Record Linkage即在不同數(shù)據(jù)集中找出同一個(gè)實(shí)體的描述記錄(如下所示)臣樱。主要目的是對(duì)不同數(shù)據(jù)源中的實(shí)體信息進(jìn)行整合雇毫,形成更加全面的實(shí)體信息。

Data Preprocessing
原始數(shù)據(jù)集的質(zhì)量會(huì)直接影響Record Linkage的結(jié)果(如下所示)枚粘,不同數(shù)據(jù)集對(duì)同一信息的描述往往并不一樣馍迄,比如時(shí)間描述、縮寫(xiě)暴凑、錯(cuò)誤等等现喳。對(duì)常識(shí)性的數(shù)據(jù)進(jìn)行歸一化處理能夠極大的提高后續(xù)步驟的準(zhǔn)確率撕捍。
| Data set | Name | Date of birth | City of residence |
|---|---|---|---|
| Data set 1 | William J. Smith | 1/2/73 | Berkeley, California |
| Data set 2 | Smith, W. J. | 1973.1.2 | Berkeley, CA |
| Data set 3 | Bill Smith | Jan 2, 1973 | Berkeley, Calif. |
Algorithm Framework
在知識(shí)圖譜實(shí)體融合過(guò)程中忧风,基本問(wèn)題是判斷兩個(gè)實(shí)體是否可以融合狮腿。假設(shè)兩個(gè)知識(shí)圖譜所包含的實(shí)體數(shù)目分別為n1和n2缘厢,那么需要判斷的實(shí)體對(duì)數(shù)目為n1 * n2贴硫,當(dāng)兩個(gè)知識(shí)圖譜實(shí)體數(shù)目在千萬(wàn)規(guī)模時(shí)伊者,無(wú)法對(duì)所有可能的實(shí)體對(duì)進(jìn)行計(jì)算,所以基本算法框架是先對(duì)所有的實(shí)體進(jìn)行Blocking操作挖诸,然后對(duì)每個(gè)Blocking內(nèi)的每一對(duì)實(shí)體進(jìn)行判斷多律,是典型的MapReduce架構(gòu)狼荞。類似設(shè)計(jì)見(jiàn)這里帮碰,這里收毫,這里殷勘。
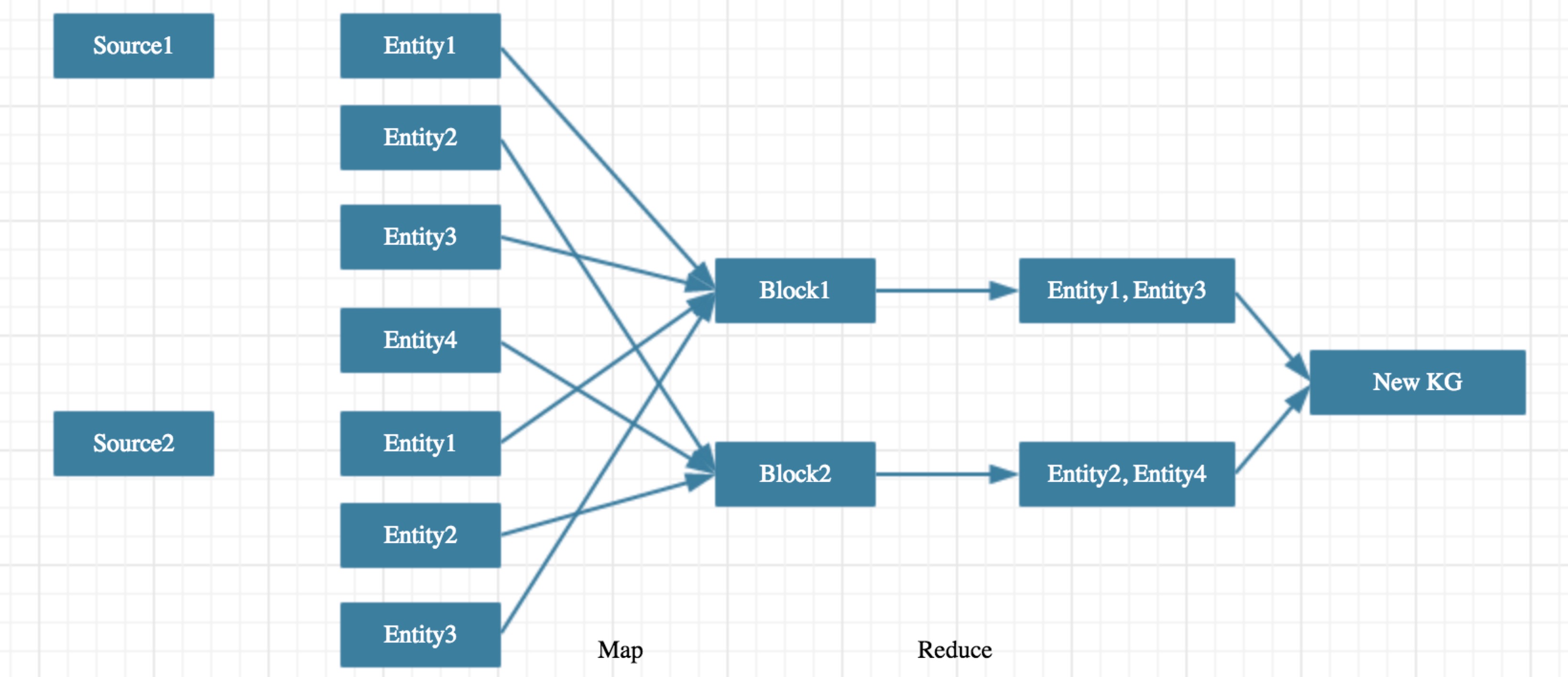
Map Stage
本階段目標(biāo)是將全部實(shí)體集合拆分成相互無(wú)關(guān)的實(shí)體子集玲销,拆分過(guò)程中保證所有潛在可融合的實(shí)體對(duì)都分到同一子集中贤斜,后續(xù)的計(jì)算過(guò)程所有子集可以并行計(jì)算瘩绒,相互之間沒(méi)有依賴带族。
