
寫在開頭
現在scrapy的安裝教程都明顯過時了漱逸,隨便一搜都是要你安裝一大堆的依賴奇唤,什么裝python(如果別人連python都沒裝,為什么要學scrapy....)wisted灾前, zope interface卷玉,pywin32.........現在scrapy的安裝真的很簡單的好不好床牧!
代碼我放github上了彭谁,可以參考:
https://github.com/hk029/doubanbook
為什么要用scrapy
我之前講過了requests肛捍,也用它做了點東西椭微,(【圖文詳解】python爬蟲實戰(zhàn)——5分鐘做個圖片自動下載器)感覺它就挺好用的呀洞坑,那為什么我還要用scrapy呢?
因為:它蝇率!更迟杂!好!用本慕!就這么簡單排拷,你只要知道這個就行了。
我相信所有能找到這篇文章的人多多少少了解了scrapy锅尘,我再copy一下它的特點來沒太多意義监氢,因為我也不會在這篇文章內深入提。就像你知道系統的sort函數肯定比你自己編的快排好用就行了藤违,如果需要知道為什么它更好浪腐,你可以更深入的去看代碼,但這里顿乒,你只要知道這個爬蟲框架別人就專門做這件事的牛欢,肯定好用,你只要會用就行淆游。
我希望每個來這里的人傍睹,或者每個在找資料的朋友,都能明確自己的目的犹菱,我也盡量將文章的標題取的更加的明確拾稳。如果這是一篇標題為《快速上手》的文章,那你可能就不要太抱希望于能在這篇文章里找到有關scrapy架構和實現原理類的內容腊脱。如果是那樣访得,我可能會取標題為《深入理解scrapy》
好了廢話說了那么多,我們就上手把?
安裝scrapy
一條命令解決所有問題
pip install scrapy
好吧悍抑,我承認如果用的是windows一條命令可能確實不夠鳄炉,因為還要裝pywin32
