Recurrent Neural Networks(RNNs)作為一個(gè)很受歡迎的模型破托,已經(jīng)在許多NLP任務(wù)展現(xiàn)了巨大的潛力。但是盡管他們最近很受歡迎中姜,我還是僅找到一些很少的關(guān)于RNN如何工作拖刃,怎樣實(shí)現(xiàn)他們的資料。這就是這個(gè)教程的目的骂因。這是一個(gè)多系列的教程我計(jì)劃包含如下部分:
- Introduction to RNNs (this post)
- Implementing a RNN using Python and Theano
- Understanding the Backpropagation Through Time (BPTT) algorithm and the vanishing gradient problem
- Implementing a GRU/LSTM RNN
在教程中我們會(huì)實(shí)現(xiàn) recurrent neural network based language model。這個(gè)語(yǔ)言模型的應(yīng)用有2個(gè)部分:第一赃泡,它允許我們基于現(xiàn)實(shí)世界的句子(sentences)給任意的句子(sentences)打分.這給我們提供一個(gè)度量語(yǔ)法和語(yǔ)義正確性的方法寒波。這樣的一個(gè)典型模型被用做機(jī)器翻譯系統(tǒng)上。第二升熊,一個(gè)可以生成新文本的語(yǔ)言模型(我認(rèn)為這是非扯硭福酷的一個(gè)應(yīng)用)。在莎士比亞文集(Shakespeare)上訓(xùn)練語(yǔ)言模型级野,生成莎士比亞文體的文本页屠。Andrej Karpathy描述了一個(gè)基于RNNs的字符級(jí)的語(yǔ)言模型。
我假設(shè)你對(duì)基本的神經(jīng)網(wǎng)絡(luò)有些熟悉蓖柔。如果不辰企,那你可能回過(guò)頭去看看Implementing A Neural Network From Scratch,這會(huì)知道你理解和實(shí)現(xiàn)non-recurrent networks况鸣。
什么是RNNs牢贸?
RNNs就是利用序列信息。在傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)里镐捧,我們假設(shè)所有的輸入(和輸出)都是相互獨(dú)立的十减。但是對(duì)很多任務(wù)來(lái)說(shuō)這是一個(gè)很壞的主意。如果你想預(yù)測(cè)一個(gè)句子中的下一個(gè)詞愤估,你最好知道之前的詞。RNNs被叫做recurrent因?yàn)樗鼈冊(cè)谛蛄兄械拿總€(gè)元素都完成相同的任務(wù)速址,輸入都依賴(lài)于前一步的計(jì)算玩焰。對(duì)RNNs的其他理解是把它們看作是一個(gè)能獲取之前計(jì)算信息的記憶("memory")。理論上的RNNs能利用任意長(zhǎng)度的序列信息芍锚,但是實(shí)際中它們受限于很少的幾步昔园。下面是一個(gè)典型的RNN:
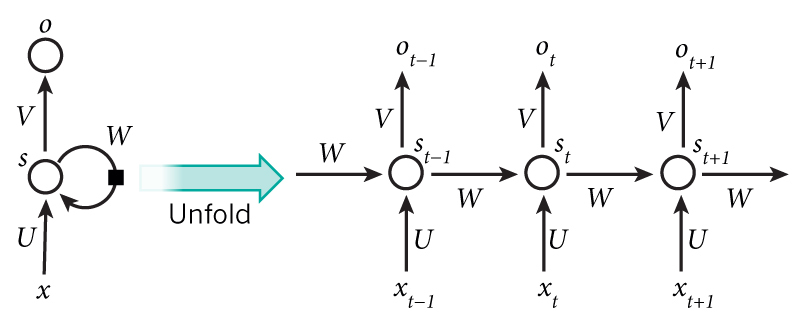
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
上面的圖展示了RNN展開(kāi)為一個(gè)全網(wǎng)絡(luò)蔓榄。通過(guò)展開(kāi)我們簡(jiǎn)單的寫(xiě)出了完整序列的網(wǎng)絡(luò)。例如默刚,如果這個(gè)序列只有5個(gè)詞甥郑,網(wǎng)絡(luò)就展開(kāi)成5層神經(jīng)網(wǎng)絡(luò),每一次一個(gè)單詞荤西。RNN中的公式計(jì)算如下:
- $x_t$是在時(shí)間步$t$的輸入澜搅,例如,$x_1$可以是one-hot表示的序列中的第二個(gè)詞
- $s_t$是隱藏狀態(tài)在時(shí)間步$t$邪锌。這是網(wǎng)絡(luò)的"memory"勉躺,$s_t$基于前面隱藏狀態(tài)和當(dāng)前輸入步計(jì)算:$s_t=f(Ux_t + Ws_{t-1})$.函數(shù)$f$通常采用非線性的$tanh$和$ReLU$.$s_{-1}$是需要計(jì)算的第一個(gè)隱藏狀態(tài),最典型的初始化是全為0觅丰。
- $o_t$是時(shí)間步t的輸出饵溅。例如,如果你希望預(yù)測(cè)句子中的下一個(gè)詞妇萄,它可能是一個(gè)向量的概率:$o_t=softmax(Vs_t)$
這里有一些需要注意的事:
- 你可以把隱藏狀態(tài)$s_t$認(rèn)為是一個(gè)網(wǎng)絡(luò)的記憶蜕企。$s_t$獲取之前所有時(shí)間步的信息。輸入$o_t$單獨(dú)基于時(shí)間$t$的記憶.下面簡(jiǎn)單提及冠句,在實(shí)際中會(huì)更加復(fù)雜一點(diǎn)轻掩,因?yàn)?s_t$不能從之前時(shí)間步獲取太多信息.
