本文講述基于 Redis 的序列號(hào)服務(wù)的設(shè)計(jì)诵姜,主要從序列號(hào)服務(wù)的概念、需求以及服務(wù)的設(shè)計(jì)思路與詳細(xì)設(shè)計(jì)等方面對(duì)其進(jìn)行闡述搏熄。
〇棚唆、前言
在筆者團(tuán)隊(duì)中,由于分布式 ID 具有單調(diào)遞增心例、形成序列的特性宵凌,我們習(xí)慣將分布式 ID 稱為序列號(hào)(Sequence),將分布式 ID 生產(chǎn)系統(tǒng)為序列號(hào)服務(wù)系統(tǒng)止后。因此瞎惫,本文以“序列號(hào)”一詞均指代分布式 ID 來進(jìn)行講述。
前些天在“開發(fā)者頭條”的熱門分享中有一篇攜程技術(shù)中心大咖寫的 《分布式架構(gòu)系統(tǒng)生成全局唯一序列號(hào)的一個(gè)思路》译株,文章中對(duì)多種分布式 ID 系統(tǒng)設(shè)計(jì)方案進(jìn)行了詳細(xì)的優(yōu)劣對(duì)比微饥,并重點(diǎn)講述了他們最終選擇以 flicker 方案為基礎(chǔ)進(jìn)行優(yōu)化改進(jìn)。另外古戴,網(wǎng)絡(luò)上闡述分布式 ID 系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)的文章數(shù)不勝數(shù),其中不少文章同樣干貨滿滿矩肩,筆者拜讀數(shù)遍现恼,受益匪淺肃续,其中包括美團(tuán)點(diǎn)評(píng) Leaf ,微信的 seqsvr叉袍。
在此始锚,筆者基于團(tuán)隊(duì)的業(yè)務(wù)適用性繼續(xù)對(duì)該主題進(jìn)行補(bǔ)充,為讀者提供一種基于 Redis 的序列號(hào)服務(wù)系統(tǒng)的設(shè)計(jì)思路(當(dāng)時(shí)主要是參考微信的 seqsvr 做的簡化方案)喳逛。
一瞧捌、服務(wù)介紹
1.1 概念