https://sourceforge.net/projects/pywin32/files/pywin32/
現在sourceforge變的很慢,如果你們不能打開搜骡,我在網盤上也放一個64位的拂盯,最新220版本的:
鏈接: http://pan.baidu.com/s/1geUY6Dd 密碼: z2ep
然后就結束了!记靡!結束了L父汀!好不好摸吠!就這么簡單空凸!
豆瓣讀書9分書榜單爬取
我們考慮下做一個什么爬蟲呢?簡單點寸痢,我們做一個豆瓣讀書9分書:
https://www.douban.com/doulist/1264675/
建立第一個scrapy工程
把scrapy命令的目錄加入環(huán)境變量呀洲,然后輸入一條命令
scrapy startproject doubanbook
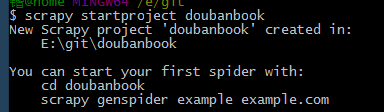
然后你的目錄下就有一個文件夾名為doubanbook目錄,按照提示啼止,我們cd進目錄道逗,然后按提示輸入,這里我們爬蟲取名為dbbook族壳,網址就是上面的網址
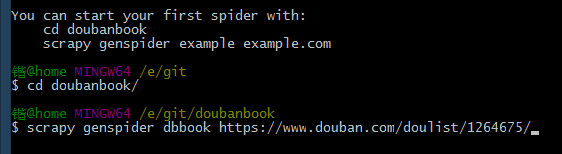
打開pycharm,新建打開這個文件夾
關于pytharm的安裝配置:Pycharm的配置和使用
打開后趣些,我們在最頂層的目錄上新建一個python文件仿荆,取名為main,這是運行的主程序(其實就一行代碼坏平,運行爬蟲)
輸入
from scrapy import cmdline
cmdline.execute("scrapy crawl dbbook".split())

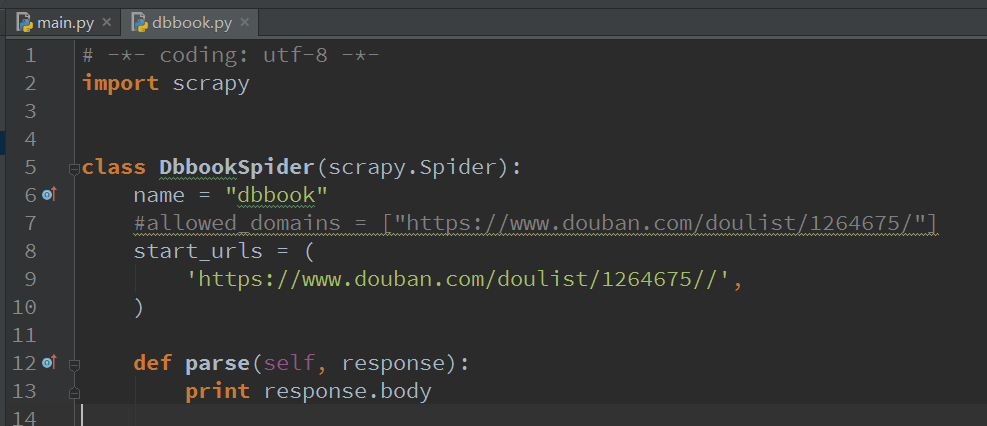
