介紹
我正在和一位剛剛在印度超市連鎖店擔(dān)任運(yùn)營(yíng)經(jīng)理的朋友說話奈辰。在我們的討論中,我們開始談?wù)撛谟《裙?jié)日(排燈節(jié))開始之前乱豆,連鎖店需要做的準(zhǔn)備量奖恰。
他告訴我,他們估計(jì)/預(yù)測(cè)哪個(gè)產(chǎn)品會(huì)像熱蛋糕一樣銷售,哪些產(chǎn)品不會(huì)在購(gòu)買之前是至關(guān)重要的房官。一個(gè)不好的決定可能會(huì)讓您的客戶在競(jìng)爭(zhēng)對(duì)手商店中尋找優(yōu)惠和產(chǎn)品趾徽。挑戰(zhàn)并沒有在這里完成 - 您需要估算不同地區(qū)的商店的不同類別的產(chǎn)品銷售情況,消費(fèi)者有不同的消費(fèi)技術(shù)翰守。
當(dāng)我的朋友描述挑戰(zhàn)時(shí),我的數(shù)據(jù)科學(xué)家開始微笑疲酌!為什么蜡峰?我剛剛想出了下一篇文章的潛在主題。在今天的文章中朗恳,我會(huì)告訴你需要知道的關(guān)于回歸模型的一切湿颅,以及如何使用它們來解決像上面提到的預(yù)測(cè)問題。
花一點(diǎn)時(shí)間粥诫,列出所有可以考慮的因素油航,一個(gè)商店的銷售將依賴于這些因素。對(duì)于每個(gè)因素怀浆,都會(huì)產(chǎn)生一個(gè)關(guān)于為什么以及如何影響各種產(chǎn)品銷售的因素的假設(shè)谊囚。例如 - 我期望產(chǎn)品的銷售取決于商店的位置,因?yàn)槊總€(gè)地區(qū)的當(dāng)?shù)鼐用穸紩?huì)有不同的生活方式执赡。商店在艾哈邁達(dá)巴德將出售的面包量將是孟買類似商店的一小部分镰踏。
同樣列出你可以想到的所有可能的因素。
您商店的位置沙合,產(chǎn)品的可用性奠伪,商店的尺寸,產(chǎn)品的優(yōu)惠首懈,產(chǎn)品的廣告绊率,商店的放置可能是您的銷售依賴的一些功能。
你能想出多少因素究履?如果不到15滤否,再考慮一下!處理這個(gè)問題的數(shù)據(jù)科學(xué)家可能會(huì)想到數(shù)百個(gè)這樣的因素挎袜。
考慮到這一想法顽聂,我為您提供了一個(gè)這樣的數(shù)據(jù)集 - 大賣場(chǎng)銷售。在數(shù)據(jù)集中盯仪,我們有一個(gè)鏈的多個(gè)出口的產(chǎn)品明智的銷售紊搪。
讓我們來看一下數(shù)據(jù)集的快照:

在數(shù)據(jù)集中,我們可以看到出售物品的特征(脂肪含量全景,可見性耀石,類型,價(jià)格)和出口(建立年份爸黄,大小滞伟,位置揭鳞,類型)的一些特征以及為該特定物品出售的物品數(shù)量。我們來看看我們可以使用這些功能來預(yù)測(cè)銷售情況梆奈。
目錄
預(yù)測(cè)的簡(jiǎn)單模型
線性回歸
最適合的線條
梯度下降
使用線性回歸進(jìn)行預(yù)測(cè)
評(píng)估您的Model-R平方和R平方
使用所有功能進(jìn)行預(yù)測(cè)
多項(xiàng)式回歸
偏差和差異
正則
嶺回歸
拉索回歸
彈性網(wǎng)回歸
正則化技術(shù)的類型[可選]
預(yù)測(cè)的簡(jiǎn)單模型
讓我們先從使用幾種簡(jiǎn)單的方法開始做預(yù)測(cè)野崇。如果我問你,什么可以是預(yù)測(cè)物品銷售的最簡(jiǎn)單的方法亩钟,你會(huì)說什么乓梨?
型號(hào)1 - 平均銷量:
即使沒有機(jī)器學(xué)習(xí)的知識(shí),你可以說如果你必須預(yù)測(cè)一個(gè)項(xiàng)目的銷售量清酥,這將是過去幾天的平均水平扶镀。/月/周。
這是一個(gè)很好的想法焰轻,但它也提出了一個(gè)問題 - 這個(gè)模型有多好臭觉?
事實(shí)證明,我們有多種方式可以評(píng)估我們的模型有多好辱志。最常見的方法是均方誤差蝠筑。讓我們了解如何衡量它。
預(yù)測(cè)錯(cuò)誤
為了評(píng)估模型有多好荸频,讓我們了解錯(cuò)誤預(yù)測(cè)的影響菱肖。如果我們預(yù)測(cè)銷售額高于可能的水平,那么商店將花費(fèi)大量的資金進(jìn)行不必要的安排旭从,從而導(dǎo)致庫(kù)存過剩稳强。另一方面,如果我預(yù)測(cè)它太低和悦,我會(huì)失去銷售機(jī)會(huì)退疫。
因此,計(jì)算誤差的最簡(jiǎn)單的方法是計(jì)算預(yù)測(cè)值和實(shí)際值的差異鸽素。但是褒繁,如果我們簡(jiǎn)單地添加它們,它們可能會(huì)被取消馍忽,所以我們?cè)谔砑又熬蛯?duì)這些錯(cuò)誤進(jìn)行排列棒坏。我們還將它們除以數(shù)據(jù)點(diǎn)的數(shù)量來計(jì)算平均誤差,因?yàn)樗粦?yīng)該取決于數(shù)據(jù)點(diǎn)的數(shù)量遭笋。