分布式 ID 生成系統(tǒng),顧名思義润文,是在分布式的架構(gòu)環(huán)境中姐呐,生成全局唯一標(biāo)識(shí)的系統(tǒng)。比如在常見的業(yè)務(wù)系統(tǒng)中典蝌,分布式 ID 可用來標(biāo)記客戶號(hào)曙砂、訂單號(hào)、文件號(hào)骏掀、優(yōu)惠券號(hào)等鸠澈,以保證這些數(shù)據(jù)的全局唯一性。正如前文所述截驮,筆者團(tuán)隊(duì)所使用的分布式 ID 具有單調(diào)遞增笑陈、形成序列的特性(既滿足全局唯一,又滿足排序的特性)葵袭,被稱為序列號(hào)涵妥,而生成序列號(hào)的系統(tǒng)被稱為序列號(hào)服務(wù)。
序列號(hào)服務(wù)業(yè)內(nèi)有許多方案眶熬,比如基于 UUID妹笆,基于 Redis 的 INCR 自增,基于數(shù)據(jù)庫 ID 自增娜氏,基于 snowflake 的 bit 分段等等拳缠,它們各有優(yōu)缺點(diǎn)和適用性∶趁郑基于團(tuán)隊(duì)當(dāng)前的系統(tǒng)量級(jí)與業(yè)務(wù)適用性窟坐,筆者團(tuán)隊(duì)選擇了基于 Redis 的方案。
1.2 需求
筆者團(tuán)隊(duì)中有些業(yè)務(wù)場(chǎng)景與日切相關(guān)绵疲,所以將序列號(hào)分為兩類哲鸳,一類是遞增序列(Normal Sequence)、另一類是日切序列(Batch Sequence)盔憨。
- 永增序列:永遠(yuǎn)按升序生成新序列號(hào)
- 日切序列:按日切換批次的序列徙菠,同一天按升序生成新序列號(hào),換批次后序列號(hào)重置從 1 開始
二郁岩、服務(wù)設(shè)計(jì)
2.1 設(shè)計(jì)思路
我們知道婿奔,序列號(hào)服務(wù)實(shí)現(xiàn)序列號(hào)全局唯一與單調(diào)遞增可排序并非難事缺狠,它的難點(diǎn)在于如何設(shè)計(jì)好整體架構(gòu)以滿足高性能,高并發(fā)以及高可用等非功能特性萍摊。
2.1.1 Redis HINCRBY 命令
Redis 的 INCR 命令支持 Key 的 “INCR AND GET” 原子操作挤茄。利用這個(gè)特性,我們可以在 Redis 中存序列號(hào)冰木,讓分布式環(huán)境中多個(gè)取號(hào)方在集中的 Redis 中通過 INCR 命令來實(shí)現(xiàn)取號(hào)穷劈;同時(shí) Redis 是單進(jìn)程單線程的架構(gòu),不會(huì)因?yàn)槎鄠€(gè)取號(hào)方的 INCR 命令導(dǎo)致取號(hào)重復(fù)踊沸。那么基于 Redis 的 INCR 命令實(shí)現(xiàn)序列號(hào)的生產(chǎn)基本能滿足全局唯一與單調(diào)遞增的特性歇终,并且性能還不錯(cuò)。
