問題描述
我們知道方差表示一個值距離平均值的遠(yuǎn)近程度,如果用一個二位圖表示的話敛惊,方差越大蚪腋,高斯分布越“平緩”扣癣,方差越小即寒,高斯分布越“高尖”良价。
但是如何理解,“方差越大蒿叠,信息量就越多”?
或者蚣常,我們應(yīng)該如何理解“信息量”這個詞市咽?在某一個特征中,系統(tǒng)的混亂程度抵蚊?值的大惺┮铩?多少贞绳?
原問題地址:http://www.zhihu.com/question/36481348
簡書md這公式支持也是醉了谷醉,不支持LaTeX也就算了,用API轉(zhuǎn)成圖片還不能用行內(nèi)圖片冈闭,湊合著看吧俱尼,忍不了的可以去知乎的原問題下看我的回答。也可以去GitHub去下這篇文章的md源代碼萎攒。
回答
前面幾位答主答的非常好非常專業(yè)遇八,但是不太接地氣矛绘,過于陽春白雪了,我來下里巴人一下刃永,以我作為一個學(xué)識淺薄的門外漢的角度沒什么干貨的淺談一下货矮。
題主問的很明確,為什么方差和信息量是正相關(guān)的斯够?題主非常熟悉方差那一套理論囚玫,那么現(xiàn)在的疑問就是信息量的定義是什么?通過什么方法去量化信息量读规?
以非專業(yè)的角度來說抓督,我們直觀感受什么叫信息量大?比如我今天看了一集電視劇掖桦,和昨天看的那一集一樣是40分鐘本昏,下載下來大小也是一樣的,但是大呼“臥槽枪汪,今天這集信息量好大涌穆,腦子轉(zhuǎn)不過來了”是什么意思?這是我們?nèi)粘UZ境的信息量雀久,也就是事物給我們傳遞的信息的數(shù)量宿稀。比如今天我們要競選特首,一共有3位候選人赖捌,如果完全按照基本法去產(chǎn)生祝沸,也就是說選舉委員會的投票完全隨機,那么這3位候選人當(dāng)選的概率均等越庇,服從均勻分布(也就是方差最大的一種情況)罩锐,那么民眾都是非常期待看到這場競選的直播的,因為之前誰也不知道誰會當(dāng)選卤唉,而看完以后就能獲得“究竟誰能當(dāng)選”這個信息涩惑;然而競選開始之前,歐盟出了個報告說其中某位先生是欽定的桑驱,這場競選中他贏的概率是100%(此時方差為0)竭恬,那么基本上就沒人想看競選了,因為這場競選只是走個形式并沒有傳遞出任何其他信息熬的。
當(dāng)然我說了這是我們的日常語境中十分不嚴(yán)格的定量分析痊硕,實際在信息論中,信息量(amount of information)一直是以信息熵(entropy)來度量的押框。信息論經(jīng)典教材elements of information theory[1]也從來沒正面提到過怎么定義信息量岔绸,只提到過:
- 信息熵可以用來描述隨機變量包含的信息量
- 互信息量(mutual information)是一種用來度量一個隨機變量包含的關(guān)于另一個隨機變量的信息量的手段
,也不難推出第二條推論。那么信息熵的定義里面亭螟,是提到過它是隨機變量不確定度的度量挡鞍,并且有許多符合度量信息的直觀要求。那究竟是哪些特性可以反映信息量预烙?
信息量的定義可以追溯到Hartley(沒錯墨微,就是那個有噪信道編碼定理Shannon-Hartley Theorem的那個Hartley)提出如果一個信源以相等的概率從包含S個符號的有限集中選擇N個傳輸符號進(jìn)行傳輸,那么信息量就是
10扁掸,但是后來我們使用和討論二元信道的情況更多翘县,所以規(guī)定底數(shù)為2),這也是后來我們經(jīng)常在各類書籍中看到的信息熵定義{0,1}中選擇一個發(fā)給對方氓奈,那我接收這個信號得到的信息量就是X的不確定度,如果信源的字典只有一個{1}的話鼎天,這個信源就是信息量為0的舀奶,反正不接收我都能猜的對要傳送的是什么,如果還是剛才的情況{0,1}但不是均勻分布斋射,而是取0的概率為90%育勺,那么信息量也比均勻分布坍縮不少,因為我們已經(jīng)了解到很大可能性是0罗岖,而接收只是破除了10%的疑義涧至。所以,從感性上來說桑包,隨機變量的不確定度是可以用來度量隨機變量的信息量化借。
那么剩下的問題是信息熵和(協(xié))方差有什么關(guān)系?方差和信息熵是否正相關(guān)捡多?