- 不同于傳統(tǒng)的深度神經(jīng)網(wǎng)絡(luò),在每一層使用不同的參數(shù)轩端,RNN在所有步共享相同的參數(shù)($U,V,W$)這反應(yīng)了一個(gè)事實(shí)放典,我們?cè)诿恳徊蕉紙?zhí)行相同的任務(wù),只是使用了不同的輸入基茵。這極大的減少的我們需要學(xué)習(xí)的參數(shù)數(shù)量奋构。
- 上圖的每一步的輸出,根據(jù)任務(wù)可能是不需要的拱层。例如弥臼,句子情感預(yù)測(cè)的時(shí)候,我們只關(guān)注最后的輸出根灯,而不是每個(gè)詞的情感径缅。相似的,我們可能不需要每次的輸入烙肺。RNN的主要特點(diǎn)是它的隱藏狀態(tài)纳猪,它獲取序列的一些信息。
RNNs能做什么桃笙?
RNNs在許多NLP任務(wù)展現(xiàn)了巨大的成功氏堤。這個(gè)點(diǎn)來(lái)說(shuō)我會(huì)提及最通用的RNNs模型LSTMs,更好的捕獲長(zhǎng)距離依賴(lài)搏明。但是不用擔(dān)心鼠锈,LSTMs本質(zhì)上和RNN做的是同樣的事情闪檬,他們只是在計(jì)算隱藏狀態(tài)上的方法不同。在后面我們會(huì)有更詳細(xì)的LSTMs介紹购笆。這里列舉一些RNNs在NLP的一些應(yīng)用粗悯。
語(yǔ)言模型和生成模型
給定一個(gè)序列,我們希望給定前面的詞預(yù)測(cè)每一個(gè)詞的概率同欠。語(yǔ)言模型度量句子的相似样傍,這對(duì)于機(jī)器翻譯來(lái)說(shuō)是很重要的(概率高的句子代表正確)。通過(guò)輸出概率中抽樣生成新文本行您,預(yù)測(cè)下一個(gè)單詞我們可以得到一個(gè)生成模型铭乾。訓(xùn)練數(shù)據(jù)決定了我們生成的東西。在語(yǔ)言模型里面我們的輸入是典型的單詞序列(例如使用one-hot向量編碼)娃循,我們的輸入是序列的預(yù)測(cè)詞炕檩。當(dāng)訓(xùn)練網(wǎng)絡(luò)時(shí)我們?cè)O(shè)置$o_t=x_{t+1}$是我們想要的時(shí)間步$t$的輸出也就是下一個(gè)實(shí)際的詞。
關(guān)于語(yǔ)言模型和文本生成的研究論文:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
機(jī)器翻譯
機(jī)器翻譯類(lèi)似于語(yǔ)言模型捌斧,從原始語(yǔ)言(eg.德語(yǔ))輸入的詞序列笛质,我們希望輸入目標(biāo)語(yǔ)言(eg. 英語(yǔ))的詞序列.一個(gè)關(guān)鍵的不同在于我們的輸出只有在完全輸入之后才能看見(jiàn),因?yàn)槲覀兎g的句子的第一詞可能需要捕獲完整的輸入序列.
