字符編碼(英語(yǔ):Character encoding)、字集碼是把字符集中的字符編碼為指定集合中某一對(duì)象(例如:比特模式、自然數(shù)序列、8位組或者電脈沖)斥赋,以便文本在計(jì)算機(jī)中存儲(chǔ)和通過(guò)通信網(wǎng)絡(luò)的傳遞。計(jì)算機(jī)中的字符編碼算是一個(gè)歷史遺留性問(wèn)題产艾,因?yàn)楦鱾€(gè)國(guó)家種族對(duì)應(yīng)著不同的問(wèn)題疤剑,以及各個(gè)組織機(jī)構(gòu)推出不同的標(biāo)準(zhǔn),因此現(xiàn)在計(jì)算機(jī)中的字符編碼格式繁多闷堡。
打開(kāi)某網(wǎng)頁(yè)隘膘,或者用記事本打開(kāi)某文本文件時(shí),我們可能會(huì)看到一堆的亂碼如"б?ЯАзЪСЯ"杠览、"?????????"弯菊,出現(xiàn)這種問(wèn)題,往往是我們選用的字符編碼不對(duì)踱阿。
簡(jiǎn)介
計(jì)算機(jī)中儲(chǔ)存的信息都是用二進(jìn)制數(shù)表示的管钳;而我們?cè)谄聊簧峡吹降挠⑽摹h字等字符是二進(jìn)制數(shù)轉(zhuǎn)換之后的結(jié)果软舌。也就是說(shuō)才漆,我們?cè)谟?jì)算機(jī)中存儲(chǔ)數(shù)據(jù)時(shí),字母 'a' 需要用什么二進(jìn)制來(lái)表示佛点,這便稱(chēng)為"編碼"醇滥;反之,將存儲(chǔ)在計(jì)算機(jī)中的二進(jìn)制數(shù)解析顯示出來(lái)恋脚,稱(chēng)為"解碼"腺办,如同密碼學(xué)中的加密和解密焰手。而如果在解碼過(guò)程中我們使用了錯(cuò)誤的規(guī)則糟描,則會(huì)導(dǎo)致解碼錯(cuò)誤 'a' 變成了 '0'。
字符集(Charset):是一個(gè)系統(tǒng)支持的所有抽象字符的集合书妻。字符是各種文字和符號(hào)的總稱(chēng)船响,包括各國(guó)家文字躬拢、標(biāo)點(diǎn)符號(hào)、圖形符號(hào)见间、數(shù)字等聊闯。
字符編碼(Character Encoding):是一套法則,使用該法則能夠?qū)ψ匀徽Z(yǔ)言的字符的一個(gè)集合(如字母表或音節(jié)表)米诉,與其他東西的一個(gè)集合(如號(hào)碼或電脈沖)進(jìn)行配對(duì)菱蔬。即在符號(hào)集合與數(shù)字系統(tǒng)之間建立對(duì)應(yīng)關(guān)系,它是信息處理的一項(xiàng)基本技術(shù)史侣。通常人們用符號(hào)集合(一般情況下就是文字)來(lái)表達(dá)信息拴泌。而以計(jì)算機(jī)為基礎(chǔ)的信息處理系統(tǒng)則是利用元件(硬件)不同狀態(tài)的組合來(lái)存儲(chǔ)和處理信息的。元件不同狀態(tài)的組合能代表數(shù)字系統(tǒng)的數(shù)字惊橱,因此字符編碼就是將符號(hào)轉(zhuǎn)換為計(jì)算機(jī)可以接受的數(shù)字系統(tǒng)的數(shù)蚪腐,稱(chēng)為數(shù)字代碼。
