標(biāo)簽: JVM
1、什么是可回收對象(垃圾)年柠?
畫圖演示
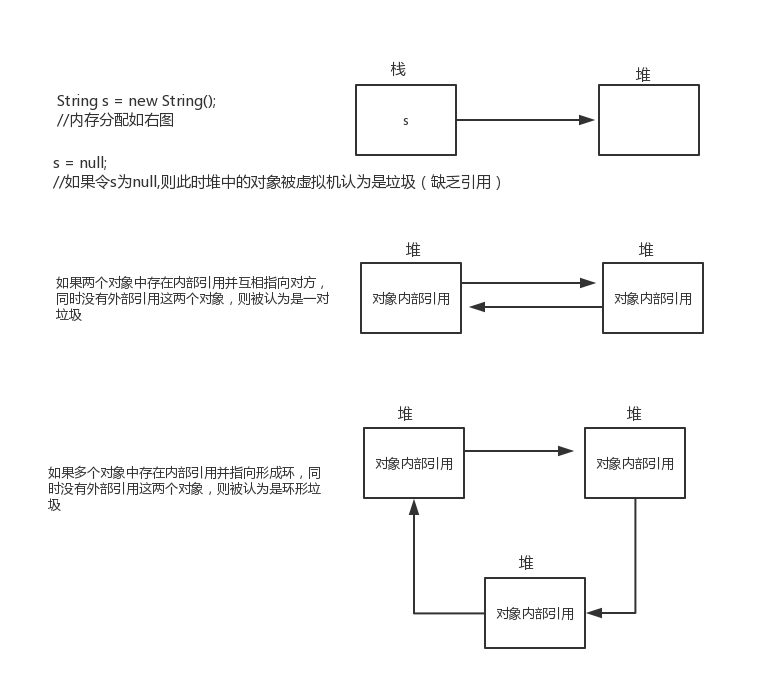
-
引用:
強(qiáng)引用:強(qiáng)引用指的是子啊程序代碼中普通存在的,類似Object obj = new Object()這類的引用,只要強(qiáng)引用還在溯壶,垃圾收集器則不會回收掉被引用的對象.
軟引用:軟引用用于描述一些還有用但并非必需的對象。對于軟引用關(guān)聯(lián)著的對象甫男,在系統(tǒng)將要發(fā)生內(nèi)存溢出異常之前茸塞,將會把這些對象列進(jìn)回收范圍之中進(jìn)行第二次回收,如果這次回收還沒有足夠的內(nèi)存查剖,才會拋出內(nèi)存溢出異常钾虐,在jdk1.2之后,提供了SoftReference類來實(shí)現(xiàn)軟引用.
弱引用:弱引用也是用于描述非必須對象笋庄,但是它的強(qiáng)度比軟引用更弱一些效扫,被弱引用關(guān)聯(lián)的對象只能生存到下一次垃圾收集發(fā)生之前。當(dāng)垃圾收集器工作時(shí)直砂,無論當(dāng)前內(nèi)存是否足夠菌仁,都會回收掉只被弱引用關(guān)聯(lián)的對象,在jdk1.2之后静暂,提供了WeakReference類來實(shí)現(xiàn)弱引用.
虛引用:也稱為幽靈引用济丘、幻影引用,是最弱的一種引用關(guān)系洽蛀,一個(gè)對象是否有虛引用的存在盗冷,不會對其生成時(shí)間構(gòu)成影響,無法通過虛引用來引用對象隅居。為一個(gè)對象設(shè)置虛引用的目的是能在這個(gè)對象被收集器回收時(shí)收到一個(gè)系統(tǒng)通知须揣,jdk1.2提供PhantomReference類來實(shí)現(xiàn)虛引用.
2、GC是如何確定垃圾的驮审?
