nodejs 模塊機制
簡單模塊定義和使用
在Node.js中尖淘,定義一個模塊十分方便。我們以計算圓形的面積和周長兩個方法為例忍宋,來表現(xiàn)Node.js中模塊的定義方式俗或。
var PI = Math.PI;
exports.area = function (r) {
return PI * r * r;
};
exports.circumference = function (r) {
return 2 * PI * r;
};
將這個文件存為circle.js,然后新建一個app.js文件陨亡,并寫入以下代碼:
var circle = require('./circle.js');
console.log( 'The area of a circle of radius 4 is ' + circle.area(4));
可以看到模塊調(diào)用也十分方便傍衡,只需要require需要調(diào)用的文件即可深员。
在require了這個文件之后,定義在exports對象上的方法便可以隨意調(diào)用蛙埂。Node.js將模塊的定義和調(diào)用都封裝得極其簡單方便辨液,從API對用戶友好這一個角度來說,Node.js的模塊機制是非常優(yōu)秀的箱残。
關(guān)于exports的內(nèi)容,可以參考之前的文章 exports && module.exports
模塊分類
核心模塊
核心模塊優(yōu)先級僅次于緩存加載止吁,因此無法加載一個和核心模塊標(biāo)識符相同的自定義模塊被辑。
路徑形式的文件模塊
以"."、".."開頭和"/"開始的標(biāo)識符敬惦,這里都被當(dāng)作文件模塊來處理盼理。require()方法會將路徑轉(zhuǎn)為真實路徑,并以真實路徑作為索引俄删,并將編譯執(zhí)行后的結(jié)果存放到緩存中宏怔。
自定義模塊(特殊的文件模塊)
自定義模塊是指非核心模塊,也不是路徑形式的標(biāo)識符畴椰。它是一種特殊的文件模塊臊诊,可能是一個文件或者包的形式。
模塊路徑是Node在定位文件模塊的具體文件時制定的查找策略斜脂,具體表現(xiàn)為一個路徑組成的數(shù)組(module.paths)抓艳。這個路徑由當(dāng)前目錄開始往上一直到根目錄,Node會逐個嘗試模塊路徑中的路徑帚戳,直到找到目標(biāo)文件未知玷或,若到達根目錄還是沒有找到目標(biāo)文件,則會拋出查找失敗的異常片任。當(dāng)前文件的目錄越深偏友,模塊查找耗時越多隧土。
模塊載入策略
上文中說道享怀,Node.js的模塊分為兩類,一類為原生(核心)模塊质和,一類為文件模塊犁钟。
原生模塊在Node.js源代碼編譯的時候編譯進了二進制執(zhí)行文件棱诱,加載的速度最快。另一類文件模塊是動態(tài)加載的涝动,加載速度比原生模塊慢迈勋。但是Node.js對原生模塊和文件模塊都進行了緩存,于是在第二次require時醋粟,是不會有重復(fù)開銷的靡菇。由于通過命令行加載啟動的文件幾乎都為文件模塊重归。我們從Node.js如何加載文件模塊開始談起。
我們從命令行啟動上文的app.js文件厦凤。
node app.js
加載文件模塊的工作鼻吮,主要由原生模塊module來實現(xiàn)和完成,該原生模塊在啟動時已經(jīng)被加載较鼓,進程直接調(diào)用到runMain靜態(tài)方法椎木。
// bootstrap main module.
Module.runMain = function () {
// Load the main module--the command line argument.
