最大池化的例子。
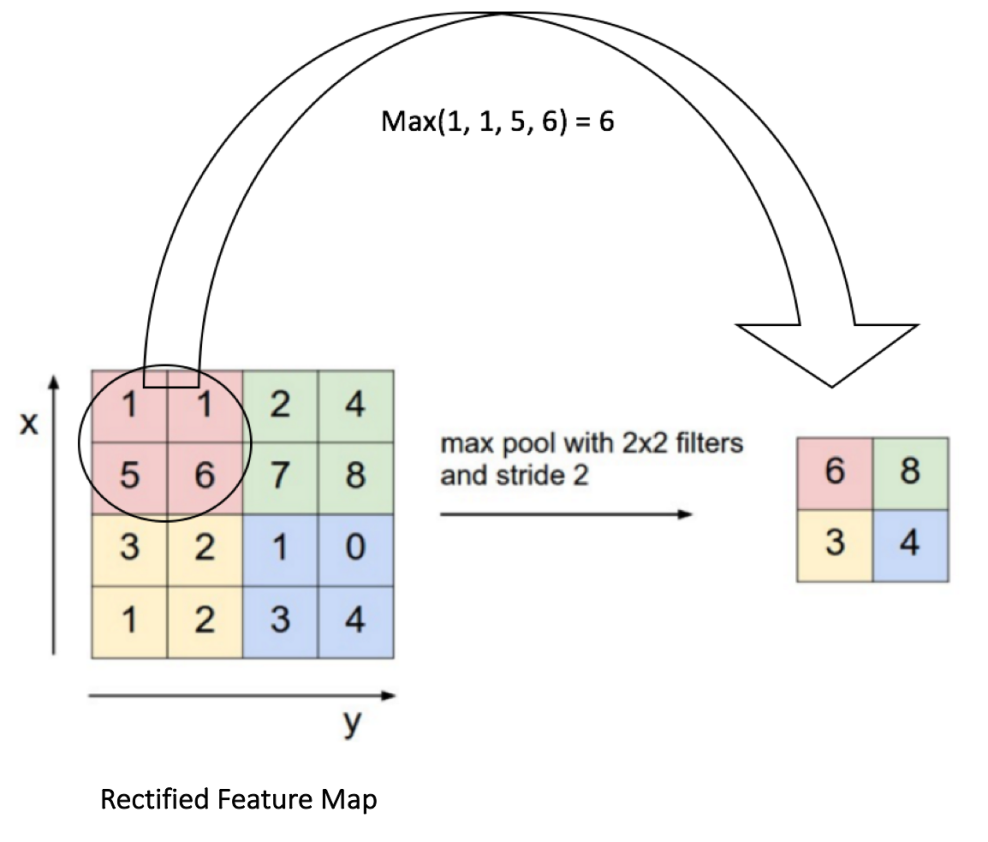
我們以 2 個(gè)元素(也叫做“步長(zhǎng)”)滑動(dòng)我們 2x2 的窗口梁呈,并在每個(gè)區(qū)域內(nèi)取最大值婚度。如上圖所示,這樣操作可以降低我們特征圖的維度。
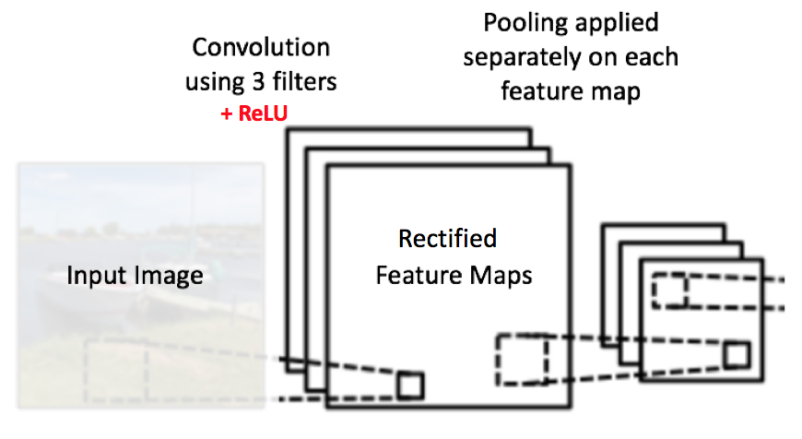
在下圖展示的網(wǎng)絡(luò)中蝗茁,池化操作是分開(kāi)應(yīng)用到各個(gè)特征圖的(注意醋虏,因?yàn)檫@樣的操作,我們可以從三個(gè)輸入圖中得到三個(gè)輸出圖)哮翘。
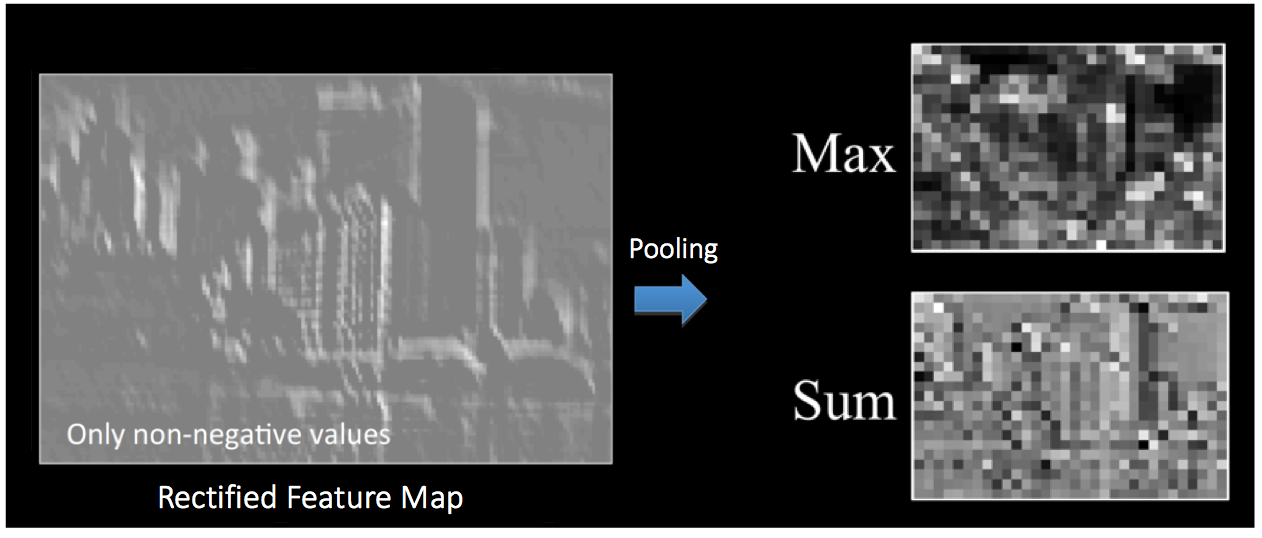
下圖展示了我們?cè)?ReLU 操作之后得到的修正特征圖的池化操作的效果:
池化函數(shù)可以逐漸降低輸入表示的空間尺度颈嚼。特別地,Pooling 的好處是:
使輸入表示(特征維度)變得更小饭寺,并且網(wǎng)絡(luò)中的參數(shù)和計(jì)算的數(shù)量更加可控的減小阻课,因此,可以控制過(guò)擬合艰匙。
使網(wǎng)絡(luò)對(duì)于輸入圖像中更小的變化限煞、冗余和變換變得不變性(輸入的微小冗余將不會(huì)改變池化的輸出——因?yàn)槲覀冊(cè)诰植苦徲蛑惺褂昧俗畲蠡?平均值的操作)。
-
幫助我們獲取圖像最大程度上的尺度不變性(準(zhǔn)確的詞是“不變性”)员凝。它非常的強(qiáng)大署驻,因?yàn)槲覀兛梢詸z測(cè)圖像中的物體,無(wú)論它們位置在哪里健霹。
?