那么我先說一下我的結(jié)論:“方差越大信息量就越多”這個斷言是極具誤導(dǎo)性的。若是沒有任何應(yīng)用的前提下單單談這句話铐炫,是十分沒有意義的垒手。
正如 @雷天琪 的回答解釋的非常直觀,深入而淺出倒信。因為在主成分分析(PCA)方法中科贬,我們確實是把方差作為衡量信息量的指標(biāo),在我們的感性理解中,方差越大說明數(shù)據(jù)越具有多樣性榜掌,相關(guān)性也就越強(參考協(xié)方差的定義)优妙。
然而,(協(xié))方差度量的是數(shù)據(jù)分布的離散度(diversity憎账,也稱多樣性)套硼,對于統(tǒng)計樣本和隨機變量都如是。而衡量信息量所用的信息熵則是用來度量不確定程度(物理上的熵表示混亂程度胞皱,實際這個混亂度的意義還是和Shannon熵的不確定意義一致)邪意。在信息論體系下,解壓也好傳輸也好降維也好反砌,導(dǎo)致的信息損失(information loss)也是使用互信息量的差值表示雾鬼。在這里,一個很明顯的差異可以被發(fā)現(xiàn):對于有量綱的樣本數(shù)據(jù)宴树,(協(xié))方差是個有量綱的量策菜,而信息熵,甚至包括建立在熵度量基礎(chǔ)上的一系列度量(相對熵酒贬,條件熵又憨,互信息量)都是無量綱的(這個說法也不嚴(yán)謹(jǐn),可以認(rèn)為熵的量綱取決于對數(shù)的底數(shù))同衣。那么這個差異也可以說明一個非常大的問題:方差的指取決于隨機變量本身的取值竟块,而信息熵和互信息量等量的取值僅僅與隨機變量的分布有關(guān),與隨機變量本身的具體取值無關(guān)耐齐。
那么這兩個具有很大的相似度的兩個量哪個更適合用來表示信息量浪秘?
舉個十分極端的例子,對于兩個獨立的離散隨機變量X1埠况,X2耸携,它們的取值可以有具體意義(比如天氣預(yù)報預(yù)測未來一個月下雨的天數(shù),可以從天氣晴朗的0到30任意取整數(shù)值)辕翰,也可以沒有任何數(shù)學(xué)意義(如特首選舉中當(dāng)選的候選人編號)
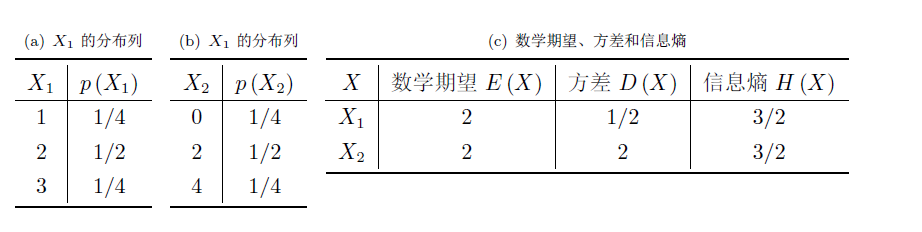
這就是個方差越大夺衍,信息熵未必越大的例子。當(dāng)然我還能舉出很多方差增大但信息熵減少的例子喜命,造成這些的原因是沟沙,當(dāng)我們試圖用方差去描述隨機變量的不確定程度時,我們過分關(guān)注了隨機變量的值域壁榕,而隨機變量本身的取值跨度真的可以用來度量“信息量”嗎矛紫?
通過我們的直觀感受,這兩個離散隨機變量包含的“信息量”有什么不一樣嗎牌里?恐怕并沒有吧颊咬,誰在意到底是具體是哪位先生當(dāng)選特首,在意的只是選舉的公平性。接受取值跨度大的信息破除的疑義就一定比接受取值跨度小的信息大嗎喳篇?