實(shí)際上雕沿,為了存儲(chǔ)序列號(hào)的更多相關(guān)信息练湿,我們使用了 Redis 的 Hash 數(shù)據(jù)結(jié)構(gòu),Redis 同樣為 Hash 提供 HINCRBY 命令來實(shí)現(xiàn) “INCR AND GET” 原子操作审轮,詳情稍后請(qǐng)看 Redis 的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)肥哎。
2.1.2 Redis 宕機(jī)序列號(hào)恢復(fù)問題
我們?cè)傧胂耄琑edis 是內(nèi)存數(shù)據(jù)庫疾渣,在提供高性能存取的同時(shí)篡诽,在沒有開啟 RDB 或者 AOF 持久化的情況下一旦宕機(jī)序列號(hào)將會(huì)有丟失。
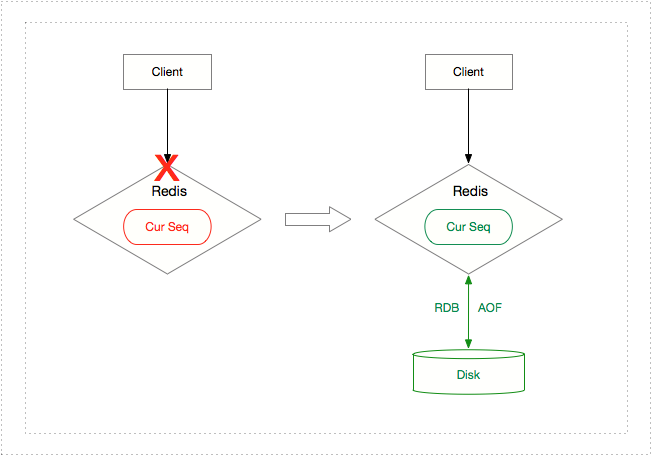
即便開啟了 RDB 持久化榴捡,由于最近一次快照時(shí)間和最新一條 HINCRBY 命令的時(shí)間有可能存在時(shí)間差杈女,宕機(jī)后通過 RDB 快照恢復(fù)數(shù)據(jù)集會(huì)發(fā)生取號(hào)重復(fù)的情況;
而 AOF 持久化通過追加寫命令到 AOF 文件的方式記錄所有 Redis 服務(wù)器的寫命令吊圾,服務(wù)重啟后通過執(zhí)行這些寫命令恢復(fù)數(shù)據(jù)达椰,理論上數(shù)據(jù)集都能恢復(fù)到最新狀態(tài),不會(huì)發(fā)生取號(hào)重復(fù)的情況项乒;然而 AOF 持久化會(huì)損耗性能并且在宕機(jī)重啟后可能由于文件過大導(dǎo)致恢復(fù)數(shù)據(jù)時(shí)間過長啰劲;另外,即便能通過 AOF 重寫來壓縮文件檀何,如果是在寫 AOF 時(shí)發(fā)生宕機(jī)導(dǎo)致文件出錯(cuò)蝇裤,則需要較多時(shí)間去人為恢復(fù) AOF 文件;所以我們需要一個(gè)恢復(fù)方案來保證 Redis 序列號(hào)服務(wù)在 Redis 宕機(jī)后可快速恢復(fù)數(shù)據(jù)并且不會(huì)導(dǎo)致取號(hào)重復(fù)频鉴。