到目前為止我們了解了卷積旺上、ReLU 和池化是如何操作的。理解這些層是構(gòu)建任意 CNN 的基礎(chǔ)是很重要的糖埋。正如下圖所示抚官,我們有兩組卷積、ReLU & 池化層 —— 第二組卷積層使用六個(gè)濾波器對(duì)第一組的池化層的輸出繼續(xù)卷積阶捆,得到一共六個(gè)特征圖凌节。接下來(lái)對(duì)所有六個(gè)特征圖應(yīng)用 ReLU。接著我們對(duì)六個(gè)修正特征圖分別進(jìn)行最大池化操作洒试。
這些層一起就可以從圖像中提取有用的特征倍奢,并在網(wǎng)絡(luò)中引入非線性,減少特征維度垒棋,同時(shí)保持這些特征具有某種程度上的尺度變化不變性卒煞。
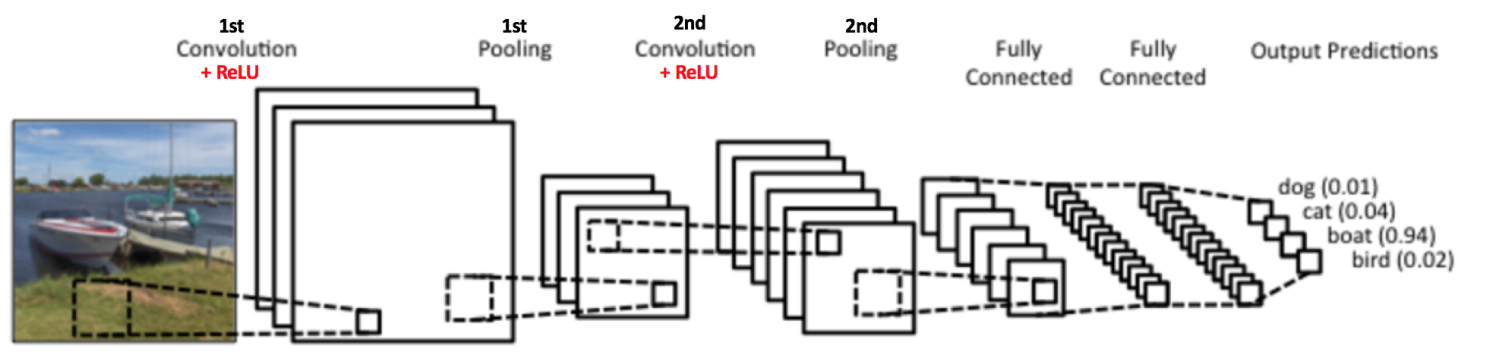
第二組池化層的輸出作為全連接層的輸入,接下來(lái)我們將介紹全連接層叼架。
Connect
全連接層是傳統(tǒng)的多層感知器畔裕,在輸出層使用的是 softmax 激活函數(shù)(也可以使用其他像 SVM 的分類器,但在本文中只使用 softmax)乖订“缛模「全連接」(Fully Connected) 這個(gè)詞表明前面層的所有神經(jīng)元都與下一層的所有神經(jīng)元連接。
卷積和池化層的輸出表示了輸入圖像的高級(jí)特征乍构。全連接層的目的是為了使用這些特征把輸入圖像基于訓(xùn)練數(shù)據(jù)集進(jìn)行分類甜无。比如,在下面圖中我們進(jìn)行的圖像分類有四個(gè)可能的輸出結(jié)果(注意下圖并沒(méi)有顯示全連接層的節(jié)點(diǎn)連接)。
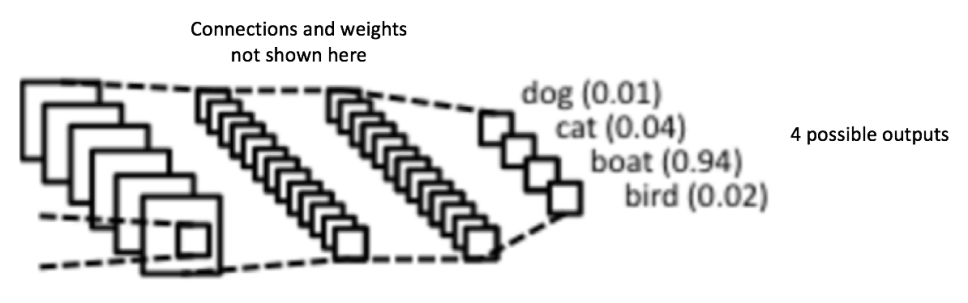
除了分類岂丘,添加一個(gè)全連接層也(一般)是學(xué)習(xí)這些特征的非線性組合的簡(jiǎn)單方法陵究。從卷積和池化層得到的大多數(shù)特征可能對(duì)分類任務(wù)有效,但這些特征的組合可能會(huì)更好奥帘。
從全連接層得到的輸出概率和為 1铜邮。這個(gè)可以在輸出層使用 softmax 作為激活函數(shù)進(jìn)行保證。softmax 函數(shù)輸入一個(gè)任意大于 0 值的矢量寨蹋,并把它們轉(zhuǎn)換為零一之間的數(shù)值矢量松蒜,其和為一。
Use Backpropagation to Train whole network
正如上面討論的钥庇,卷積 + 池化層的作用是從輸入圖像中提取特征牍鞠,而全連接層的作用是分類器咖摹。
注意在下面的圖中评姨,因?yàn)檩斎氲膱D像是船,對(duì)于船這一類的目標(biāo)概率是 1萤晴,而其他三類的目標(biāo)概率是 0吐句,即
輸入圖像 = 船
-
目標(biāo)矢量 = [0, 0, 1, 0]
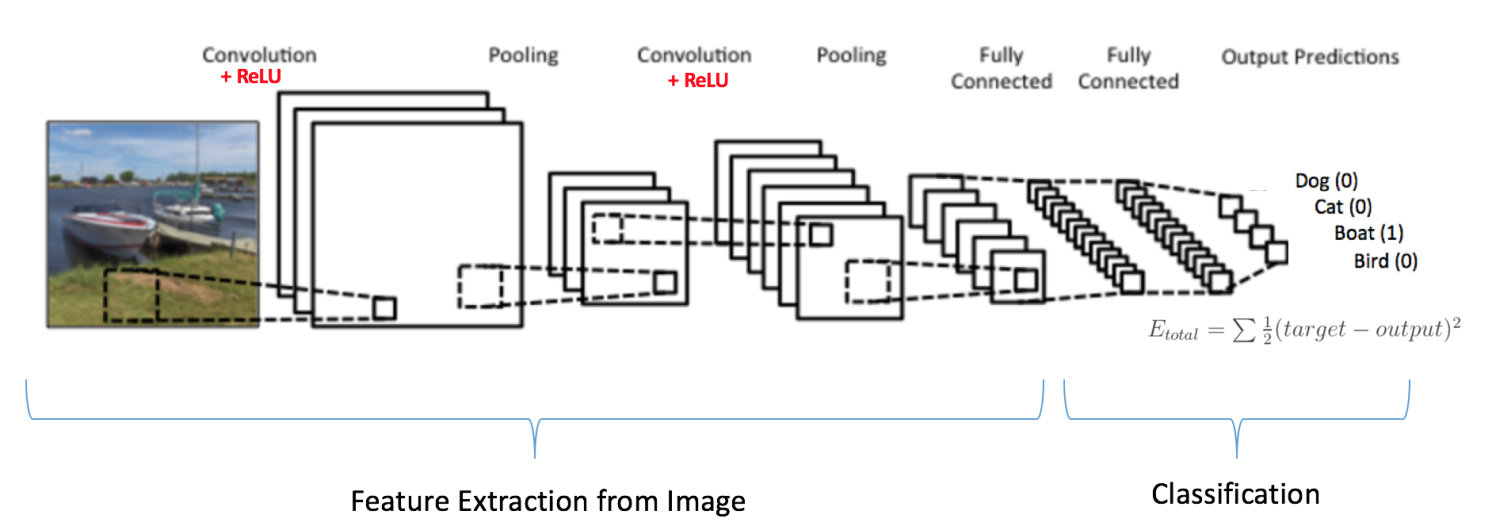
完整的卷積網(wǎng)絡(luò)的訓(xùn)練過(guò)程可以總結(jié)如下:
- 第一步:我們初始化所有的濾波器,使用隨機(jī)值設(shè)置參數(shù)/權(quán)重
- 第二步:網(wǎng)絡(luò)接收一張訓(xùn)練圖像作為輸入店读,通過(guò)前向傳播過(guò)程(卷積嗦枢、ReLU 和池化操作,以及全連接層的前向傳播)屯断,找到各個(gè)類的輸出概率
- 我們假設(shè)船這張圖像的輸出概率是 [0.2, 0.4, 0.1, 0.3]
- 因?yàn)閷?duì)于第一張訓(xùn)練樣本的權(quán)重是隨機(jī)分配的文虏,輸出的概率也是隨機(jī)的