這被稱為均方誤差坝冕。
這里是e1,e2 ...瓦呼。喂窟,en是實(shí)際值和預(yù)測(cè)值之間的差異。
那么在第一個(gè)模型中,平均誤差是多少磨澡?在預(yù)測(cè)所有數(shù)據(jù)點(diǎn)的平均值時(shí)碗啄,我們得到均方誤差= 29,11,799∥壬悖看起來像巨大的錯(cuò)誤稚字。簡(jiǎn)單地預(yù)測(cè)平均值可能不是很酷。
我們來看看我們是否可以想到一些東西來減少錯(cuò)誤厦酬。
型號(hào)2-按位置平均銷售:
我們知道這個(gè)位置在一個(gè)物品的銷售中起著至關(guān)重要的作用尉共。例如,讓我們說弃锐,在德里,汽車的銷售將比在瓦拉納西的銷售高得多殿托。因此霹菊,我們使用列“Outlet_Location_Type”的數(shù)據(jù)。
所以基本上支竹,讓我們來計(jì)算每個(gè)位置類型的平均銷售額旋廷,并進(jìn)行相應(yīng)的預(yù)測(cè)。
預(yù)測(cè)相同礼搁,我們得到mse = 28,75,386饶碘,低于我們以前的情況。所以我們可以注意到馒吴,通過使用特征[位置]扎运,我們減少了錯(cuò)誤。
現(xiàn)在饮戳,如果銷售有多個(gè)功能需要依賴什么呢豪治?我們?nèi)绾问褂眠@些信息預(yù)測(cè)銷售?線性回歸來我們的救援扯罐。
線性回歸
線性回歸是預(yù)測(cè)建模中最簡(jiǎn)單和最廣泛使用的統(tǒng)計(jì)技術(shù)负拟。它基本上給了我們一個(gè)方程,我們將我們的特征作為自變量歹河,我們的目標(biāo)變量[在我們的情況下的銷售]依賴于它們掩浙。
那么方程式是什么樣的?線性回歸方程如下:

在這里秸歧,我們有Y作為因變量(Sales)厨姚,X是獨(dú)立變量,所有的系數(shù)都是系數(shù)寥茫。系數(shù)基本上是基于它們的重要性分配給特征的權(quán)重遣蚀。例如,如果我們認(rèn)為一個(gè)項(xiàng)目的銷售對(duì)倉(cāng)庫(kù)類型的依賴程度會(huì)更高,那么這意味著一級(jí)城市的銷售額要比3級(jí)更小城市在一個(gè)更大的出口芭梯。因此险耀,位置類型的系數(shù)將大于店面大小。
所以玖喘,首先讓我們嘗試用一個(gè)特征即只有一個(gè)獨(dú)立變量來理解線性回歸甩牺。因此,我們的方程式成為累奈,

該方程被稱為一個(gè)簡(jiǎn)單的線性回歸方程贬派,其表示的直線,其中“Θ0”是截距澎媒,“Θ1”是直線的斜率搞乏。看看銷售和MRP之間的情節(jié)戒努。

令人驚訝的是请敦,我們可以看到產(chǎn)品的銷售額隨著MRP的增加而增加。因此储玫,虛線紅線代表我們的回歸線或最佳擬合線侍筛。但是出現(xiàn)的一個(gè)問題是你會(huì)發(fā)現(xiàn)這一行?
最適合的線條
正如你可以在下面看到的撒穷,可以有這么多的行可以用來根據(jù)他們的MRP估計(jì)銷售額匣椰。那么你如何選擇最合適的線條或回歸線呢?

最佳擬合線的主要目的是端礼,我們的預(yù)測(cè)值應(yīng)該更接近于實(shí)際值或觀測(cè)值禽笑,因?yàn)轭A(yù)測(cè)與實(shí)際值相距很遠(yuǎn)的值沒有意義。換句話說齐媒,我們傾向于最小化我們預(yù)測(cè)的值與觀測(cè)值之間的差異蒲每,實(shí)際上被稱為誤差。誤差的圖形表示如下圖所示喻括。這些錯(cuò)誤也稱為殘差邀杏。殘差由垂直線表示,表示預(yù)測(cè)值和實(shí)際值之差唬血。

好的望蜡,現(xiàn)在我們知道我們的主要目標(biāo)是找出錯(cuò)誤并盡量減少。但在此之前拷恨,讓我們想想如何處理第一部分脖律,也就是計(jì)算錯(cuò)誤。我們已經(jīng)知道腕侄,誤差是我們預(yù)測(cè)的值與觀測(cè)值的差值小泉。讓我們考慮三種方法來計(jì)算錯(cuò)誤:
殘差總和(Σ(Y-h(X)))- 它可能導(dǎo)致抵消正負(fù)誤差芦疏。
殘差絕對(duì)值(Σ| Yh(X)|)- 絕對(duì)值的總和將阻止錯(cuò)誤的消除
殘差平方和(Σ(Yh(X))2)- 這是實(shí)際使用的方法,因?yàn)檫@里我們比較小的懲罰更高的誤差值微姊,所以造成大的誤差有很大差異和小錯(cuò)誤酸茴,這使得容易區(qū)分和選擇最適合線。
因此兢交,這些殘差的平方和表示為:

其中薪捍,H(x)是由我們預(yù)測(cè)的值,H(X)=Θ1* X +Θ0配喳,y為實(shí)際值酪穿,m是在訓(xùn)練組中的行數(shù)。
成本函數(shù)
那么說晴裹,你增加了一個(gè)特定的商店的大小被济,在那里你預(yù)測(cè)銷售額會(huì)更高。但盡管規(guī)模不斷擴(kuò)大涧团,但該店的銷售額并沒有增加溉潭。因此,增加商店規(guī)模所需的成本給您帶來負(fù)面結(jié)果少欺。
所以,我們需要盡量減少這些成本馋贤。因此赞别,我們引入一個(gè)成本函數(shù),它基本上用于定義和測(cè)量模型的誤差配乓。