理想情況下,我們只需要設(shè)計(jì)Partition函數(shù)hash_func(entity) = block_id來(lái)得到每個(gè)實(shí)體所屬的block阳堕。但在具體操作過(guò)程中可能會(huì)遇到實(shí)體分布不均的問(wèn)題恬总,即某一個(gè)block內(nèi)的實(shí)體數(shù)遠(yuǎn)大于其他block壹堰,從而導(dǎo)致整個(gè)算法運(yùn)行時(shí)間大大增加骡湖。所以需要額外進(jìn)行Load Balance來(lái)保證所有block中的實(shí)體數(shù)相當(dāng),同時(shí)保證不會(huì)漏掉任何可能融合的實(shí)體對(duì)并巍。
Partition
針對(duì)不同的任務(wù)懊渡,Partition函數(shù)的選擇會(huì)有所不同剃执。在特定領(lǐng)域內(nèi)進(jìn)行實(shí)體融合時(shí)懈息,完全可以根據(jù)領(lǐng)域特定知識(shí)來(lái)設(shè)計(jì),比如在領(lǐng)域內(nèi)有明確區(qū)分度的字段俗慈,實(shí)際效果往往被復(fù)雜的算法更好遣耍。在通用領(lǐng)域主要方法有如下幾種:
- Hierarchical Clustering
- Nearest Neighbor based methods
- Correlation Clustering, greeding algo
Load Balance
對(duì)于Load Balance問(wèn)題赊豌,這篇文章給出了詳細(xì)的策略碘饼,基本框架是兩次Map-Reduce麸拄,第一次Map-Reduce統(tǒng)計(jì)基于Partition函數(shù)計(jì)算結(jié)果后每個(gè)block中實(shí)體數(shù)目的分布拢切,第二次Map-Reduce再根據(jù)該分布再進(jìn)行二次Partition淮椰,具體流程如下:
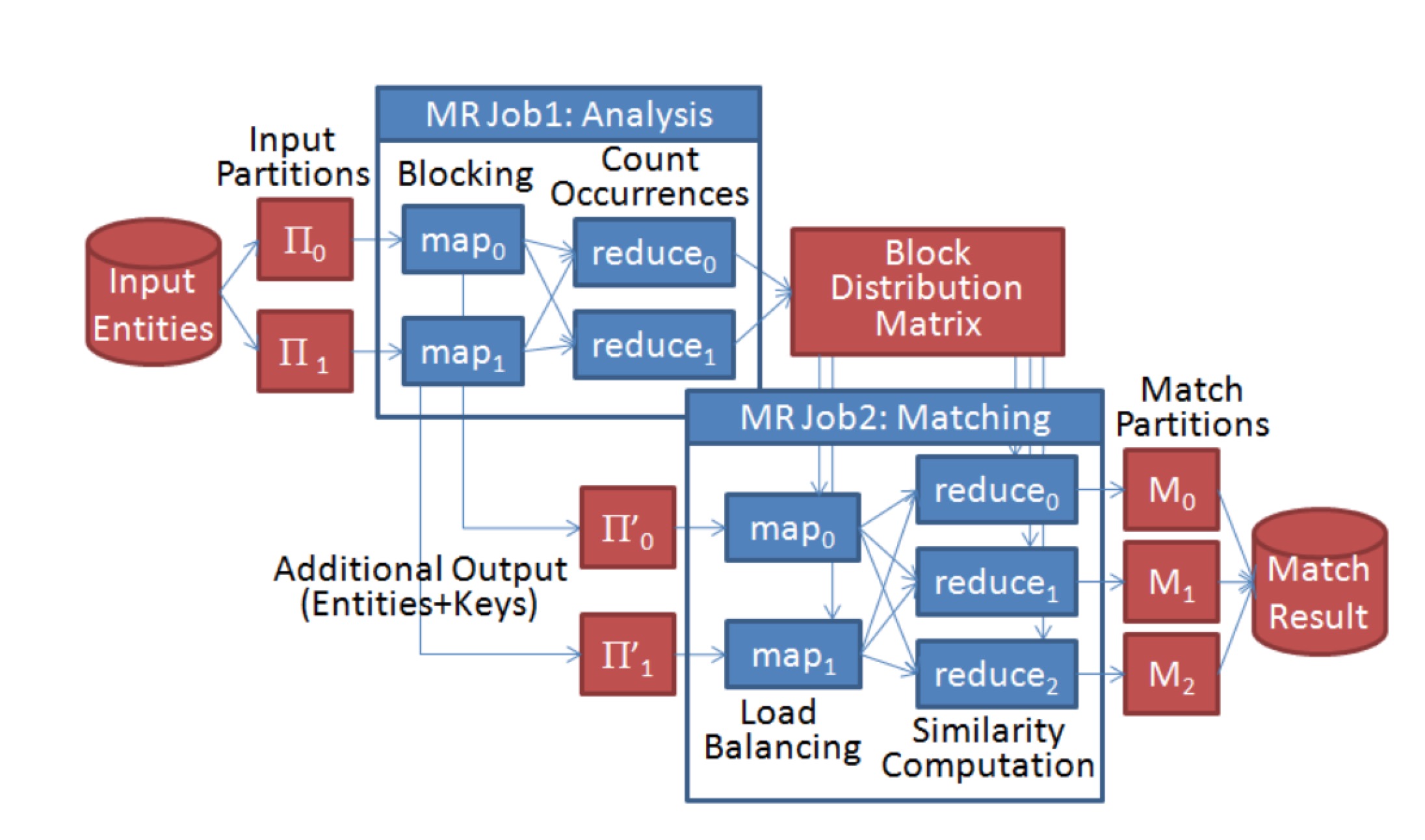
Reduce Stage
本階段目標(biāo)是對(duì)同一block內(nèi)任意兩個(gè)可能的實(shí)體對(duì)進(jìn)行判斷是否可以融合主穗。根據(jù)不同的策略毙芜,分為Deterministic record linkage和Probabilistic record linkage腋粥。
Deterministic record linkage