常用編碼
常見(jiàn)字符編碼為:ASCII,GB2312,UTF-8,Unicode,Big5等税朴,下面我們對(duì)其中一些詳細(xì)闡述回季。
ASCII
ASCII(1963年)和EBCDIC(1964年)這樣的字符集逐漸成為標(biāo)準(zhǔn)。最早的時(shí)候計(jì)算機(jī)ASCII碼只能表示256個(gè)符號(hào)(含控制符號(hào))正林,這個(gè)字符集表示英文字母足夠泡一。使用7位(bits)表示一個(gè)字符,共128字符觅廓;但是7位編碼的字符集只能支持128個(gè)字符瘾杭,為了表示更多的歐洲常用字符對(duì)ASCII進(jìn)行了擴(kuò)展,我們通常成為擴(kuò)展 ASCII 碼哪亿,其使用 8位(bits)表示一個(gè)字符粥烁,共256字符。
一般標(biāo)準(zhǔn) ASCII 碼是每個(gè)學(xué)計(jì)算機(jī)的人必須知道和了解的蝇棉,對(duì)常用的一些字符所表示的二進(jìn)制能夠非常熟悉讨阻,例如:(0-9)->(0x30-0x39) (A-Z)->(0x41-0x5A) (a-z)->(0x61-7A) NULL->(0x00) 等。
雖然 ASCII 的使用范圍很廣篡殷,但表示漢字钝吮、日語(yǔ)、韓語(yǔ)就不太夠用了板辽,漢字常用字有3000多個(gè)奇瘦。這些字符集的局限很快就變得明顯,于是人們開(kāi)發(fā)了許多方法來(lái)擴(kuò)展它們劲弦,于是就有了其他一些新興字符集的出現(xiàn)耳标。
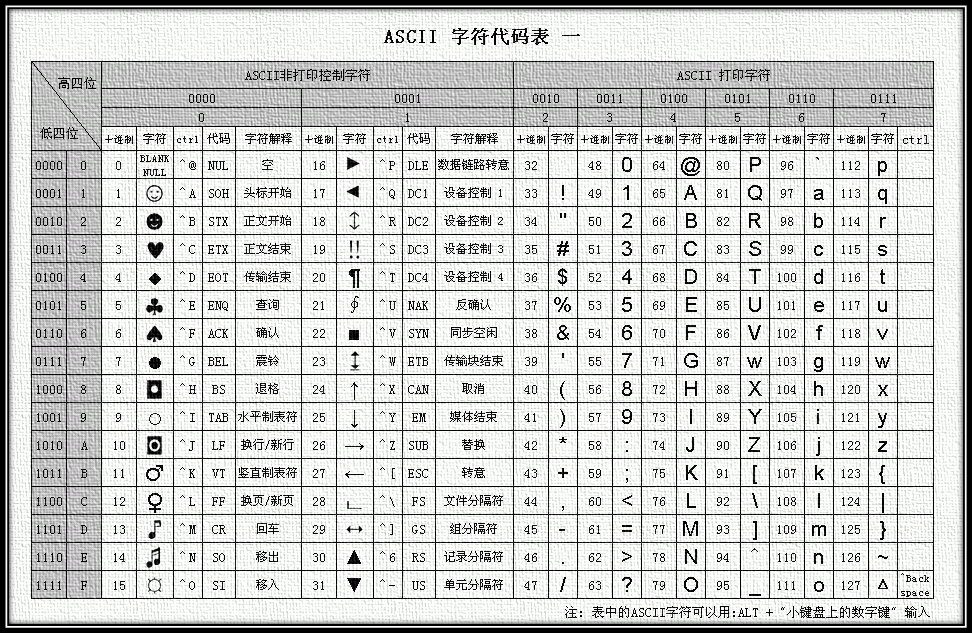
GB2312
計(jì)算機(jī)發(fā)明之處及后面很長(zhǎng)一段時(shí)間,只用應(yīng)用于美國(guó)及西方一些發(fā)達(dá)國(guó)家邑跪,ASCII能夠很好滿足用戶的需求次坡。但對(duì)于亞洲眾多國(guó)家來(lái)說(shuō)并不適用呼猪,當(dāng)計(jì)算機(jī)傳入我國(guó)后,為了顯示中文砸琅,必須設(shè)計(jì)一套編碼規(guī)則用于將漢字轉(zhuǎn)換為計(jì)算機(jī)可以接受的數(shù)字系統(tǒng)的數(shù)宋距。
于是國(guó)內(nèi)指定了國(guó)標(biāo) GB2312(中國(guó)國(guó)家標(biāo)準(zhǔn)簡(jiǎn)體中文字符集),全稱(chēng)《信息交換用漢字編碼字符集·基本集》症脂,又稱(chēng)GB0谚赎,由中國(guó)國(guó)家標(biāo)準(zhǔn)總局發(fā)布,1981年5月1日實(shí)施诱篷。GB2312編碼通行于中國(guó)大陸沸版;新加坡等地也采用此編碼。
中國(guó)大陸幾乎所有的中文系統(tǒng)和國(guó)際化的軟件都支持GB2312兴蒸。GB2312的出現(xiàn)视粮,基本滿足了漢字的計(jì)算機(jī)處理需要,它所收錄的漢字已經(jīng)覆蓋中國(guó)大陸99.75%的使用頻率橙凳。對(duì)于人名蕾殴、古漢語(yǔ)等方面出現(xiàn)的罕用字,GB2312不能處理岛啸,這導(dǎo)致了后來(lái)GBK及GB 18030漢字字符集的出現(xiàn)钓觉。
