之前介紹過Apache Spark的基本概念以及環(huán)境準(zhǔn)備胧沫,本篇以分類算法為入口疑苔,主要熟悉下Spark的Python API规丽,重點(diǎn)不在算法份企,而是API的熟悉也榄,具體的分類算法會(huì)給出相應(yīng)的Wiki鏈接,感興趣的可以一起交流下司志。
分類模型種類
我們將討論Spark中常見的三種分類模型:線性模型甜紫、決策樹和樸素貝葉斯模型。線性模型, 簡單而且相對容易擴(kuò)展到非常大的數(shù)據(jù)集;決策樹是一個(gè)強(qiáng)大的非線性技術(shù),訓(xùn)練過程計(jì)算量大 并且較難擴(kuò)展(幸運(yùn)的是,MLlib會(huì)替我們考慮擴(kuò)展性的問題),但是在很多情況下性能很好;樸 素貝葉斯模型簡單骂远、易訓(xùn)練,并且具有高效和并行的優(yōu)點(diǎn)(實(shí)際中,模型訓(xùn)練只需要遍歷所有數(shù) 據(jù)集一次)囚霸。而且,樸素 貝葉斯模型可以作為一個(gè)很好的模型測試基準(zhǔn),用于比較其他模型的性能。
線性模型
線性模型的核心思想是對樣本的預(yù)測結(jié)果(通常稱為目標(biāo)或者因變量)進(jìn)行建模,即對輸入變量(特征或者自變量)應(yīng)用簡單的線性預(yù)測函數(shù)激才,具體

給定輸入數(shù)據(jù)的特征向量和相關(guān)的目標(biāo)值,存在一個(gè)權(quán)重向量能夠最好對數(shù)據(jù)進(jìn)行擬合,擬 合的過程即最小化模型輸出與實(shí)際值的誤差拓型。這個(gè)過程稱為模型的擬合、訓(xùn)練或者優(yōu)化瘸恼。本文主要關(guān)注的線性模型包括邏輯回歸和線性支持向量機(jī)劣挫。需要進(jìn)一步了解線性模型和損失函數(shù)的細(xì)節(jié),可參考[Spark二分類部分](http://spark.apache.org/docs/latest/mllib-linear- methods.html#binary-classification).
樸素貝葉斯模型
樸素貝葉斯是一個(gè)概率模型,通過計(jì)算給定數(shù)據(jù)點(diǎn)在某個(gè)類別的概率來進(jìn)行預(yù)測。樸素貝葉斯模型假定每個(gè)特征分配到某個(gè)類別的概率是獨(dú)立分布的(假定各個(gè)特征之間條件獨(dú)立)东帅。
基于這個(gè)假設(shè),屬于某個(gè)類別的概率表示為若干概率乘積的函數(shù),其中這些概率包括某個(gè)特 2 征在給定某個(gè)類別的條件下出現(xiàn)的概率(條件概率),以及該類別的概率(先驗(yàn)概率)压固。這樣使得 模型訓(xùn)練非常直接且易于處理。類別的先驗(yàn)概率和特征的條件概率可以通過數(shù)據(jù)的頻率估計(jì)得 到靠闭。分類過程就是在給定特征和類別概率的情況下選擇最可能的類別帐我。
另外還有一個(gè)關(guān)于特征分布的假設(shè),即參數(shù)的估計(jì)來自數(shù)據(jù)。MLlib實(shí)現(xiàn)了多項(xiàng)樸素貝葉斯 (multinomial nai?ve Bayes),其中假設(shè)特征分布是多項(xiàng)分布,用以表示特征的非負(fù)頻率統(tǒng)計(jì)阎毅。具體請參考Spark文檔中對應(yīng)的關(guān)于[樸素貝葉斯的介紹](http://spark.apache.org/do cs/latest/mllib-naive-bayes.html), 如果想了解模型的數(shù)學(xué)公司焚刚,可參考[維基百科](http://en.wi kipedia. org/wiki/Naive_Bayes_classifier)。
決策樹
決策樹是一個(gè)強(qiáng)大的非概率模型,它可以表達(dá)復(fù)雜的非線性模式和特征相互關(guān)系扇调。決策樹在 很多任務(wù)上表現(xiàn)出的性能很好,相對容易理解和解釋,可以處理類屬或者數(shù)值特征,同時(shí)不要求 輸入數(shù)據(jù)歸一化或者標(biāo)準(zhǔn)化矿咕。決策樹非常適合應(yīng)用集成方法(ensemble method),比如多個(gè)決策 樹的集成,稱為決策樹森林。
下圖截圖了其他博客的一張決策樹的圖,比如新來一個(gè)用戶:無房產(chǎn)碳柱,單身捡絮,年收入55K,那么根據(jù)上面的決策樹莲镣,可以預(yù)測他無法償還債務(wù)(藍(lán)色虛線路徑)福稳。
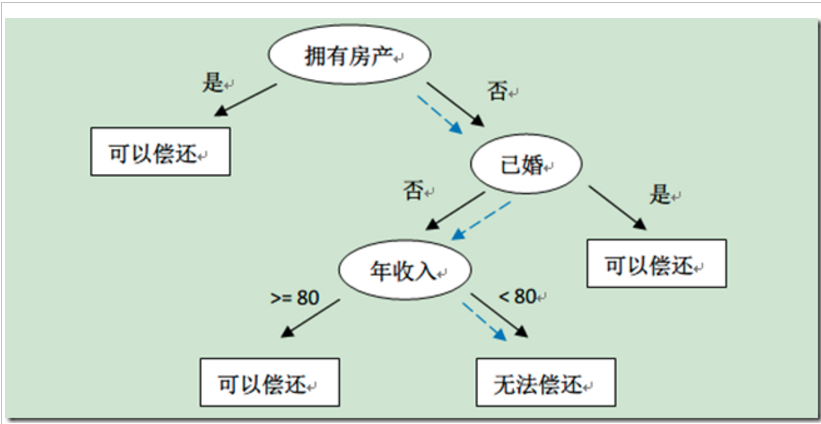