Deterministic record linkage即基于規(guī)則的實(shí)體融合方法,在具體操作過(guò)程中闹瞧,主要是根據(jù)一個(gè)或多個(gè)identifiers來(lái)判斷是否進(jìn)行融合奥邮,在特定領(lǐng)域內(nèi),基于規(guī)則的實(shí)體融合方法往往會(huì)得到不錯(cuò)的效果脚粟。
Probabilistic record linkage
Probabilistic record linkage即基于概率的實(shí)體融合方法核无,基本流程是先進(jìn)行相似度的計(jì)算生成特征度液,再通過(guò)機(jī)器學(xué)習(xí)方法來(lái)進(jìn)行判斷堕担。從組成模塊上來(lái)看,主要分為訓(xùn)練模塊和預(yù)測(cè)模塊佑惠。
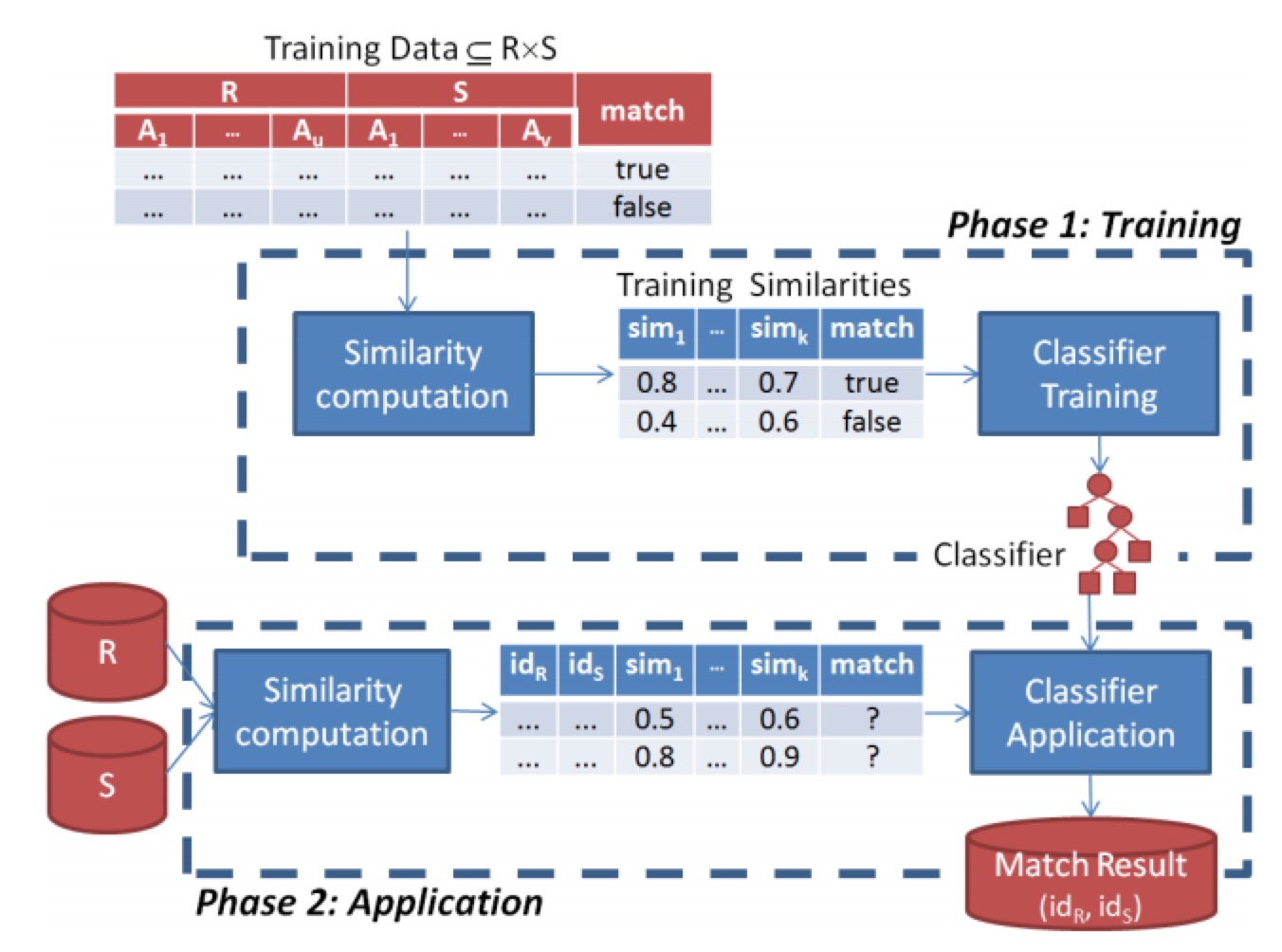
關(guān)于相似度計(jì)算膜楷,這個(gè)赌厅,這個(gè)轿塔,這個(gè)都有提到,比如基于布爾值的判斷揍障;編輯距離毒嫡,Levenstein, Smith‐Waterman, Affine幻梯;基于set的相似度計(jì)算礼旅,Jaccard, Dice;基于vector的相似度計(jì)算菲嘴,Cosine similarity, TFIDF龄坪;基于alignment的相似度計(jì)算,Jaro‐Winkler, Soft‐TFIDF, Monge‐Elkan烛卧;基于phonetic的相似度計(jì)算总放,Soundex好爬;基于翻譯模型的相似度計(jì)算;基于數(shù)值的相似度計(jì)算炬搭;領(lǐng)域特定相似度計(jì)算等等宫盔。而具體應(yīng)用中享完,基于alignment的相似度適合處理名字縮寫(xiě)般又、別名,基于set、vector的相似度計(jì)算適合處理普通文本句狼,如tweets等腻菇。
關(guān)于機(jī)器學(xué)習(xí)模型,常規(guī)的分類模型都可以使用糖耸,如樸素貝葉斯嘉竟、svm、深度學(xué)習(xí)等等倦蚪。在實(shí)際操作過(guò)程中陵且,由于訓(xùn)練數(shù)據(jù)有限个束,一般會(huì)采用active learning的策略通過(guò)迭代的方式逐步提高模型的準(zhǔn)確率。
Evaluation
整體評(píng)估指標(biāo)主要還是F值以及整個(gè)算法的運(yùn)行時(shí)間沪悲,具體而言值的關(guān)注的指標(biāo)有:全量實(shí)體對(duì)的數(shù)目可训,經(jīng)過(guò)Map之后需要匹配的實(shí)體對(duì)數(shù)目/召回率握截,最終匹配上的實(shí)體對(duì)數(shù)目/準(zhǔn)確率/召回率烂叔,MapReduce中每一步的運(yùn)行時(shí)間,整體運(yùn)行時(shí)間胯努。
