定義
Hashmap是map接口的常用實(shí)現(xiàn)類患膛。
Hashmap中put方法的源碼如下:
public V put(K key, V value)
{
// 如果 key 為 null,調(diào)用 putForNullKey 方法進(jìn)行處理
if (key == null)
return putForNullKey(value);
// 根據(jù) key 的 keyCode 計(jì)算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在對(duì)應(yīng) table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引處的 Entry 不為 null,通過(guò)循環(huán)不斷遍歷 e 元素的下一個(gè)元素
for (Entry<K,V> e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 與需要放入的 key 相等(hash 值相同
// 通過(guò) equals 比較放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引處的 Entry 為 null戒祠,表明此處還沒(méi)有 Entry
modCount++;
// 將 key弥臼、value 添加到 i 索引處
addEntry(hash, key, value, i);
return null;
}
上面程序中用到了一個(gè)重要的內(nèi)部接口:Map.Entry,每個(gè) Map.Entry 其實(shí)就是一個(gè) key-value 對(duì)朝群。從上面程序中可以看出:當(dāng)系統(tǒng)決定存儲(chǔ) HashMap 中的 key-value 對(duì)時(shí)燕耿,完全沒(méi)有考慮 Entry 中的 value,僅僅只是根據(jù) key 來(lái)計(jì)算并決定每個(gè) Entry 的存儲(chǔ)位置姜胖。這也說(shuō)明了前面的結(jié)論:我們完全可以把 Map 集合中的 value 當(dāng)成 key 的附屬誉帅,當(dāng)系統(tǒng)決定了 key 的存儲(chǔ)位置之后,value 隨之保存在那里即可。
所以蚜锨,若Hashmap在插入key時(shí)档插,
HashMap會(huì)先用key的hash值來(lái)檢查是否發(fā)生了hash碰撞,也就是對(duì)應(yīng)的位置是否為空踏志。如果原本已經(jīng)存在對(duì)應(yīng)的key阀捅,則直接改變對(duì)應(yīng)的value,并返回舊的value针余,而在判斷key是否存在的時(shí)候是先比較key的hashCode饲鄙,再比較相等或equals的。
Hashmap的構(gòu)造
HashMap 包含如下幾個(gè)構(gòu)造器:
* HashMap():構(gòu)建一個(gè)初始容量為 16圆雁,負(fù)載因子為 0.75 的 HashMap忍级。
* HashMap(int initialCapacity):構(gòu)建一個(gè)初始容量為 initialCapacity,負(fù)載因子為 0.75 的 HashMap伪朽。
* HashMap(int initialCapacity, float loadFactor):以指定初始容量轴咱、指定的負(fù)載因子創(chuàng)建一個(gè) HashMap。
對(duì)于 HashMap 及其子類而言烈涮,它們采用 Hash 算法來(lái)決定集合中元素的存儲(chǔ)位置朴肺。當(dāng)系統(tǒng)開(kāi)始初始化 HashMap 時(shí),系統(tǒng)會(huì)創(chuàng)建一個(gè)長(zhǎng)度為 capacity 的 Entry 數(shù)組坚洽,這個(gè)數(shù)組里可以存儲(chǔ)元素的位置被稱為“桶(bucket)”戈稿,每個(gè) bucket 都有其指定索引,系統(tǒng)可以根據(jù)其索引快速訪問(wèn)該 bucket 里存儲(chǔ)的元素讶舰。
無(wú)論何時(shí)鞍盗,HashMap 的每個(gè)“桶”只存儲(chǔ)一個(gè)元素(也就是一個(gè) Entry),由于 Entry 對(duì)象可以包含一個(gè)引用變量(就是 Entry 構(gòu)造器的的最后一個(gè)參數(shù))用于指向下一個(gè) Entry跳昼,因此可能出現(xiàn)的情況是:HashMap 的 bucket 中只有一個(gè) Entry般甲,但這個(gè) Entry 指向另一個(gè) Entry ——這就形成了一個(gè) Entry 鏈。如圖 1 所示:
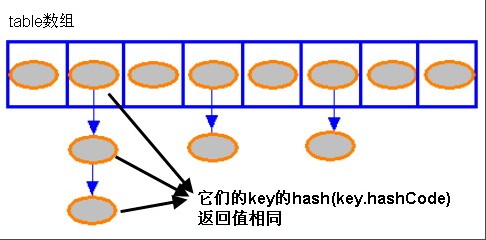
Hashmap的讀取