決策樹算法是一種自上而下始于根節(jié)點(diǎn)(或特征)的方法,在每一個(gè)步驟中通過評估特征分裂的信息增益,最后選出分割數(shù)據(jù)集最優(yōu)的特征。信息增益通過計(jì)算節(jié)點(diǎn)不純度(即節(jié)點(diǎn)標(biāo)簽不相似或不同質(zhì)的程度)減去分割后的兩個(gè)子節(jié)點(diǎn)不純度的加權(quán)和瑞侮。對于分類任務(wù),這里有兩個(gè)評估方法用于選擇最好分割:基尼不純和熵的圆。要進(jìn)一步了解決策樹算法和不純度估計(jì),請參考[Spark官方文檔](http://spark.apache.org/docs/latest/mllib-decision-
tree.html)
分類模型實(shí)例
上面講了關(guān)于分類的一些概念半火,都是點(diǎn)到為止越妈,本文的重點(diǎn)在于Spark的Python API熟悉,如想了解具體分類模型钮糖,還需要進(jìn)一步Google對應(yīng)的算法介紹梅掠,本文最后也會(huì)給出一些相關(guān)的鏈接。
接下來我們就按照做數(shù)據(jù)的一般流程來演示這個(gè)分類模型是如何構(gòu)建的店归,主要包括數(shù)據(jù)準(zhǔn)備(特征提取)阎抒、模型訓(xùn)練、模型使用消痛、模型評估以及模型改進(jìn)等且叁。
數(shù)據(jù)準(zhǔn)備
本文使用的數(shù)據(jù)集來自Kaggle比賽,由StumbleUpon提供肄满,比賽的問題涉及網(wǎng)頁中推薦的頁面是短暫(短暫 存在,很快就不流行了)還是長久(長時(shí)間流行)谴古。
開始之前,為了讓Spark更好地操作數(shù)據(jù),我們需要?jiǎng)h除文件第一行的列頭名稱。進(jìn)入數(shù)據(jù) 的目錄(這里用PATH表示),然后輸入如下命令刪除第一行并且通過管道保存到以 train_noheader.tsv命名的新文件中:
> sed 1d train.tsv > train_noheader.tsv
接下來稠歉,我們啟動(dòng)spark的python命令行工具掰担,命令如下,如果你熟悉Python怒炸,那你應(yīng)該對IPython不會(huì)陌生带饱,IPython是個(gè)非常有用的家伙,有興趣的可以了解下阅羹。
> IPYTHON=1 pyspark
首先我們來引入相關(guān)的依賴包勺疼,下面是本文需要的全部依賴包,主要都是分類模型相關(guān)的捏鱼。
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.classification import LogisticRegressionWithSGD
from pyspark.mllib.classification import SVMWithSGD
from pyspark.mllib.classification import NaiveBayes
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
from pyspark.mllib.evaluation import BinaryClassificationMetrics
from pyspark.mllib.regression import LabeledPoint
依賴包引入之后执庐,我們就可以使用對應(yīng)的API來讀入元數(shù)據(jù)了,通過觀察records.first()的輸出导梆,大概對數(shù)據(jù)有個(gè)大致的了解轨淌。開始四列分別包含URL迂烁、頁面的ID、 原始的文本內(nèi)容和分配給頁面的類別递鹉。接下來22列包含各種各樣的數(shù)值或者類屬特征盟步。最后一列 為目標(biāo)值,?1為長久,0為短暫。
data_path = "/Users/caolei/WorkSpace/hack-spark/data/evergreen"
records = sc.textFile(data_path + "/train-no-header.tsv").map(lambda line : line.split("\t"))
records.first()
我們將用簡單的方法直接對數(shù)值特征做處理躏结。因?yàn)槊總€(gè)類屬變量是二元的,對這些變量已有 一個(gè)用1-of-編碼的特征,于是不需要額外提取特征却盘。由于數(shù)據(jù)格式的問題,我們做一些數(shù)據(jù)清理的工作,在處理過程中把額外的(")去掉。數(shù) 據(jù)集中還有一些用"?"代替的缺失數(shù)據(jù),本例中,我們直接用0替換那些缺失數(shù)據(jù)媳拴,而且定義了抽取特征和標(biāo)簽的函數(shù)黄橘。
records_trimmed = records.map(lambda record : map(lambda field : field.replace("\"", ""), record))
records_trimmed.cache()