Conclusion
關(guān)于實(shí)體融合的相關(guān)論文非常多叶沛,但到2012年之后基于新算法忘朝、新框架的論文逐漸變少局嘁,更多是survey、工程上性能優(yōu)化肴茄。也就是說(shuō)寡痰,學(xué)術(shù)界認(rèn)為這個(gè)任務(wù)在一定程度上已經(jīng)得到了解決。而從基本算法框架上來(lái)看氓癌,關(guān)于MapReduce算法框架的實(shí)體融合論文明顯多于其他框架贪婉,在工程上甚至已經(jīng)有了開(kāi)源工具包如dedupe,大規(guī)模的實(shí)體融合也有相應(yīng)的支持如dedoop才顿。從技術(shù)壁壘來(lái)看郑气,基本框架與具體算法看起來(lái)都比較簡(jiǎn)單腰池,但當(dāng)數(shù)據(jù)規(guī)模達(dá)到一定程度后,算法讳侨、工程上都會(huì)遇到瓶頸跨跨,如果在大規(guī)模數(shù)據(jù)下順暢跑通整個(gè)流程勇婴,并得到質(zhì)量足夠高的知識(shí)圖譜嘱腥,本身就是壁壘,而在具體實(shí)現(xiàn)過(guò)程中萨螺,針對(duì)特定領(lǐng)域的融合算法優(yōu)化也會(huì)是壁壘的一部分。另外椭盏,整個(gè)系統(tǒng)的很多子模塊都是常見(jiàn)的機(jī)器學(xué)習(xí)問(wèn)題掏颊,深度學(xué)習(xí)在整個(gè)系統(tǒng)中的想象空間也非常大艾帐。
References
維基百科鏈接柒爸,對(duì)該算法常見(jiàn)處理流程與算法有非常好的概述捎稚。
Dedupe, 基于Python的工具包求橄,實(shí)現(xiàn)了包括fuzzy matching, deduplication, entity resolution在內(nèi)的常見(jiàn)任務(wù)罐农。主要處理流程是先對(duì)所有record通過(guò)Clustering/Blocking的方法進(jìn)行分組,然后在組內(nèi)部通過(guò)計(jì)算相似度特征和機(jī)器學(xué)習(xí)分類模型對(duì)任一一對(duì)record進(jìn)行預(yù)測(cè)是否為同一實(shí)體宰睡。相關(guān)論文參考Paper拆内。
Dedoop, 基于Hadoop的Deduplication實(shí)現(xiàn)裆悄,主要流程分為Blocking(對(duì)record進(jìn)行分組),Similarity Computation(計(jì)算組內(nèi)每一對(duì)實(shí)體的相似度)光稼,Match Classification(通過(guò)規(guī)則或機(jī)器學(xué)習(xí)算法來(lái)判斷是否是同一實(shí)體)艾君。有完善的User Interface以及高效的Map-Reduce實(shí)現(xiàn)機(jī)制。
