re模塊
Python中通過re模塊使用正則表達(dá)式帘撰,該模塊提供的幾個常用方法:
1.匹配
re.match(pattern, string, flags=0)
- 參數(shù):匹配的正則表達(dá)式宇姚,要匹配的字符串咒吐,標(biāo)志位(匹配方法)
- 嘗試從字符串的開頭進(jìn)行匹配矮瘟,匹配成功會返回一個匹配的對象懦鼠,
類型是:<class '_sre.SRE_Match'>
group與groups
re.search(pattern, string, flags=0)
- 參數(shù):同上
- 掃描整個字符串搜吧,返回第一個匹配的對象盲赊,否則返回None
注意:match方法和search的最大區(qū)別:match如果開頭就不和正則表達(dá)式匹配,
直接返回None惊窖,而search則是匹配整個字符串9粝堋!
2.檢索與替換
re.findall(pattern, string, flags=0)
- 參數(shù):同上
- 遍歷字符串界酒,找到正則表達(dá)式匹配的所有位置圣拄,并以列表的形式返回
re.finditer(pattern, string, flags=0)
- 參數(shù):同上
- 遍歷字符串,找到正則表達(dá)式匹配的所有位置毁欣,并以迭代器的形式返回
re.sub(pattern, repl, string, count=0, flags=0)
-
參數(shù):repl替換為什么字符串庇谆,可以是函數(shù)岳掐,把匹配到的結(jié)果做一些轉(zhuǎn)換;
count替換的最大次數(shù)饭耳,默認(rèn)0代表替換所有的匹配串述。 - 找到所有匹配的子字符串,并替換為新的內(nèi)容
re.split(pattern, string, maxsplit=0, flags=0)
- 參數(shù):maxsplit設(shè)置分割的數(shù)量哥攘,默認(rèn)0代表所有滿足匹配的都分割
- 在正則表達(dá)式匹配的地方進(jìn)行分割剖煌,并返回一個列表
3.編譯成Pattern對象
對于會多次用到的正則表達(dá)式,我們可以調(diào)用re的compile()方法編譯成
Pattern對象逝淹,調(diào)用的時候直接Pattern對象.xxx即可,從而提高運行效率桶唐。
附:flags(可選標(biāo)志位)表
多個標(biāo)志可通過按位OR(|)進(jìn)行連接栅葡,比如:re.I|re.M
| 修飾符 | 描述 |
|---|---|
| re.I | 使匹配對大小寫不敏感 |
| re.L | 做本地化識別(locale-aware)匹配 |
| re.M | 多行匹配,影響 ^ 和 $ |
| re.S | 使 . 匹配包括換行在內(nèi)的所有字符 |
| re.U | 根據(jù)Unicode字符集解析字符尤泽。這個標(biāo)志影響 \w, \W, \b, \B. |
| re.X | 該標(biāo)志通過給予你更靈活的格式以便你將正則表達(dá)式寫得更易于理解欣簇。 |
2.正則規(guī)則詳解
1.加在正則字符串前的'r'
為了告訴編譯器這個string是個raw string(原字符串),不要轉(zhuǎn)義反斜杠坯约!
比如在raw string里\n是兩個字符熊咽,''和'n',不是換行闹丐!
2.字符
| 字符 | 作用 |
|---|---|
. |
匹配任意一個字符(除了\n) |
[] |
匹配[]中列舉的字符 |
[^...] |
匹配不在[]中列舉的字符 |
\d |
匹配數(shù)字横殴,0到9 |
\D |
匹配非數(shù)字 |
\s |
匹配空白,就是空格和tab |
\S |
匹配非空白 |
\w |
匹配字母數(shù)字或下劃線字符卿拴,a-z衫仑,A-Z粗截,0-9乘陪,_ |
\W |
匹配非字母數(shù)字或下劃線字符 |
- |
匹配范圍,比如[a-f] |
3.數(shù)量
| 字符 | 作用(前面三個做了優(yōu)化掂为,速度會更快缘挽,盡量優(yōu)先用前三個) |
|---|---|
* |
前面的字符出現(xiàn)了0次或無限次瞄崇,即可有可無 |
+ |
前面的字符出現(xiàn)了1次或無限次,即最少一次 |
? |
前面的字符出現(xiàn)了0次或者1次壕曼,要么不出現(xiàn)苏研,要么只出現(xiàn)一次 |
{m} |
前一個字符出現(xiàn)m次 |
{m,} |
前一個字符至少出現(xiàn)m次 |
{m,n} |
前一個字符出現(xiàn)m到n次 |
4.邊界
| 字符 | 作用 |
|---|---|
^ |
字符串開頭 |
$ |
字符串結(jié)尾 |
\b |
單詞邊界,即單詞和空格間的位置窝稿,比如'er\b' 可以匹配"never" 中的 'er'楣富,但不能匹配 "verb" 中的 'er' |
\B |
非單詞邊界,和上面的\b相反 |
\A |
匹配字符串的開始位置 |
\Z |
匹配字符串的結(jié)束位置 |
5.分組
用()表示的就是要提取的分組伴榔,一般用于提取子串纹蝴,
比如:^(\d{3})-(\d{3,8})$:從匹配的字符串中提取出區(qū)號和本地號碼
| 字符 | 作用 |
|---|---|

