Hadoop2.X后可以劃分為三部分:HDFS、MapReduce和Yarn认臊,本篇主要看一下HDFS。
架構(gòu)圖
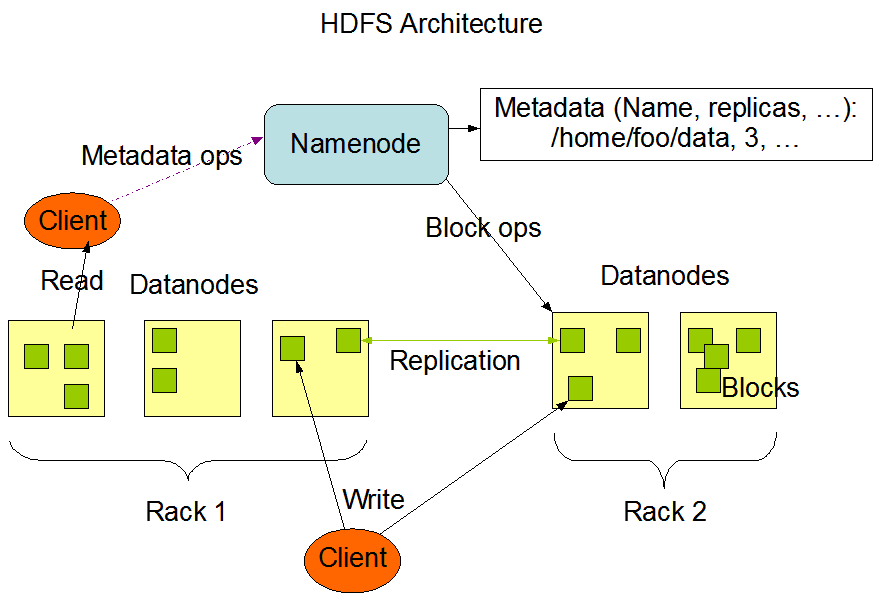
進程及作用
當(dāng)我們在安裝Hadoop的機器上執(zhí)行jps命令,我們會看到如下三個進程:NameNode坦刀、Secondary NameNode和DataNode。接下來了解一下這個三個進程的作用绑警。
-
NameNode
管理者文件系統(tǒng)的Namespace求泰。它維護著文件系統(tǒng)樹(filesystem tree)以及文件樹中所有的文件和文件夾的元數(shù)據(jù)(metadata)。管理這些信息的文件有兩個计盒,分別是Namespace 鏡像文件(Namespace image)和操作日志文件(edit log)渴频,這些信息被Cache在RAM中,當(dāng)然北启,這兩個文件也會被持久化存儲在本地硬盤卜朗。Namenode記錄著每個文件中各個塊所在的數(shù)據(jù)節(jié)點的位置信息,但是他并不持久化存儲這些信息咕村,因為這些信息會在系統(tǒng)啟動時從數(shù)據(jù)節(jié)點重建场钉。
-
Secondary NameNode
監(jiān)控HDFS狀態(tài)的輔助后臺程序。就想NameNode一樣懈涛,每個集群都有一個SecondaryNameNode逛万,并且部署在一個單獨的服務(wù)器上。Secondary NameNode不同于NameNode批钠,它不接受或者記錄任何實時的數(shù)據(jù)變化宇植,但是得封,它會與NameNode進行通信,以便定期地保存HDFS元數(shù)據(jù)的快照指郁。由于NameNode是單點的忙上,通過Secondary NameNode的快照功能,可以將NameNode的宕機時間和數(shù)據(jù)損失降低到最小闲坎。同時疫粥,如果NameNode發(fā)生問題,Secondary NameNode可以及時地作為備用NameNode使用腰懂。
合并時機 core-site.xml配置項 fs.checkpoint.period表示多長時間記錄一次hdfs的鏡像 fs.checkpoint.size表示一次記錄多大的size梗逮,默認64M 當(dāng)?shù)胶喜r間時合并,如果沒到合并時間記錄size到達64M則合并 -
Datanode
Datanode是文件系統(tǒng)的工作節(jié)點悯恍,他們根據(jù)客戶端或者是NameNode的調(diào)度存儲和檢索數(shù)據(jù)库糠,并且定期向NameNode發(fā)送他們所存儲的塊(block)的列表。
Block的放置策略 第一個副本:放置在上傳文件的DataNode 如果是集群外提交的,則隨機挑選一臺涮毫,磁盤不太滿瞬欧,cpu不太忙的節(jié)點 第二個副本:放置在于第一個副本不同的機架節(jié)點 第三個副本:與第二個副本相同的機架的節(jié)點上 更多副本:隨機節(jié)點
讀寫文件
寫入文件