def replace_special_simbal(a):
if a == "?":
return 0.0
else:
return float(a)
def extract_label(record):
return record[len(record)-1]
def extract_features(record):
return map(lambda field : replace_special_simbal(field), record[4:len(record) -1 ])
在清理和處理缺失數(shù)據(jù)后,我們提取最后一列的標(biāo)記變量以及第5列到第25列的特征矩陣。 將標(biāo)簽變量轉(zhuǎn)換為Int值,特征向量轉(zhuǎn)換為Double數(shù)組禀挫。最后,我們將標(biāo)簽和和特征向量轉(zhuǎn)換為 LabeledPoint實(shí)例旬陡。
data = records_trimmed.map(lambda r : LabeledPoint(extract_label(r), extract_features(r))).filter(lambda record : record.features.array.size == 22)
data.cache()
模型訓(xùn)練
其實(shí)不管是數(shù)據(jù)挖掘還是機(jī)器學(xué)習(xí),或者更牛逼的AI语婴,個(gè)人理解,重點(diǎn)在數(shù)據(jù)驶睦,如果數(shù)據(jù)準(zhǔn)備和處理的得當(dāng)砰左,那模型和算法都是太大問題,下面是模型訓(xùn)練的代碼场航。
# 模型訓(xùn)練缠导,包括線性回歸,SVNM溉痢,決策樹和樸素貝葉斯
numIterations = 10
lrModel = LogisticRegressionWithSGD.train(data, numIterations)
svmModel = SVMWithSGD.train(data, numIterations)
maxTreeDepth = 5
dtModel = DecisionTree.trainClassifier(data, numClasses=2, categoricalFeaturesInfo={},impurity='gini', maxDepth=maxTreeDepth, maxBins=32)
# 樸素樸貝葉斯要求特征值非負(fù)
def deal_negative(a):
if a == "?" or float(a) < 0.0:
return 0.0
else:
return float(a)
def extract_no_negative_features(record):
return map(lambda field : deal_negative(field), record[4:len(record) -1 ])
data_for_bayes = records_trimmed.map(lambda r : LabeledPoint(extract_label(r), extract_no_negative_features(r))).filter(lambda record : record.features.array.size == 22)
bayesModel = NaiveBayes.train(data_for_bayes)
模型使用
模型訓(xùn)練出來之后僻造,應(yīng)該將模型用在測試數(shù)據(jù)上,簡單起見孩饼,我們直接將模型運(yùn)用在訓(xùn)練數(shù)據(jù)上髓削,還是那句話,重點(diǎn)在熟悉API镀娶,而不是算法和效果立膛。以邏輯回歸為例:
lrModel.predict(data.first().features) # 輸出1
data.first().label #輸出0
這個(gè)結(jié)果說明我們預(yù)測錯(cuò)了,你可以嘗試其他的數(shù)據(jù)點(diǎn)梯码,來看看模型訓(xùn)練的是否滿足要求宝泵,其中這塊主要是由模型評估來保證的。
模型評估
在使用模型做預(yù)測時(shí),如何知道預(yù)測到底好不好呢?換句話說,應(yīng)該知道怎么評估模型性能轩娶。 通常在二分類中使用的評估方法包括:預(yù)測正確率和錯(cuò)誤率儿奶、準(zhǔn)確率和召回率、準(zhǔn)確率?召回率曲線下方的面積鳄抒、ROC曲線闯捎、ROC曲線下的面積和F-Measure搅窿。
預(yù)測的正確率和錯(cuò)誤率
在二分類中,預(yù)測正確率可能是最簡單評測方式,正確率等于訓(xùn)練樣本中被正確分類的數(shù)目除以總樣本數(shù)。類似地,錯(cuò)誤率等于訓(xùn)練樣本中被錯(cuò)誤分類的樣本數(shù)目除以總樣本數(shù)隙券。我們通過對輸入特征進(jìn)行預(yù)測并將預(yù)測值與實(shí)際標(biāo)簽進(jìn)行比較,計(jì)算出模型在訓(xùn)練數(shù)據(jù)上的 正確率男应。將對正確分類的樣本數(shù)目求和并除以樣本總數(shù),得到平均分類正確率:
## 正確率和錯(cuò)誤率
lrTotalCorrect = data.map(lambda r : 1 if (lrModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
lrAccuracy = lrTotalCorrect / float(data.count()) # 0.5136044023234485
svmTotalCorrect = data.map(lambda r : 1 if (svmModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
svmAccuracy = svmTotalCorrect / float(data.count()) #0.5136044023234485
nbTotalCorrect = data_for_bayes.map(lambda r : 1 if (bayesModel.predict(r.features) == r.label) else 0).reduce(lambda x, y : x + y)
nbAccuracy = nbTotalCorrect / float(data_for_bayes.count()) #0.5799449709568939
dt_predictions = dtModel.predict(data.map(lambda x: x.features))
labelsAndPredictions = data.map(lambda x: x.label).zip(dt_predictions)
dtTotalCorrect = labelsAndPredictions.map(lambda r : 1 if (r[0] == r[1]) else 0).reduce(lambda x, y : x + y)
dtAccuracy = dtTotalCorrect / float(data.count()) #0.654234179150107
最后發(fā)現(xiàn),四個(gè)模型的準(zhǔn)確率都在50%到60% 左右娱仔,跟隨即差不多沐飘,這說明我們的模型訓(xùn)練的很不好。
準(zhǔn)確率和召回率
在信息檢索中,準(zhǔn)確率通常用于評價(jià)結(jié)果的質(zhì)量,而召回率用來評價(jià)結(jié)果的完整性牲迫。
在二分類問題中,準(zhǔn)確率定義為真陽性的數(shù)目除以真陽性和假陽性的總數(shù),其中真陽性是指 被正確預(yù)測的類別為1的樣本,假陽性是錯(cuò)誤預(yù)測為類別1的樣本耐朴。如果每個(gè)被分類器預(yù)測為類別 1的樣本確實(shí)屬于類別1,那準(zhǔn)確率達(dá)到100%。
召回率定義為真陽性的數(shù)目除以真陽性和假陰性的和,其中假陰性是類別為1卻被預(yù)測為0 的樣本盹憎。如果任何一個(gè)類型為1的樣本沒有被錯(cuò)誤預(yù)測為類別0(即沒有假陰性),那召回率達(dá)到 100%筛峭。
通常,準(zhǔn)確率和召回率是負(fù)相關(guān)的,高準(zhǔn)確率常常對應(yīng)低召回率,反之亦然。為了說明這點(diǎn), 假定我們訓(xùn)練了一個(gè)模型的預(yù)測輸出永遠(yuǎn)是類別1陪每。因?yàn)榭偸穷A(yù)測輸出類別1,所以模型預(yù)測結(jié)果 不會(huì)出現(xiàn)假陰性,這樣也不會(huì)錯(cuò)過任何類別1的樣本影晓。于是,得到模型的召回率是1.0。另一方面, 假陽性會(huì)非常高,意味著準(zhǔn)確率非常低(這依賴各個(gè)類別在數(shù)據(jù)集中確切的分布情況)檩禾。
準(zhǔn)確率和召回率在單獨(dú)度量時(shí)用處不大,但是它們通常會(huì)被一起組成聚合或者平均度量挂签。二 者同時(shí)也依賴于模型中選擇的閾值。
直覺上來講,當(dāng)閾值低于某個(gè)程度,模型的預(yù)測結(jié)果永遠(yuǎn)會(huì)是類別1盼产。因此,模型的召回率 為1,但是準(zhǔn)確率很可能很低饵婆。相反,當(dāng)閾值足夠大,模型的預(yù)測結(jié)果永遠(yuǎn)會(huì)是類別0。此時(shí),模 型的召回率為0,但是因?yàn)槟P筒荒茴A(yù)測任何真陽性的樣本,很可能會(huì)有很多的假陰性樣本戏售。不 僅如此,因?yàn)檫@種情況下真陽性和假陽性為0,所以無法定義模型的準(zhǔn)確率侨核。