然后我們進入spider-dbbook拢操,然后把start_urls里面重復的部分刪除(如果你一開始在命令行輸入網址的時候,沒輸入http://www.那就不用改動)然后把allowed_domains注掉
并且舶替,把parse里面改成
print response.body
好了令境,到此第一個爬蟲的框架就搭完了,我們運行一下代碼顾瞪。(注意這里選擇main.py)
運行一下舔庶,發(fā)現沒打印東西,看看陈醒,原來是403

說明爬蟲被屏蔽了惕橙,這里要加一個請求頭部,模擬瀏覽器登錄
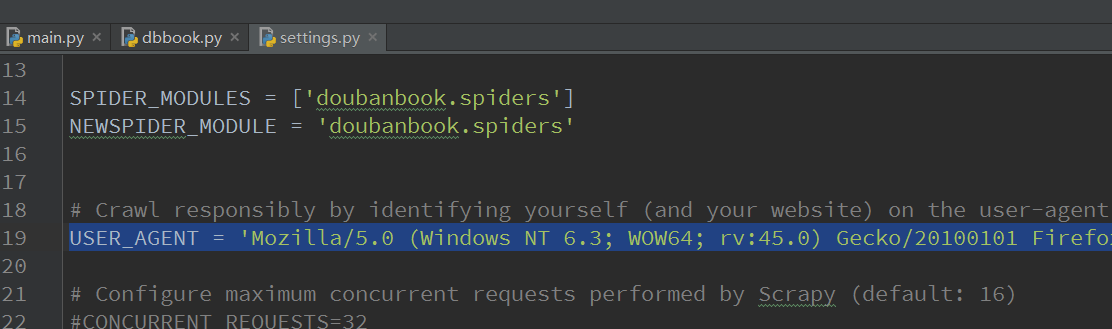
在settings.py里加入如下內容就可以模擬瀏覽器了
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
我們再運行钉跷,發(fā)現網頁內容已經被爬取下來了
好了弥鹦,我們的scrapy教程結束!
如果真這樣結束爷辙,我知道你會打我彬坏。朦促。
編寫xpath提取標題名和作者名
這里我們就要得分,標題名和作者名
觀察網頁源代碼栓始,用f12务冕,我們可以快速找到,這里不細講怎么找信息的過程了混滔,具體過程洒疚,參考上一個教程【圖文詳解】python爬蟲實戰(zhàn)——5分鐘做個圖片自動下載器
根據先大后小的原則,我們先用bd doulist-subject坯屿,把每個書找到油湖,然后,循環(huán)對里面的信息進行提取

提取書大框架:
'//div[@class="bd doulist-subject"]'
提取題目:
'div[@class="title"]/a/text()'
提取得分:
'div[@class="rating"]/span[@class="rating_nums"]/text()'
提取作者:(這里用正則方便點)