- 第三步:在輸出層計(jì)算總誤差(計(jì)算 4 類的和)
- Total Error = ∑ ? (target probability – output probability) 2
- 第四步:使用反向傳播算法,根據(jù)網(wǎng)絡(luò)的權(quán)重計(jì)算誤差的梯度殖演,并使用梯度下降算法更新所有濾波器的值/權(quán)重以及參數(shù)的值氧秘,使輸出誤差最小化
- 權(quán)重的更新與它們對(duì)總誤差的占比有關(guān)
- 當(dāng)同樣的圖像再次作為輸入,這時(shí)的輸出概率可能會(huì)是 [0.1, 0.1, 0.7, 0.1]趴久,這就與目標(biāo)矢量 [0, 0, 1, 0] 更接近了
- 這表明網(wǎng)絡(luò)已經(jīng)通過(guò)調(diào)節(jié)權(quán)重/濾波器丸相,可以正確對(duì)這張?zhí)囟▓D像的分類,這樣輸出的誤差就減小了
- 像濾波器數(shù)量彼棍、濾波器大小灭忠、網(wǎng)絡(luò)結(jié)構(gòu)等這樣的參數(shù),在第一步前都是固定的座硕,在訓(xùn)練過(guò)程中保持不變——僅僅是濾波器矩陣的值和連接權(quán)重在更新
- 第五步:對(duì)訓(xùn)練數(shù)據(jù)中所有的圖像重復(fù)步驟 1 ~ 4
上面的這些步驟可以訓(xùn)練 ConvNet —— 這本質(zhì)上意味著對(duì)于訓(xùn)練數(shù)據(jù)集中的圖像弛作,ConvNet 在更新了所有權(quán)重和參數(shù)后,已經(jīng)優(yōu)化為可以對(duì)這些圖像進(jìn)行正確分類华匾。
當(dāng)一張新的(未見(jiàn)過(guò)的)圖像作為 ConvNet 的輸入缆蝉,網(wǎng)絡(luò)將會(huì)再次進(jìn)行前向傳播過(guò)程,并輸出各個(gè)類別的概率(對(duì)于新的圖像,輸出概率是使用已經(jīng)在前面訓(xùn)練樣本上優(yōu)化分類的參數(shù)進(jìn)行計(jì)算的)刊头。如果我們的訓(xùn)練數(shù)據(jù)集非常的大黍瞧,網(wǎng)絡(luò)將會(huì)(有希望)對(duì)新的圖像有很好的泛化,并把它們分到正確的類別中去原杂。
注 1: 上面的步驟已經(jīng)簡(jiǎn)化印颤,也避免了數(shù)學(xué)詳情,只為提供訓(xùn)練過(guò)程的直觀內(nèi)容穿肄。
注 2:在上面的例子中我們使用了兩組卷積和池化層年局。然而請(qǐng)記住,這些操作可以在一個(gè) ConvNet 中重復(fù)多次咸产。實(shí)際上矢否,現(xiàn)在有些表現(xiàn)最好的 ConvNet 擁有多達(dá)十幾層的卷積和池化層!同時(shí)脑溢,每次卷積層后面不一定要有池化層僵朗。如下圖所示,我們可以在池化操作前連續(xù)使用多個(gè)卷積 + ReLU 操作屑彻。還有验庙,請(qǐng)注意 ConvNet 的各層在下圖中是如何可視化的。

Visualization on CNN
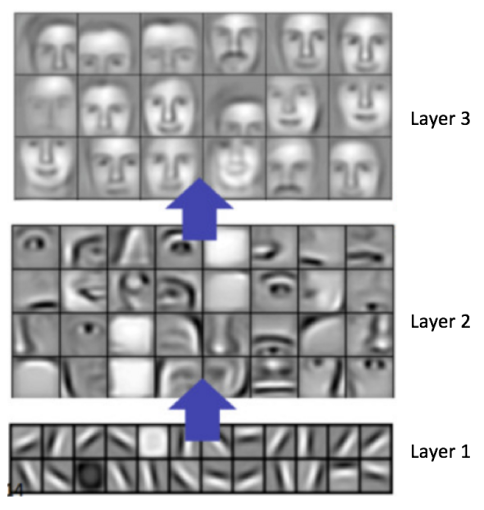
一般而言社牲,越多的卷積步驟粪薛,網(wǎng)絡(luò)可以學(xué)到的識(shí)別特征就越復(fù)雜。比如搏恤,ConvNet 的圖像分類可能在第一層從原始像素中檢測(cè)出邊緣违寿,然后在第二層使用邊緣檢測(cè)簡(jiǎn)單的形狀,接著使用這些形狀檢測(cè)更高級(jí)的特征熟空,比如更高層的人臉藤巢。下面的圖中展示了這些內(nèi)容——我們使用卷積深度置信網(wǎng)絡(luò)學(xué)習(xí)到的特征,這張圖僅僅是用來(lái)證明上面的內(nèi)容(這僅僅是一個(gè)例子:真正的卷積濾波器可能會(huì)檢測(cè)到對(duì)我們毫無(wú)意義的物體)痛阻。