2.1.3 Redis 宕機(jī)序列號(hào)恢復(fù)方案
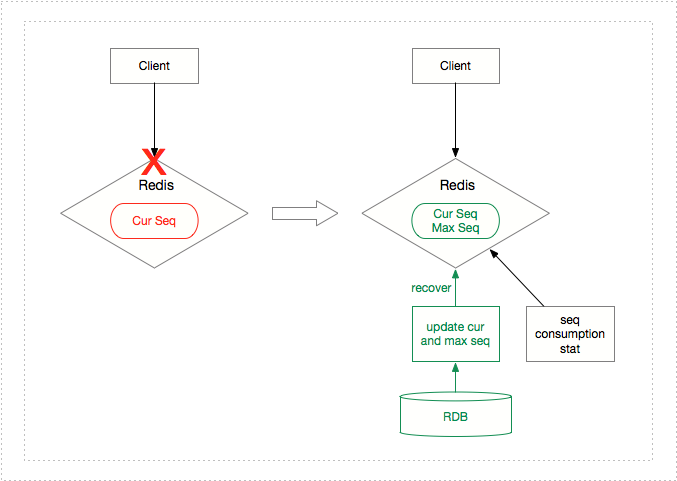
我們可以利用關(guān)系型數(shù)據(jù)庫來記錄一個(gè)短時(shí)內(nèi) 最大可取序列號(hào) max栓辜,取號(hào)方從 Redis 中取號(hào)時(shí)只能取小于 max 的序列號(hào)。另外垛孔,我們可以設(shè)計(jì)兩個(gè)服務(wù):一個(gè)定期地統(tǒng)計(jì)序列號(hào)消費(fèi)速度藕甩,另一個(gè)定期獲取統(tǒng)計(jì)值,當(dāng) Redis 中 當(dāng)前可取序列號(hào) cur 取號(hào)接近 max 時(shí)自動(dòng)更新 max 到一個(gè)適當(dāng)?shù)闹抵芗觯嫒霐?shù)據(jù)庫和 Redis辛萍。在 Redis 宕機(jī)的情況下悯姊,將從數(shù)據(jù)庫將最大可取序列號(hào) max 恢復(fù)成 Redis 當(dāng)前已取序列號(hào) cur,防止 Redis 取號(hào)重復(fù)贩毕。另外,也有可能關(guān)系型數(shù)據(jù)庫發(fā)生宕機(jī)仆嗦,不過由于主要的取號(hào)操作在 Redis辉阶,并且設(shè)計(jì)適當(dāng)?shù)淖畲罂扇⌒蛄刑?hào) max 能夠提供足夠時(shí)間恢復(fù)關(guān)系型數(shù)據(jù)庫。
在筆者團(tuán)隊(duì)當(dāng)前的系統(tǒng)量級(jí)要求以及業(yè)務(wù)需求下瘩扼,這種設(shè)計(jì)思路經(jīng)過一段時(shí)間的生產(chǎn)實(shí)踐相對(duì)適用谆甜,接下來講述詳細(xì)的系統(tǒng)設(shè)計(jì)。
2.2 詳細(xì)設(shè)計(jì)
由于日切序列在設(shè)計(jì)上與永增序列差異不大集绰,只是多了一個(gè)日期的維度规辱,所以在詳細(xì)設(shè)計(jì)的講述過程中將以永增序列為主,日切序列不再贅述栽燕。