'<div class="abstract">(.*?)<br'
編寫代碼
經過之前的學習领跛,應該很容易寫出下面的代碼吧:作者那里用正則更方便提取
selector = scrapy.Selector(response)
books = selector.xpath('//div[@class="bd doulist-subject"]')
for each in books:
title = each.xpath('div[@class="title"]/a/text()').extract()[0]
rate = each.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()[0]
author = re.search('<div class="abstract">(.*?)<br',each.extract(),re.S).group(1)
print '標題:' + title
print '評分:' + rate
print author
print ''
關鍵這個代碼在哪里編寫呢乏德?答案就是還記得大明湖……不對,是還記得剛才輸出response的位置嗎吠昭?就是那里喊括,那里就是我們要對數據處理的地方。我們寫好代碼矢棚,這里注意:
- 不是用etree來提取了郑什,改為scrapy.Selector了,這點改動相信難不倒聰明的你
- xpath如果要提取內容蒲肋,需要在后面加上.extract()蘑拯,略為不適應,但是習慣還好兜粘。
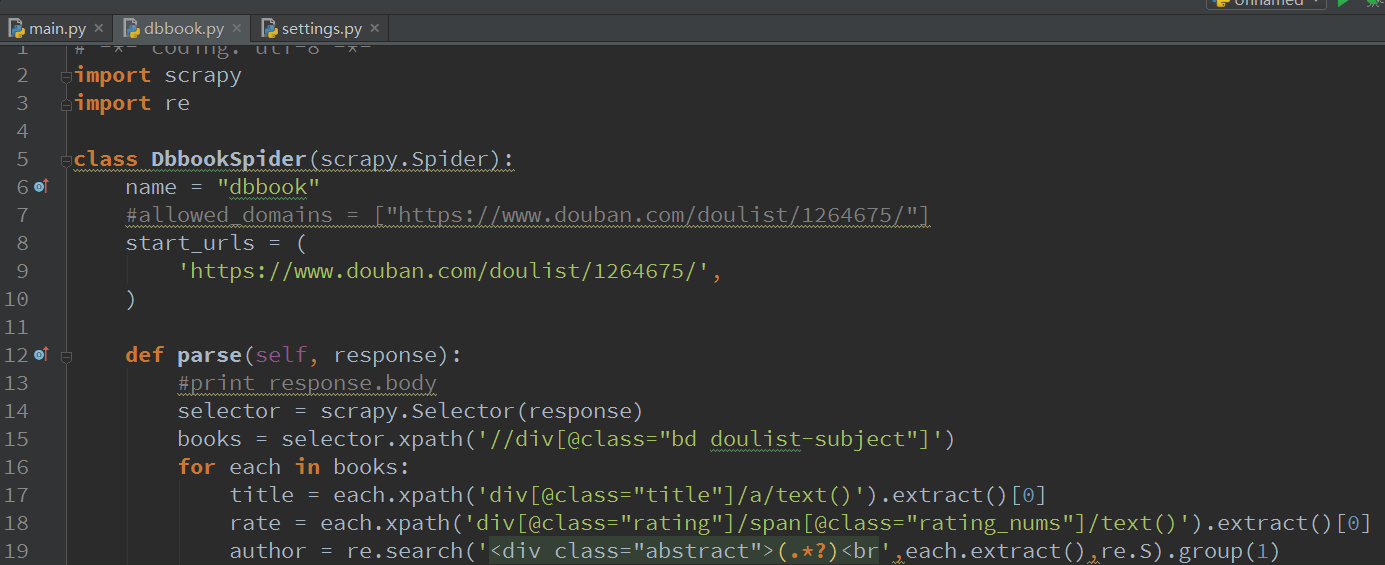
我們看看結果申窘,不好看,對于注重美觀的我們來說孔轴,簡直不能忍
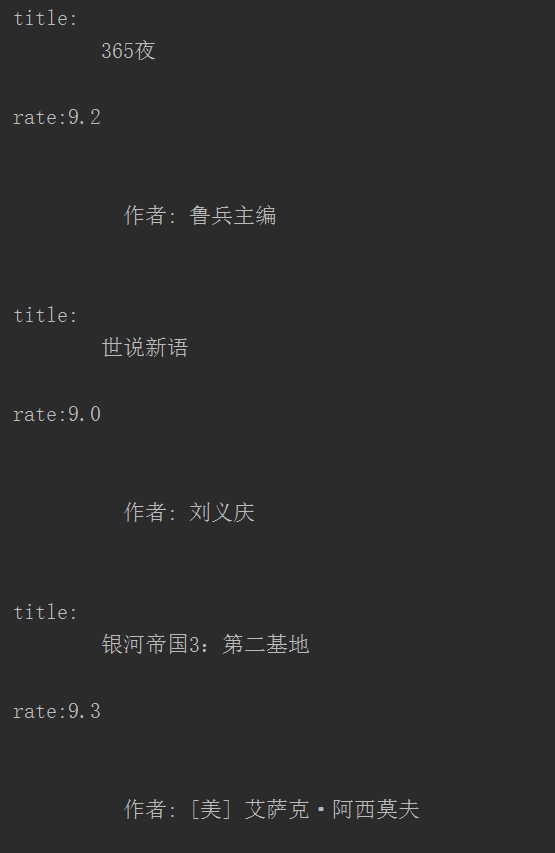
