用了一段時(shí)間的pyspider衷佃,一直沒有研究源碼审姓。這兩天抽空看了看欺缘,稍微拿幾個(gè)點(diǎn)出來研究一下识虚,如果讀到哪里不對的地方容劳,請及時(shí)指出我好糾正蓬戚,本文我也會在今后實(shí)際使用過程中不斷修正蚯斯。
本文會有錯(cuò)誤此再!寫本文的目的是我希望一邊寫文章何乎,一邊看源碼句惯。所以并不是看完源碼之后的總結(jié),請謹(jǐn)慎閱讀支救。
主要參考文章:
導(dǎo)航欄:
[TOC]
目錄結(jié)構(gòu)
1. database
2. fetcher
3. libs
4. message_queue
5. processor
6. result
7. scheduler
8. webui
結(jié)構(gòu)分析
PySpider主要由scheduler抢野,fetcher各墨,processor三大組件指孤,webui提供前端頁面,database和result提供持久層(數(shù)據(jù)層)贬堵,lib常用工具類叉跛,message_queue消息傳遞層筷厘。
三大數(shù)據(jù)庫表
projectdb: project項(xiàng)目管理摊溶,管理該項(xiàng)目的代碼,狀態(tài)赫冬,速率浓镜,上一次的更新時(shí)間等基礎(chǔ)信息。
taskdb: 組件中互相傳遞信息的json劲厌,封裝了所有需要傳遞給各個(gè)組件進(jìn)行使用和調(diào)用的數(shù)據(jù)膛薛,用戶的整個(gè)爬蟲都會被翻譯成一系列的task,在組件中進(jìn)行傳遞补鼻,最后獲得結(jié)果哄啄。
resultdb: 如果將數(shù)據(jù)存在本地?cái)?shù)據(jù)庫,則一般以resultdb存儲
總體結(jié)構(gòu)
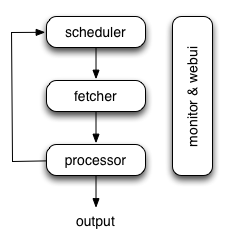
- 各個(gè)組件間使用消息隊(duì)列連接风范,除了scheduler是單點(diǎn)組件咨跌,fetcher和processor都可以是多實(shí)例分布式部署的。scheduler負(fù)責(zé)整體的調(diào)度控制
- 任務(wù)由scheduler發(fā)起調(diào)度硼婿,fetcher抓取網(wǎng)頁內(nèi)容锌半,processor執(zhí)行預(yù)先編寫(webui端)的python腳本,輸出結(jié)果或產(chǎn)生新的提煉任務(wù)(發(fā)往scheduler)寇漫,行程閉環(huán)
- 每個(gè)腳本可以靈活使用各種python庫對頁面進(jìn)行解析刊殉,使用框架API控制下一步抓取動(dòng)作,通過設(shè)置回調(diào)控制解析動(dòng)作
三大組件介紹
scheduler
按照binux的介紹該組件有以下特點(diǎn):
- 任務(wù)優(yōu)先級
- 周期定時(shí)任務(wù)
- 流量控制
- 基于時(shí)間周期或前鏈標(biāo)簽(如更新時(shí)間)的重抓取調(diào)度
那么從源碼的角度來看可以歸為下面7個(gè)方法州胳,由scheduler.py中的Scheduler類的run()方法進(jìn)入run_once(),可看到下面7個(gè)方法:
def run_once(self):
'''comsume queues and feed tasks to fetcher, once'''
self._update_projects()
self._check_task_done()
self._check_request()
while self._check_cronjob():
pass
self._check_select()
self._check_delete()
self._try_dump_cnt()
這7個(gè)方法我還沒完全過掉记焊,先說我覺得正確的幾個(gè),希望之后您也可以幫我補(bǔ)充一下:
- [x] _update_projects() : 從projectdb中檢查project栓撞,是否有過期遍膜,需不需要重爬
- [x] _check_task_done() : 從消息隊(duì)列中取出消息(task)
- [ ] _check_request() :
- [ ] _check_cronjob() :
- [ ] _check_select() :
- [x] _check_delete() : 檢查是否有需要?jiǎng)h除的project,pyspider默認(rèn)Status為STOP瓤湘,且24小時(shí)之后自行刪除
- [ ] _try_dump_cnt() :
fetcher
按照binux的介紹該組件有以下特點(diǎn):
- dataurl支持瓢颅,用于假抓取模擬傳遞
- method, header, cookies, proxy, etag, last_modified, timeout等等抓取調(diào)度控制
- 可以通過適配
類似phantomjs的webkit引擎支持渲染
fetcher中主要看 tornado_fetcher.py 和 phantomjs_fetcher.js 兩個(gè)文件。
tornado_fetcher.py
-
HTTP請求
看名字就知道該.py文件和tornado有所關(guān)系岭粤,點(diǎn)開可以看到tornado_fetcher.py繼承了tornado的兩個(gè)類:
class MyCurlAsyncHTTPClient(CurlAsyncHTTPClient):
def free_size(self):
return len(self._free_list)
def size(self):
return len(self._curls) - self.free_size()
class MySimpleAsyncHTTPClient(SimpleAsyncHTTPClient):
def free_size(self):
return self.max_clients - self.size()
def size(self):
return len(self.active)
