個(gè)推 Spark 實(shí)踐教你繞過開發(fā)那些“坑” - V2EX https://www.v2ex.com/t/241917
//
1 、數(shù)據(jù)處理經(jīng)常出現(xiàn)數(shù)據(jù)傾斜扁位,導(dǎo)致負(fù)載不均衡的問題曾棕,需要做統(tǒng)計(jì)分析找到傾斜數(shù)據(jù)特征刊懈,定散列策略把将。
2 夷恍、使用 Parquet 列式存儲童擎,減少 IO ,提高 Spark SQL 效率苏章。
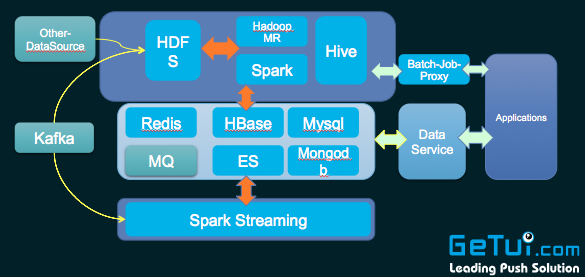
3 寂嘉、實(shí)時(shí)處理方面:一方面要注意數(shù)據(jù)源( Kafka ) topic 需要多個(gè) partition 奏瞬,并且數(shù)據(jù)要散列均勻,使得 Spark Streaming 的 Recevier 能夠多個(gè)并行泉孩,并且均衡地消費(fèi)數(shù)據(jù) 硼端。使用 Spark Streaming ,要多通過 Spark History 排查 DStream 的操作中哪些處理慢寓搬,然后進(jìn)行優(yōu)化珍昨。另外一方面我們自己還做了實(shí)時(shí)處理的監(jiān)控系統(tǒng),用來監(jiān)控處理情況如流 入句喷、流出數(shù)據(jù)速度等镣典。通過監(jiān)控系統(tǒng)報(bào)警,能夠方便地運(yùn)維 Spark Streaming 實(shí)時(shí)處理程序。這個(gè)小監(jiān)控系統(tǒng)主要用了 influxdb+grafana 等實(shí)現(xiàn)唾琼。
4 兄春、我們測試網(wǎng)經(jīng)常出現(xiàn)找不到第三方 jar 的情況,如果是用 CDH 的同學(xué)一般會遇到锡溯,就是在 CDH 5.4 開始赶舆, CDH 的技術(shù)支持人員說他們?nèi)サ袅?hbase 等一些 jar ,他們認(rèn)那些 jar 已經(jīng)不需要耦合在自己的 classpath 中祭饭,這個(gè)情況可以通過 spark.executor.extraClassPath 方式添加進(jìn)來芜茵。
5 、一些新入門的人會遇到搞不清 transform 和 action 倡蝙,沒有明白 transform 是 lazy 的夕晓,需要 action 觸發(fā),并且兩個(gè) action 前后調(diào)用效果可能不一樣悠咱。
6 、大家使用過程當(dāng)中征炼,對需要重復(fù)使用的 RDD 析既,一定要做 cache ,性能提升會很明顯谆奥。
//
1 眼坏、個(gè)推做用戶畫像、模型迭代以及一些推薦的時(shí)候直接用了 MLLib 酸些, MLLib 集成了很多算法宰译,非常方便。