加入兩條代碼:
title = title.replace(' ','').replace('\n','')
author = author.replace(' ','').replace('\n','')
再看看結果剃法,這才是我們想要的嘛
好了,剩下的事情就是如何把結果寫入文件或數據庫了路鹰,這里我采用寫入文件贷洲,因為如果是寫入數據庫,我又得花時間講數據庫的一些基本知識和操作晋柱,還是放在以后再說吧恩脂。
items.py
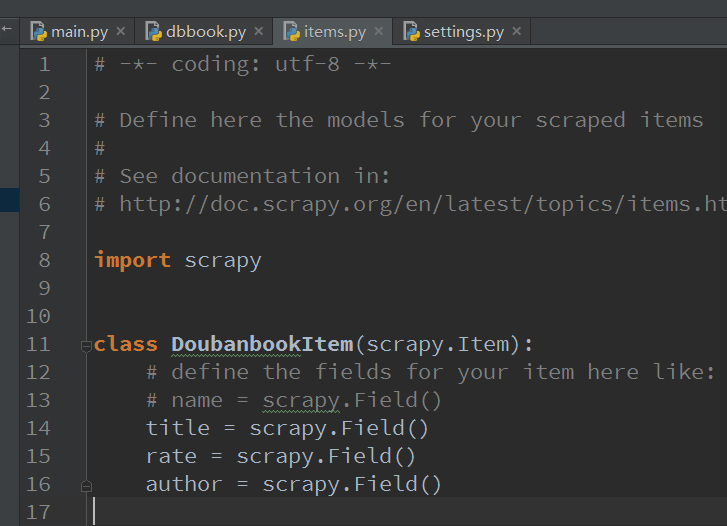
好了,我們終于要講里面別的.py文件了趣斤,關于這個items.py俩块,你只要考慮它就是一個存儲數據的容器,可以考慮成一個結構體,你所有需要提取的信息都在這里面存著玉凯。
這里我們需要存儲3個變量势腮,title,rate漫仆,author捎拯,所以我在里面加入三個變量,就這么簡單:
title = scrapy.Field()
rate = scrapy.Field()
author = scrapy.Field()
pipelines.py
一般來說盲厌,如果你要操作數據庫什么的署照,需要在這里處理items,這里有個process_item的函數吗浩,你可以把items寫入數據庫建芙,但是今天我們用不到數據庫,scrapy自帶了一個很好的功能就是Feed exports懂扼,它支持多種格式的自動輸出禁荸。所以我們直接用這個就好了,pipelines維持不變
settings.py
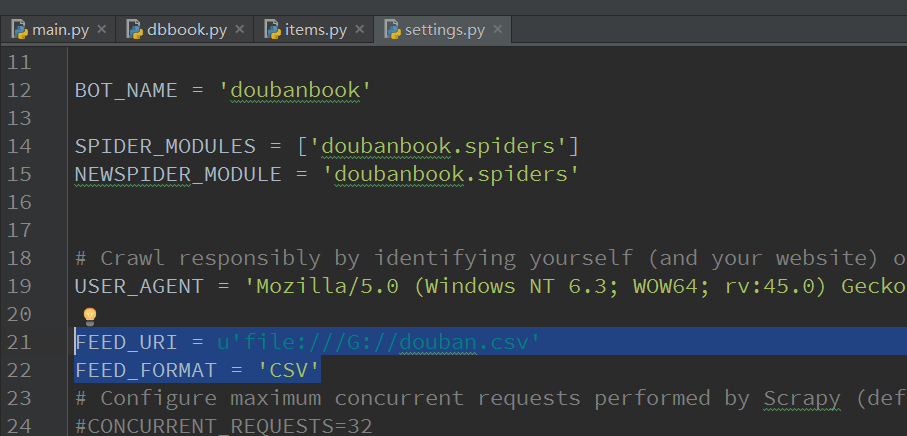
Feed 輸出需要2個環(huán)境變量:
FEED_FORMAT :指示輸出格式阀湿,csv/xml/json/