- 引用計(jì)數(shù)法
算法思路:給對象添加一個(gè)引用計(jì)數(shù)器鲫寄,每當(dāng)有一個(gè)地方引用它時(shí),計(jì)數(shù)器值加1疯淫;當(dāng)引用失效時(shí)地来,計(jì)數(shù)器值減1;任何時(shí)刻計(jì)數(shù)器為0的對象則是不可用的熙掺。
引用計(jì)數(shù)算法(Reference Counting)的實(shí)現(xiàn)簡單未斑,判定效率也很高,但是無法解決循環(huán)引用問題
- 可達(dá)性分析
從roots對象計(jì)算可以達(dá)到的對象
-
可作為GC Roots的對象包括:
- 虛擬機(jī)棧(棧幀中的本地變量表)中引用的對象
- 方法區(qū)中類靜態(tài)屬性引用的對象
- 方法區(qū)中常量引用的對象
- 本地方法棧中JNI引用的對象
算法思路:以GC Roots 對象為起始點(diǎn)适掰,從這些節(jié)點(diǎn)開始向下搜索(深度搜索)颂碧,搜索所走過的路勁成為引用鏈(Reference Chain)荠列,當(dāng)一個(gè)對象到GCRoots不存在引用鏈(不可達(dá))時(shí),則證明此對象是不可用载城,即判定為可回收對象肌似。邏輯圖如下:
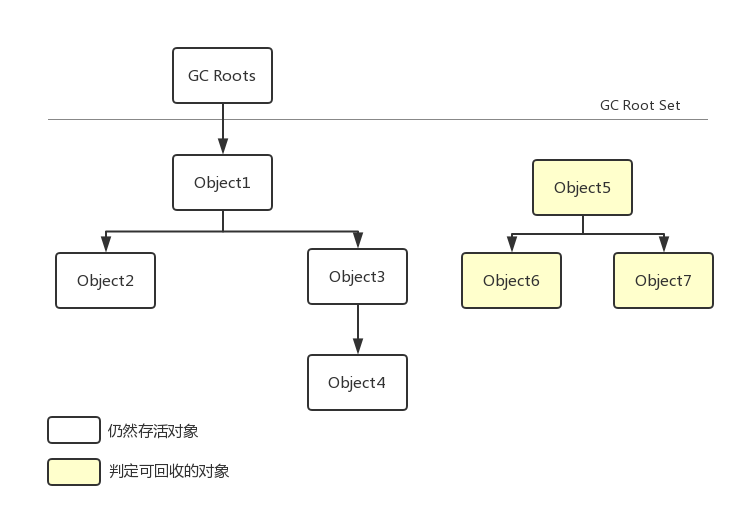
一種可能的物理內(nèi)存圖:
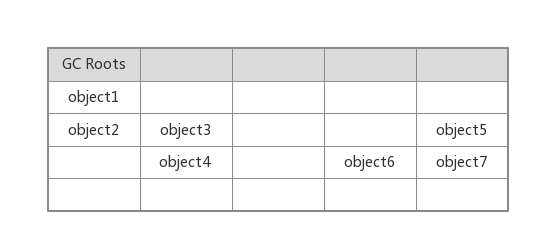
3、GC算法
- Mark-Sweep標(biāo)記清除:
算法分為標(biāo)記和清除兩個(gè)階段:首先標(biāo)記出所有需要回收的對象诉瓦,在標(biāo)記完成后統(tǒng)一回收所有被標(biāo)記的對象川队,標(biāo)記過程通過可達(dá)性分析,將不可達(dá)的對象進(jìn)行標(biāo)記判定睬澡。
-
不足之處:
- 效率問題固额,標(biāo)記和清除兩個(gè)過程效率都不高
- 空間問題,標(biāo)記清除之后會產(chǎn)生大量不連續(xù)的內(nèi)存碎片煞聪,空間碎片太多可能會導(dǎo)致后續(xù)需要分配較大內(nèi)存的對象時(shí)斗躏,無法找到足夠的連續(xù)內(nèi)存,而不得不提前觸發(fā)一次FGC
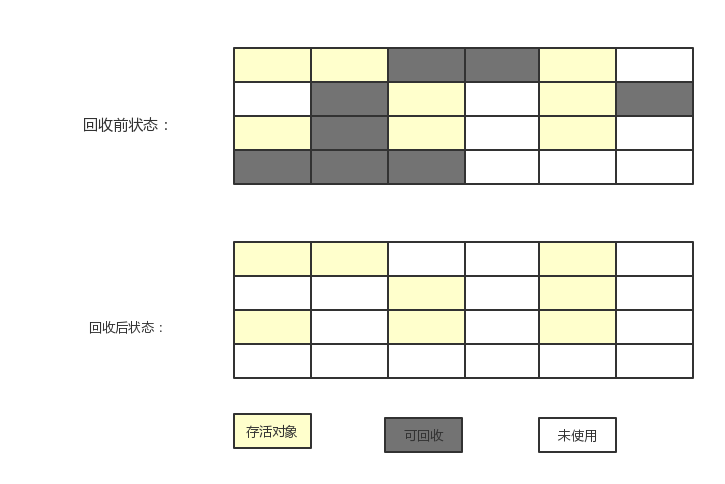 標(biāo)記清除
標(biāo)記清除
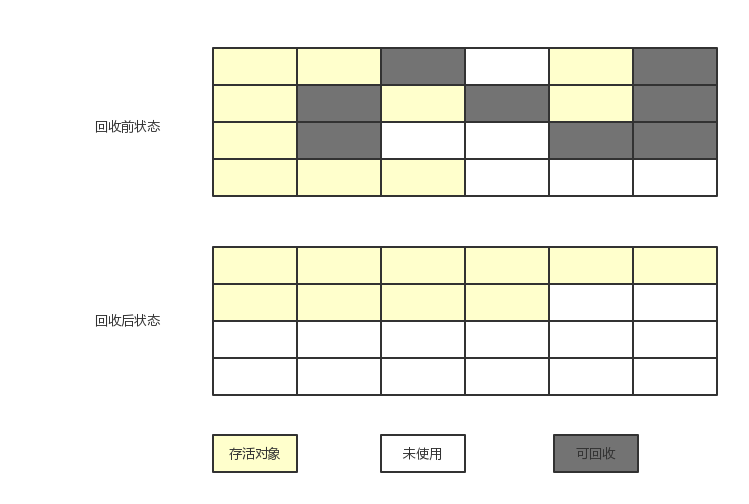
- Copying復(fù)制:
將內(nèi)存按容量劃分為大小相等的兩塊昔脯,每次只使用其中的一塊啄糙,當(dāng)這一塊的內(nèi)存用完了,就將還存活著的對象復(fù)制到另外一塊上面云稚,然后再把使用過的內(nèi)存空間一次清理掉隧饼。常用于新生代 survivor區(qū)的from/to的復(fù)制
優(yōu)點(diǎn):在內(nèi)存上進(jìn)行復(fù)制效率高,不存在內(nèi)存碎片化問題
-
缺點(diǎn):內(nèi)存空間利用率低静陈,算法代價(jià)高燕雁,因此實(shí)際分給新生代中的survivor區(qū)內(nèi)存較小,與Eden區(qū)比例約為8:1:1
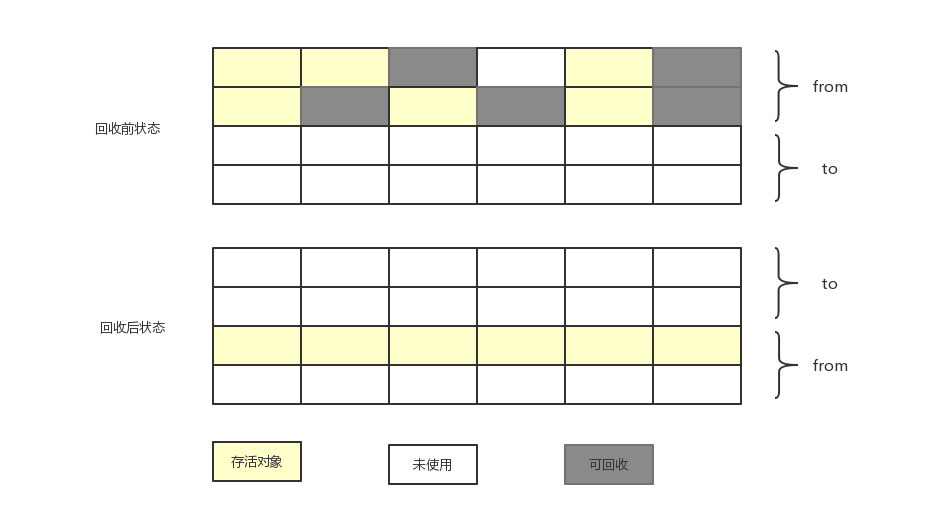 復(fù)制算法
復(fù)制算法
- Mark-Compact標(biāo)記壓縮:
標(biāo)記過程仍然與標(biāo)記-清除算法一樣鲸拥,采用可達(dá)性分析標(biāo)記判定拐格,然后讓所有存活對象都向一端移動,然后直接清理掉端邊界以外的內(nèi)存崩泡。
該算法效率略低于復(fù)制算法禁荒,但內(nèi)存空間利用率高猬膨,常用于老年代GC
-
分代收集算法:當(dāng)前商業(yè)虛擬機(jī)的垃圾收集都采用分代收集(GenerationalCollection)算法,角撞,該算法根據(jù)對象存活周期的不同將堆內(nèi)存劃分為幾塊:新生代、老年代勃痴,然后根據(jù)各個(gè)年代的特點(diǎn)采用最適當(dāng)?shù)腉C算法:
在新生代中谒所,每次GC時(shí)都發(fā)現(xiàn)有大量對象死去,只有少量存活沛申,則選用復(fù)制算法劣领,只需要付出少量存活對象的復(fù)制成本即可完成GC
在老年代中,對象存活率高铁材、尖淘,沒有額外空間對它進(jìn)行分配擔(dān)保奕锌,則需要使用標(biāo)記-清除算法或者標(biāo)記-壓縮算法(默認(rèn)使用)進(jìn)行GC
4、垃圾收集器:翻譯自官方文檔
- 串行收集器 Serial Collector:
串行收集器使用單個(gè)線程執(zhí)行所有垃圾收集工作村生,這使得它相對高效惊暴,因?yàn)榫€程之間沒有通信開銷。它最適合于單處理器機(jī)器趁桃,因?yàn)樗荒芾枚嗵幚砥饔布苫埃M管對于具有小數(shù)據(jù)集(高達(dá)大約100 MB)的應(yīng)用程序,它可能對多處理器很有用卫病。串行收集器在某些硬件和操作系統(tǒng)配置中默認(rèn)選中油啤,或者可以使用該選項(xiàng)明確啟用-XX:+UseSerialGC。