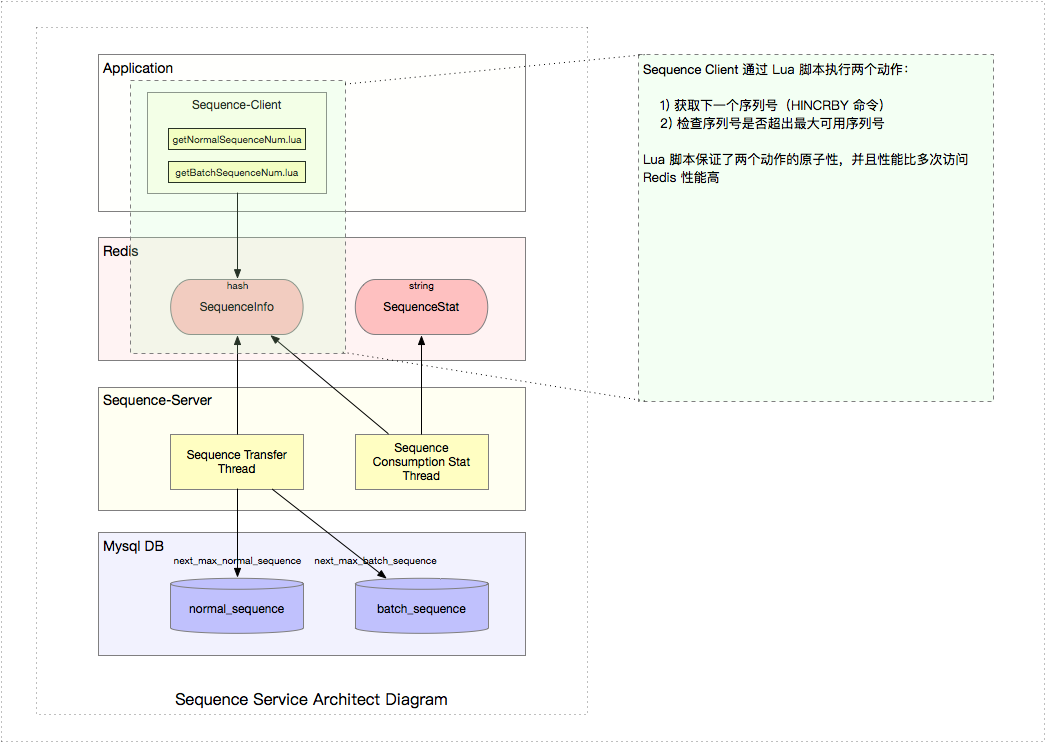
2.2.1 架構(gòu)圖
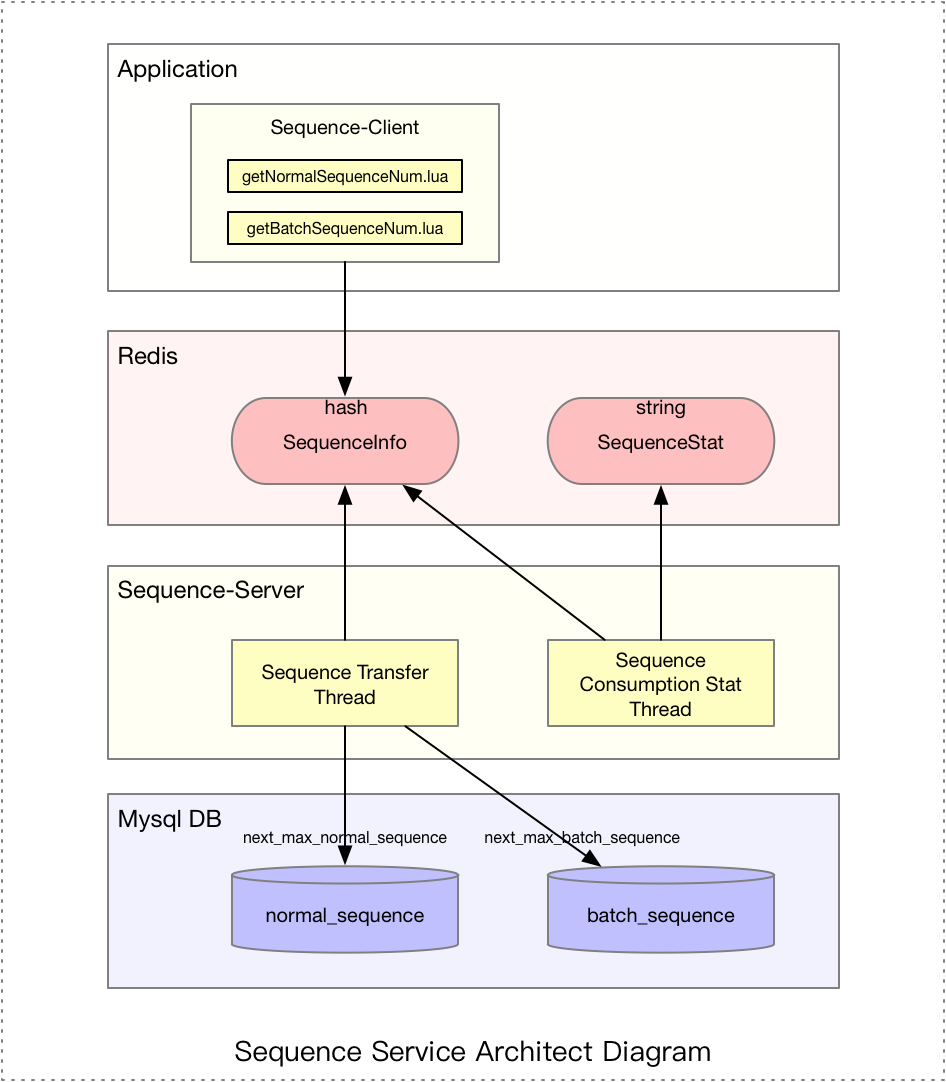
從上圖可知罕袋,序列號(hào)服務(wù)分兩部分:Sequence-Server 和 Sequence-Client,這兩部分都依賴于 Redis 和 Mysql碍岔。我們先從 Redis 和 Mysql 的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)開始浴讯,然后再繼續(xù)講述 Server 和 Client 的部分。
2.2.2 Redis 數(shù)據(jù)結(jié)構(gòu)
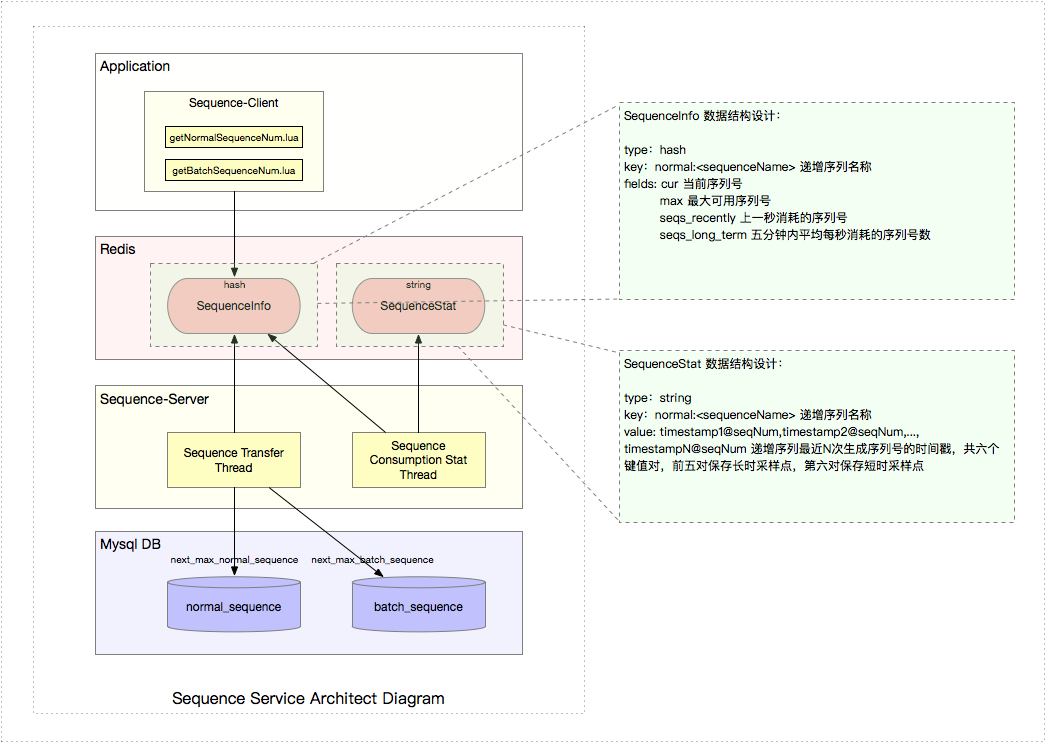
A. Sequence Info —— 序列號(hào)相關(guān)信息
1) 數(shù)據(jù)結(jié)構(gòu)
| 類型 | 值 | 說明 |
|---|---|---|
| type | hash | 哈希數(shù)據(jù)結(jié)構(gòu) |
| key | normal:<sequenceName> | 遞增序列名稱 |
| fields | cur | 當(dāng)前序列號(hào) |
| - | max | 最大可用序列號(hào) |
| - | seqs_recently | 上一秒消耗的序列號(hào)數(shù) |
| - | seqs_long_term | 五分鐘內(nèi)平均每秒消耗的序列號(hào)數(shù) |
取號(hào)方應(yīng)用通過 Sequence-Client 獲取序列號(hào)的時(shí)候蔼啦,通過 HINCRBY 命令增加 cur 的值并且取出榆纽,然后校驗(yàn)當(dāng)前值是否超出了最大可用序列號(hào) max。seqs_recently 和 seqs_long_term 記錄了 sequenceName 這個(gè)序列近期(上一秒)和長期(五分鐘內(nèi)平均每秒)消耗的序列號(hào)數(shù)捏肢,Sequence Server 用它來計(jì)算每次增大 max 的步長奈籽。
2) 數(shù)據(jù)樣例
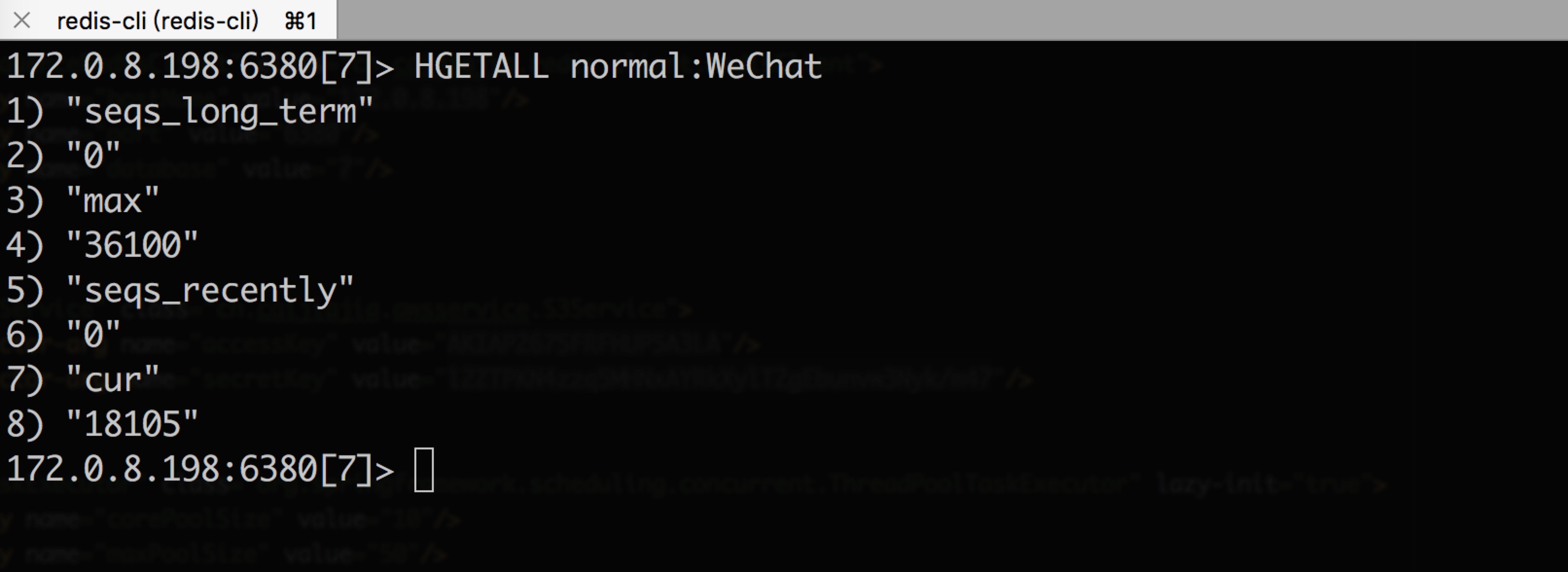
