本文是 「Golang 并發(fā)編程」系列的第一篇,筆者水平有限辛润,歡迎各位大佬指點~
## 1. 前言
Go 語言最大的魅力就是只需要 `go` 關(guān)鍵字即可快速創(chuàng)建一個 goroutine 膨处,無需關(guān)注操作系統(tǒng)的調(diào)度細節(jié),即可利用上多核輕松開發(fā)出高并發(fā)的服務(wù)器應(yīng)用。理解了 Golang 調(diào)度器的機制真椿,能讓我們寫出高性能的并發(fā)程序鹃答,也可以提升我們的問題定位、性能優(yōu)化的能力突硝。
## 2. 進程测摔、線程、協(xié)程
任何**并發(fā)**程序解恰,無論在應(yīng)用層是何形式锋八,最終都要被操作系統(tǒng)所管理。由此涉及到以下幾個概念:
- 進程 (Process):操作系統(tǒng)分配資源的基本單位
- 線程 (Thread):CPU 調(diào)度的基本單位护盈,一個核上同時只能運行一個線程挟纱,單線程的棧內(nèi)存大小約 **1MB**
- 協(xié)程 (Coroutine):輕量級、用戶態(tài)線程黄琼。在 Go 語言中樊销,有 `goroutine`的概念。當一個 `goroutine` 被創(chuàng)建出來時,分配的棧大小是 **2KB**衬衬,可見其「輕量」
## 3. 早期的調(diào)度模型:GM 模型
系統(tǒng)的設(shè)計往往都不是一蹴而就的奄喂,伴隨著演進和優(yōu)化,Golang scheduler 也不例外剂府。`1.1` 版本前的 go,使用的是相對簡單的 `GM` 模型來處理 goroutine 的調(diào)度剃盾,`GM` 實際是兩個結(jié)構(gòu)體腺占,即:
- G(Goroutine): 協(xié)程結(jié)構(gòu)體,使用 `go func()` 時痒谴,就會創(chuàng)建一個 `G`
- M(Machine): 處理線程操作的結(jié)構(gòu)體衰伯,與操作系統(tǒng)直接交互
GM 模型包含一個**全局協(xié)程隊列**,即所有新建的 `G` 對象都會排隊等待 `M` 的處理积蔚。如圖:

這樣的設(shè)計在高并發(fā)下會帶來以下問題:
>? What’s wrong with current implementation:
>? 1. Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc).
>? 2. Goroutine (G) hand-off (G.nextg). Worker threads (M’s) frequently hand-off runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G.