查看 tornado.httpclient - 異步HTTP客戶端 文檔后惜索,很清楚的看到pyspider異步特性就是借助了tornado里的httpclient客戶端。
class Fetcher(object):
還從以Fetcher類中的run方法為入口看剃浇,發(fā)現(xiàn)會不斷從inqueue隊(duì)列中取task巾兆,進(jìn)行fetch猎物;
fetch默認(rèn)為異步,那么抓取的核心方法就是async_fetch(self, task, callback=None)角塑;
fetch幾點(diǎn)步驟和內(nèi)容蔫磨,還沒弄懂的內(nèi)容我沒打勾:
- [x] 從task中獲得url
- [x] callback默認(rèn)為None
- [x] fetch判斷是否使用異步(默認(rèn)全部使用)
- [x] 判斷url類型,其實(shí)就是判斷是否使用phantomjs(ps:這邊的startwith=data沒懂)判斷是否是js, splash圃伶。若都不是堤如,則為普通的HTTP請求
- [x] http_fetch可以看到就是處理cookie,重定向,robots.txt等一系列的方法
- [ ] 獲得result結(jié)果后,最后寫了一句raise gen.Return(result) 引發(fā)的異常退出(這塊沒懂)窒朋,只看到tornado.gen模塊是一個(gè)基于python generator實(shí)現(xiàn)的異步編程接口
phantomjs_fetcher.js
先附上phantomjs WebServer部分的官方文檔
- [x] 使用WebServer方式搀罢,監(jiān)聽端口(默認(rèn)為127.0.0.1:9999)
- [x] 使用POST方式(拒絕GET)提交給Phantomjs監(jiān)聽的端口
webPage是PhantomJS的核心模塊,可以通過下面方式獲得一個(gè)webPage模塊的實(shí)例:
var webPage = require('webpage')
var page = webPage.create()
再介紹phantomjs_fetcher.js中幾個(gè)核心的方法:
- [x] onLoadFinished : 監(jiān)聽頁面是否加載完成
- [x] onResourceRequested : 當(dāng)頁面去請求一個(gè)資源時(shí)侥猩,會觸發(fā)onResourceRequested()方法的回調(diào)函數(shù)榔至。回調(diào)函數(shù)接受兩個(gè)參數(shù)欺劳,第一個(gè)參數(shù)requestData是這個(gè)HTTP請求的元數(shù)據(jù)對象唧取,包括以下屬性:
* id: 所請求資源的id號,這個(gè)應(yīng)該是phantomjs給標(biāo)識的
* method: 所使用的HTTP方法(GET/POST/PUT/DELETE等)
* url: 所請求資源的URL
* time: 包含請求該資源時(shí)間的一個(gè)Date對象划提。
* headers: 該請求的http請求頭中的信息數(shù)組枫弟。
- [x] onResourceReceived : onResourceReceived屬性用于指定一個(gè)回調(diào)函數(shù),當(dāng)網(wǎng)頁收到所請求的資源時(shí)鹏往,就會執(zhí)行該回調(diào)函數(shù)淡诗。回調(diào)函數(shù)只有一個(gè)參數(shù)掸犬,就是所請求資源的服務(wù)器發(fā)來的HTTP response的元數(shù)據(jù)對象袜漩,包括以下字段:
* id: 所請求的資源編號绪爸,此編號phantomjs標(biāo)識湾碎。
* url: 所請求的資源的URL
* time: 包含HTTP回應(yīng)時(shí)間的Date對象
* headers: 響應(yīng)的HTTP頭信息數(shù)組
* bodySize: 解壓縮后的收到的內(nèi)容大小
* contentType: 接到的內(nèi)容種類
* redirectURL: 重定向URL(如果有的話)
* stage: 對于多數(shù)據(jù)塊的HTTP回應(yīng),頭一個(gè)數(shù)據(jù)塊為start奠货,最后一個(gè)數(shù)據(jù)塊為end
* status: HTTP狀態(tài)碼介褥,成功時(shí)為200
* statusText: HTTP狀態(tài)信息,比如OK
最后通過調(diào)用page.open發(fā)送請求給Phantomjs
通過make_result方法返回response
processor
按照binux的介紹該組件有以下特點(diǎn):
- 內(nèi)置的PyQuery递惋,以jQuery解析頁面
- 在腳本中完全控制調(diào)度抓取的各項(xiàng)參數(shù)
- 可以向后鏈傳遞信息
- 異常捕獲
我還沒具體看柔滔,簡單的看了一眼先得出以下結(jié)論:
- [x] 去取來自fetcher的task,調(diào)用task中process變量的callback函數(shù)(python腳本萍虽,存在projectdb中)
- [x] 將合適的數(shù)據(jù)輸出到result
- [x] 有其他后續(xù)任務(wù)則重新放入消息隊(duì)列并返回到scheduler中睛廊。
其他組件
webui
前端頁面是用Flask框架搭建的Web頁面,具有以下功能:
- web 的可視化任務(wù)監(jiān)控
- web 腳本編寫杉编,單步調(diào)試
- 異常捕獲超全、log捕獲咆霜、print捕獲等
message_queues
因?yàn)闀簳r(shí)就用到了Redis,所以介紹一下源碼中用到的Redis方法嘶朱,其他的可見Redi官方文檔
- [x] loop key : 移除并返回列表key的頭元素
- [x] rpush key value : 將一個(gè)或多個(gè)value值插入到表key的表尾
- [x] llen key : 返回列表key的長度