上圖顯示最大可用序列號(hào) max為 36100,當(dāng)前已取序列號(hào) cur為 18105鸵赫,上一秒消耗的序列號(hào)數(shù) seqs_recently為 0衣屏,五分鐘內(nèi)平均每秒消耗的序列號(hào)數(shù)seqs_long_term為 0。
B. Sequence Stat —— 序列號(hào)采樣信息
1) 數(shù)據(jù)結(jié)構(gòu)
| 類型 | 值 | 說明 |
|---|---|---|
| type | String Value | 字符串 |
| key | normal:<sequenceName>:stat | 遞增序列名稱 |
| value | timestamp1@seqNum,...,timestamp6@seqNum | 遞增序列最近N次生成序列號(hào)的時(shí)間戳奉瘤,共六個(gè)鍵值對(duì)勾拉,前五對(duì)保存長時(shí)采樣點(diǎn),第六對(duì)保存短時(shí)采樣點(diǎn) |
2) 數(shù)據(jù)樣例

2.2.3 MySql 數(shù)據(jù)結(jié)構(gòu)
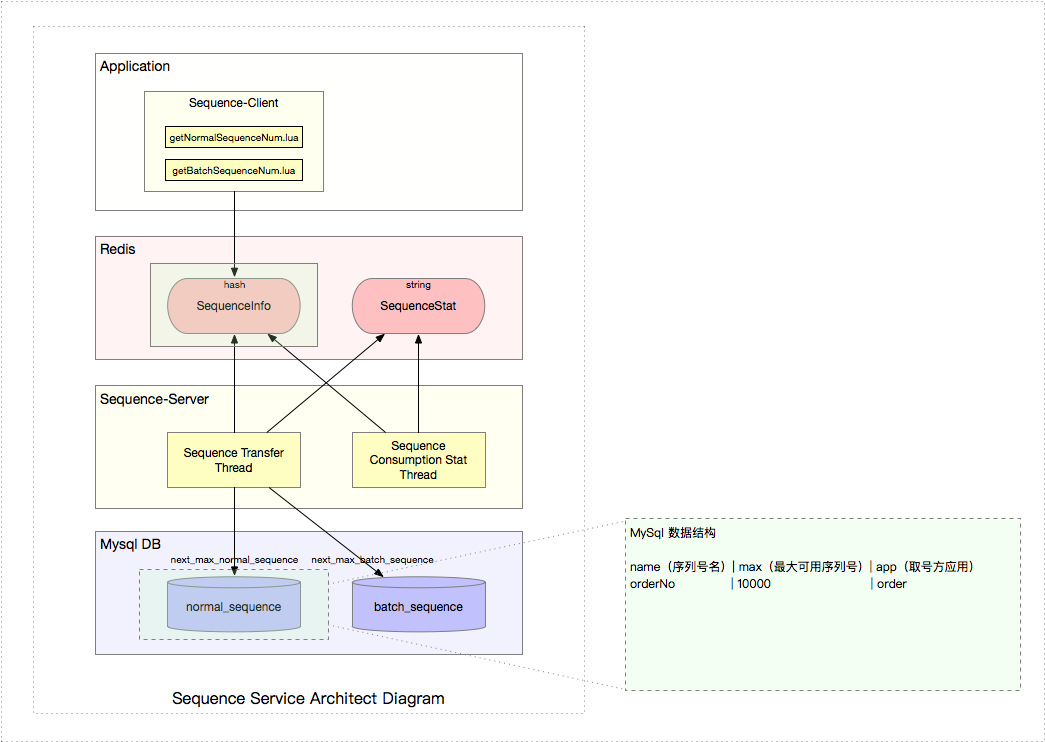
另外盗温,編寫數(shù)據(jù)庫自定義函數(shù) —— 更新數(shù)據(jù)庫 最大可取序列號(hào) max(其中 last_insert_id(max + step) 為了保證事務(wù))藕赞,如下:
CREATE FUNCTION `next_max_normal_sequence`(sequence_name varchar (50), step int(11))
RETURNS bigint(20)
BEGIN
update normal_sequence set max = last_insert_id(max + step) where name = sequence_name;
return last_insert_id();
END;
2.2.4 Sequence-Server
Sequence-Server 依賴 MySql 數(shù)據(jù)庫生成和更新 最大可取序列號(hào) max,并開啟兩個(gè)常駐線程把序列號(hào)相關(guān)信息和統(tǒng)計(jì)信息更新到 Redis卖局。