FEED_URI : 指示輸出位置赶熟,可以是本地,也可以是FTP服務器
FEED_URI = u'file:///G://douban.csv'
FEED_FORMAT = 'CSV'
FEED_URI改成自己的就行了
dbbook.py修改
其實也就加了3條命令陷嘴,是把數據寫入item
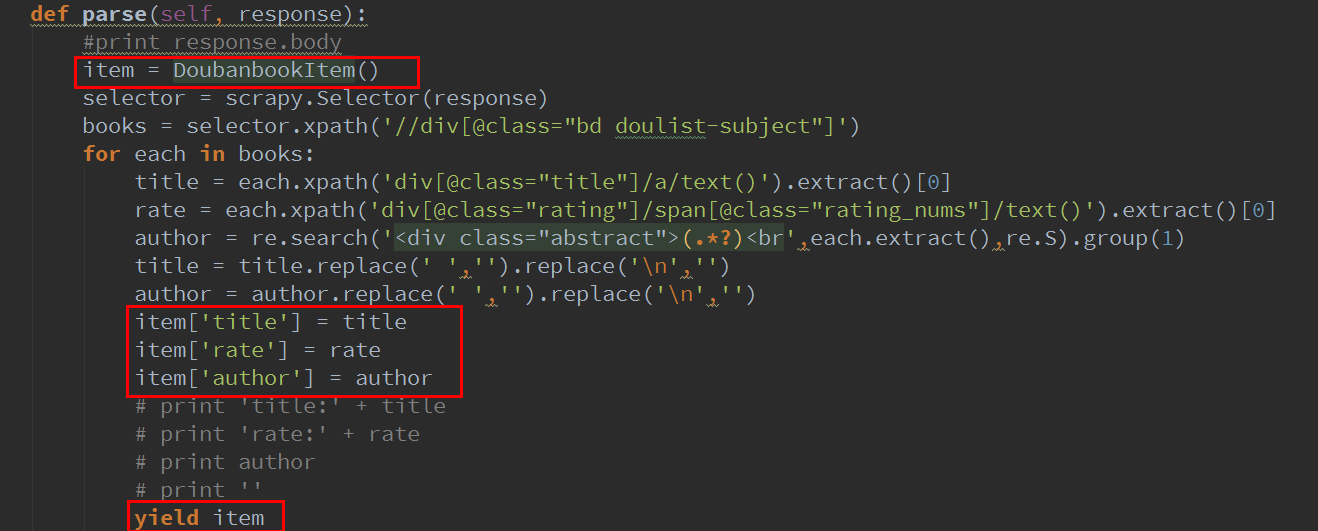
當然映砖,你要使用item,需要把item類引入
from doubanbook.items import DoubanbookItem
下面的yield可以讓scrapy自動去處理item
好拉灾挨,再運行一下邑退,可以看見G盤出現了一個douban.csv的文件
用excel打開看一下,怎么是亂碼
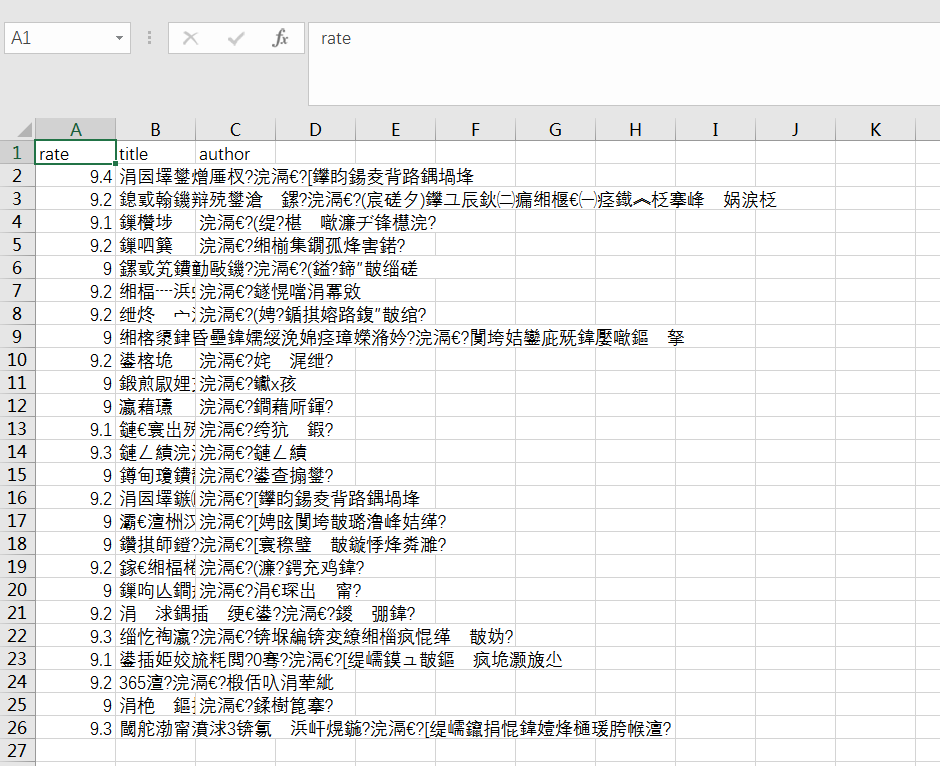
沒關系又是編碼的問題涨醋,用可以修改編碼的編輯器比如sublime打開一下瓜饥,

保存編碼為utf-8包含bom逝撬,或者用gvim打開:set fileencoding=gbk
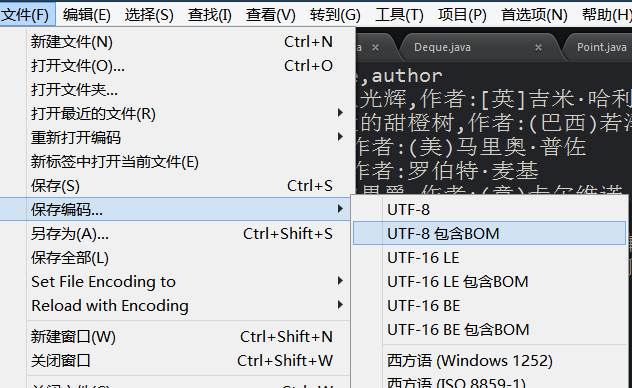
再打開浴骂,就正常了

爬取剩下頁面
這還只保存了一個頁面,那剩下的頁面怎么辦呢宪潮?難道要一個個復制網址溯警??當然不是狡相,我們重新觀察網頁梯轻,可以發(fā)現有個后頁的鏈接,里面包含著后一頁的網頁鏈接尽棕,我們把它提取出來就行了喳挑。
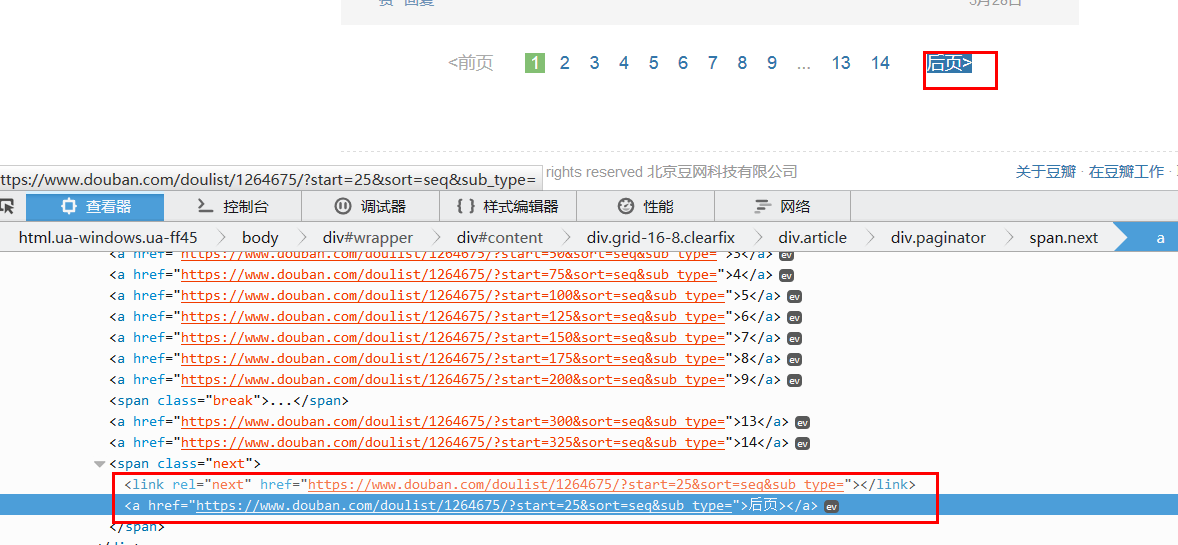
因為只有這里會出現<span class = 'next'>標簽,所以用xpath輕松提取
'//span[@class="next"]/link/@href'
然后提取后 我們scrapy的爬蟲怎么處理呢?