http://iswc2015.semanticweb.org/sites/iswc2015.semanticweb.org/files/93660257.pdf
Effective Online Knowledge Graph Fusion蹬癌,本文研究的方向是如何將搜索引擎返回結(jié)果中的實(shí)體卡片映射到維基百科上的實(shí)體逝薪。由于并非是傳統(tǒng)意義上的兩個(gè)知識(shí)庫(kù)的融合蝴罪,本文的思路還是走的Entity Linking的方法要门,即看維基百科中anchor text與實(shí)體一起出現(xiàn)的概率作為將卡片映射到實(shí)體的強(qiáng)度廓啊,并考慮了傳統(tǒng)實(shí)體融合中用到的計(jì)算相似度的方法谴轮。同時(shí)對(duì)實(shí)體的屬性名第步、屬性值融合有比較清楚的描述藻雌。
Swoosh: a generic approach to entity resolution胯杭,斯坦福的實(shí)體融合框架,相關(guān)論文在這里鸽心。很不一樣的一篇文章顽频,其他文章主要都是在講如何blocking/matching太闺,輸出的結(jié)果就是哪一些實(shí)體對(duì)是可以融合的。這篇文章將匹配函數(shù)和融合函數(shù)當(dāng)作黑盒蟀淮,主要是在討論基于這兩個(gè)函數(shù)如何能夠通過(guò)更加好的算法生成新的實(shí)體庫(kù)怠惶,而不僅僅輸出實(shí)體對(duì)轧粟。
http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
Learnable Similarity Functions and Their Application to Record Linkage and Clustering兰吟,Dedupe工具包就是根據(jù)這篇博士論文實(shí)現(xiàn)的。本文對(duì)常見(jiàn)的相似度算法edit distance讽膏,tf-idf等進(jìn)行了詳細(xì)描述府树,Blocking料按、Clustering、Matching等模塊用到了svm垄潮、active learning等機(jī)器學(xué)習(xí)模型弯洗,在現(xiàn)在看來(lái)逢勾,一些模型選型應(yīng)該有更多選擇。
https://pdfs.semanticscholar.org/cf6c/8ce4ec5bbbae9be4b9076c41d49a8eaad7b3.pdf