A. Sequence Transfer Thread
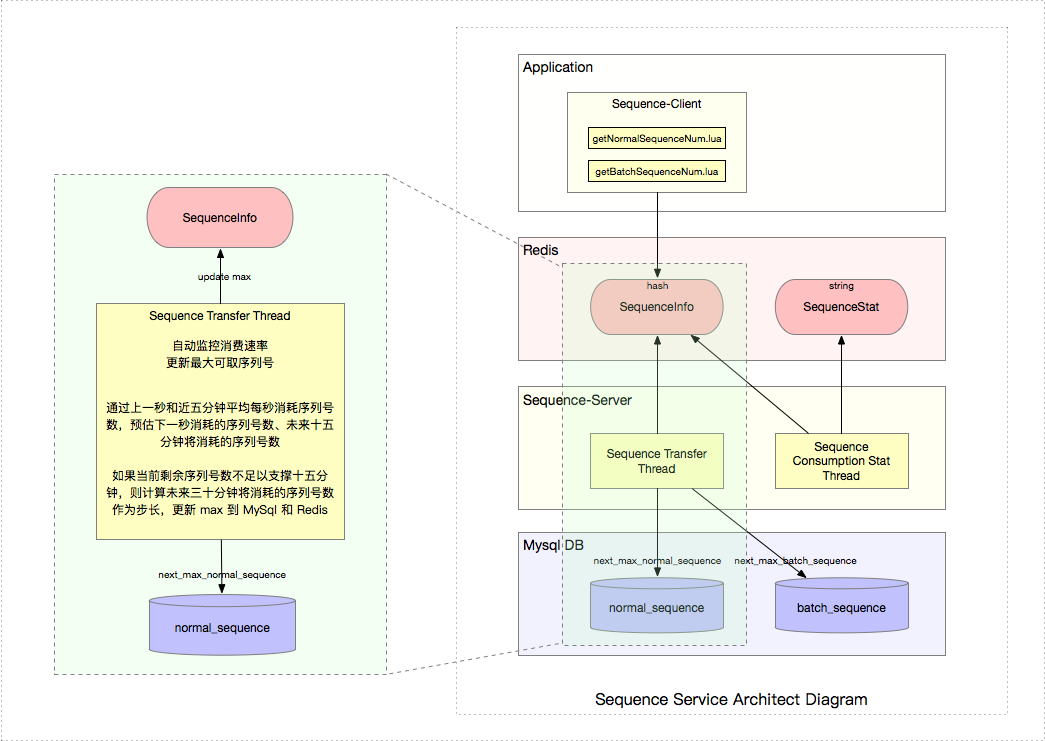
常駐線程 Sequence Transfer Thread 負(fù)責(zé)定時(shí)(每秒一次)通過上一秒消耗序列號(hào)數(shù) seqs_recently 和近五分鐘平均每秒消耗序列號(hào)數(shù) seqs_long_term斧蜕,預(yù)估下一秒消耗的序列號(hào)數(shù),從而預(yù)估未來十五分鐘將消耗的序列號(hào)數(shù)砚偶。如果當(dāng)前剩余序列號(hào)數(shù)不足以支撐十五分鐘批销,則計(jì)算未來三十分鐘將消耗的序列號(hào)數(shù)作為步長洒闸,更新 max 到 MySql 和 Redis,保證取號(hào)方應(yīng)用每次都能獲取到有效的序列號(hào)均芽。
B. Sequence Stat Thread
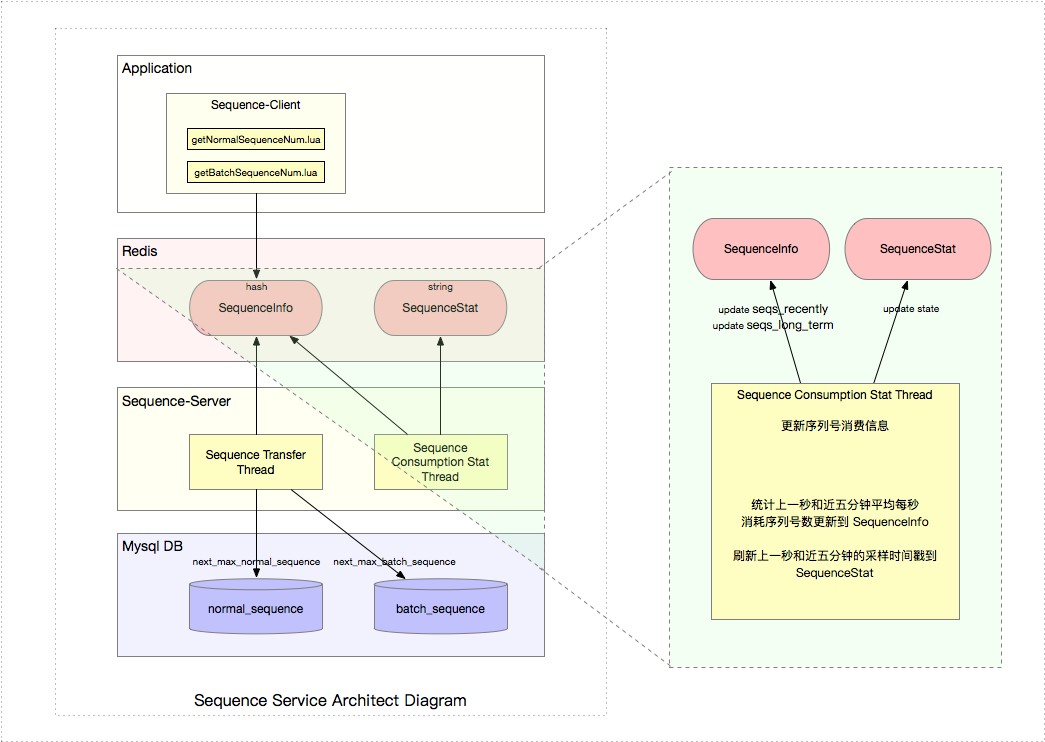
常駐線程 Sequence Stat Thread 負(fù)責(zé)定時(shí)(每秒一次)統(tǒng)計(jì)取號(hào)速率丘逸,以便自動(dòng)調(diào)整 Mysql 與 Redis 中的 最大可取序列號(hào) Max)。
2.2.5 Sequence-Client
Sequence-Client 以 jar 包的形式被取號(hào)方的應(yīng)用所引用掀宋,它通過封裝 “INCR AND GET深纲、校驗(yàn)序列號(hào)是否在有效范圍” 這兩個(gè)操作到 Lua 腳本中實(shí)現(xiàn)原子性以及避免多次訪問redis造成的性能消耗。
-- Sequence-Client Lua 腳本
local maxSeqNumStr = redis.pcall("HGET", KEYS[1], "max")
if type(maxSeqNumStr) == 'boolean' and maxSeqNumStr == false then
return nil
end
local maxSeqNum = tonumber(maxSeqNumStr)
local seqNum = redis.pcall("HINCRBY", KEYS[1], "cur", 1)