初始化FileSystem,客戶端調(diào)用create()來創(chuàng)建文件
FileSystem用RPC調(diào)用元數(shù)據(jù)節(jié)點罢防,在文件系統(tǒng)的命名空間中創(chuàng)建一個新的文件艘虎,元數(shù)據(jù)節(jié)點首先確定文件原來不存在,并且客戶端有創(chuàng)建文件的權(quán)限咒吐,然后創(chuàng)建新文件野建。
FileSystem返回DFSOutputStream,客戶端用于寫數(shù)據(jù)恬叹,客戶端開始寫入數(shù)據(jù)候生。
DFSOutputStream將數(shù)據(jù)分成塊,寫入data queue绽昼。data queue由Data Streamer讀取唯鸭,并通知元數(shù)據(jù)節(jié)點分配數(shù)據(jù)節(jié)點,用來存儲數(shù)據(jù)塊(每塊默認復(fù)制3塊)硅确。分配的數(shù)據(jù)節(jié)點放在一個pipeline里目溉。Data Streamer將數(shù)據(jù)塊寫入pipeline中的第一個數(shù)據(jù)節(jié)點。第一個數(shù)據(jù)節(jié)點將數(shù)據(jù)塊發(fā)送給第二個數(shù)據(jù)節(jié)點菱农。第二個數(shù)據(jù)節(jié)點將數(shù)據(jù)發(fā)送給第三個數(shù)據(jù)節(jié)點缭付。
DFSOutputStream為發(fā)出去的數(shù)據(jù)塊保存了ack queue,等待pipeline中的數(shù)據(jù)節(jié)點告知數(shù)據(jù)已經(jīng)寫入成功循未。
當(dāng)客戶端結(jié)束寫入數(shù)據(jù)陷猫,則調(diào)用stream的close函數(shù)。此操作將所有的數(shù)據(jù)塊寫入pipeline中的數(shù)據(jù)節(jié)點,并等待ack queue返回成功绣檬。最后通知元數(shù)據(jù)節(jié)點寫入完畢舅巷。
如果數(shù)據(jù)節(jié)點在寫入的過程中失敗,關(guān)閉pipeline河咽,將ack queue中的數(shù)據(jù)塊放入data queue的開始,當(dāng)前的數(shù)據(jù)塊在已經(jīng)寫入的數(shù)據(jù)節(jié)點中被元數(shù)據(jù)節(jié)點賦予新的標示赋元,則錯誤節(jié)點重啟后能夠察覺其數(shù)據(jù)塊是過時的忘蟹,會被刪除。失敗的數(shù)據(jù)節(jié)點從pipeline中移除搁凸,另外的數(shù)據(jù)塊則寫入pipeline中的另外兩個數(shù)據(jù)節(jié)點媚值。元數(shù)據(jù)節(jié)點則被通知此數(shù)據(jù)塊是復(fù)制塊數(shù)不足,將來會再創(chuàng)建第三份備份护糖。
讀取文件

初始化FileSystem褥芒,然后客戶端(client)用FileSystem的open()函數(shù)打開文件
FileSystem用RPC調(diào)用元數(shù)據(jù)節(jié)點,得到文件的數(shù)據(jù)塊信息嫡良,對于每一個數(shù)據(jù)塊锰扶,元數(shù)據(jù)節(jié)點返回保存數(shù)據(jù)塊的數(shù)據(jù)節(jié)點的地址。
FileSystem返回FSDataInputStream給客戶端寝受,用來讀取數(shù)據(jù)坷牛,客戶端調(diào)用stream的read()函數(shù)開始讀取數(shù)據(jù)。
DFSInputStream連接保存此文件第一個數(shù)據(jù)塊的最近的數(shù)據(jù)節(jié)點很澄,data從數(shù)據(jù)節(jié)點讀到客戶端(client)
當(dāng)此數(shù)據(jù)塊讀取完畢時京闰,DFSInputStream關(guān)閉和此數(shù)據(jù)節(jié)點的連接,然后連接此文件下一個數(shù)據(jù)塊的最近的數(shù)據(jù)節(jié)點甩苛。
當(dāng)客戶端讀取完畢數(shù)據(jù)的時候蹂楣,調(diào)用FSDataInputStream的close函數(shù)。
在讀取數(shù)據(jù)的過程中讯蒲,如果客戶端在與數(shù)據(jù)節(jié)點通信出現(xiàn)錯誤痊土,則嘗試連接包含此數(shù)據(jù)塊的下一個數(shù)據(jù)節(jié)點。
失敗的數(shù)據(jù)節(jié)點將被記錄爱葵,以后不再連接施戴。
SecondNamenode合并流程

在namenode上的edits文件和fsimage進行合并:
Secondary NameNode請求NameNode進行edit log的滾動(即創(chuàng)建一個新的edit log),將新的編輯操作記錄到新生成的edit log文件萌丈;
通過http get方式赞哗,讀取NameNode上的fsimage和edits文件,到Secondary NameNode上辆雾;
讀取fsimage到內(nèi)存中肪笋,即加載fsimage到內(nèi)存,然后執(zhí)行edits中所有操作(類似OracleDG,應(yīng)用redo log)藤乙,并生成一個新的fsimage文件猜揪,即這個檢查點被創(chuàng)建;
通過http post方式坛梁,將新的fsimage文件傳送到NameNode而姐;
NameNode使用新的fsimage替換原來的fsimage文件,讓(1)創(chuàng)建的edits替代原來的edits文件划咐;并且更新fsimage文件的檢查點時間拴念。
整個處理過程完成。
Secondary NameNode的處理褐缠,是將fsimage和edites文件周期的合并政鼠,不會造成nameNode重啟時造成長時間不可訪問的情況。