>? 3. Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M’s, while they need to be associated only with M’s running Go code (an M blocked inside of syscall does not need mcache). A ratio between M’s running Go code and all M’s can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality.
> 4. Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
(原文見 [Scalable Go Scheduler Design Doc](https://xie.infoq.cn/article/a6948402be688dba530094e9b))
翻譯總結(jié)一下意鲸,即存在以下優(yōu)化點:
1. **全局鎖、中心化狀態(tài)帶來的鎖競爭導致的性能下降**
2. M 會頻繁交接 G尽爆,導致額外開銷怎顾、性能下降。每個 M 都得能執(zhí)行任意的 runnable 狀態(tài)的 G
3. 對每個 M 的不合理的內(nèi)存緩存分配漱贱,進行系統(tǒng)調(diào)用被阻塞住的 M 其實不需要分配內(nèi)存緩存
4. 強線程阻塞/解阻塞槐雾。頻繁的系統(tǒng)調(diào)用導致的線程阻塞/解阻塞帶來了大量的系統(tǒng)開銷。
由此演進出經(jīng)典的 `GMP` 調(diào)度模型
## 4. 高效的 GMP 調(diào)度模型
為了解決 `G` 和 `M` 調(diào)度低效的問題幅狮,中間層 `P(Processor)` 被引入了募强。
- `P(Processor)` 即管理 `goroutine` 資源的處理器
由此得以將原先的系統(tǒng)線程資源管理 `M` 與 `goroutine` 對象 `G` 解耦株灸。
除此之外,GMP 還引入了幾個新概念:
- `LRQ (Local Runnable Queue)` 本地可運行隊列钻注,這個「本地」蚂且,是針對 P 而言的,是指掛載在一個 P 上的可運行 G 隊列
- `GRQ (Global Runnable Queue)` 全局可運行隊列
如下圖所示:
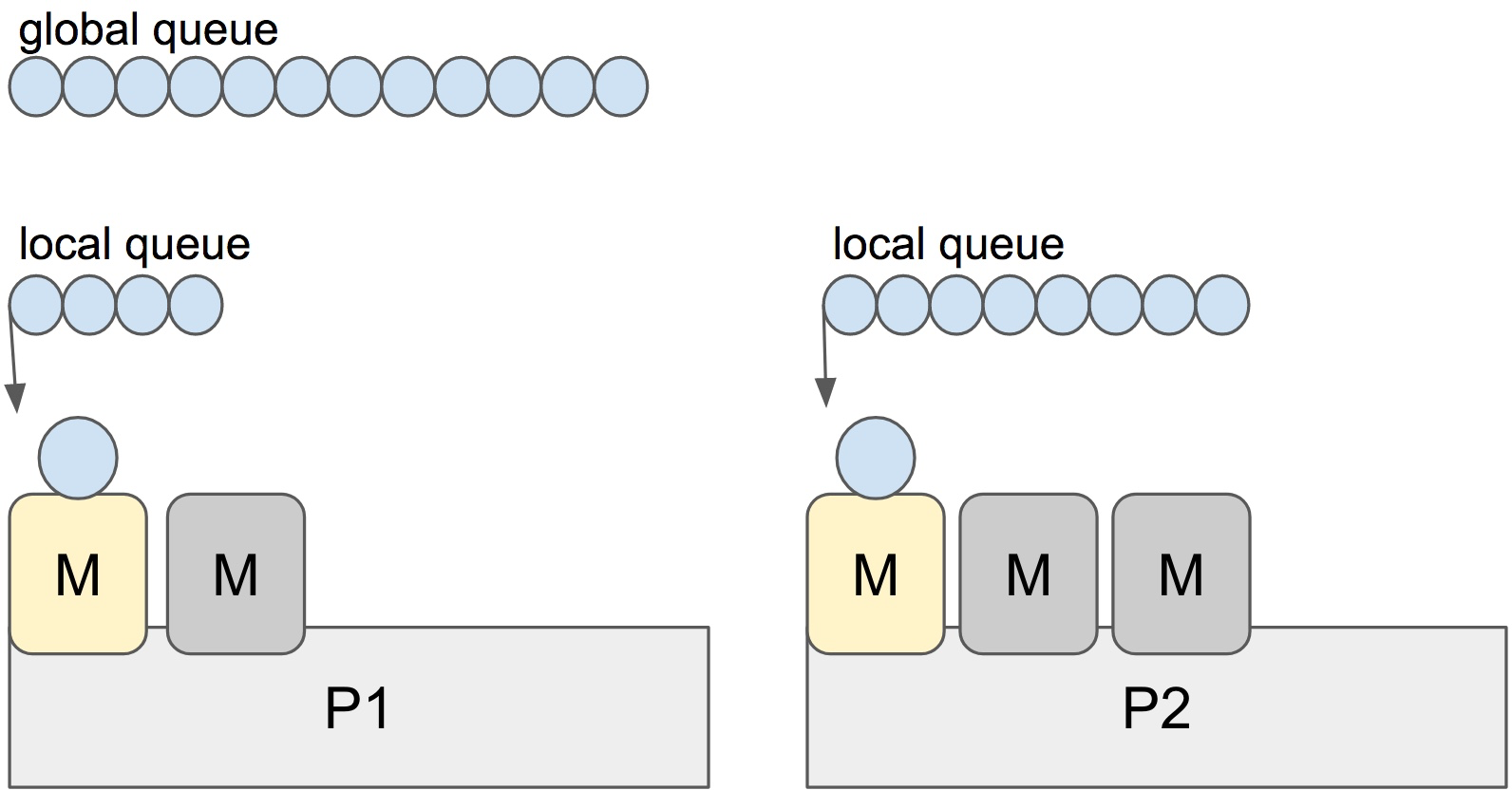
從 runtime 源碼可知幅恋,整體的調(diào)度流程如下:
```go
runtime.schedule() {
? ? // only 1/61 of the time, check the global runnable queue for a G.