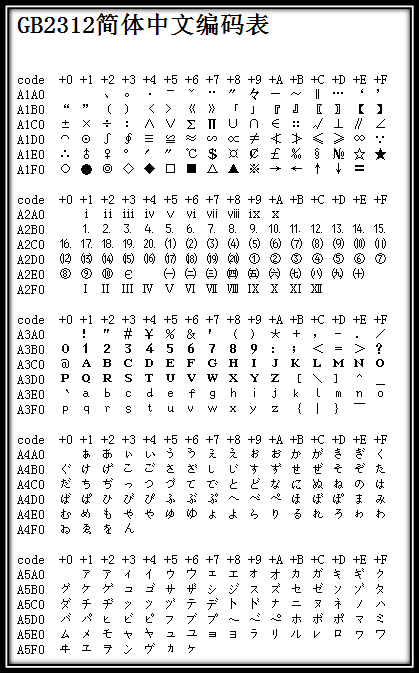
GB2312 定義的規(guī)則如下:一個(gè)小于 127 的字符的意義與原來(lái)相同(即:兼容 ASCII 碼標(biāo)準(zhǔn)),但兩個(gè)大于 127 的字符連在一起時(shí)坚踩,就表示一個(gè)漢字荡灾,前面的一個(gè)字節(jié)(他稱(chēng)之為高字節(jié))從 0xA1 用到 0xF7,后面一個(gè)字節(jié)(低字節(jié))從 0xA1 到 0xFE瞬铸,這樣我們就可以組合出大約 7000 多個(gè)簡(jiǎn)體漢字了批幌,GB2312 是對(duì) ASCII 的中文擴(kuò)展。
在這些編碼里嗓节,還把數(shù)學(xué)符號(hào)荧缘、羅馬希臘的 字母、日文的假名們都編進(jìn)去了拦宣,連在 ASCII 里本來(lái)就有的數(shù)字截粗、標(biāo)點(diǎn)、字母都統(tǒng)統(tǒng)重新編了兩個(gè)字節(jié)長(zhǎng)的編碼鸵隧,這就是常說(shuō)的"全角"字符绸罗,而原來(lái)在 127 號(hào)以下的那些就叫"半角"字符了,也就不難看出為何我們平時(shí)選用全角輸入數(shù)字字母時(shí)豆瘫,會(huì)發(fā)現(xiàn)樣式變寬了珊蟀,占用了多個(gè)位置,這也是因?yàn)椴捎萌呛竺蚁郏總€(gè)字符占用了兩個(gè)字節(jié)系洛,一般我應(yīng)該要避免使用這種情況輸入俊性。
GB2312 后來(lái)發(fā)現(xiàn)還是不夠用略步,于是干脆不再要求低字節(jié)一定是127號(hào)之后的內(nèi)碼描扯,只要第一個(gè)字節(jié)是大于127就固定表示這是一個(gè)漢字的開(kāi)始,不管后面跟的是不是擴(kuò)展字符集里的內(nèi)容趟薄。結(jié)果擴(kuò)展之后的編碼方案被稱(chēng)為 GBK 標(biāo)準(zhǔn)绽诚,GBK 包括了 GB2312 的所有內(nèi)容,同時(shí)又增加了近 20000 個(gè)新的漢字(包括繁體字)和符號(hào)杭煎。后來(lái)少數(shù)民族也要用電腦了恩够,于是我們?cè)贁U(kuò)展,又加了幾千個(gè)新的少數(shù)民族的字羡铲,GBK 擴(kuò)成了 GB18030蜂桶。
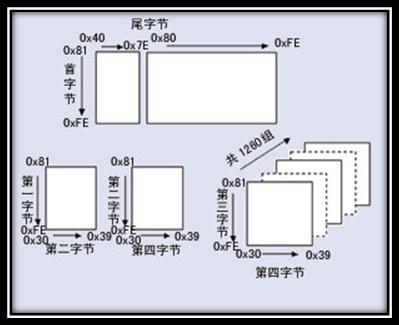
Big5