如果仔細(xì)觀察這個(gè)方程仿滔,它只是類似于平方誤差的總和,只需要1 / 2m的乘積來減輕數(shù)學(xué)犹芹。
所以為了改進(jìn)我們的預(yù)測(cè)崎页,我們需要最小化成本函數(shù)。為此腰埂,我們使用梯度下降算法飒焦。所以讓我們了解它是如何工作的。
漸變下降
讓我們考慮一個(gè)例子屿笼,我們需要找到這個(gè)方程的最小值牺荠,
Y = 5x + 4x ^ 2。在數(shù)學(xué)中驴一,我們簡(jiǎn)單地將x方程的導(dǎo)數(shù)簡(jiǎn)單地等于零休雌。這給出了這個(gè)方程式最小的一點(diǎn)。因此肝断,取代該值可以給出該方程的最小值杈曲。
梯度血統(tǒng)以類似的方式工作驰凛。它迭代地更新Θ,找到成本函數(shù)最小的點(diǎn)担扑。如果你想深入研究血液深度下降恰响,我強(qiáng)烈建議您閱讀本文。
使用線性回歸預(yù)測(cè)
現(xiàn)在讓我們考慮使用線性回歸預(yù)測(cè)我們的大型市場(chǎng)銷售問題的銷售魁亦。
模型3 - 輸入線性回歸:
從以前的情況渔隶,我們知道通過使用正確的功能將提高我們的準(zhǔn)確性。所以現(xiàn)在讓我們用兩個(gè)功能洁奈,MRP和店鋪建立年度來估算銷售间唉。
現(xiàn)在,我們?cè)趐ython中建立一個(gè)線性回歸模型利术,只考慮這兩個(gè)特征呈野。
# importing basic libraries
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from sklearn.model_selection import train_test_split
import test and train file
train = pd.read_csv('Train.csv')
test = pd.read_csv('test.csv')
# importing linear regressionfrom sklearn
from sklearn.linear_model import LinearRegression
lreg = LinearRegression()
splitting into training and cv for cross validation
X = train.loc[:,['Outlet_Establishment_Year','Item_MRP']]
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
training the model
lreg.fit(x_train,y_train)
predicting on cv
pred = lreg.predict(x_cv)
calculating mse
mse = np.mean((pred - y_cv)**2)
在這種情況下,我們得到mse = 19,10,586.53印叁,比我們的模型2小得多被冒。因此,借助兩個(gè)特征預(yù)測(cè)更準(zhǔn)確轮蜕。
我們來看一下這個(gè)線性回歸模型的系數(shù)昨悼。
# calculating coefficients
coeff = DataFrame(x_train.columns)
coeff['Coefficient Estimate'] = Series(lreg.coef_)
coeff

因此,我們可以看到MRP具有較高的系數(shù)跃洛,意味著價(jià)格較高的物品銷售更好率触。
6.評(píng)估您的模型 - R平方和調(diào)整后的R平方
您認(rèn)為該模型的準(zhǔn)確度如何?我們有任何評(píng)估指標(biāo)汇竭,以便我們檢查一下嗎葱蝗?其實(shí)我們有一個(gè)數(shù)量,叫做R-Square细燎。
R-Square:它決定了Y(因變量)的總變化的多少是由X(自變量)的變化來解釋的两曼。數(shù)學(xué)上可以寫成:

R平方的值始終在0和1之間,其中0表示模型沒有模型解釋目標(biāo)變量(Y)中的任何變異性玻驻,1表示解釋目標(biāo)變量的完全變異性悼凑。
現(xiàn)在讓我們檢查上述模型的r平方。
lreg.score(x_cv,y_cv)
0.3287
在這種情況下璧瞬,R 2為32%佛析,這意味著銷售額的差異只有32%是由成立年份和MRP進(jìn)行解釋的。換句話說彪蓬,如果您知道建立成立年份和MRP寸莫,您將有32%的信息來準(zhǔn)確預(yù)測(cè)其銷售。
現(xiàn)在如果我在我的模型中再引入一個(gè)功能档冬,會(huì)發(fā)生什么事情膘茎,我的模型會(huì)更加逼近實(shí)際價(jià)值嗎桃纯?R-Square的價(jià)值會(huì)增加嗎?
讓我們考慮另一個(gè)案例披坏。
模型4 - 具有更多變量的線性回歸
我們通過使用兩個(gè)變量而不是一個(gè)變量了解到态坦,我們提高了對(duì)項(xiàng)目銷售進(jìn)行準(zhǔn)確預(yù)測(cè)的能力。
所以棒拂,我們?cè)賮斫榻B一下另外一個(gè)功能“重量”的情況∩√荩現(xiàn)在我們用這三個(gè)特征構(gòu)建一個(gè)回歸模型。
X = train.loc[:,['Outlet_Establishment_Year','Item_MRP','Item_Weight']]
splitting into training and cv for cross validation
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
## training the model
lreg.fit(x_train,y_train)
ValueError:輸入包含NaN帚屉,無(wú)窮大或?qū)type('float64')太大的值谜诫。
它會(huì)產(chǎn)生錯(cuò)誤,因?yàn)轫?xiàng)目權(quán)重列有一些缺失值攻旦。所以讓我們用其他非空條目的平均值來估算它喻旷。
train['Item_Weight'].fillna((train['Item_Weight'].mean()),inplace=True)
讓我們?cè)俅螄L試運(yùn)行該模型牢屋。
training the modellreg.fit(x_train,y_train)
## splitting into training and cv for cross validation
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales)
## training the modellreg.fit(x_train,y_train)
predicting on cvpred = lreg.predict(x_cv)
calculating mse
mse = np.mean((pred - y_cv)**2)
mse
1853431.59
## calculating coefficients
coeff = DataFrame(x_train.columns)
coeff['Coefficient Estimate'] = Series(lreg.coef_)

calculating r-square
lreg.score(x_cv,y_cv)0.32942
所以我們可以看到且预,mse進(jìn)一步減少。R平方值有增加烙无,是否意味著增加項(xiàng)目權(quán)重對(duì)我們的模型是有用的锋谐?
調(diào)整后的R平方
R2的唯一缺點(diǎn)是如果將新的預(yù)測(cè)因子(X)添加到我們的模型中,則R2僅增加或保持恒定截酷,但不會(huì)降低怀估。我們不能通過增加我們的模型的復(fù)雜性判斷,我們是否更準(zhǔn)確合搅?
這就是為什么我們使用“調(diào)整的R方”。
調(diào)整后的R平方是R模型的修改形式歧蕉,已經(jīng)針對(duì)模型中的預(yù)測(cè)數(shù)量進(jìn)行了調(diào)整灾部。它結(jié)合了模型的自由度。如果新術(shù)語(yǔ)提高了模型精度惯退,調(diào)整后的R-Square只會(huì)增加赌髓。
哪里