2 魄懂、個(gè)推有一個(gè) BI 工具箱沿侈,讓一些運(yùn)營人員提取數(shù)據(jù),我們是用 Spark SQL+Parquet 格式寬表實(shí)現(xiàn)市栗, Parquet 是列式存儲格式缀拭,使用它你不用加載整個(gè)表咳短,只會去加載關(guān)心那些字段,大大減少 IO 消耗蛛淋。
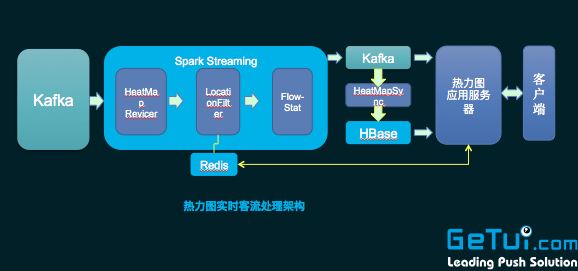
3 咙好、實(shí)時(shí)統(tǒng)計(jì)分析這塊:例如個(gè)推有款產(chǎn)品叫個(gè)圖,就是使用 Spark streaming 來實(shí)時(shí)統(tǒng)計(jì)褐荷。
4 勾效、復(fù)雜的 ETL 任務(wù)我們也使用 Spark 。例如:我們個(gè)推推送報(bào)表這一塊叛甫,每天需要做很多維度的推送報(bào)表統(tǒng)計(jì)层宫。使用 Spark 通過 cache 中間結(jié)果緩存,然后再統(tǒng)計(jì)其他維度合溺,大大地減少了 I/O 消耗卒密,顯著地提升了統(tǒng)計(jì)處理速度。
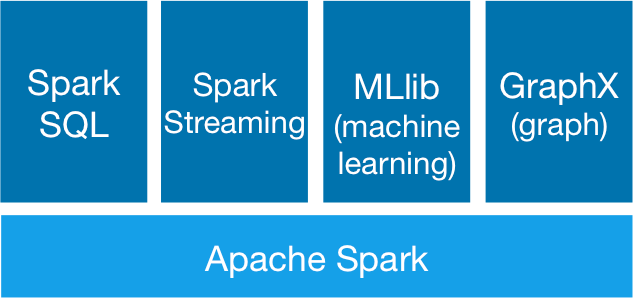
Spark 作為一個(gè)開源數(shù)據(jù)處理框架棠赛,它在數(shù)據(jù)計(jì)算過程中把中間數(shù)據(jù)直接緩存到內(nèi)存里哮奇,能大大地提高處理速度,特別是復(fù)雜的迭代計(jì)算睛约。 Spark 主要包括 SparkSQL 鼎俘, SparkStreaming , Spark MLLib 以及圖計(jì)算辩涝。
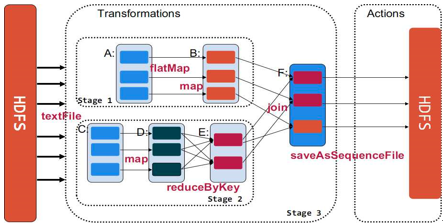
Spark 核心概念簡介 1 贸伐、 RDD 即彈性分布式數(shù)據(jù)集,通過 RDD 可以執(zhí)行各種算子實(shí)現(xiàn)數(shù)據(jù)處理和計(jì)算怔揩。比如用 Spark 做統(tǒng)計(jì)詞頻捉邢,即拿到一串文字進(jìn)行 WordCount ,可以把這個(gè)文字?jǐn)?shù)據(jù) load 到 RDD 之后商膊,調(diào)用 map 伏伐、 reducebyKey 算子,最后執(zhí)行 count 動作觸發(fā)真正的計(jì)算晕拆。 2 藐翎、寬依賴和窄依賴。工廠里面有很多流水線实幕,一款產(chǎn)品上游有一個(gè)人操作吝镣,下游有人進(jìn)行第二個(gè)操作,窄依賴和這個(gè)很類似昆庇,下游依賴上游末贾。而所謂寬依賴類似于有多條流水線, A 流水線的一個(gè)操作是需要依賴一條流水線 B 凰锡,才可以繼續(xù)執(zhí)行未舟,要求兩條流水線之間要做材料運(yùn)輸圈暗,做協(xié)調(diào),但效率低裕膀。
最后編輯于 :2017.12.06 04:50:10
?著作權(quán)歸作者所有,轉(zhuǎn)載或內(nèi)容合作請聯(lián)系作者