Big5,又稱(chēng)為大五碼或五大碼也切,是使用繁體中文(正體中文)社區(qū)中最常用的電腦漢字字符集標(biāo)準(zhǔn)扑媚,共收錄13,060個(gè)漢字。Big5雖普及于臺(tái)灣雷恃、香港與澳門(mén)等繁體中文通行區(qū)疆股,但長(zhǎng)期以來(lái)并非當(dāng)?shù)氐膰?guó)家標(biāo)準(zhǔn),而只是業(yè)界標(biāo)準(zhǔn)倒槐。Big5碼是一套雙字節(jié)字符集旬痹,使用了雙八碼存儲(chǔ)方法,以?xún)蓚€(gè)字節(jié)來(lái)安放一個(gè)字讨越。第一個(gè)字節(jié)稱(chēng)為"高位字節(jié)"两残,第二個(gè)字節(jié)稱(chēng)為"低位字節(jié)"。"高位字節(jié)"使用了0x81-0xFE把跨,"低位字節(jié)"使用了0x40-0x7E磕昼,及0xA1-0xFE。這邊不再對(duì)該編碼做過(guò)多的介紹节猿。
Unicode
Unicode(統(tǒng)一碼票从、萬(wàn)國(guó)碼、單一碼)是計(jì)算機(jī)科學(xué)領(lǐng)域里的一項(xiàng)業(yè)界標(biāo)準(zhǔn),包括字符集滨嘱、編碼方案等峰鄙。Unicode 是為了解決傳統(tǒng)的字符編碼方案的局限而產(chǎn)生的,它為每種語(yǔ)言中的每個(gè)字符設(shè)定了統(tǒng)一并且唯一的二進(jìn)制編碼太雨,以滿足跨語(yǔ)言吟榴、跨平臺(tái)進(jìn)行文本轉(zhuǎn)換、處理的要求囊扳。1990年開(kāi)始研發(fā)吩翻,1994年正式公布兜看。
Unicode當(dāng)然是一個(gè)很大的集合,現(xiàn)在的規(guī)南料梗可以容納100多萬(wàn)個(gè)符號(hào)细移。每個(gè)符號(hào)的編碼都不一樣,比如熊锭,U+0639表示阿拉伯字母Ain弧轧,U+0041表示英語(yǔ)的大寫(xiě)字母A,U+4E25表示漢字"嚴(yán)"碗殷。具體的符號(hào)對(duì)應(yīng)表精绎,可以查詢(xún)unicode.org,或者專(zhuān)門(mén)的漢字對(duì)應(yīng)表锌妻。
從unicode開(kāi)始代乃,無(wú)論是半角的英文字母,還是全角的漢字仿粹,它們都是統(tǒng)一的一個(gè)字符(并不是一個(gè)字節(jié)搁吓,而是兩個(gè)字節(jié))。在unicode中牍陌,一個(gè)字符就是兩個(gè)字節(jié)擎浴,一個(gè)漢字不再類(lèi)似于 GB2312 中當(dāng)作兩個(gè)字符來(lái)處理了。
unicode同樣有著自身的問(wèn)題毒涧,一個(gè)是贮预,如何才能區(qū)別 unicode 和 ascii 。計(jì)算機(jī)如何知道三個(gè)字節(jié)表示一個(gè)符號(hào)契讲,而不是分別表示三個(gè)符號(hào)呢仿吞?二是,我們已經(jīng)知道捡偏,英文字母只用一個(gè)字節(jié)表示就夠了唤冈,如果unicode統(tǒng)一規(guī)定,每個(gè)符號(hào)用三個(gè)或四個(gè)字節(jié)表示银伟,那么每個(gè)英文字母前都必然有二到三個(gè)字節(jié)是 0你虹,這對(duì)于過(guò)去計(jì)算機(jī)來(lái)說(shuō)存儲(chǔ)空間極為珍貴,而這樣做無(wú)疑造成了極大的浪費(fèi)彤避,文本文件的大小會(huì)因此大出兩三倍傅物,這是難以接受的。