R2=樣品R平方
p =預(yù)測(cè)數(shù)量
N =總樣本量
7.使用所有功能進(jìn)行預(yù)測(cè)
現(xiàn)在讓我們構(gòu)建一個(gè)包含所有功能的模型。在建立回歸模型時(shí)催跪,我只使用了連續(xù)的功能锁蠕。這是因?yàn)槲覀冃枰诜诸愖兞恐安煌厥褂镁€性回歸模型。有不同的技術(shù)來對(duì)待它們懊蒸,這里我使用了一個(gè)熱編碼(將每個(gè)類別的分類變量轉(zhuǎn)換為一個(gè)特征)荣倾。除此之外,我還估計(jì)出口尺寸的缺失值骑丸。
回歸模型的數(shù)據(jù)預(yù)處理步驟
# imputing missing values
train['Item_Visibility'] = train['Item_Visibility'].replace(0,np.mean(train['Item_Visibility']))
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
train['Outlet_Size'].fillna('Small',inplace=True)
# creating dummy variables to convert categorical into numeric values
mylist = list(train1.select_dtypes(include=['object']).columns)
dummies = pd.get_dummies(train[mylist], prefix= mylist)
train.drop(mylist, axis=1, inplace = True)
X = pd.concat([train,dummies], axis =1 )
建立模型
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv('training.csv')
test = pd.read_csv('testing.csv')
# importing linear regression
from sklearnfrom sklearn.linear_model import LinearRegression
lreg = LinearRegression()
# for cross validation
from sklearn.model_selection import train_test_split
X = train.drop('Item_Outlet_Sales',1)
x_train, x_cv, y_train, y_cv = train_test_split(X,train.Item_Outlet_Sales, test_size =0.3)
# training a linear regression model on train
lreg.fit(x_train,y_train)
# predicting on cv
pred_cv = lreg.predict(x_cv)
# calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse
1348171.96
# evaluation using r-square
lreg.score(x_cv,y_cv)
0.54831541460870059
顯然舌仍,我們可以看到妒貌,mse和R-square都有很大的改進(jìn),這意味著我們的模型現(xiàn)在能夠預(yù)測(cè)與實(shí)際值接近的價(jià)值觀铸豁。
為您的模型選擇正確的功能
當(dāng)我們有一個(gè)高維數(shù)據(jù)集時(shí)灌曙,使用所有變量是非常低效的,因?yàn)樗鼈冎械囊恍┛赡軙?huì)傳遞冗余信息节芥。我們需要選擇正確的變量集合在刺,這些變量給出了一個(gè)準(zhǔn)確的模型,并能很好地解釋因變量头镊。有多種方式為模型選擇正確的變量集蚣驼。其中首先是業(yè)務(wù)理解和領(lǐng)域知識(shí)。例如拧晕,在預(yù)測(cè)銷售情況時(shí)隙姿,我們知道營(yíng)銷工作應(yīng)對(duì)銷售產(chǎn)生積極影響,并且是您的模型中的重要特征厂捞。我們還應(yīng)該注意输玷,我們選擇的變量不應(yīng)該在它們之間相互關(guān)聯(lián)。
而不是手動(dòng)選擇變量靡馁,我們可以通過使用向前或向后選擇來自動(dòng)執(zhí)行此過程欲鹏。前向選擇從模型中最重要的預(yù)測(cè)變量開始,并為每個(gè)步驟添加變量臭墨。反向消除從模型中的所有預(yù)測(cè)變量開始赔嚎,并刪除每個(gè)步驟的最不重要的變量。選擇標(biāo)準(zhǔn)可以設(shè)置為任何統(tǒng)計(jì)測(cè)量胧弛,如R平方尤误,t-stat等。
回歸曲調(diào)解釋
看看殘差對(duì)擬合值圖结缚。
residual plot
x_plot = plt.scatter(pred_cv, (pred_cv - y_cv), c='b')
plt.hlines(y=0, xmin= -1000, xmax=5000)
plt.title('Residual plot')

我們可以在情節(jié)中看到一個(gè)像形狀的漏斗损晤。這種形狀表示異方差。在誤差項(xiàng)中存在非常數(shù)方差導(dǎo)致異方差红竭。我們可以清楚地看到誤差項(xiàng)(殘差)的方差不是恒定的尤勋。一般來說,在出現(xiàn)異常值或極度杠桿值的情況下出現(xiàn)非恒定方差茵宪。這些值得到太多的重量最冰,從而不成比例地影響了模型的性能。當(dāng)出現(xiàn)這種現(xiàn)象時(shí)稀火,樣本預(yù)測(cè)的置信區(qū)間往往是不切實(shí)際的寬或窄暖哨。
我們可以通過查看殘差對(duì)擬合值圖來輕松地檢查這一點(diǎn)。如果存在異方差性凰狞,則繪圖將顯示如上所示的漏斗形狀圖案鹿蜀。這表示數(shù)據(jù)中沒有被模型捕獲的非線性的跡象箕慧。我強(qiáng)烈建議您閱讀本文,詳細(xì)了解回歸圖的假設(shè)和解釋茴恰。
為了捕獲這種非線性效應(yīng)颠焦,我們有另一種稱為多項(xiàng)式回歸的回歸。所以讓我們現(xiàn)在明白一下往枣。
多項(xiàng)式回歸
多項(xiàng)式回歸是另一種形式的回歸伐庭,其中自變量的最大冪大于1.在該回歸技術(shù)中,最佳擬合線不是直線分冈,而是以曲線的形式圾另。
二次回歸或二階多項(xiàng)式的回歸由下式給出:
Y =Θ1+Θ2* X +Θ3* X2
現(xiàn)在看下面給出的情節(jié)。

顯然雕沉,二次方程擬合數(shù)據(jù)比簡(jiǎn)單的線性方程更好集乔。在這種情況下,你認(rèn)為二次回歸的R平方值比簡(jiǎn)單的線性回歸如何坡椒?肯定是的扰路,因?yàn)槎位貧w擬合數(shù)據(jù)比線性回歸更好。雖然二次和三次多項(xiàng)式是常見的倔叼,但您也可以添加更高等級(jí)的多項(xiàng)式汗唱。
下圖顯示了6度多項(xiàng)式方程的行為。

那么你認(rèn)為使用更高階多項(xiàng)式來適應(yīng)數(shù)據(jù)集總是更好丈攒×ㄗ铮可悲的是,沒有巡验〖什澹基本上,我們已經(jīng)創(chuàng)建了一個(gè)適合我們的培訓(xùn)數(shù)據(jù)的模型显设,但沒有估計(jì)超出訓(xùn)練集的變量之間的真實(shí)關(guān)系框弛。因此,我們的模型在測(cè)試數(shù)據(jù)上表現(xiàn)不佳敷硅。這個(gè)問題被稱為過擬合。我們也說模型的方差偏高愉阎,偏倚偏低绞蹦。