if seqNum <= maxSeqNum then
return seqNum
else
return nil
end
三劲妙、服務(wù)總結(jié)
當(dāng)前序列號(hào)服務(wù)方案滿足:
- 序列號(hào)全局唯一
- 日切序列單日內(nèi)序列號(hào)全局唯一
- 序列號(hào)單調(diào)遞增可排序
- 高并發(fā)
- 可用性
- Redis(主備) + Mysql
在本機(jī)的性能測(cè)試如下:
| 線程數(shù) | 平均響應(yīng)時(shí)間(毫秒) | 吞吐量(個(gè)/秒) |
|---|---|---|
| 1 | 4 | 233 |
| 10 | 5 | 1989 |
| 100 | 16 | 5923 |
| 500 | 19 | 5505 |
總的來講湃鹊,當(dāng)前我們?cè)O(shè)計(jì)的序列號(hào)服務(wù)依舊能適用于業(yè)務(wù)需要。隨著系統(tǒng)量級(jí)的增大以及業(yè)務(wù)需求的變更與演進(jìn)镣奋,序列號(hào)服務(wù)也會(huì)隨之做出調(diào)整币呵。比如 Redis 性能可能成為瓶頸,那么可以在 sequence client 的 HINCRBY 命令上增加大于 1 的增量侨颈,提供批量獲取序列號(hào)的功能(需要調(diào)整統(tǒng)計(jì)序列號(hào)消費(fèi)速率來協(xié)助自動(dòng)調(diào)整 max 值)余赢;也可以為取號(hào)方提供 Redis 的分片功能,不同的取號(hào)方在各自 Redis 中取序列號(hào)等等肛搬。
至此本文結(jié)束没佑,希望可以為讀者提供一種基于 Redis 的序列號(hào)服務(wù)系統(tǒng)的設(shè)計(jì)思路。當(dāng)然温赔,其中方案的優(yōu)缺點(diǎn)以及改進(jìn)點(diǎn)蛤奢,讀者亦可自行思考總結(jié),找到適用于自己的方案陶贼。
轉(zhuǎn)載聲明:未經(jīng)授權(quán)不得轉(zhuǎn)載啤贩,授權(quán)后轉(zhuǎn)載請(qǐng)注明出處并附上原文鏈接。
更多閱讀請(qǐng)關(guān)注【泛金融技術(shù)】微信公眾號(hào)拜秧。