當(dāng) HashMap 的每個(gè) bucket 里存儲(chǔ)的 Entry 只是單個(gè) Entry ——也就是沒(méi)有通過(guò)指針產(chǎn)生 Entry 鏈時(shí)鹅颊,此時(shí)的 HashMap 具有最好的性能:當(dāng)程序通過(guò) key 取出對(duì)應(yīng) value 時(shí)敷存,系統(tǒng)只要先計(jì)算出該 key 的 hashCode() 返回值,在根據(jù)該 hashCode 返回值找出該 key 在 table 數(shù)組中的索引堪伍,然后取出該索引處的 Entry历帚,最后返回該 key 對(duì)應(yīng)的 value 即可「苡椋看 HashMap 類的 get(K key) 方法代碼:
public V get(Object key)
{
// 如果 key 是 null,調(diào)用 getForNullKey 取出對(duì)應(yīng)的 value
if (key == null)
return getForNullKey();
// 根據(jù)該 key 的 hashCode 值計(jì)算它的 hash 碼
int hash = hash(key.hashCode());
// 直接取出 table 數(shù)組中指定索引處的值谱煤,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜索該 Entry 鏈的下一個(gè) Entr
e = e.next) // ①
{
Object k;
// 如果該 Entry 的 key 與被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}
從上面代碼中可以看出摊求,如果 HashMap 的每個(gè) bucket 里只有一個(gè) Entry 時(shí),HashMap 可以根據(jù)索引刘离、快速地取出該 bucket 里的 Entry室叉;在發(fā)生“Hash 沖突”的情況下睹栖,單個(gè) bucket 里存儲(chǔ)的不是一個(gè) Entry,而是一個(gè) Entry 鏈茧痕,系統(tǒng)只能必須按順序遍歷每個(gè) Entry野来,直到找到想搜索的 Entry 為止——如果恰好要搜索的 Entry 位于該 Entry 鏈的最末端(該 Entry 是最早放入該 bucket 中),那系統(tǒng)必須循環(huán)到最后才能找到該元素踪旷。
由此曼氛,我們可以在創(chuàng)建 HashMap 時(shí)根據(jù)實(shí)際需要適當(dāng)?shù)卣{(diào)整 load factor 的值;如果程序比較關(guān)心空間開(kāi)銷令野、內(nèi)存比較緊張舀患,可以適當(dāng)?shù)卦黾迂?fù)載因子;如果程序比較關(guān)心時(shí)間開(kāi)銷气破,內(nèi)存比較寬裕則可以適當(dāng)?shù)臏p少負(fù)載因子聊浅。
Hashmap的遍歷
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("cn", "中國(guó)");
hashMap.put("jp", "日本");
hashMap.put("fr", "法國(guó)");
System.out.println(hashMap);
System.out.println("cn:" + hashMap.get("cn"));
System.out.println(hashMap.containsKey("cn"));
System.out.println(hashMap.keySet());
System.out.println(hashMap.isEmpty());
hashMap.remove("cn");
System.out.println(hashMap.containsKey("cn"));
//采用Iterator遍歷HashMap
Iterator it = hashMap.keySet().iterator();
while(it.hasNext()) {
String key = (String)it.next();
System.out.println("key:" + key);
System.out.println("value:" + hashMap.get(key));
}
//遍歷HashMap的另一個(gè)方法
Set<Entry<String, String>> sets = hashMap.entrySet();
for(Entry<String, String> entry : sets) {
System.out.print(entry.getKey() + ", ");
System.out.println(entry.getValue());
}
}
}
Maphash中的一些方法
Maphash.keySet獲得map的鍵集合
Maphash中的紅黑樹(shù)(待)
JDK 1.8 以前 HashMap 的實(shí)現(xiàn)是 數(shù)組+鏈表,即使哈希函數(shù)取得再好现使,也很難達(dá)到元素百分百均勻分布低匙。