同樣,我們有一個(gè)叫做另一個(gè)問題欠擬合榜旦,它發(fā)生在我們的模型中沒有適合的訓(xùn)練數(shù)據(jù)幽七,也不推廣上的新數(shù)據(jù)。
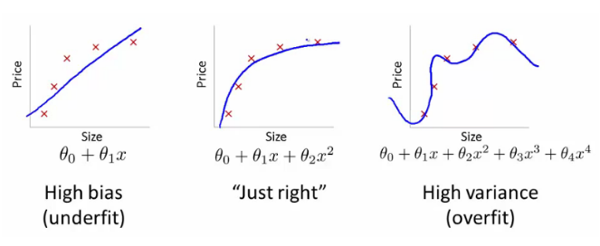
當(dāng)我們有高偏差和低方差時(shí)溅呢,我們的模型是不足的澡屡。
回歸模型的偏差和方差
這個(gè)偏差和方差實(shí)際上是什么意思猿挚?讓我們通過射箭目標(biāo)的例子來理解這一點(diǎn)。

假設(shè)我們的模型是非常準(zhǔn)確的驶鹉,因此我們的模型的誤差將會(huì)很低绩蜻,這意味著低偏差和低方差,如圖所示室埋。所有數(shù)據(jù)點(diǎn)都適合公牛办绝。同樣,我們可以說姚淆,如果方差增加孕蝉,我們的數(shù)據(jù)點(diǎn)的擴(kuò)展增加,這導(dǎo)致不太準(zhǔn)確的預(yù)測(cè)腌逢。隨著偏差的增加降淮,我們的預(yù)測(cè)值和觀測(cè)值之間的誤差也增加。
現(xiàn)在這個(gè)偏差和方差是如何平衡的有一個(gè)完美的模型搏讶?看看下面的圖片佳鳖,并嘗試了解。

隨著我們?cè)谀P椭性黾釉絹碓蕉嗟膮?shù)窍蓝,其復(fù)雜性增加腋颠,導(dǎo)致方差增加和偏差減小,即過度擬合吓笙。因此淑玫,我們需要在我們的模型中找出一個(gè)最優(yōu)點(diǎn),其中偏差的減少等于方差的增加面睛。在實(shí)踐中絮蒿,沒有分析方法來找到這一點(diǎn)。那么如何處理高偏差或高偏差呢叁鉴?
為了克服欠擬合或高偏差土涝,我們基本上可以為我們的模型添加新的參數(shù),使得模型的復(fù)雜性增加幌墓,從而減少高偏差但壮。
現(xiàn)在,我們?nèi)绾慰朔^擬合的回歸模型常侣?
基本上有兩種方法來克服過擬合蜡饵,
降低模型復(fù)雜度
正則
在這里,我們將詳細(xì)討論正則化胳施,以及如何使用它來使您的模型更加一般化溯祸。
正規(guī)化
你有你的模型準(zhǔn)備好了,你已經(jīng)預(yù)測(cè)了你的輸出。那你為什么要學(xué)習(xí)正規(guī)化呢焦辅?有必要嗎博杖?
假設(shè)你參加了比賽,在這個(gè)問題上你需要預(yù)測(cè)一個(gè)連續(xù)變量筷登。所以你應(yīng)用線性回歸并預(yù)測(cè)你的輸出剃根。瞧!你在排行榜上仆抵。但等待你看到的排行榜上還有很多人在你身上跟继。但是你做了一切正確的,那怎么可能呢镣丑?
“一切都應(yīng)該盡可能簡(jiǎn)單舔糖,但不要簡(jiǎn)單 - 愛因斯坦愛因斯坦”
我們做的更簡(jiǎn)單,其他所有人都這樣做莺匠,現(xiàn)在讓我們看看簡(jiǎn)單金吗。這就是為什么我們將嘗試在正規(guī)化的幫助下優(yōu)化我們的代碼。
在正則化中趣竣,我們所做的是通常我們保持相同數(shù)量的特征摇庙,但是減小系數(shù)j的大小。減少系數(shù)如何有助于我們遥缕?
我們來看看我們上述回歸模型中的特征系數(shù)卫袒。
checking the magnitude of coefficients
predictors = x_train.columns
coef = Series(lreg.coef_,predictors).sort_values()
coef.plot(kind='bar', title='Modal Coefficients')
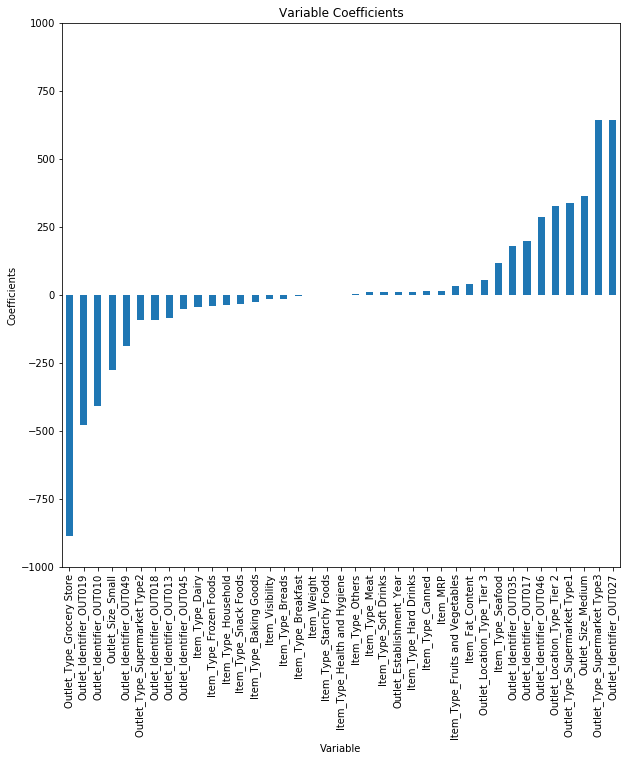
我們可以看到Outlet_Identifier_OUT027和Outlet_Type_Supermarket_Type3(最后2)的系數(shù)與其余系數(shù)相比要高得多。因此单匣,這兩個(gè)功能將更多地推動(dòng)項(xiàng)目的總銷售額夕凝。
我們?nèi)绾螠p小我們模型中系數(shù)的大小户秤?為此码秉,我們有不同類型的回歸技術(shù),使用正則化來克服這個(gè)問題鸡号。所以讓我們討論一下转砖。
嶺回歸
我們首先對(duì)我們的上述問題進(jìn)行實(shí)施,并檢查我們的結(jié)果是否比線性回歸模型更好鲸伴。
from sklearn.linear_modelimport Ridge
## training the model
ridgeReg = Ridge(alpha=0.05, normalize=True)
ridgeReg.fit(x_train,y_train)
pred = ridgeReg.predict(x_cv)
calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse1348171.96## calculating scoreridgeReg.score(x_cv,y_cv)0.5691
所以府蔗,我們可以看到,由于R-Square的價(jià)值增加汞窗,我們的模型略有改善姓赤。請(qǐng)注意,Alpha的值是Ridge的超參數(shù)杉辙,這意味著它們不會(huì)被模型自動(dòng)學(xué)習(xí)模捂,而是必須手動(dòng)設(shè)置。
這里我們考慮α= 0.05蜘矢。但是讓我們考慮不同的α值狂男,并繪制每種情況的系數(shù)。