XX:+UseSerialGC
單線程
- 并行收集器 Paraller Collector:
官方文檔(翻譯):并行收集器(也稱為吞吐量收集器)并行執(zhí)行次要收集蟀苛,這可以顯著減少垃圾收集開銷益咬。它適用于在多處理器或多線程硬件上運(yùn)行的中型到大型數(shù)據(jù)集的應(yīng)用程序。并行收集器在某些硬件和操作系統(tǒng)配置上默認(rèn)選中帜平,或者可以使用該選項(xiàng)明確啟用-XX:+UseParallelGC础废。
并行壓縮是一個(gè)使并行采集器能夠并行執(zhí)行主要采集的功能。如果沒有并行壓縮罕模,主要集合將使用單個(gè)線程執(zhí)行评腺,這可能會極大地限制可伸縮性。如果-XX:+UseParallelGC指定了選項(xiàng)淑掌,則默認(rèn)啟用并行壓縮蒿讥。關(guān)閉它的選項(xiàng)是-XX:-UseParallelOldGC。
并發(fā)量大抛腕,每次GC時(shí)芋绸,JVM需要停頓
- 并發(fā)收集器
-
CMS Collector: 此收集器適用于希望縮短垃圾收集暫停時(shí)間并能夠與垃圾收集共享處理器資源的應(yīng)用程序。
- 停頓時(shí)間短
-
G1: 這種服務(wù)器式垃圾收集器適用于內(nèi)存較大的多處理器機(jī)器担敌。它以高概率滿足垃圾收集暫停時(shí)間目標(biāo)摔敛,同時(shí)實(shí)現(xiàn)高吞吐量。
- 停頓短全封,同時(shí)并發(fā)大
- 停頓短全封,同時(shí)并發(fā)大
-
- 并發(fā)開銷:
大多數(shù)并發(fā)收集器交換處理器資源(否則可用于應(yīng)用程序)以縮短主要收集暫停時(shí)間马昙。最明顯的開銷是在收集的并發(fā)部分期間使用一個(gè)或多個(gè)處理器。在N處理器系統(tǒng)上刹悴,并發(fā)部分集合將使用可用處理器的K / N行楞,其中1 <= K <= ceiling { N / 4}。(注意K上的精確選擇和邊界)除了在并行階段使用處理器之外土匀,還會產(chǎn)生額外的開銷以實(shí)現(xiàn)并發(fā)子房。因此,雖然垃圾收集暫停通常比并發(fā)收集器短得多,但應(yīng)用程序吞吐量也往往略低于其他收集器证杭。