|
匹配左右任意一個表達(dá)式 |
(re) |
匹配括號內(nèi)的表達(dá)式庄萎,也表示一個組 |
| (?:re) | 同上,但是不表示一個組 |
(?P<name>) |
分組起別名塘安,group可以根據(jù)別名取出糠涛,比如(?P<first>\d)match后的結(jié)果調(diào)m.group('first')可以拿到第一個分組中匹配的記過 |
(?=re) |
前向肯定斷言,如果當(dāng)前包含的正則表達(dá)式在當(dāng)前位置成功匹配兼犯, 則代表成功忍捡,否則失敗。一旦該部分正則表達(dá)式被匹配引擎嘗試過切黔, 就不會繼續(xù)進(jìn)行匹配了砸脊;剩下的模式在此斷言開始的地方繼續(xù)嘗試。 |
(?!re) |
前向否定斷言纬霞,作用與上面的相反 |
(?<=re) |
后向肯定斷言凌埂,作用和(?=re)相同,只是方向相反 |
(?<!re) |
后向否定斷言诗芜,作用于(?!re)相同瞳抓,只是方向想法 |
附:group()方法與其他方法詳解
不引入括號,增個表達(dá)式作為一個組伏恐,是group(0)
不引入()的話孩哑,代表整個表達(dá)式作為一個組,group = group(0)
如果引入()的話翠桦,會把表達(dá)式分為多個分組横蜒,比如下面的例子:

輸出結(jié)果:

除了group方法外還有三個常用的方法:
- groups(): 從group(1)開始往后的所有的值,返回一個元組
- start():返回匹配的開始位置
- end():返回匹配的結(jié)束位置
- span():返回一個元組組秤掌,表示匹配位置(開始愁铺,結(jié)束)
貪婪與非貪婪
正則匹配默認(rèn)是貪婪匹配,也就是匹配盡可能多的字符闻鉴。
比如:ret = re.match(r'^(\d+)(0*)$','12345000').groups()?
我們的原意是想得到('12345','000')這樣的結(jié)果茵乱,但是輸出
ret我們看到的卻是:

0全給匹配了瓶竭,結(jié)果0只能匹配空字符串了,如果想盡可能少的
匹配渠羞,可以在\d+后加上一個?問號采用非貪婪匹配斤贰,改成:
r'^(\d+?)(0)$',輸出結(jié)果就變成了:
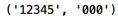
3.正則練習(xí)
例子1:簡單驗證手機號碼格式
流程分析:
- 1.開頭可能是帶0(長途)次询,86(天朝國際區(qū)號),17951(國際電話)中的一個或者一個也沒有:

- 2.接著1xx荧恍,有13x,14x,15x送巡,17x摹菠,18x,然后這個x也是取值范圍也是不一樣的:
13x:0123456789
14x:579
15x:012356789
17x:01678
18x:0123456789
然后修改下正則表達(dá)式骗爆,可以隨便輸個字符串驗證下:

- 3.最后就是剩下部分的8個數(shù)字了次氨,很簡單:[0-9]{8} 加上:

^(0|86|17951)?(13[0-9]|14[579]|15[0-35-9]|17[01678]|18[0-9])[0-9]{8}$
例子2:驗證身份證
流程分析:
身份證號碼分為一代和二代,一代由15位號碼組成摘投,而二代則是由18個號碼組成:
十五位:xxxxxx????yy mm dd ??pp s
十八位:xxxxxx yyyy mm dd ppp s
為了方便了解煮寡,把這兩種情況分開,先是十八位的:
- 1.前6位:地址編碼(省市縣)犀呼,第一位從1開始幸撕,其他五位0-9

- 2.第7到10(接著的兩位或者四位有):年,范圍是1800到2099:

- 3.第11到12:月圆凰,1-9月需要補0杈帐,10,11专钉,12

- 4.第13到14:日,首位可能是012累铅,第二位為0-9跃须,還要補上10,20娃兽,30菇民,31

- 5.第15到17:順序碼,這里就是三個數(shù)字投储,對同年第练、同月、同日出生的人
編定的順序號玛荞,奇數(shù)分給男的娇掏,偶數(shù)分給女的:

- 6.第18位:校驗碼,0到9或者x和X

能推算出18的勋眯,那么推算出15的也不難了:

最后用|組合下:

^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|10|11|12)([012][1-9]|10|20|30|31)\d{3}[0-9Xx]|[1-9]\d{5}\d{2}(0[1-9]|10|11|12)([012][1-9]|10|20|30|31)\d{2}[0-9Xx]$
另外婴梧,這里的正則匹配出的身份證不一定是合法的,判斷身份是否
合法還需要通過程序進(jìn)行校驗客蹋,校驗最后的校驗碼是否正確塞蹭。
擴(kuò)展閱讀:身份證的最后一位是怎么算出來的?
更多可見:第二代身份證號碼編排規(guī)則
首先有個加權(quán)因子的表:(沒弄懂怎么算出來的..)
[7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
然后位和值想乘讶坯,結(jié)果相加番电,最后除11求余,比如我隨便網(wǎng)上找的
一串身份證:411381199312150167辆琅,我們來驗證下最后的7是對的嗎漱办?
sum = 47 + 19 + 110 + 35 +88 + 1 4 ... + 6 * 2 = 282
sum % 11 = 7这刷,所以這個是一個合法的身份證號。
例子3:驗證ip是否正確
流程分析:
ip由4段組成洼冻,xxx.xxx.xxx.xxx崭歧,訪問從0到255,因為要考慮上中間的.
所以我們把第一段和后面三段分開撞牢,然后分析下ip的結(jié)構(gòu)率碾,可能是這幾種情況:
一位數(shù):[1-9]
兩位數(shù):[1-9][0-9]
三位數(shù)(100-199):1[0-9][0-9]
三位數(shù)(200-249):2[0-4][0-9]
三位數(shù)(250-255): 25[0-5]
理清了第一段的正則怎么寫就一清二楚了:

然后后面三段,需要在前面加上一個一個
.屋彪,然后這玩意是元字符所宰,需要加上一個反斜杠/,讓他失去作用畜挥,后面三段的正則就是:
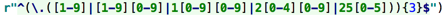
把兩段拼接下即可得出完整的驗證ip的正則表達(dá)式了:

^([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(\.([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}$
例子4:匹配各種亂七八糟的
匹配中文:
[\u4e00-\u9fa5]匹配雙字節(jié)字符:
[^\x00-\xff]-
匹配數(shù)字并輸出示例:

輸出結(jié)果: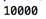
-
匹配開頭結(jié)尾示例:

輸出結(jié)果: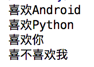
4.正則實戰(zhàn)
實戰(zhàn):抓一波城市編碼列表
本來想著就抓抓中國氣象局的天氣就好了仔粥,然后呢,比如深圳天氣的網(wǎng)頁是:
http://www.weather.com.cn/weather1dn/101280601.shtml
然后這個101280601是城市編碼蟹但,然后網(wǎng)上搜了下城市編碼列表躯泰,發(fā)現(xiàn)要么
很多是錯的,要么就缺失很多华糖,或者鏈接失效麦向,想想自己想辦法寫一個采集
的,先搞一份城市編碼的列表客叉,不過我去哪里找數(shù)據(jù)來源呢诵竭?中國氣象局
肯定是會有的,只是應(yīng)該不會直接全部暴露出來兼搏,想想能不能通過一些間接
操作來實現(xiàn)卵慰。對著中國氣象局的網(wǎng)站瞎點,結(jié)果不負(fù)有心人佛呻,我在這里:
http://www.weather.com.cn/forecast/
發(fā)現(xiàn)了這個:
點進(jìn)去后:http://www.weather.com.cn/textFC/hb.shtml#
然后裳朋,我覺得這可能是入手點:
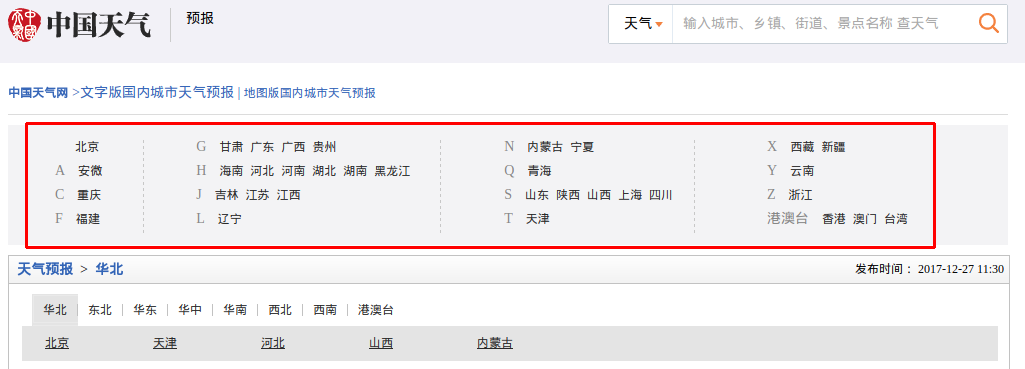
F12打開開發(fā)者工具,不出所料:
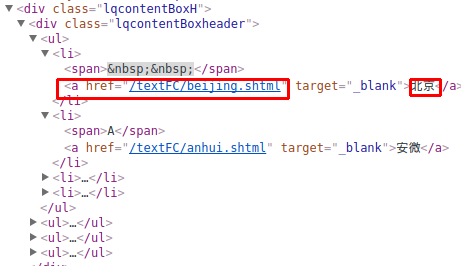
這里有個超鏈接件相,難不成是北京所有的地區(qū)的列表再扭,點擊下進(jìn)去看看:
http://www.weather.com.cn/textFC/beijing.shtml
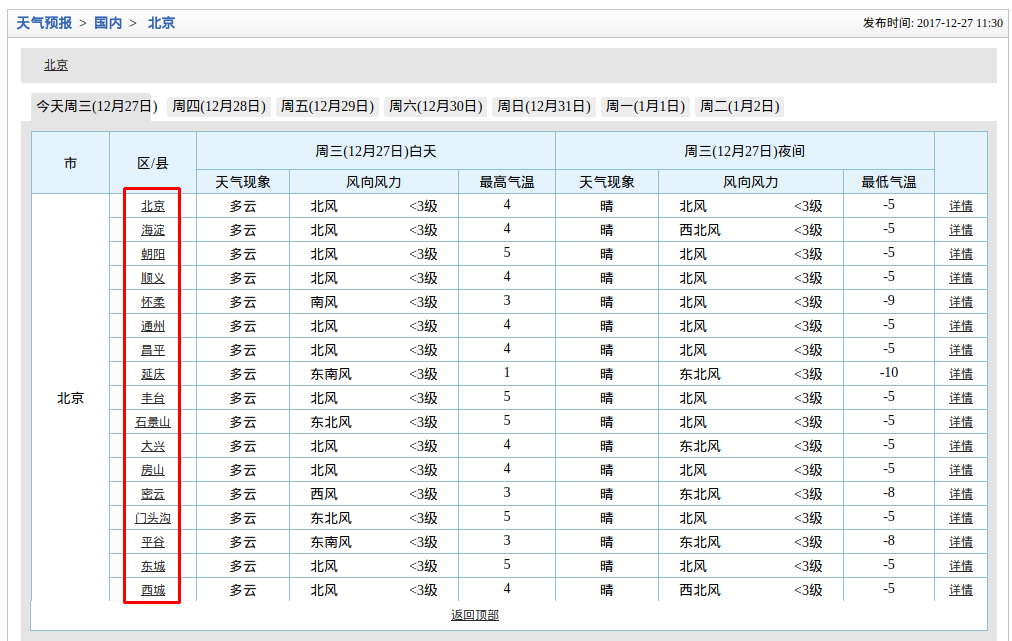
臥槽,果然是北京所有的地區(qū)夜矗,然后每個地區(qū)的名字貌似都有一個超鏈接泛范,
F12看下指向哪里?
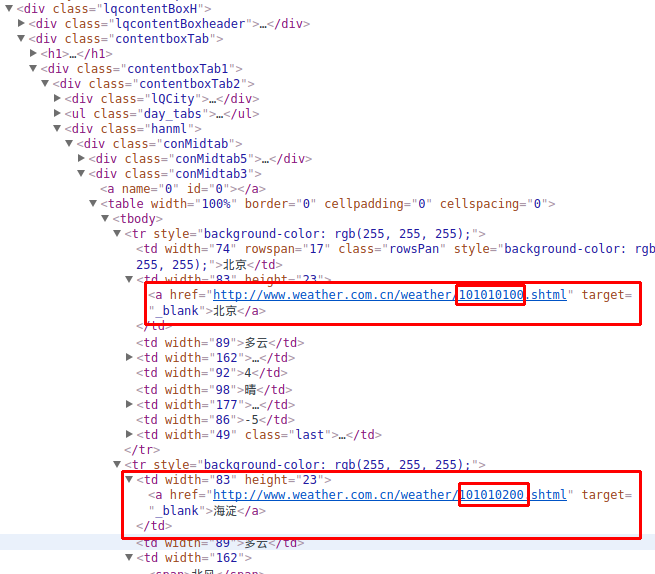
到這里就豁(huo)然開朗了紊撕,我們來捋一捋實現(xiàn)的流程:
- 1.先拿到第一層的城市列表鏈接用列表存起來
- 2.接著遍歷列表去訪問不同的城市列表鏈接罢荡,截取不同城市的城市名,城市編碼存起來
流程看上去很簡單,接著來實操一波区赵。
先是拿城市列表url