當(dāng) HashMap 中有大量的元素都存放到同一個(gè)桶中時(shí),這個(gè)桶下有一條長(zhǎng)長(zhǎng)的鏈表碳锈,這個(gè)時(shí)候 HashMap 就相當(dāng)于一個(gè)單鏈表顽冶,假如單鏈表有 n 個(gè)元素,遍歷的時(shí)間復(fù)雜度就是 O(n)殴胧,完全失去了它的優(yōu)勢(shì)渗稍。
針對(duì)這種情況,JDK 1.8 中引入了 紅黑樹(shù)(查找時(shí)間復(fù)雜度為 O(logn))來(lái)優(yōu)化這個(gè)問(wèn)題团滥。
練習(xí)
leetcode no.599
使用哈希索引找最小索引
public class no599 {
public static String[] findRestaurant(String[] list1, String[] list2) {
List<String> buffer = null;
Map<String, Integer> map1 = new HashMap<>();
Map<String, Integer> map2 = new HashMap<>();
int min = Integer.MAX_VALUE;
for(int i = 0; i < list1.length; i++){
map1.put(list1[i], i);
}
for (int i = 0; i < list2.length; i++){
map2.put(list2[i], i);
}
for (int i = 0; i < list1.length; i++){
if(map2.containsKey(list1[i])){
int sum = map1.get(list1[i]) + map2.get(list1[i]);
if(sum < min){
min = sum;
buffer = new ArrayList<String>();
buffer.add(list1[i]);
}
else if(sum == min)
buffer.add(list1[i]);
}
}
return buffer.toArray(new String[buffer.size()]);
}
public static void main(String[] args){
String[] a = {"Shogun", "Tapioca Express", "Burger King", "KFC"};
String[] b = {"KFC", "Shogun", "Burger King"};
System.out.println(Arrays.toString(findRestaurant(a, b)));
}
}
no.594
public class no594 {
public static int findLHS(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++){
// if(!map.containsKey(nums[i]))
// map.put(nums[i], 1);
// else {
int value = map.getOrDefault(nums[i], 0);
value++;
map.put(nums[i], value);
}
int length = 0;
for (int num: map.keySet()){
if(map.containsKey(num + 1))
length = Math.max(length, map.get(num) + map.get(num + 1));
}
return length;
}
public static void main(String[] args){
int[] nums = {1,3,2,2,5,2,3,7};
System.out.println(findLHS(nums));
}
}
http://www.cnblogs.com/chenssy/p/3521565.html
HashSet和HashMap的區(qū)別
- HashMap實(shí)現(xiàn)了Map接口 HashSet實(shí)現(xiàn)了Set接口
- HashMap儲(chǔ)存鍵值對(duì) HashSet僅僅存儲(chǔ)對(duì)象
- 使用put()方法將元素放入map中 使用add()方法將元素放入set中
- HashMap中使用鍵對(duì)象來(lái)計(jì)算hashcode值 HashSet使用成員對(duì)象來(lái)計(jì)算hashcode值竿屹,對(duì)于兩個(gè)對(duì)象來(lái)說(shuō)hashcode可能相同,所以equals()方法用來(lái)判斷對(duì)象的相等性灸姊,如果兩個(gè)對(duì)象不同的話拱燃,那么返回false
- HashMap比較快,因?yàn)槭鞘褂梦ㄒ坏逆I來(lái)獲取對(duì)象 HashSet較HashMap來(lái)說(shuō)比較慢