Adam Harley 創(chuàng)建了一個(gè)卷積神經(jīng)網(wǎng)絡(luò)的可視化結(jié)果菌瘪,使用的是 MNIST 手寫數(shù)字的訓(xùn)練集。我強(qiáng)烈建議使用它來(lái)理解 CNN 的工作原理阱当。
我們可以在下圖中看到網(wǎng)絡(luò)是如何識(shí)別輸入 「8」 的俏扩。注意下圖中的可視化并沒(méi)有單獨(dú)展示 ReLU 操作。
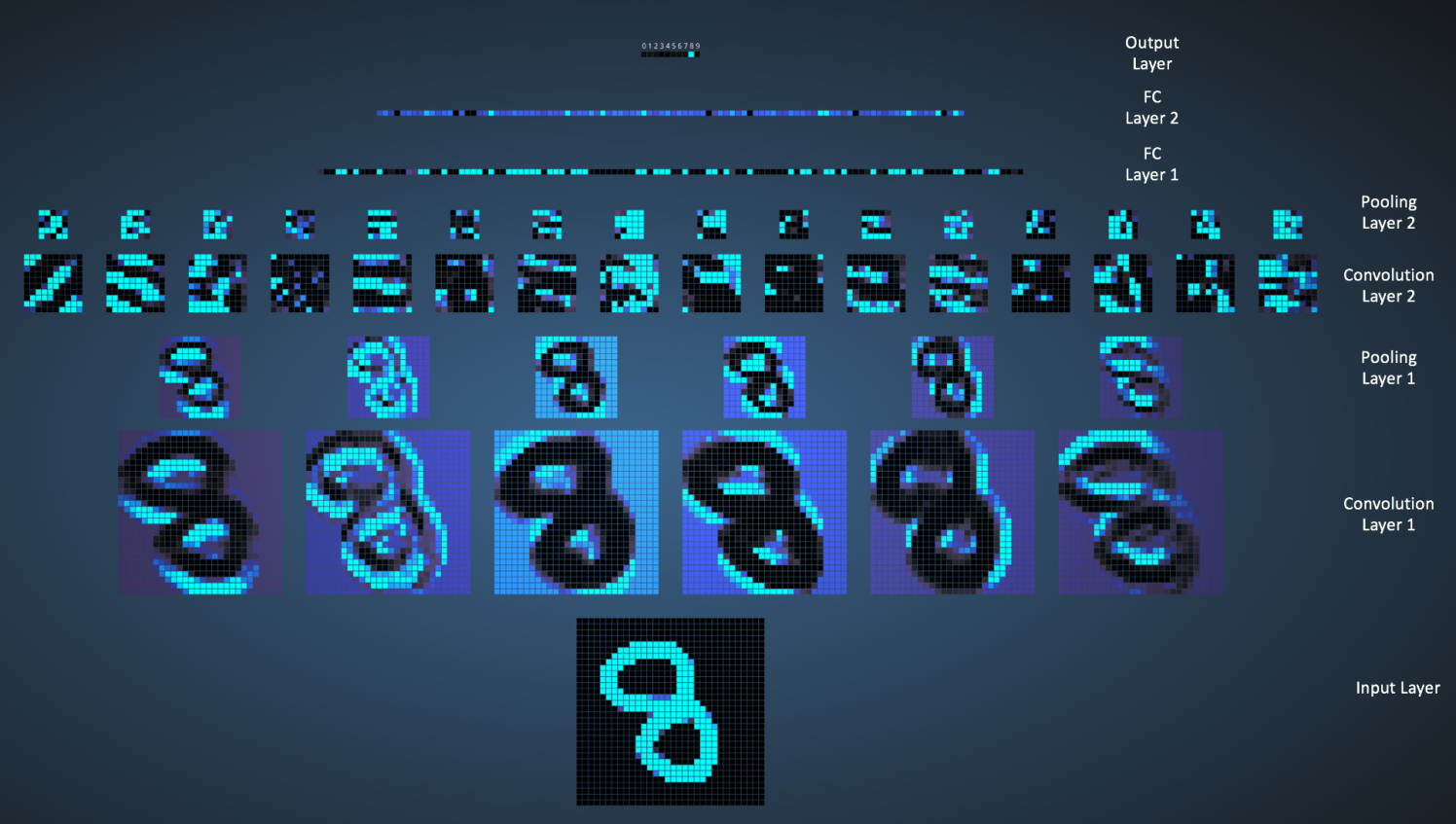
輸入圖像包含 1024 個(gè)像素(32 x 32 大斜滋怼)录淡,第一個(gè)卷積層(卷積層 1)由六個(gè)獨(dú)特的 5x5 (步長(zhǎng)為 1)的濾波器組成。如圖可見(jiàn)油坝,使用六個(gè)不同的濾波器得到一個(gè)深度為六的特征圖嫉戚。
卷積層 1 后面是池化層 1刨裆,在卷積層 1 得到的六個(gè)特征圖上分別進(jìn)行 2x2 的最大池化(步長(zhǎng)為 2)的操作。你可以在池化層上把鼠標(biāo)移動(dòng)到任意的像素上彬檀,觀察在前面卷積層(如上圖所示)得到的 4x4 的小格帆啃。你會(huì)發(fā)現(xiàn) 4x4 小格中的最大值(最亮)的像素將會(huì)進(jìn)入到池化層。

池化層 1 后面的是六個(gè) 5x5 (步長(zhǎng)為 1)的卷積濾波器窍帝,進(jìn)行卷積操作努潘。后面就是池化層 2,進(jìn)行 2x2 的最大池化(步長(zhǎng)為 2)的操作坤学。這兩層的概念和前面描述的一樣疯坤。
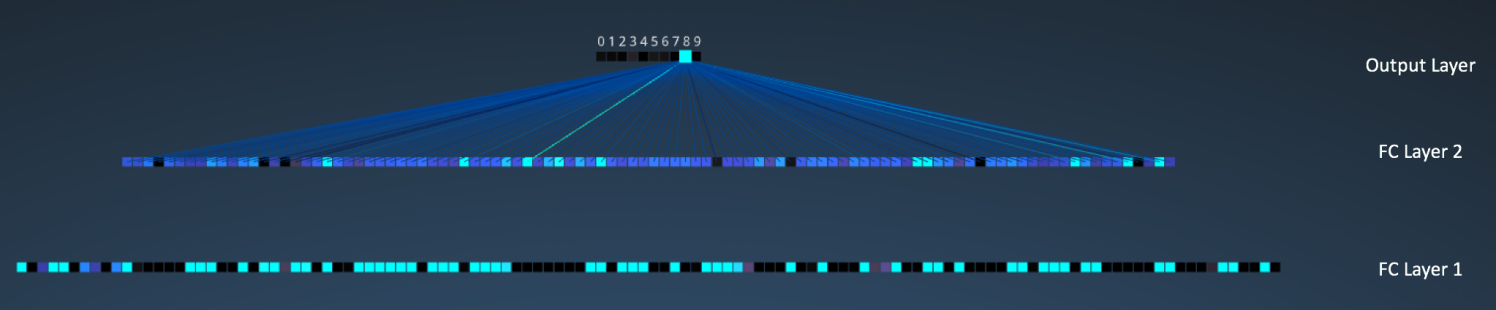
接下來(lái)我們就到了三個(gè)全連接層。它們是:
- 第一個(gè)全連接層有 120 個(gè)神經(jīng)元
- 第二層全連接層有 100 個(gè)神經(jīng)元
- 第三個(gè)全連接層有 10 個(gè)神經(jīng)元深浮,對(duì)應(yīng) 10 個(gè)數(shù)字——也就做輸出層
注意在下圖中压怠,輸出層中的 10 個(gè)節(jié)點(diǎn)的各個(gè)都與第二個(gè)全連接層的所有 100 個(gè)節(jié)點(diǎn)相連(因此叫做全連接)。
同時(shí)飞苇,注意在輸出層那個(gè)唯一的亮的節(jié)點(diǎn)是如何對(duì)應(yīng)于數(shù)字 “8” 的——這表明網(wǎng)絡(luò)把我們的手寫數(shù)字正確分類(越亮的節(jié)點(diǎn)表明從它得到的輸出值越高菌瘫,即,8 是所有數(shù)字中概率最高的)玄柠。
同樣的 3D 可視化可以在這里看到突梦。
Other ConvNet
卷積神經(jīng)網(wǎng)絡(luò)從上世紀(jì) 90 年代初期開(kāi)始出現(xiàn)诫舅。我們上面提到的 LeNet 是早期卷積神經(jīng)網(wǎng)絡(luò)之一羽利。其他有一定影響力的架構(gòu)如下所示:
- LeNet (1990s): 本文已介紹。
- 1990s to 2012:在上世紀(jì) 90 年代后期至 2010 年初期刊懈,卷積神經(jīng)網(wǎng)絡(luò)進(jìn)入孵化期这弧。隨著數(shù)據(jù)量和計(jì)算能力的逐漸發(fā)展,卷積神經(jīng)網(wǎng)絡(luò)可以處理的問(wèn)題變得越來(lái)越有趣虚汛。