這個很容易拿惭缰,就直接貼代碼了:

拿到需要的城市列表url:

接著隨便點開一個,比如beijing.shtml笼才,頁面結(jié)構(gòu)是這樣的:
想要的內(nèi)容是這里的超鏈接:
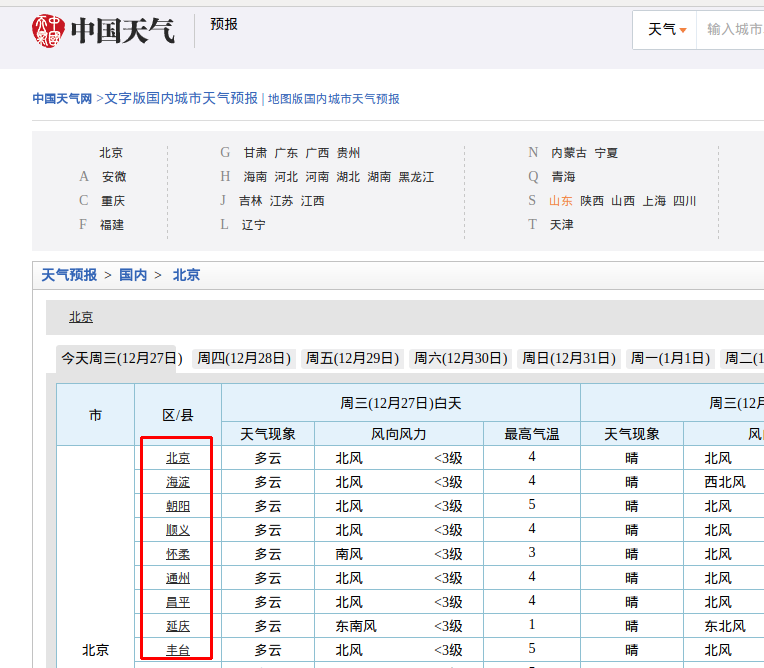
F12看下頁面結(jié)構(gòu)漱受,層次有點多,不過沒關(guān)系骡送,這樣更能夠鍛煉我們

入手點一般都是離我們想要數(shù)據(jù)最近地方下手昂羡,我看上了:conMidtab3
全局搜了一下,也就八個:

第一個直接就可以排除了:

接著其余的七個摔踱,然后發(fā)現(xiàn)都他么是一樣的...虐先,那就直接抓到第一個吧:

輸出下:

是我們想要的內(nèi)容,接著里面的tr是我們需要內(nèi)容派敷,找一波:

輸出下:

繼續(xù)細(xì)扒蛹批,我們要的只是a這個東西:
輸出下:
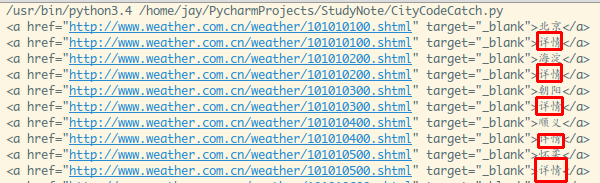
重復(fù)出現(xiàn)了一堆詳情,很明顯是我們不想要的篮愉,我們可以在循環(huán)的時候
執(zhí)行一波判斷腐芍,重復(fù)的不加入到列表中:

然后我們想拿到城市編碼和城市名稱這兩個東西:

城市的話還好,直接調(diào)用tag對象的string直接就能拿到试躏,
而城市編碼的話甸赃,按照以前的套路,我們需要先['href']拿到
再做字符串裁剪冗酿,挺繁瑣的,既然本節(jié)學(xué)習(xí)了正則络断,為何不用
正則來一步到位裁替,不難寫出這樣的正則:

匹配拿到group(1)就是我們要的城市編碼:

輸出內(nèi)容:
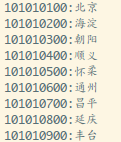
臥槽,就是我們想要的結(jié)果貌笨,美滋滋弱判,接著把之前拿到所有
的城市列表都跑一波,存字典里返回锥惋,最后賽到一個大字典
里昌腰,然后寫入到文件中,完成膀跌。
========= BUG的分割線 =========
最后把數(shù)據(jù)打印出來發(fā)現(xiàn)只有428條數(shù)據(jù)遭商,后面才發(fā)現(xiàn)conMidtab3那里處理有些
問題,漏掉了一些捅伤,限于篇幅劫流,就不重新解釋了,直接貼上修正完后的代碼把...
import urllib.request
from urllib import error
from bs4 import BeautifulSoup
import os.path
import re
import operator
# 通過中國氣象局抓取到所有的城市編碼
# 中國氣象網(wǎng)基地址
weather_base_url = "http://www.weather.com.cn"
# 華北天氣預(yù)報url
weather_hb_url = "http://www.weather.com.cn/textFC/hb.shtml#"
# 獲得城市列表鏈接
def get_city_list_url():
city_list_url = []
weather_hb_resp = urllib.request.urlopen(weather_hb_url)
weather_hb_html = weather_hb_resp.read().decode('utf-8')
weather_hb_soup = BeautifulSoup(weather_hb_html, 'html.parser')
weather_box = weather_hb_soup.find(attrs={'class': 'lqcontentBoxheader'})
weather_a_list = weather_box.findAll('a')
for i in weather_a_list:
city_list_url.append(weather_base_url + i['href'])
return city_list_url
# 根據(jù)傳入的城市列表url獲取對應(yīng)城市編碼
def get_city_code(city_list_url):
city_code_dict = {} # 創(chuàng)建一個空字典
city_pattern = re.compile(r'^<a.*?weather/(.*?).s.*</a>$') # 獲取城市編碼的正則
weather_hb_resp = urllib.request.urlopen(city_list_url)
weather_hb_html = weather_hb_resp.read().decode('utf-8')
weather_hb_soup = BeautifulSoup(weather_hb_html, 'html.parser')
# 需要過濾一波無效的
div_conMidtab = weather_hb_soup.find_all(attrs={'class': 'conMidtab', 'style': ''})
for mid in div_conMidtab:
tab3 = mid.find_all(attrs={'class': 'conMidtab3'})
for tab in tab3:
trs = tab.findAll('tr')
for tr in trs:
a_list = tr.findAll('a')
for a in a_list:
if a.get_text() != "詳情":
# 正則拿到城市編碼
city_code = city_pattern.match(str(a)).group(1)
city_name = a.string
city_code_dict[city_code] = city_name
return city_code_dict
# 寫入文件中
def write_to_file(city_code_list):
try:
with open('city_code.txt', "w+") as f:
for city in city_code_list:
f.write(city[0] + ":" + city[1] + "\n")
except OSError as reason:
print(str(reason))
else:
print("文件寫入完畢!")
if __name__ == '__main__':
city_result = {} # 創(chuàng)建一個空字典祠汇,用來存所有的字典
city_list = get_city_list_url()
# get_city_code("http://www.weather.com.cn/textFC/guangdong.shtml")
for i in city_list:
print("開始查詢:" + i)
city_result.update(get_city_code(i))
# 根據(jù)編碼從升序排列一波
sort_list = sorted(city_result.items(), key=operator.itemgetter(0))
# 保存到文件中
write_to_file(sort_list)
運行結(jié)果:

5.小結(jié)和幾個API
本節(jié)對Python中了正則表達(dá)式進(jìn)行了一波學(xué)習(xí)仍秤,練手,發(fā)現(xiàn)和Java里的正則
多了一些規(guī)則可很,正則在字符串匹配的時候是挺爽的诗力,但是正則并不是全能
的,比如閏年二月份有多少天的那個問題我抠,還需要程序另外去做判斷苇本!
正則還需要多練手啊,限于篇幅屿良,就沒有另外去抓各種天氣信息了圈澈,
而且不是剛需,順道提供兩個免費可用三個和能拿到天氣數(shù)據(jù)的API吧:
- 小米:http://weatherapi.market.xiaomi.com/wtr-v2/weather?cityId=101280601
- 魅族:http://aider.meizu.com/app/weather/listWeather?cityIds=101280601
還有個中國氣象局提供的根據(jù)經(jīng)緯度獲取天氣的:
http://e.weather.com.cn/d/town/index?lat=22.5383&lon=113.9524
人生苦短尘惧,我用Python康栈,爬蟲真好玩!期待下節(jié)爬蟲框架scrapy學(xué)習(xí)~

來啊喷橙,Py交易啊
想加群一起學(xué)習(xí)Py的可以加下啥么,智障機器人小Pig,驗證信息里包含:
Python贰逾,python悬荣,py,Py疙剑,加群氯迂,交易,屁眼 中的一個關(guān)鍵詞即可通過言缤;

驗證通過后回復(fù) 加群 即可獲得加群鏈接(不要把機器人玩壞了=朗础!管挟!)~~~
歡迎各種像我一樣的Py初學(xué)者轿曙,Py大神加入,一起愉快地交流學(xué)♂習(xí)僻孝,van♂轉(zhuǎn)py导帝。