unicode在很長(zhǎng)一段時(shí)間內(nèi)無(wú)法推廣琉预,直到互聯(lián)網(wǎng)的出現(xiàn)董饰,為解決unicode如何在網(wǎng)絡(luò)上傳輸?shù)膯?wèn)題,于是面向傳輸?shù)谋姸?UTF(UCS Transfer Format)標(biāo)準(zhǔn)出現(xiàn)了。UTF-8 就是每次8個(gè)位傳輸數(shù)據(jù)卒暂,而UTF-16就是每次16個(gè)位傳輸啄栓。UTF-8 就是在互聯(lián)網(wǎng)上使用最廣的一種 unicode 的實(shí)現(xiàn)方式,這是為傳輸而設(shè)計(jì)的編碼也祠,并使編碼無(wú)國(guó)界昙楚,這樣就可以顯示全世界上所有文化的字符了。
可以這樣理解:Unicode是字符集齿坷,UTF-32/ UTF-16/ UTF-8是三種字符編碼方案桂肌。
UTF-8
互聯(lián)網(wǎng)的普及数焊,強(qiáng)烈要求出現(xiàn)一種統(tǒng)一的編碼方式永淌。UTF-8就是在互聯(lián)網(wǎng)上使用最廣的一種Unicode的實(shí)現(xiàn)方式。其他實(shí)現(xiàn)方式還包括UTF-16(字符用兩個(gè)字節(jié)或四個(gè)字節(jié)表示)和UTF-32(字符用四個(gè)字節(jié)表示)佩耳,不過(guò)在互聯(lián)網(wǎng)上基本不用遂蛀。重復(fù)一遍,這里的關(guān)系是干厚,UTF-8是Unicode的實(shí)現(xiàn)方式之一李滴。
UTF-8 最大的一個(gè)特點(diǎn),就是它是一種變長(zhǎng)的編碼方式蛮瞄。它可以使用1~4個(gè)字節(jié)表示一個(gè)符號(hào)所坯,根據(jù)不同的符號(hào)而變化字節(jié)長(zhǎng)度。
UTF-8 的編碼規(guī)則很簡(jiǎn)單:
- 對(duì)于單字節(jié)的符號(hào)挂捅,字節(jié)的第一位設(shè)為0芹助,后面7位為這個(gè)符號(hào)的 unicode 碼。因此對(duì)于英語(yǔ)字母闲先,UTF-8編碼和ASCII碼是相同的状土。
- 對(duì)于 n 字節(jié)的符號(hào)(n>1),第一個(gè)字節(jié)的前 n 位都設(shè)為 1伺糠,第n+1位設(shè)為0蒙谓,后面字節(jié)的前兩位一律設(shè)為10。剩下的沒(méi)有提及的二進(jìn)制位训桶,全部為這個(gè)符號(hào)的 unicode 碼累驮。
下面是對(duì)比 Unicode 和 UTF-8 的對(duì)比:
| Unicode 符號(hào)范圍 | UTF-8 編碼方式 |
|---|---|
| (十六進(jìn)制) | (二進(jìn)制) |
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