- AlexNet (2012) – 在 2012匾浪,Alex Krizhevsky (與其他人)發(fā)布了 AlexNet,它是比 LeNet 更深更寬的版本卷哩,并在 2012 年的 ImageNet 大規(guī)模視覺(jué)識(shí)別大賽(ImageNet Large Scale Visual Recognition Challenge蛋辈,ILSVRC)中以巨大優(yōu)勢(shì)獲勝。這對(duì)于以前的方法具有巨大的突破将谊,當(dāng)前 CNN 大范圍的應(yīng)用也是基于這個(gè)工作冷溶。
- ZF Net (2013) – ILSVRC 2013 的獲勝者是來(lái)自 Matthew Zeiler 和 Rob Fergus 的卷積神經(jīng)網(wǎng)絡(luò)。它以 ZFNet (Zeiler & Fergus Net 的縮寫)出名尊浓。它是在 AlexNet 架構(gòu)超參數(shù)上進(jìn)行調(diào)整得到的效果提升逞频。
- GoogLeNet (2014) – ILSVRC 2014 的獲勝者是來(lái)自于 Google 的 Szegedy等人的卷積神經(jīng)網(wǎng)絡(luò)。它的主要貢獻(xiàn)在于使用了一個(gè) Inception 模塊栋齿,可以大量減少網(wǎng)絡(luò)的參數(shù)個(gè)數(shù)(4M苗胀,AlexNet 有 60M 的參數(shù))襟诸。
- VGGNet (2014) – 在 ILSVRC 2014 的領(lǐng)先者中有一個(gè) VGGNet 的網(wǎng)絡(luò)。它的主要貢獻(xiàn)是展示了網(wǎng)絡(luò)的深度(層數(shù))對(duì)于性能具有很大的影響基协。
- ResNets (2015) – 殘差網(wǎng)絡(luò)是何凱明(和其他人)開(kāi)發(fā)的歌亲,并贏得 ILSVRC 2015 的冠軍。ResNets 是當(dāng)前卷積神經(jīng)網(wǎng)絡(luò)中最好的模型澜驮,也是實(shí)踐中使用 ConvNet 的默認(rèn)選擇(截至到 2016 年五月)应结。
- DenseNet (2016 八月) – 近來(lái)由 Gao Huang (和其他人)發(fā)表的,the Densely Connected Convolutional Network 的各層都直接于其他層以前向的方式連接泉唁。DenseNet 在五種競(jìng)爭(zhēng)積累的目標(biāo)識(shí)別基準(zhǔn)任務(wù)中鹅龄,比以前最好的架構(gòu)有顯著的提升⊥ば螅可以在這里看 Torch 實(shí)現(xiàn)扮休。
CNN on TensorFlow
Tensorflow 在卷積和池化上有很強(qiáng)的靈活性。我們改如何處理邊界拴鸵?步長(zhǎng)應(yīng)該設(shè)多大玷坠?在這個(gè)實(shí)例里,我們會(huì)一直使用 vanilla 版本劲藐。我們的卷積網(wǎng)絡(luò)選用步長(zhǎng)(stride size)為 1八堡,邊距(padding size)為 0 的模板,保證輸出和輸入是同一個(gè)大衅肝摺(嚴(yán)格卷積)兄渺。我們的池化選用簡(jiǎn)單傳統(tǒng)的 $2 \times 2$ 大小的模板作為 max pooling(最大池化)。為了使代碼更簡(jiǎn)潔汰现,我們把這部分抽象成一個(gè)函數(shù):