還是那句話敞临,方差描述變量的離散程度,信息熵描述變量的不確定程度麸澜。兩者雖然有一定的聯(lián)系但并不等價挺尿。隨機變量的取值可以很不確定但并不是非常離散,在信息論體系中痰憎,我們認(rèn)為破除的疑義可以表達(dá)這個信息量票髓,而變量的離散程度并不能表示這個疑義。所以铣耘,方差越大信息量越多這個說法是不正確的洽沟。
那為什么主成分分析的過程是尋找能使方差最大的方向以此保持最大的信息量?在這種方法中蜗细,為什么就可以認(rèn)為找到使降維后的數(shù)據(jù)樣本方差最大的基底就使損失的信息最小化裆操?
不妨想一下PCA降維的目的,就是為了降噪[2]炉媒。除去和結(jié)果關(guān)系不大的特征踪区,保留最具相關(guān)性的特征。但是這些數(shù)據(jù)是以什么概率分布產(chǎn)生的吊骤,我們并不知道缎岗,這里的信息熵就沒有什么太大意義了,不能開上帝視角找到最大信息熵的方向白粉,PCA方法本來就是用來“揣測”和“創(chuàng)造”數(shù)據(jù)之間的規(guī)律[3]传泊。至于我們怎樣區(qū)分出什么是噪聲,什么是主成分鸭巴,就是出于這種揣測的思路找到離散程度最高的方向眷细,而離散程度低的方向更有可能是由于噪聲的干擾表現(xiàn)出同一性,或者反過來說就是因為太同一所以沒什么分析價值鹃祖。因此我們把注意力放在離散程度高的成分上溪椎,因為它的多樣性可以幫助我們分析數(shù)據(jù)間潛在的關(guān)系。
那么從信號傳輸?shù)慕嵌瓤刺窨冢纸鈪f(xié)方差矩陣找到特征值最大的方向(也就是方差最大的方向)是否真正保留了信息論意義上的最大信息量校读?
假設(shè)有這樣一個信道:
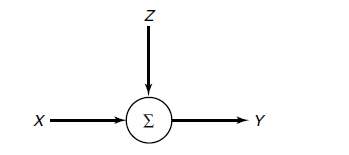
信源信號(輸入)為向量x,傳輸過程中的噪聲為向量z祖能,最后得到的信號(輸出)為
那么考慮以下情況:
-
x服從Gaussian分布,z也服從Gaussian分布且其協(xié)方差矩陣與恒等矩陣成比例(也就是z向量各個維度i.i.d的情況)芯杀。我們定義PCA降為后的結(jié)果為(w是新空間的基向量,l是新空間的維數(shù)),那么此時PCA確實最大化了互信息量[4].
- 如果噪聲
z依然是Gaussian的揭厚,且還是遵從i.i.d却特,但信源信號x卻是非Gaussian信號(這是常見的應(yīng)用場景),那么PCA至少最小化了信息損失的上界筛圆,而這里的信息損失表示為[5].
3.當(dāng)噪聲z服從i.i.d裂明,同時至少比信源信號x更Gaussian,這里指在相對熵(Kullback–Leibler divergence)意義上更Guassian太援,PCA確實最小化了信息損失量闽晦。
總之,當(dāng)噪聲z的各個維度打破這種獨立分布關(guān)系時提岔,PCA就不能保證信息損失量的最優(yōu)化了仙蛉。
-
Cover T M, Thomas J A. Elements of information theory[M]. John Wiley & Sons, 2012. ?
-
Wikipedia: https://en.wikipedia.org/wiki/Principal_component_analysis ?
-
Rangayyan R M. Biomedical signal analysis[M]. John Wiley & Sons, 2015. ?
-
Linsker R. Self-organization in a perceptual network[J]. Computer, 1988, 21(3): 105-117. ?
-
Geiger B C, Kubin G. Signal enhancement as minimization of relevant information loss[C]//Systems, Communication and Coding (SCC), Proceedings of 2013 9th International ITG Conference on. VDE, 2013: 1-6. ?