在具有多個(gè)處理核心的計(jì)算機(jī)上田度,處理器可用于集合并發(fā)部分中的應(yīng)用程序線程,因此并發(fā)垃圾收集器線程不會“暫徒夥撸”應(yīng)用程序每币。這通常會導(dǎo)致更短的暫停,但是應(yīng)用程序可用的處理器資源也較少琢歇,應(yīng)該會出現(xiàn)一些減速兰怠,特別是在應(yīng)用程序最大限度地使用所有處理內(nèi)核的情況下。隨著N的增加李茫,由于并發(fā)垃圾收集導(dǎo)致的處理器資源減少變得更小揭保,同時(shí)收集的收益也增加。的部分并行模故障在并發(fā)標(biāo)記掃描(CMS)集電極討論了這樣的縮放潛在限制魄宏。
由于至少有一個(gè)處理器用于并發(fā)階段的垃圾收集秸侣,因此并發(fā)收集器通常不會為單處理器(單核)機(jī)器提供任何好處。但是宠互,對于CMS(不是G1)味榛,可以使用單獨(dú)的模式,可以在只有一個(gè)或兩個(gè)處理器的系統(tǒng)上實(shí)現(xiàn)低暫停; 看到增量模式在并發(fā)標(biāo)記掃描(CMS)收集器的詳細(xì)信息予跌。此功能在Java SE 8中不推薦使用搏色,并可能在以后的主要版本中刪除。
- 選擇收集器:除非應(yīng)用程序具有相當(dāng)嚴(yán)格的暫停時(shí)間要求券册,否則請先運(yùn)行您的應(yīng)用程序并允許VM選擇收集器频轿。如有必要,請調(diào)整堆大小以提高性能烁焙。如果性能仍不能達(dá)到您的目標(biāo)航邢,請使用以下指南作為選擇收集器的起點(diǎn)。
如果應(yīng)用程序有一個(gè)小數(shù)據(jù)集(最多大約100MB)骄蝇,那么用選項(xiàng)選擇串行收集器-XX:+UseSerialGC膳殷。
如果應(yīng)用程序?qū)⒃趩蝹€(gè)處理器上運(yùn)行,并且沒有暫停時(shí)間要求九火,則讓VM選擇收集器赚窃,或者使用該選項(xiàng)選擇串行收集器-XX:+UseSerialGC。
如果(a)峰值應(yīng)用程序性能是第一優(yōu)先級并且(b)沒有暫停時(shí)間要求或暫停1秒或更長時(shí)間是可接受的吃既,則讓VM選擇收集器考榨,或者選擇并行收集器-XX:+UseParallelGC。
如果響應(yīng)時(shí)間比整體吞吐量更重要鹦倚,并且垃圾收集暫停時(shí)間必須短于大約1秒,那么使用-XX:+UseConcMarkSweepGC或選擇并發(fā)收集器-XX:+UseG1GC冀惭。
如果推薦的收集器無法達(dá)到所需的性能震叙,請首先嘗試調(diào)整堆和代的大小以達(dá)到所需的目標(biāo)掀鹅。如果性能仍然不足,請嘗試使用其他收集器:使用并發(fā)收集器來減少暫停時(shí)間媒楼,并使用并行收集器來提高多處理器硬件的整體吞吐量乐尊。
參考資料:
1.《深入理解Java虛擬機(jī)》
2.官方文檔