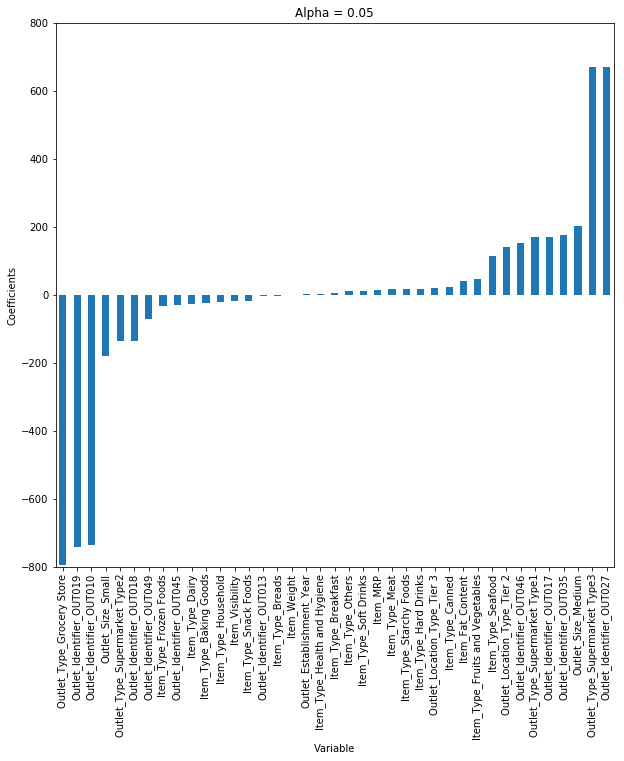
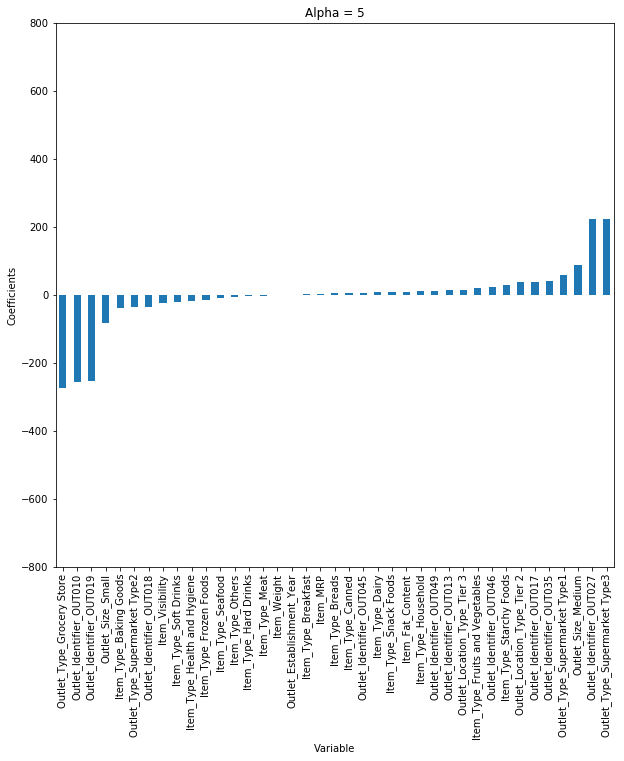

您可以看到品腹,當(dāng)我們?cè)黾应恋闹禃r(shí)岖食,系數(shù)的幅度減小,其中值達(dá)到零但不是絕對(duì)零舞吭。
但是泡垃,如果您計(jì)算每個(gè)alpha的R平方,我們將看到在α= 0.05時(shí)R平方的值將是最大值羡鸥。所以我們必須明智地選擇它蔑穴,通過遍歷一系列值,并使用給我們最低錯(cuò)誤的值惧浴。
所以存和,現(xiàn)在你有一個(gè)想法如何實(shí)現(xiàn)它,但讓我們來看看數(shù)學(xué)方面。到目前為止,我們的想法是基本上最小化成本函數(shù)帅容,使得預(yù)測(cè)的值更接近于期望的結(jié)果护蝶。
現(xiàn)在再次回顧一下脊線回歸的成本函數(shù)。

在這里桥狡,如果你注意到,我們遇到一個(gè)額外的術(shù)語(yǔ),這被稱為懲罰術(shù)語(yǔ)宪祥。這里給出的λ實(shí)際上由脊函數(shù)中的α參數(shù)表示。所以通過改變?chǔ)恋闹抵砼ィ覀兓旧暇褪强刂屏P球品山。α值越高,懲罰越大烤低,因此系數(shù)的幅度就越小肘交。
重點(diǎn):
它縮小了參數(shù),因此它主要用于防止多重共線性扑馁。
它通過系數(shù)收縮降低了模型的復(fù)雜性涯呻。
它使用L2正則化技術(shù)。(我將在本文后面討論)
現(xiàn)在讓我們考慮另一種也利用正則化的回歸技術(shù)腻要。
拉索回歸
LASSO(最小絕對(duì)收縮算子)與山脊非常相似复罐,但我們可以通過在我們的大型市場(chǎng)問題中實(shí)現(xiàn)它們來區(qū)分它們。
from sklearn.linear_model import Lasso
lassoReg = Lasso(alpha=0.3, normalize=True)
lassoReg.fit(x_train,y_train)
pred = lassoReg.predict(x_cv)
# calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse
1346205.82
lassoReg.score(x_cv,y_cv)
0.5720
我們可以看到雄家,我們的模型的Mse和R平方的值都增加了效诅。因此,套索模型預(yù)測(cè)比線性和脊線都好。
再次讓我們改變alpha的值乱投,看看它是如何影響系數(shù)的咽笼。