圖5-8所示的準(zhǔn)確率-召回率(PR)曲線,表示給定模型隨著決策閾值的改變,準(zhǔn)確率和召回 率的對應(yīng)關(guān)系。PR曲線下的面積為平均準(zhǔn)確率灌灾。直覺上,PR曲線下的面積為1等價(jià)于一個(gè)完美模 型,其準(zhǔn)確率和召回率達(dá)到100%搓译。
ROC曲線和AUC
ROC曲線在概念上和PR曲線類似,它是對分類器的真陽性率?假陽性率的圖形化解釋。
真陽性率(TPR)是真陽性的樣本數(shù)除以真陽性和假陰性的樣本數(shù)之和紧卒。換句話說,TPR是 真陽性數(shù)目占所有正樣本的比例侥衬。這和之前提到的召回率類似,通常也稱為敏感度。
假陽性率(FPR)是假陽性的樣本數(shù)除以假陽性和真陰性的樣本數(shù)之和跑芳。換句話說,FPR是 假陽性樣本數(shù)占所有負(fù)樣本總數(shù)的比例轴总。
和準(zhǔn)確率和召回率類似,ROC曲線(圖5-9)表示了分類器性能在不同決策閾值下TPR對FPR 的折衷。曲線上每個(gè)點(diǎn)代表分類器決策函數(shù)中不同的閾值博个。
ROC下的面積(通常稱作AUC)表示平均值怀樟。同樣,AUC為1.0時(shí)表示一個(gè)完美的分類器,0.5則表示一個(gè)隨機(jī)的性能。于是,一個(gè)模型的AUC為0.5時(shí)和隨機(jī)猜測效果一樣盆佣。下面是計(jì)算
PR和ROC的代碼往堡。
# Compute raw scores on the test set
lrPredictionAndLabels = data.map(lambda lp: (float(lrModel.predict(lp.features)), lp.label))
# Instantiate metrics object
lrmetrics = BinaryClassificationMetrics(lrPredictionAndLabels)
# Area under precision-recall curve
print("Area under PR = %s" % lrmetrics.areaUnderPR)
# Area under ROC curve
print("Area under ROC = %s" % lrmetrics.areaUnderROC)
svmPredictionAndLabels = data.map(lambda lp: (float(svmModel.predict(lp.features)), lp.label))
svmMetrics = BinaryClassificationMetrics(svmPredictionAndLabels)
print("Area under PR = %s" % svmmetrics.areaUnderPR)
print("Area under ROC = %s" % svmmetrics.areaUnderROC)
bayesPredictionAndLabels = data_for_bayes.map(lambda lp: (float(bayesModel.predict(lp.features)), lp.label))
bayesMetrics = BinaryClassificationMetrics(bayesPredictionAndLabels)
print("Area under PR = %s" % bayesMetrics.areaUnderPR)
print("Area under ROC = %s" % bayesMetrics.areaUnderROC)
邏輯回歸和SVM的AUC的結(jié)果在0.5左右,表明這兩個(gè)模型并不比隨機(jī)好械荷。樸素貝葉斯模型 和決策樹模型性能稍微好些,AUC分別是0.58和0.65。但是,在二分類問題上這個(gè)性能并不是非 常好虑灰。
模型改進(jìn)
根據(jù)上面的結(jié)果吨瞎,我們已經(jīng)確定我們訓(xùn)練出的模型很不少,但問題出在哪里呢穆咐?想想看,我們只是簡單地把原始數(shù)據(jù)送進(jìn)了模型做訓(xùn)練颤诀。事實(shí)上,我們并沒有把所有數(shù)據(jù)用 在模型中,只是用了其中易用的數(shù)值部分。同時(shí),我們也沒有對這些數(shù)值特征做太多分析对湃,包括特征標(biāo)準(zhǔn)化崖叫,歸一化處理,異常數(shù)據(jù)處理拍柒,模型參數(shù)調(diào)優(yōu)等心傀。接下來計(jì)劃寫一篇專文來介紹這些。
總結(jié)
本篇主要是熟悉API為主拆讯,所以很多細(xì)節(jié)都是點(diǎn)到為止脂男,在學(xué)習(xí)的過程中,也了解了一些Scala的東西往果,感覺用Scala比用Python還要簡潔疆液,學(xué)習(xí)的路還很長啊。
參考文章
Spark官網(wǎng)
Spark機(jī)器學(xué)習(xí)
留一交叉驗(yàn)證