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = 'SAME')
Convolution Layer on TensorFlow
卷積操作是使用一個(gè)二維的卷積核在一個(gè)批處理的圖片上進(jìn)行不斷掃描挂谍。具體操作就是將一個(gè)卷積和在每張圖片上按照一個(gè)合適的尺寸在每個(gè)通道上面進(jìn)行掃描。為了達(dá)到更好的卷積效率瞎饲,需要在不同的通道和不同的卷積核之間進(jìn)行權(quán)衡口叙。
-
conv2d:任意的卷積核,能同時(shí)在不同的通道上面進(jìn)行卷積操作嗅战。 -
depthwise_conv2d:卷積核能相互獨(dú)立地在自己的通道上面進(jìn)行卷積操作妄田。 -
separable_conv2d:在縱深卷積depthwise filter之后進(jìn)行逐點(diǎn)卷積separable filter。
注意:雖然這些操作被稱之為「卷積」操作驮捍,但是嚴(yán)格地來(lái)說(shuō)疟呐,他們只是互相關(guān),因?yàn)榫矸e核沒(méi)有做一個(gè)逆向的卷積過(guò)程厌漂。
卷積核的卷積過(guò)程是按照 strides 參數(shù)來(lái)確定的萨醒,比如 strides = [1, 1, 1, 1] 表示卷積核對(duì)每個(gè)像素點(diǎn)進(jìn)行卷積,即在二維屏幕上面苇倡,兩個(gè)軸方向的步長(zhǎng)都是 1富纸。strides = [1, 2, 2, 1]表示卷積核對(duì)每隔一個(gè)像素點(diǎn)進(jìn)行卷積囤踩,即在二維屏幕上面,兩個(gè)軸方向的步長(zhǎng)都是 2晓褪。
如果我們暫不考慮通道這個(gè)因素堵漱,那么卷積操作的空間含義定義如下:如果輸入數(shù)據(jù)是一個(gè)四維的 input ,數(shù)據(jù)維度是[batch, in_height, in_width, ...]涣仿,卷積核也是一個(gè)四維的卷積核勤庐,數(shù)據(jù)維度是[filter_height, filter_width, ...],那么好港,對(duì)于輸出數(shù)據(jù)的維度 shape(output)愉镰,這取決于填充參數(shù)padding 的設(shè)置:
-
padding = 'SAME':向下取舍,僅適用于全尺寸操作钧汹,即輸入數(shù)據(jù)維度和輸出數(shù)據(jù)維度相同丈探。out_height = ceil(float(in_height) / float(strides[1])) out_width = ceil(float(in_width) / float(strides[2])) -
padding = 'VALID':向上取舍,適用于部分窗口拔莱,即輸入數(shù)據(jù)維度和輸出數(shù)據(jù)維度不同碗降。out_height = ceil(float(in_height - filter_height + 1) / float(strides[1])) out_width = ceil(float(in_width - filter_width + 1) / float(strides[2]))
output[b, i, j, :] =
sum_{di, dj} input[b, strides[1] * i + di, strides[2] * j + dj, ...] *
filter[di, dj, ...]