所以,我們可以看到戚炫,即使在α值較小的情況下剑刑,系數(shù)的大小也減少了很多。通過看地塊双肤,你能看出山脊和套索之間的區(qū)別嗎施掏?
我們可以看到,隨著我們?cè)黾应恋闹得┟樱禂?shù)接近零七芭,但是如果你看到套索的情況,即使在較小的α蔑赘,我們的系數(shù)也減少到絕對(duì)零抖苦。因此,套索選擇唯一的一些特征米死,同時(shí)將他人的系數(shù)降低到零锌历。這個(gè)屬性被稱為特征選擇,在脊的情況下是不存在的峦筒。
拉索回歸后的數(shù)學(xué)與山脊相似究西,靜止不同,而不是加上theta的平方物喷,我們將加上Θ的絕對(duì)值卤材。
在這里,λ是超儀峦失,其值等于拉索函數(shù)中的α扇丛。
重點(diǎn):
它使用L1正則化技術(shù)(將在本文后面討論)
當(dāng)我們擁有更多的功能時(shí),通常使用它尉辑,因?yàn)樗鼤?huì)自動(dòng)進(jìn)行功能選擇帆精。
現(xiàn)在您已經(jīng)對(duì)脊和套索回歸有了基本了解,我們來看一個(gè)例子隧魄,我們有一個(gè)大的數(shù)據(jù)集卓练,可以說它有10,000個(gè)特征。我們知道一些獨(dú)立的功能與其他獨(dú)立功能相關(guān)购啄。然后想想襟企,你會(huì)使用哪種回歸,Rigde或Lasso狮含?
讓我們一一討論一下顽悼。如果我們應(yīng)用脊回歸曼振,它將保留所有的特征,但會(huì)縮小系數(shù)蔚龙。但是問題是拴测,模型仍將保持復(fù)雜,因?yàn)橛?0,000個(gè)功能府蛇,因此可能導(dǎo)致模型性能不佳。
而不是如果我們應(yīng)用套索回歸這個(gè)問題怎么辦屿愚?套索回歸的主要問題是當(dāng)我們有相關(guān)變量時(shí)汇跨,它只保留一個(gè)變量,并將其他相關(guān)變量設(shè)置為零妆距。這可能會(huì)導(dǎo)致信息丟失穷遂,導(dǎo)致我們的模型的準(zhǔn)確性降低。
那么這個(gè)問題的解決方案是什么娱据?實(shí)際上蚪黑,我們有另一種類型的回歸,稱為彈性網(wǎng)回歸中剩,其基本上是脊和套索回歸的混合忌穿。所以讓我們?cè)囍チ私庖幌隆?/p>
彈性網(wǎng)回歸
在進(jìn)入理論部分之前,讓我們?cè)诖笮褪袌?chǎng)銷售問題上實(shí)施结啼。它會(huì)比山脊和套索好嗎掠剑?讓我們檢查!
from sklearn.linear_model import ElasticNet
ENreg = ElasticNet(alpha=1, l1_ratio=0.5, normalize=False)
ENreg.fit(x_train,y_train)
pred_cv = ENreg.predict(x_cv)
#calculating mse
mse = np.mean((pred_cv - y_cv)**2)
mse1773750.73
ENreg.score(x_cv,y_cv)
0.4504
所以我們得到了R-Square的價(jià)值郊愧,它比山脊和套索還要小朴译。你能想到為什么嗎這個(gè)垮臺(tái)背后的原因基本上是沒有一大堆功能。當(dāng)我們有一個(gè)大數(shù)據(jù)集時(shí)属铁,彈性回歸通常會(huì)很好眠寿。
注意,這里我們有兩個(gè)參數(shù)alpha和l1_ratio焦蘑。首先讓我們討論一下盯拱,彈性網(wǎng)中會(huì)發(fā)生什么,以及它與脊和套索的不同之處例嘱。
彈性網(wǎng)基本上是L1和L2正則化的組合坟乾。所以如果你知道彈性網(wǎng),你可以通過調(diào)整參數(shù)來實(shí)現(xiàn)Ridge和Lasso蝶防。所以它使用L1和L2的兩性術(shù)語(yǔ)甚侣,因此它的方程式如下:

那么我們?nèi)绾握{(diào)整羔羊來控制L1和L2懲罰項(xiàng)?讓我們以一個(gè)例子了解间学。你正在試圖從池塘里撈一條魚殷费。你只有一個(gè)網(wǎng)印荔,那么你會(huì)做什么?你會(huì)隨機(jī)扔你的網(wǎng)嗎详羡?不仍律,你真的會(huì)等到你看到一條魚在游泳的時(shí)候,然后你會(huì)把網(wǎng)向這個(gè)方向实柠,基本上收集整個(gè)魚群水泉。因此,即使相關(guān)窒盐,我們?nèi)匀幌肟纯此麄兊恼麄€(gè)團(tuán)體草则。
彈性回歸的工作方式類似。假設(shè)我們?cè)跀?shù)據(jù)集中有一堆相關(guān)的自變量蟹漓,那么彈性網(wǎng)將簡(jiǎn)單地形成一個(gè)由這些相關(guān)變量組成的組】缓幔現(xiàn)在,如果這個(gè)組中的任何一個(gè)變量是一個(gè)強(qiáng)大的預(yù)測(cè)因子(意味著與因變量有很強(qiáng)的關(guān)系)葡粒,那么我們將把整個(gè)組包括在模型構(gòu)建中份殿,因?yàn)槭÷云渌兞浚ň拖裎覀冊(cè)谔姿髦凶龅哪菢樱?dǎo)致在解釋能力方面失去一些信息,導(dǎo)致模型表現(xiàn)不佳嗽交。
所以卿嘲,如果你看上面的代碼,我們需要在定義模型時(shí)定義alpha和l1_ratio夫壁。Alpha和l1_ratio是您可以相應(yīng)設(shè)置的參數(shù)腔寡,如果您想分別控制L1和L2懲罰。其實(shí)我們有
α= a + b和l1_ratio = a /(a + b)
其中掌唾,a和b分別分配給L1和L2項(xiàng)放前。所以當(dāng)我們改變alpha和l1_ratio的值時(shí),a和b被設(shè)置為使得它們控制L1和L2之間的權(quán)衡:
a *(L1項(xiàng))+ b *(L2項(xiàng))
讓?duì)粒ɑ騛 + b)= 1糯彬,現(xiàn)在考慮以下情況:
如果l1_ratio = 1凭语,那么如果我們看l1_ratio的公式,我們可以看到撩扒,如果a = 1似扔,則l1_ratio只能等于1,這意味著b = 0搓谆。因此炒辉,這將是一個(gè)套索。
類似地泉手,如果l1_ratio = 0黔寇,則暗示a = 0。那么懲罰將是一個(gè)山脊懲罰斩萌。
對(duì)于l1_ratio在0和1之間缝裤,懲罰是脊和套索的組合屏轰。
所以讓我們來調(diào)整alpha和l1_ratio,并嘗試從下面給出的系數(shù)圖中理解憋飞。


