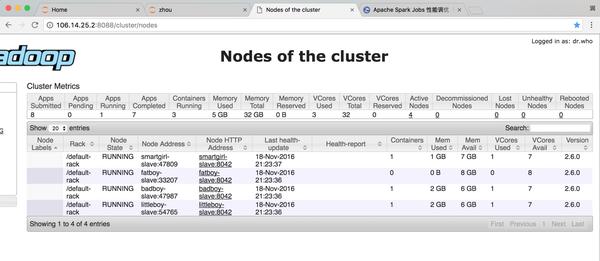
準(zhǔn)備工作:
hostname *** #配置HOSTvi /etc/hosts #配置IP和HOST映射.ssh/authorized_keys #配置SSH通道
第一次嘗試:
最方便的當(dāng)然是用 Ambari**(Apache Software Foundation 下的一個頂級項目)可視化安裝捕虽,
選擇要安裝的服務(wù)碉碉,如HDFS、Yarn究西、Zookeeper锄列、Hive图云、Spark等;
對每個服務(wù)進(jìn)行配置操作邻邮,選擇每個服務(wù)的 Master & Slave 安裝在哪些節(jié)點上竣况;
開始安裝,顯示成功或失敗的結(jié)果及日志筒严。
詳細(xì):http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/**
但是小潤在安裝的時候進(jìn)度總卡住丹泉,然后因為超時就 failed 了,好氣啊鸭蛙。
第二次嘗試
自己手動搭建咯...
注意:學(xué)校的鏡像源#wget 安裝包http://mirrors.hust.edu.cn/apache/
配置環(huán)境變量vi ~/.bashrcexport JAVA_HOME=/usr/jdk64/jdk1.8.0_77export JRE_HOME=/usr/jdk64/jdk1.8.0_77/jreexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATHexport CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/libexport HADOOP_HOME=/usr/local/hadoop-2.6.0export PATH=$HADOOP_HOME/bin:$PATHexport SPARK_HOME=/usr/local/sparkexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinexport PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/build:$PYTHONPATHexport PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH
安裝 Java
安裝 Scala
安裝 Hadoop 及配置cd $HADOOP_HOME/etc/hadoop#具體修改見下面的鏈接vi core-site.xmlvi hdfs-site.xmlvi yarn-site.xmlvi hadoop-env.shvi slavescd $HADOOP_HOME#啟動sbin/start-dfs.shsbin/start-yarn.sh
安裝 Spark 及配置
spark的3種運行模式:Standalone Deploy Mode**摹恨、Apache Mesos**、Hadoop YARN**
cd $SPARK_HOME/conf#具體修改見下面的鏈接vi spark-env.shvi slavescd $SPARK_HOME#啟動sbin/start-all.sh
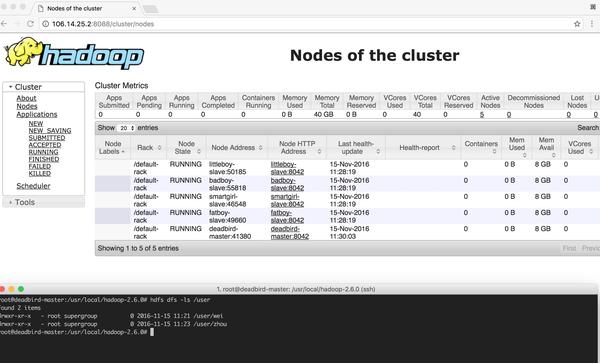
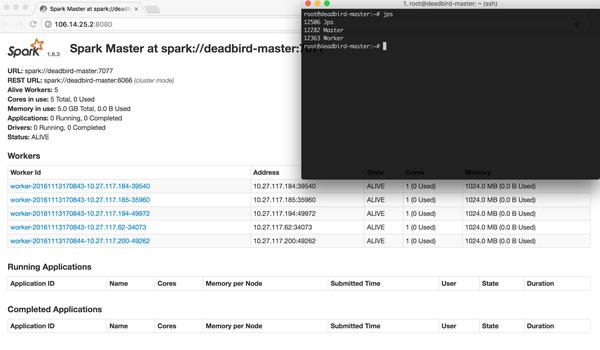
Master 上的進(jìn)程:
root@deadbird-master:~# jps9824 Master9219 NameNode9402 SecondaryNameNode9546 ResourceManager12494 Jps
其中一個 Slave 上的進(jìn)程:
root@smartgirl-slave:~# jps18212 Worker18057 NodeManager17946 DataNode18461 Jps
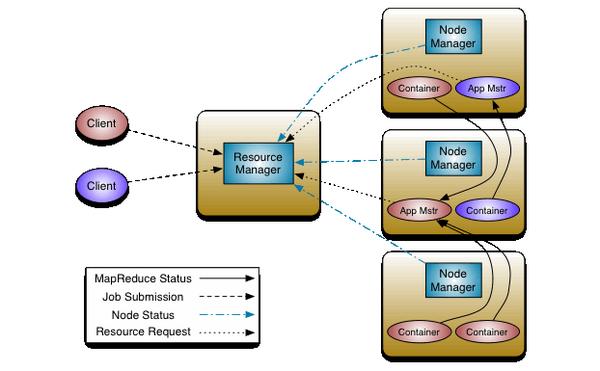
手動安裝一番過后,小潤更好地理解了集群配置肪获,稍稍體會到了運行機制寝凌。
續(xù):
接下來配置了 zeppelin** 的 interpreter,交互式地來操作(支持Spark孝赫、Scala硫兰、SQL等)