答案還是yield伊诵,
yield scrapy.http.Request(url,callback=self.parse)
這樣爬蟲就會自動執(zhí)行url的命令了单绑,處理方式還是使用我們的parse函數
改后的代碼這樣:
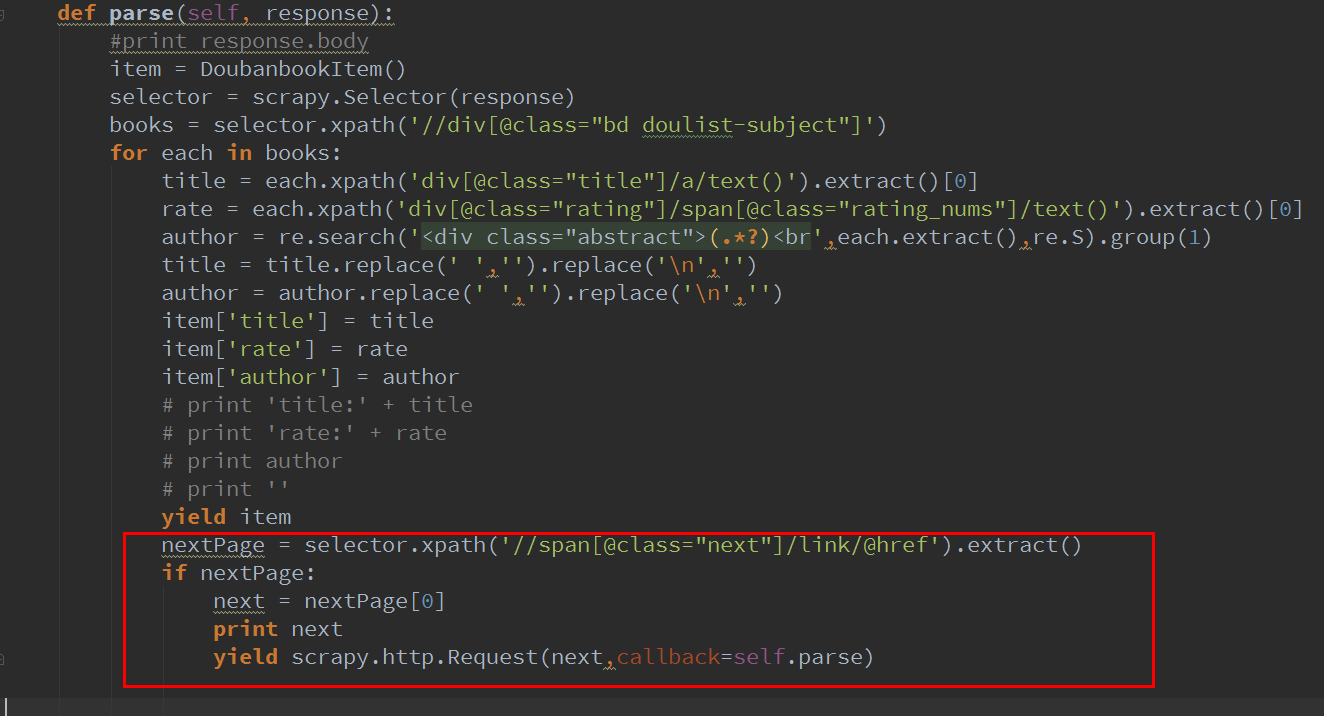
這里要加一個判斷,因為在最后一頁曹宴,“后一頁”的鏈接就沒了搂橙。
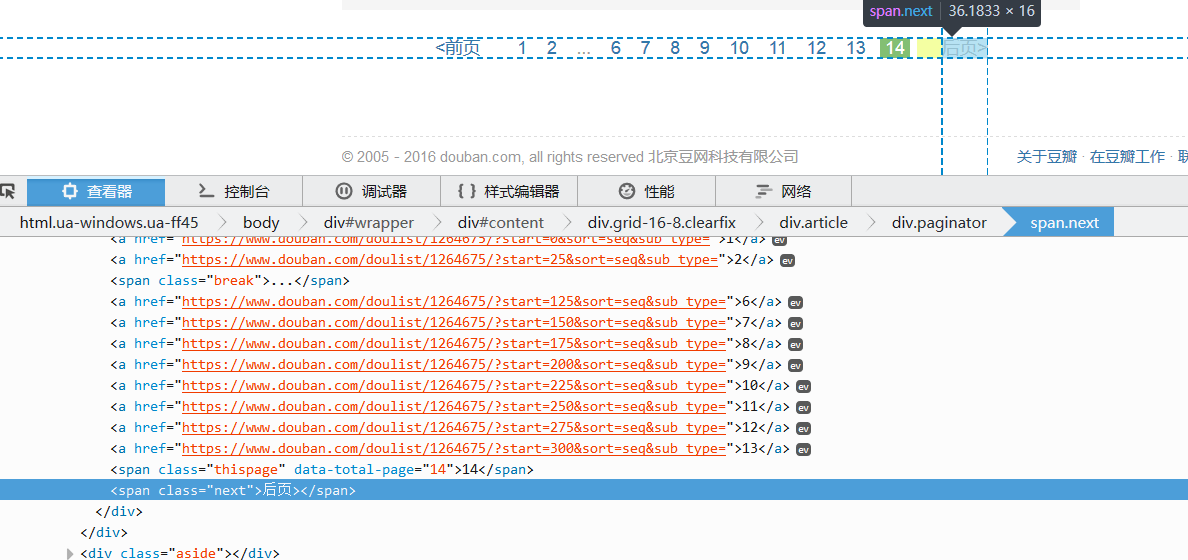
好了,我們再運行一下(先把之前的csv刪除笛坦,不然就直接在后面添加了)可以發(fā)現区转,運行的特別快,十幾頁一下就運行完了版扩,如果你用requests自己編寫的代碼废离,可以比較一下,用scrapy快很多资厉,而且是自動化程度高很多厅缺。