? ? // if not found, check the local queue.
? ? // if not found,
? ? //? ? try to steal from other Ps.
? ? //? ? if not, check the global runnable queue.
? ? //? ? if not found, poll network.
}
```
翻譯一下杏死,即
- 只有 1/61 的情況下,會檢查 GRQ 來獲取一個 G 來運行
- 如果沒找到捆交,則檢查 LRQ
- 如果 LRQ 也為空淑翼,則嘗試從其它 P 上偷 G
- 如果偷不到,就再檢查 GRQ
- 如果還是沒事干品追,就會從 `Network Poller` 上拿一個玄括。這里的 `Network Poller` 是 go 管理網(wǎng)絡(luò)調(diào)用的模塊,如下圖肉瓦,當出現(xiàn)網(wǎng)絡(luò) IO 時遭京,就會將當前的 G 移交到 `Network Poller` 處理。P.S. `Network Poller` 的實現(xiàn)泞莉,又可以扯一篇文章出來了哪雕,以后有空專門開一篇分析。


### Work-stealing 機制
`GMP`高性能的關(guān)鍵斯嚎,在于引入了 `work-stealing` 機制,如下圖所示:

> 當一個新的 G 被創(chuàng)建時挨厚,它會被追加到它當前 P 的 LRQ 隊尾堡僻。當一個 G 被執(zhí)行完時,它當前的 P 會先嘗試從自己的 LRQ 中 pop 一個 G 出來執(zhí)行疫剃,如果此時隊列為空钉疫,則會**隨機選取一個** P **并偷走它一半的** G ,對應(yīng)圖中巢价,也就是 3 個 G
這就好比公司里的卷王牲阁,自己的需求做完了,還要悄悄把摸魚大王的需求清單里一半的需求都掛到自己名下蹄溉,囧
### 最后一個疑問:GRQ 什么時候被寫入呢?
這又涉及到 G 創(chuàng)建時的分配流程了您炉,我們知道柒爵,goroutine 都是由老的 goroutine 分配出來的,main 函數(shù)也不例外赚爵,因此每個 G 被分配的時候已經(jīng)有一個老 G 和對應(yīng)的老 P 了棉胀,在掛載 G 到 P 上時法瑟,也會優(yōu)先掛在到老 P 的 LRQ 上去。但是老 P 的 LRQ 其實是有限的唁奢,當掛滿的時候霎挟,這個新 G 就只能掛到 GRQ 上,等待被調(diào)度了麻掸∷重玻可以參考源碼中 P 的定義,其中 `runq` 就是 GRQ 了:
```go
type p struct {
? ...
? ? // Queue of runnable goroutines. Accessed without lock.
? runqhead uint32
? runqtail uint32
? runq? ? [256]guintptr
? ? ...
}
```
## 5. 小結(jié)
本文講解了 go 語言調(diào)度器的發(fā)展及基于 GMP 的 work-stealing 策略脊奋,這個「偷」可以說是非常精妙啦~ 這是 「#Golang 網(wǎng)絡(luò)編程」 系列的第一篇文章熬北,如果對你有幫助,可以點個關(guān)注/在看來激勵我寫文章~
To be continued...
### 參考資料
- 《Head First of Golang Scheduler》https://zhuanlan.zhihu.com/p/42057783?
- 《動圖圖解诚隙!GMP模型里為什么要有P讶隐?背后的原因讓人暖心 | Go主題月》https://juejin.cn/post/6956008643456139301?
- 《Golang 調(diào)度器 GMP 原理與調(diào)度全分析》https://learnku.com/articles/41728
- 《Go's work-stealing scheduler》https://rakyll.org/scheduler/
- 《Scheduling In Go : Part II - Go Scheduler》https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
- 《Go的隱秘世界:Goroutine調(diào)度機制概覽》https://zhuanlan.zhihu.com/p/244054940