Module._load(process.argv[1], null, true);
};
_load靜態(tài)方法在分析文件名之后執(zhí)行
var module = new Module(id, parent);
并根據(jù)文件路徑緩存當(dāng)前模塊對象,該模塊實例對象則根據(jù)文件名加載博烂。
module.load(filename);
實際上在文件模塊中香椎,又分為3類模塊。這三類文件模塊以后綴來區(qū)分禽篱,Node.js會根據(jù)后綴名來決定加載方法畜伐。
- .js。通過fs模塊同步讀取js文件并編譯執(zhí)行躺率。
- .node玛界。通過C/C++進行編寫的Addon。通過dlopen方法進行加載悼吱。
- .json慎框。讀取文件,調(diào)用JSON.parse解析加載舆绎。
這里我們將詳細描述js后綴的編譯過程鲤脏。Node.js在編譯js文件的過程中實際完成的步驟有對js文件內(nèi)容進行頭尾包裝。以app.js為例吕朵,包裝之后的app.js將會變成以下形式:
(function (exports, require, module, __filename, __dirname) {
var circle = require('./circle.js');
console.log('The area of a circle of radius 4 is ' + circle.area(4));
});
這段代碼會通過vm原生模塊的runInThisContext方法執(zhí)行(類似eval猎醇,只是具有明確上下文,不污染全局)努溃,返回為一個具體的function對象硫嘶。最后傳入module對象的exports,require方法梧税,module沦疾,__filename(文件名),__dirname(目錄名)作為實參并執(zhí)行第队。
這就是為什么require并沒有定義在app.js文件中哮塞,但是這個方法卻存在的原因。從Node.js的API文檔中可以看到還有__filename凳谦、__dirname忆畅、module、exports幾個沒有定義但是卻存在的變量尸执。
__filename``和__dirname在查找文件路徑的過程中分析得到后傳入的家凯。module變量是這個模塊對象自身缓醋,exports是在module的構(gòu)造函數(shù)中初始化的一個空對象({},而不是null)绊诲。
在這個主文件中送粱,可以通過require方法去引入其余的模塊。而其實這個require方法實際調(diào)用的就是load方法掂之。
load方法在載入抗俄、編譯、緩存了module后世舰,返回module的exports對象橄镜。這就是circle.js文件中只有定義在exports對象上的方法才能被外部調(diào)用的原因。
以上所描述的模塊載入機制均定義在lib/module.js中冯乘。
require 方法中的文件查找策略
盡管require方法極其簡單,但是內(nèi)部的加載卻是十分復(fù)雜的晒夹,其加載優(yōu)先級也各自不同裆馒。
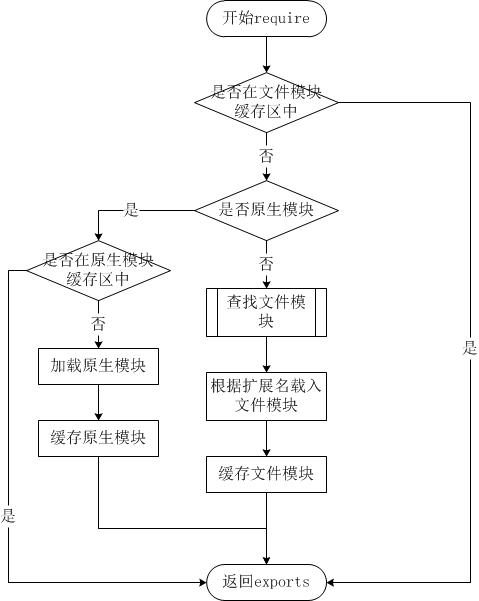
從文件加載
當(dāng)文件模塊緩存中不存在,而且不是原生模塊的時候丐怯,Node.js會解析require方法傳入的參數(shù)喷好,并從文件系統(tǒng)中加載實際的文件,加載過程中的包裝和編譯細節(jié)在前一節(jié)中已經(jīng)介紹過读跷,這里我們將詳細描述查找文件模塊的過程梗搅,其中,也有一些細節(jié)值得知曉效览。
require方法接受以下幾種參數(shù)的傳遞:
- http无切、fs、path等丐枉,原生模塊哆键。
- ./mod或../mod,相對路徑的文件模塊瘦锹。
- /pathtomodule/mod籍嘹,絕對路徑的文件模塊。
- mod弯院,非原生模塊的文件模塊辱士。
在進入路徑查找之前有必要描述一下module path這個Node.js中的概念。對于每一個被加載的文件模塊听绳,創(chuàng)建這個模塊對象的時候颂碘,這個模塊便會有一個paths屬性,其值根據(jù)當(dāng)前文件的路徑計算得到辫红。我們創(chuàng)建modulepath.js這樣一個文件凭涂,其內(nèi)容為:
console.log(module.paths);
我們將其放到任意一個目錄中執(zhí)行node modulepath.js命令祝辣,將得到以下的輸出結(jié)果(mac的演示結(jié)果)。
[ '/Users/beifeng/Desktop/test_node/node_modules',
'/Users/beifeng/Desktop/node_modules',
'/Users/beifeng/node_modules',
'/Users/node_modules',
'/node_modules' ]
可以看出module path的生成規(guī)則為:從當(dāng)前文件目錄開始查找
node_modules目錄切油;然后依次進入父目錄蝙斜,查找父目錄下的node_modules目錄;依次迭代澎胡,直到根目錄下的node_modules目錄孕荠。
文件模塊查找流程
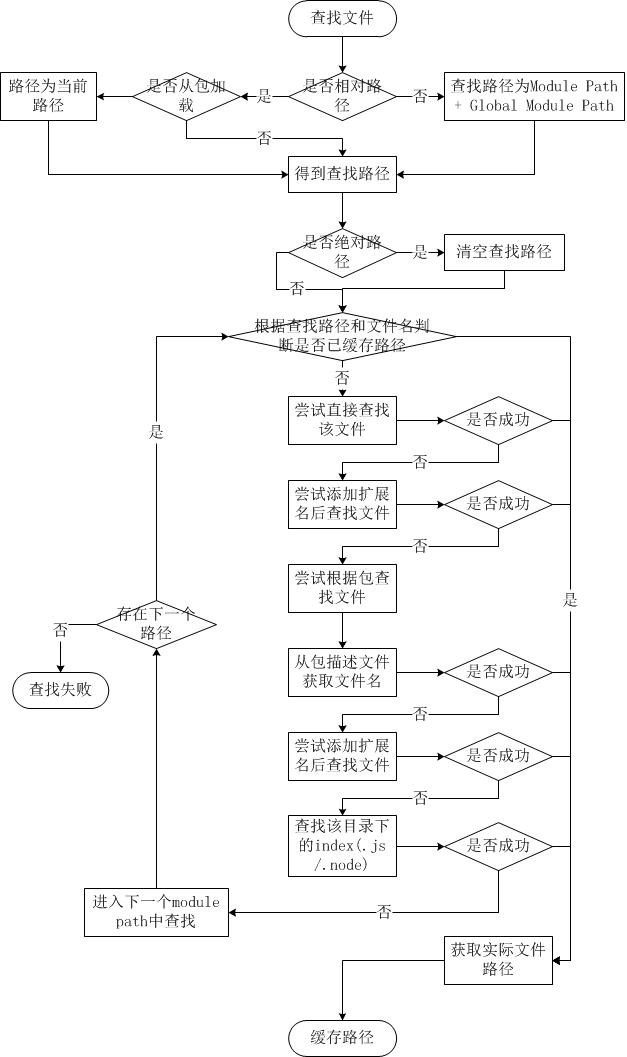
簡而言之,如果require絕對路徑的文件攻谁,查找時不會去遍歷每一個node_modules目錄稚伍,其速度最快。其余流程如下:
1.從module paths數(shù)組中取出第一個目錄作為查找基準(zhǔn)戚宦。
2.直接從目錄中查找該文件个曙,如果存在,則結(jié)束查找受楼。如果不存在垦搬,則進行下一條查找
3.嘗試添加.js、.json艳汽、.node后綴后查找猴贰,如果存在文件,則結(jié)束查找河狐。如果不存在米绕,則進行下一條。
4.嘗試將require的參數(shù)作為一個包來進行查找馋艺,讀取目錄下的package.json文件栅干,取得main參數(shù)指定的文件。
5.嘗試查找該文件捐祠,如果存在非驮,則結(jié)束查找。如果不存在雏赦,則進行第3條查找劫笙。
6.如果繼續(xù)失敗,則取出module path數(shù)組中的下一個目錄作為基準(zhǔn)查找星岗,循環(huán)第1至5個步驟填大。
7.如果繼續(xù)失敗,循環(huán)第1至6個步驟俏橘,直到module paths中的最后一個值允华。
8.如果仍然失敗,則拋出異常。
整個查找過程十分類似原型鏈的查找和作用域的查找靴寂。所幸Node.js對路徑查找實現(xiàn)了緩存機制磷蜀,否則由于每次判斷路徑都是同步阻塞式進行,會導(dǎo)致嚴(yán)重的性能消耗百炬。
CommonJS規(guī)范
JavaScript缺少包結(jié)構(gòu)褐隆。CommonJS致力于改變這種現(xiàn)狀,于是定義了包的結(jié)構(gòu)規(guī)范(http://wiki.commonjs.org/wiki/Packages/1.0 )剖踊。
CommonJS(http://www.commonjs.org)規(guī)范的出現(xiàn)庶弃,其目標(biāo)是為了構(gòu)建JavaScript在包括Web服務(wù)器,桌面德澈,命令行工具歇攻,及瀏覽器方面的生態(tài)系統(tǒng)。
一個符合CommonJS規(guī)范的包應(yīng)該是如下這種結(jié)構(gòu):
- 一個package.json文件應(yīng)該存在于包頂級目錄下
- 二進制文件應(yīng)該包含在bin目錄下梆造。
- JavaScript代碼應(yīng)該包含在lib目錄下缴守。
- 文檔應(yīng)該在doc目錄下。
- 單元測試應(yīng)該在test目錄下镇辉。
由上文的require的查找過程可以知道斧散,Node.js在沒有找到目標(biāo)文件時,會將當(dāng)前目錄當(dāng)作一個包來嘗試加載摊聋,所以在package.json文件中最重要的一個字段就是main。而實際上栈暇,這一處是Node.js的擴展麻裁,標(biāo)準(zhǔn)定義中并不包含此字段,對于require源祈,只需要main屬性即可煎源。
引用文章
深入淺出Nodejs