我們打開csv,可以看見宴偿,有345篇文章了湘捎,和豆瓣上一致。
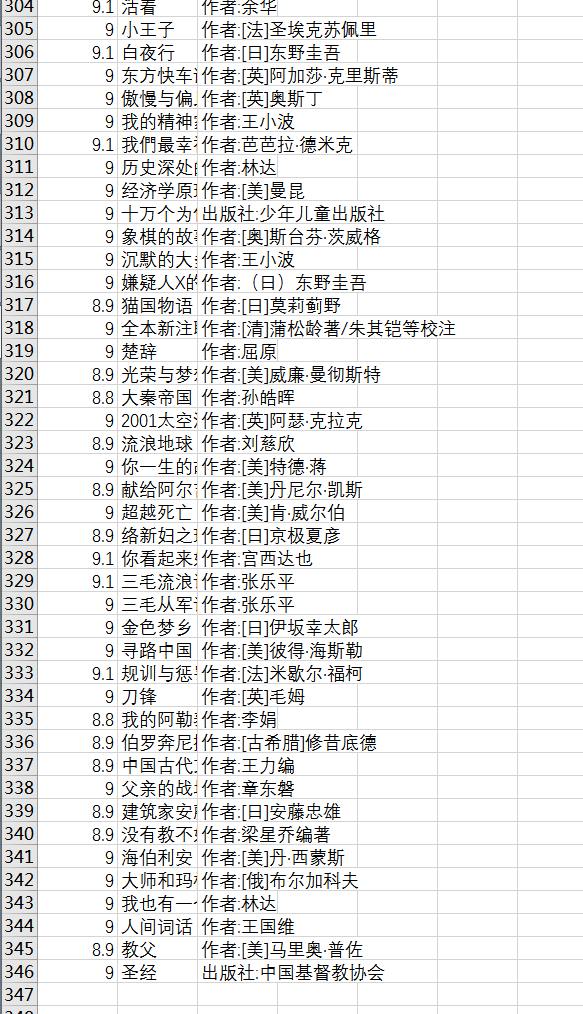
好了窄刘,這個豆瓣9分圖書的爬蟲結束了窥妇,相信通過這個例子,scrapy也差不多能上手娩践,至少編寫一般的爬蟲是so easy了活翩!
目前,我們已經能對付大多數網頁的內容了翻伺,現在爬本小說啥的應該都輕輕松松了材泄,但是為什么我說大多數呢?因為確實還有一些網頁我們應付不來吨岭,就是用Ajax動態(tài)加載的網頁拉宗,這怎么辦呢?且聽下回分解:
【圖文詳解】scrapy爬蟲與Ajax動態(tài)頁面——爬取拉勾網職位信息(1)
代碼我放github上了辣辫,可以參考:
https://github.com/hk029/doubanbook