現(xiàn)在霎苗,您對(duì)脊,套索和彈性網(wǎng)回歸有基本的了解榛做。但在此期間唁盏,我們遇到了兩個(gè)L1和L2,這兩個(gè)方面基本上是正則化的兩種检眯±謇蓿總而言之,基本上來說轰传,套索和山脊分別是L1和L2正則化的直接應(yīng)用。
但如果你還想知道瘪撇,下面我已經(jīng)解釋了他們背后的概念获茬,這是可選的。
14.正規(guī)化技術(shù)的類型[可選]
讓我們回想一下倔既,無(wú)論是山脊還是套索恕曲,我們都添加了一個(gè)懲罰術(shù)語(yǔ),但是在這兩種情況下都是不同的渤涌。在脊中佩谣,我們使用theta的平方而在套索中我們使用了θ的絕對(duì)值。那么為什么這兩個(gè)只有实蓬,不能有其他的可能性茸俭?
實(shí)際上,在正則化項(xiàng)中參數(shù)的不同選擇順序有不同的可能的正則化選擇
安皱。這通常被稱為L(zhǎng)p正則劑调鬓。

讓我們嘗試通過繪制它們來可視化一些。為了使可視化變得容易酌伊,我們可以將它們繪制在2D空間中腾窝。為此,我們假設(shè)我們只有兩個(gè)參數(shù)【幼現(xiàn)在虹脯,假設(shè)p = 1,我們有一個(gè)術(shù)語(yǔ)
奏候。我們不能繪制這條線的方程循集?下面給出了p的不同值的類似圖。

在上面的圖中蔗草,軸表示參數(shù)(θ1和θ2)暇榴。讓我們逐一檢查一下厚棵。
對(duì)于p = 0.5,只有當(dāng)其他參數(shù)太小時(shí)蔼紧,才能獲得一個(gè)參數(shù)的大值婆硬。對(duì)于p = 1,我們得到絕對(duì)值的和奸例,其中一個(gè)參數(shù)Θ的增加被其他的減小精確地抵消彬犯。對(duì)于p = 2,我們得到一個(gè)圓查吊,對(duì)于較大的p值谐区,它接近圓形正方形。
兩個(gè)最常用的正則化是我們有p = 1和p = 2逻卖,更常被稱為L(zhǎng)1和L2正則化宋列。
仔細(xì)看下面給出的圖。藍(lán)色的形狀是指正則化項(xiàng)评也,其他形狀是指我們的最小二乘誤差(或數(shù)據(jù)項(xiàng))炼杖。
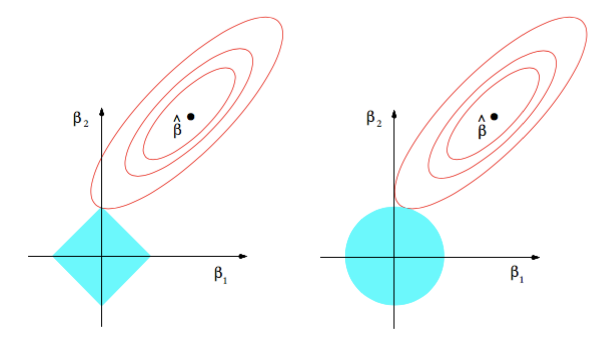
第一個(gè)數(shù)字是L1,第二個(gè)是L2正則化盗迟。黑點(diǎn)表示在該點(diǎn)處最小二乘誤差最小化坤邪,并且我們可以看到它隨著它的移動(dòng)而二次增加,并且正則化項(xiàng)在所有參數(shù)為零的原點(diǎn)被最小化罚缕。
現(xiàn)在的問題是艇纺,我們的成本功能在什么時(shí)候是最小的?答案將是邮弹,因?yàn)樗鼈兪嵌卧黾拥那猓赃@兩個(gè)術(shù)語(yǔ)的和將在它們首先相交的點(diǎn)被最小化。
看看L2正則化曲線腌乡。由于L2正則化器形成的形狀是一個(gè)圓形员帮,所以隨著我們離開它,它逐漸增加导饲。只有當(dāng)最小MSE(圖中的均方誤差或黑點(diǎn))也正好位于軸上時(shí)捞高,L2最優(yōu)(基本上是交點(diǎn))才能落在軸線上。但是在L1的情況下渣锦,L1最優(yōu)可以在軸線上硝岗,因?yàn)樗妮喞卿h利的,因此相互作用點(diǎn)的機(jī)會(huì)很大袋毙。因此型檀,即使最小MSE不在軸上,也可以在軸線上相交听盖。如果交點(diǎn)落在軸上胀溺,則稱為稀疏裂七。
因此,L1提供了一定程度的稀疏性仓坞,這使得我們的模型更有效地存儲(chǔ)和計(jì)算背零,并且還可以幫助檢查特征的重要性,因?yàn)椴恢匾奶卣骺梢跃_地設(shè)置為零无埃。
結(jié)束筆記
我希望現(xiàn)在你可以理解線性回歸背后的科學(xué)徙瓶,以及如何實(shí)現(xiàn)它,進(jìn)一步優(yōu)化它以改善模型嫉称。
“知識(shí)是寶藏侦镇,實(shí)踐是關(guān)鍵”
因此,通過解決一些問題讓你的手變臟织阅。您也可以從Big Mart銷售問題開始壳繁,并嘗試通過一些功能工程來改進(jìn)您的模型。如果在實(shí)施過程中面臨任何困難荔棉,請(qǐng)隨時(shí)在我們的討論門戶上寫信闹炉。
你覺得這篇文章有幫助嗎?請(qǐng)?jiān)谙旅娴脑u(píng)論部分分享您的意見/想法江耀。