Evaluation of entity resolution approaches on real-world match problems逃贝,本文針對(duì)不同的matching方法提出了一整套評(píng)估標(biāo)準(zhǔn)沐扳,包含match quality和runtime efficiency沪摄。并對(duì)常見(jiàn)的Non-learning match approaches和Learning-based match approaches進(jìn)行了介紹纱烘。
Entity Resolution: Tutorial凹炸,本文對(duì)實(shí)體融合的常見(jiàn)技術(shù)進(jìn)行整體梳理,包括數(shù)據(jù)預(yù)處理奕筐,相似度計(jì)算离赫,pairwise匹配決策機(jī)器學(xué)習(xí)模型,active learning策略渊胸,常見(jiàn)的constraints以及應(yīng)用方法翎猛,Clustering算法介紹,多種混合模型的嘗試等切厘。
https://pdfs.semanticscholar.org/990f/9aa328df4c3c6503d6b7815a1ea865b9bfd1.pdf
Learning-based Entity Resolution with MapReduce,本文的整體思路還是先Blocking再matching培他,但給出了一套基于MapReduce的詳細(xì)算法流程及實(shí)現(xiàn)思路舀凛,分別明確了MapSide和ReduceSide具體策略途蒋。同時(shí)對(duì)Learning-based Entity Resolution的training stage和application stage,本文也給出了詳細(xì)的架構(gòu)設(shè)計(jì)螃壤。
Entity Resolution with Markov Logic筋帖,本文給出了基于Markov Logic的實(shí)體融合方法日麸,大體思路是把已有的知識(shí)圖譜作為強(qiáng)限制映射到圖上,再通過(guò)圖計(jì)算的方式對(duì)實(shí)體進(jìn)行融合墩划。
Load Balancing for MapReduce-based Entity Resolution嗡综,本文主要針對(duì)MapReduce中Blocking策略進(jìn)行了詳細(xì)分析极景,是大規(guī)模實(shí)體融合必須要了解的。簡(jiǎn)單的事情當(dāng)數(shù)據(jù)到一定規(guī)模后也會(huì)出問(wèn)題盼樟。