因?yàn)椋?code>input數(shù)據(jù)是一個(gè)四維的,每一個(gè)通道上面是一個(gè)向量input[b, i, j, :]塘秦。對(duì)于conv2d 讼渊,這些向量會(huì)被卷積核filter[di, dj, :, :]相乘而產(chǎn)生一個(gè)新的向量。對(duì)于depthwise_conv_2d尊剔,每個(gè)標(biāo)量分量input[b, i , j, k]將在 k 個(gè)通道上面獨(dú)立地被卷積核 filter[di, dj, k]進(jìn)行卷積操作爪幻,然后把所有得到的向量進(jìn)行連接組合成一個(gè)新的向量。
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
這個(gè)函數(shù)的作用是對(duì)一個(gè)四維的輸入數(shù)據(jù) input 和四維的卷積核 filter 進(jìn)行操作赋兵,然后對(duì)輸入數(shù)據(jù)進(jìn)行一個(gè)二維的卷積操作笔咽,最后得到卷積之后的結(jié)果搔预。
給定的輸入 tensor 的維度是 [batch, in_height, in_width, in_channels]霹期,卷積核 tensor 的維度是[filter_height, filter_width, in_channels, out_channels],具體卷積操作如下:
- 將卷積核的維度轉(zhuǎn)換成一個(gè)二維的矩陣形狀
[filter_height * filter_width* in_channels, output_channels] - 對(duì)于每個(gè)批處理的圖片拯田,我們將輸入 tensor 轉(zhuǎn)換成一個(gè)臨時(shí)的數(shù)據(jù)維度
[batch, out_height, out_width, filter_height * filter_width * in_channels] - 對(duì)于每個(gè)批處理的圖片历造,我們右乘以卷積核,得到最后的輸出結(jié)果船庇。
更加具體的表示細(xì)節(jié)為吭产,如果采用默認(rèn)的 NHWC data_format形式:
output[b, i, j, k] =
sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]
所以我們注意到,必須要有strides[0] = strides[3] = 1鸭轮。在大部分處理過(guò)程中臣淤,卷積核的水平移動(dòng)步數(shù)和垂直移動(dòng)步數(shù)是相同的,即strides = [1, stride, stride, 1]窃爷。
使用例子:
import numpy as np
import tensorflow as tf
input_data = tf.Variable(np.random.rand(10, 6, 6, 3), dtype = np.float32)
filter_data = tf.Variable(np.random.rand(2, 2, 3, 1), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run(y))
print(sess.run(tf.shape(y)))
輸入?yún)?shù):
-
input: 一個(gè)Tensor邑蒋。數(shù)據(jù)類型必須是float32或者float64姓蜂。 -
filter: 一個(gè)Tensor。數(shù)據(jù)類型必須是input相同医吊。 -
strides: 一個(gè)長(zhǎng)度是 4 的一維整數(shù)類型數(shù)組钱慢,每一維度對(duì)應(yīng)的是 input 中每一維的對(duì)應(yīng)移動(dòng)步數(shù),比如卿堂,strides[1]對(duì)應(yīng)input[1]的移動(dòng)步數(shù)束莫。 -
padding: 一個(gè)字符串,取值為SAME或者VALID草描。 -
use_cudnn_on_gpu: 一個(gè)可選布爾值览绿,默認(rèn)情況下是True。 -
data_format:一個(gè)可選string穗慕,NHWC或者NCHW挟裂。默認(rèn)是用NHWC。主要是規(guī)定了輸入 tensor 和輸出 tensor 的四維形式揍诽。如果使用NHWC诀蓉,則數(shù)據(jù)以[batch, in_height, in_width, in_channels]存儲(chǔ);如果使用NCHW暑脆,則數(shù)據(jù)以[batch, in_channels, in_height, in_width]存儲(chǔ)渠啤。 -
name: (可選)為這個(gè)操作取一個(gè)名字。
輸出參數(shù):
- 一個(gè)
Tensor添吗,數(shù)據(jù)類型是input相同沥曹。
Pooling Layer on TensorFlow
池化操作是利用一個(gè)矩陣窗口在輸入張量上進(jìn)行掃描,并且將每個(gè)矩陣窗口中的值通過(guò)取最大值碟联,平均值或者其他方法來(lái)減少元素個(gè)數(shù)妓美。每個(gè)池化操作的矩陣窗口大小是由 ksize 來(lái)指定的,并且根據(jù)步長(zhǎng)參數(shù) strides 來(lái)決定移動(dòng)步長(zhǎng)鲤孵。比如壶栋,如果 strides 中的值都是1,那么每個(gè)矩陣窗口都將被使用普监。如果 strides 中的值都是2贵试,那么每一維度上的矩陣窗口都是每隔一個(gè)被使用。以此類推凯正。
更具體的輸出結(jié)果是:
output[i] = reduce( value[ strides * i: strides * i + ksize ] )
輸出數(shù)據(jù)維度是:
shape(output) = (shape(value) - ksize + 1) / strides
其中毙玻,取舍方向取決于參數(shù) padding :
-
padding = 'SAME': 向下取舍,僅適用于全尺寸操作廊散,即輸入數(shù)據(jù)維度和輸出數(shù)據(jù)維度相同桑滩。 -
padding = 'VALID: 向上取舍,適用于部分窗口允睹,即輸入數(shù)據(jù)維度和輸出數(shù)據(jù)維度不同运准。
tf.nn.avg_pool(value, ksize, strides, padding , data_format='NHWC', name=None)
這個(gè)函數(shù)的作用是計(jì)算池化區(qū)域中元素的平均值往声。
使用例子:
import numpy as np
import tensorflow as tf
input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
output = tf.nn.avg_pool(value = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1], padding = 'SAME')
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run(output))
print(sess.run(tf.shape(output)))
輸入?yún)?shù):
-
value: 一個(gè)四維的Tensor。數(shù)據(jù)維度是[batch, height, width, channels]戳吝。數(shù)據(jù)類型是float32浩销,float64塔鳍,qint8胞得,quint8,qint32匾效。 -
ksize: 一個(gè)長(zhǎng)度不小于 4 的整型數(shù)組陆盘。每一位上面的值對(duì)應(yīng)于輸入數(shù)據(jù)張量中每一維的窗口對(duì)應(yīng)值普筹。 -
strides: 一個(gè)長(zhǎng)度不小于 4 的整型數(shù)組。該參數(shù)指定滑動(dòng)窗口在輸入數(shù)據(jù)張量每一維上面的步長(zhǎng)隘马。 -
padding: 一個(gè)字符串太防,取值為SAME或者VALID。 -
data_format:一個(gè)可選string酸员,NHWC或者NCHW蜒车。默認(rèn)是用NHWC。主要是規(guī)定了輸入 tensor 和輸出 tensor 的四維形式幔嗦。如果使用NHWC酿愧,則數(shù)據(jù)以[batch, in_height, in_width, in_channels]存儲(chǔ);如果使用NCHW邀泉,則數(shù)據(jù)以[batch, in_channels, in_height, in_width]存儲(chǔ)嬉挡。 -
name: (可選)為這個(gè)操作取一個(gè)名字。
輸出參數(shù):
- 一個(gè)Tensor汇恤,數(shù)據(jù)類型和value相同庞钢。
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
這個(gè)函數(shù)的作用是計(jì)算 pooling 區(qū)域中元素的最大值。
tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax=None, name=None)
這個(gè)函數(shù)的作用是計(jì)算池化區(qū)域中元素的最大值和該最大值所在的位置因谎。
因?yàn)樵谟?jì)算位置 argmax 的時(shí)候基括,我們將 input 鋪平了進(jìn)行計(jì)算,所以蓝角,如果 input = [b, y, x, c]阱穗,那么索引位置是 `( ( b * height + y ) * width + x ) * channels + c
查看源碼,該API只能在GPU環(huán)境下使用使鹅,所以我沒(méi)有測(cè)試下面的使用例子,如果你可以測(cè)試昌抠,請(qǐng)告訴我程序是否可以運(yùn)行患朱。
源碼展示:
REGISTER_KERNEL_BUILDER(Name("MaxPoolWithArgmax")
.Device(DEVICE_GPU)
.TypeConstraint<int64>("Targmax")
.TypeConstraint<float>("T"),
MaxPoolingWithArgmaxOp<Eigen::GpuDevice, float>);
REGISTER_KERNEL_BUILDER(Name("MaxPoolWithArgmax")
.Device(DEVICE_GPU)
.TypeConstraint<int64>("Targmax")
.TypeConstraint<Eigen::half>("T"),
MaxPoolingWithArgmaxOp<Eigen::GpuDevice, Eigen::half>);
使用例子:
import numpy as np
import tensorflow as tf
input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = tf.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32)
y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
output, argmax = tf.nn.max_pool_with_argmax(input = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1], padding = 'SAME')
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run(output))
print(sess.run(tf.shape(output)))
輸入?yún)?shù):
-
input: 一個(gè)四維的Tensor。數(shù)據(jù)維度是[batch, height, width, channels]炊苫。數(shù)據(jù)類型是float32裁厅。 -
ksize: 一個(gè)長(zhǎng)度不小于 4 的整型數(shù)組冰沙。每一位上面的值對(duì)應(yīng)于輸入數(shù)據(jù)張量中每一維的窗口對(duì)應(yīng)值。 -
strides: 一個(gè)長(zhǎng)度不小于 4 的整型數(shù)組执虹。該參數(shù)指定滑動(dòng)窗口在輸入數(shù)據(jù)張量每一維上面的步長(zhǎng)拓挥。 -
padding: 一個(gè)字符串,取值為SAME或者VALID袋励。 -
Targmax: 一個(gè)可選的數(shù)據(jù)類型:tf.int32或者tf.int64侥啤。默認(rèn)情況下是tf.int64。 -
name: (可選)為這個(gè)操作取一個(gè)名字茬故。
輸出參數(shù):
一個(gè)元祖張量 (output, argmax):
-
output: 一個(gè)Tensor盖灸,數(shù)據(jù)類型是float32。表示池化區(qū)域的最大值磺芭。 -
argmax: 一個(gè)Tensor赁炎,數(shù)據(jù)類型是Targmax。數(shù)據(jù)維度是四維的钾腺。
Weight Initialization
所以徙垫,為了創(chuàng)建這個(gè)模型,我們需要?jiǎng)?chuàng)建大量的權(quán)重和偏置項(xiàng)放棒,這個(gè)模型中的權(quán)重在初始化的時(shí)候應(yīng)該加入少量的噪聲來(lái)打破對(duì)稱性以及避免 0 梯度松邪。由于我們使用的是 ReLU 神經(jīng)元,因此比較好的做法是用一個(gè)較小的正數(shù)來(lái)初始化偏置項(xiàng)哨查,以避免神經(jīng)元節(jié)點(diǎn)輸出恒為 0 的問(wèn)題(dead neurons)逗抑。為了不再建立模型的時(shí)候反復(fù)做初始化操作,我們定義兩個(gè)函數(shù)用于初始化寒亥。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = 'SAME')
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
第一層
接下來(lái)邮府,我們開(kāi)始實(shí)現(xiàn)第一層。它由一個(gè)卷積層接一個(gè) max_pooling 最大池化層完成溉奕。卷積在每個(gè) 5x5 的 patch 中算出 32 個(gè)特征褂傀。卷積的權(quán)重張量形狀是 [5, 5, 1, 32],前兩個(gè)維度是 patch 的大小加勤,接著是輸入的通道數(shù)目仙辟,最后是輸出的通道數(shù)目。而對(duì)于每一個(gè)輸出通道都有一個(gè)對(duì)應(yīng)的偏置量鳄梅。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
為了用這一層叠国,我們把 x 變成一個(gè) 4d 的向量,其第 2戴尸、第 3 維對(duì)應(yīng)圖片的寬度粟焊、高度,最后一位代表圖片的顏色通道(因?yàn)槭腔叶葓D,所以這里的通道數(shù)為 1项棠,如果是 RBG 彩色圖悲雳,則為 3)。
x_image = tf.reshape(x, [-1, 28, 28, 1])
之后香追,我們把 x_image 和權(quán)值向量進(jìn)行卷積合瓢,加上偏置項(xiàng),然后應(yīng)用 ReLU 激活函數(shù)透典,最后進(jìn)行 max pooling晴楔。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
第二層
為了構(gòu)建一個(gè)更深的網(wǎng)絡(luò),我們會(huì)把幾個(gè)類似的層堆疊起來(lái)掷匠。第二層中滥崩,每個(gè) 5x5 的 patch 會(huì)得到 64 個(gè)特征。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
密集連接層
現(xiàn)在讹语,圖片尺寸減小到 7x7钙皮,我們加入一個(gè)有 1024 個(gè)神經(jīng)元的全連接層,用于處理整個(gè)圖片顽决。我們把池化層輸出的張量 reshape 成一些向量短条,乘上權(quán)重矩陣,加上偏置才菠,然后對(duì)其使用 ReLU茸时。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
Dropout
為了減少過(guò)擬合,我們?cè)谳敵鰧又凹尤雂ropout赋访。我們用一個(gè) placeholder 來(lái)代表一個(gè)神經(jīng)元的輸出在 dropout 中保持不變的概率可都。這樣我們可以在訓(xùn)練過(guò)程中啟用 dropout,在測(cè)試過(guò)程中關(guān)閉 dropout蚓耽。 TensorFlow 的tf.nn.dropout 操作除了可以屏蔽神經(jīng)元的輸出外渠牲,還會(huì)自動(dòng)處理神經(jīng)元輸出值的 scale。所以用 dropout 的時(shí)候可以不用考慮 scale步悠。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
輸出層
最后我們添加一個(gè) softmax 層签杈,就像前面的單層 softmax regression 一樣。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
訓(xùn)練和評(píng)估模型
這個(gè)模型的效果如何呢鼎兽?
為了進(jìn)行訓(xùn)練和評(píng)估答姥,我們使用與之前簡(jiǎn)單的單層 SoftMax 神經(jīng)網(wǎng)絡(luò)模型幾乎相同的一套代碼,只是我們會(huì)用更加復(fù)雜的 ADAM 優(yōu)化器來(lái)做梯度最速下降谚咬,在 feed_dict 中加入額外的參數(shù) keep_prob 來(lái)控制 dropout 比例鹦付。然后每 100 次迭代輸出一次日志。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