下面,還是以漢字"嚴(yán)"為例舵揭,演示如何實(shí)現(xiàn)UTF-8編碼谤专。已知"嚴(yán)"的unicode是4E25(100111000100101),根據(jù)上表琉朽,可以發(fā)現(xiàn)4E25處在第三行的范圍內(nèi)(0000 0800-0000 FFFF)毒租,因此"嚴(yán)"的UTF-8編碼需要三個(gè)字節(jié),即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后墅垮,從"嚴(yán)"的最后一個(gè)二進(jìn)制位開(kāi)始惕医,依次從后向前填入格式中的 x,多出的位補(bǔ) 0算色。這樣就得到了抬伺,"嚴(yán)"的 UTF-8 編碼是 "11100100 10111000 10100101",轉(zhuǎn)換成十六進(jìn)制就是E4B8A5灾梦。
BOM頭
UTF-8 本來(lái)是兼容性最好的編碼峡钓,但 Windows 偏要加 BOM 于是經(jīng)常出問(wèn)題。
在 utf-8 編碼文件中 BOM 在文件頭部若河,占用三個(gè)字節(jié)能岩,用來(lái)標(biāo)識(shí)該文件屬于 utf-8 編碼,現(xiàn)在已經(jīng)有很多軟件識(shí)別 BOM 頭萧福,但還是有些不能識(shí)別 BOM 頭拉鹃,比如 PHP 就不能識(shí)別 BOM 頭,這也就是用記事本編輯 utf-8 編碼的 PHP 文件后鲫忍,就會(huì)報(bào)錯(cuò)的原因膏燕。
在windows環(huán)境下,用記事本打開(kāi)任何一個(gè)文本文件悟民,另存為utf-8格式后坝辫,這樣文件就自動(dòng)被加上了BOM頭信息。含BOM頭的文件射亏,在文件開(kāi)頭處多出三個(gè)字節(jié) 0xefbbbf近忙。
windows 下一般不建議使用記事本打開(kāi)文本文件,就如上面所提到的原因鸦泳,記事本會(huì)加入 BOM 頭银锻,與此同時(shí),記事本在處理其他平臺(tái)傳過(guò)來(lái)的文本時(shí)還有其他問(wèn)題做鹰,因此計(jì)算機(jī)工作者击纬,編輯文本時(shí),推薦使用 notepad++ 或者 editplus钾麸。這些軟件都可以兼容多個(gè)平臺(tái)的文本文件更振,同時(shí)編輯能力強(qiáng),打開(kāi)速度快饭尝,能夠直接各種格式的編碼肯腕。
To be continued...
https://www.zhihu.com/question/20650946
https://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
http://baike.baidu.com/link?url=HknfN5Mei0ekD1hoPPs-U1osSOA1tDDFYkfPfNa05SNX36LbaAh4ctHt_2XhefTVW03ZCRLaBw1dYpY6iG3-ea
https://www.zhihu.com/question/23374078
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://www.cnblogs.com/lfire/archive/2012/11/20/2778939.html