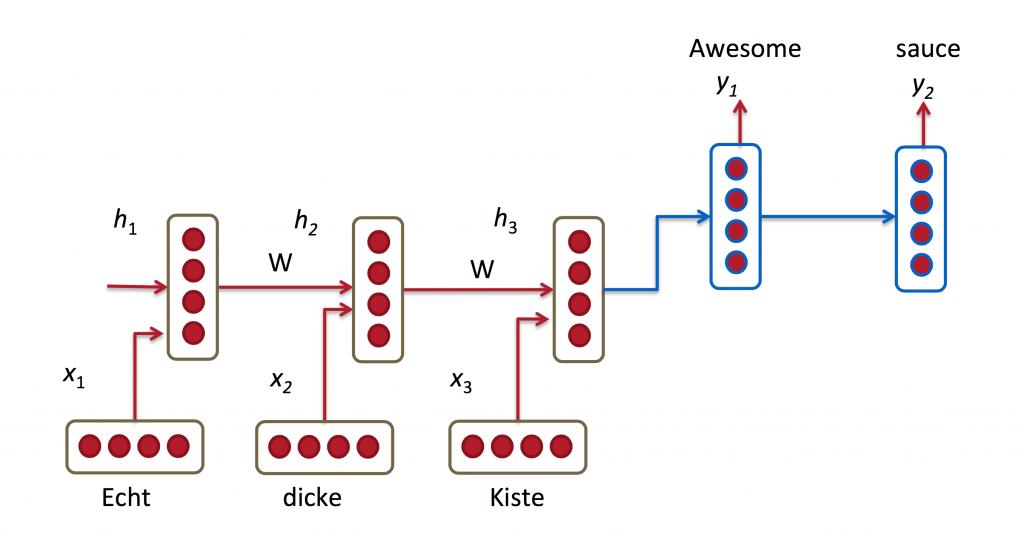
RNN for Machine Translation. Image Source:http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
關(guān)于機(jī)器翻譯的研究論文:
- A Recursive Recurrent Neural Network for Statistical Machine
- Translation Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
語(yǔ)音識(shí)別
給定聲波的語(yǔ)音信號(hào)序列捞蚂,我們可以一起預(yù)測(cè)語(yǔ)音片段的序列的概率
語(yǔ)音識(shí)別的研究論文:
生成圖像描述
結(jié)合卷積神經(jīng)網(wǎng)絡(luò)妇押,RNNs被用作無(wú)標(biāo)簽圖像的描述生成。很神奇它是如何工作的姓迅。這個(gè)聯(lián)合模型使用圖像中的特征生成詞敲霍。
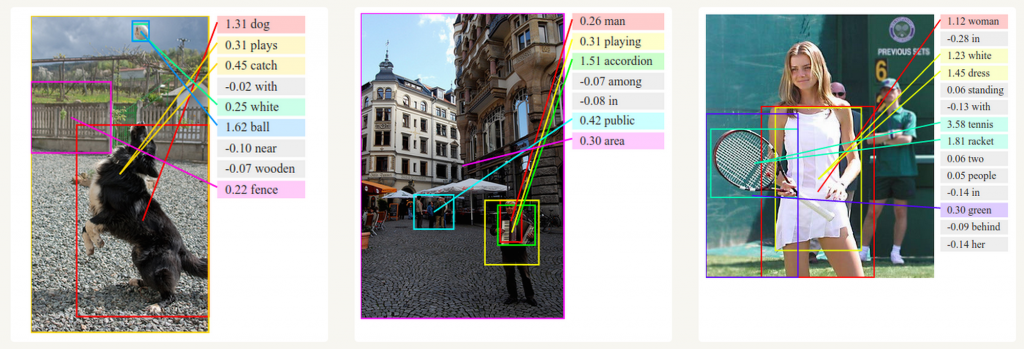
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
訓(xùn)練RNNs
訓(xùn)練RNN和訓(xùn)練傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)很相似。我們同樣使用后向傳播算法丁存,但是有一些曲折肩杈。因?yàn)閰?shù)在所有時(shí)間步共享,梯度在每一次輸觸不僅依賴(lài)于計(jì)算當(dāng)前時(shí)間步解寝,也需要前面的時(shí)間步扩然。例如,為了計(jì)算時(shí)間步$t=4$的梯度聋伦,我們需要時(shí)間步3和梯度求和夫偶。這被稱(chēng)作定時(shí)后向傳播(Backpropagation Through Time).如果這對(duì)你還沒(méi)有一個(gè)整體的概念,不要擔(dān)心觉增,后面我們會(huì)有更詳細(xì)的介紹”#現(xiàn)在,只需要知道原始的RNNs使用BPTT訓(xùn)練有長(zhǎng)距離依賴(lài)的問(wèn)題逾礁。這主要由于梯度爆炸和梯度消失問(wèn)題引發(fā)说铃。存在一些工具來(lái)處理這些問(wèn)題,某些類(lèi)型的RNNs(LSTMs)是專(zhuān)門(mén)設(shè)計(jì)來(lái)規(guī)避這個(gè)問(wèn)題的。
RNN 擴(kuò)展
多年以來(lái)研究者們?cè)O(shè)計(jì)更加復(fù)雜的RNNs來(lái)處理原始RNN模型的缺陷截汪。我們會(huì)在后面的覆蓋更多的內(nèi)容,但是在這個(gè)部分我想給你一個(gè)簡(jiǎn)介使你能熟悉模型的分類(lèi)植捎。
Bidirectional RNNs(雙向RNN):思想基于在時(shí)間步t的輸出不僅依賴(lài)于序列中前面的元素也依賴(lài)于未來(lái)的元素衙解。例如,預(yù)測(cè)一個(gè)序列中的缺失值焰枢,你需要考慮左右上下文蚓峦。
Bidirectional RNNs是很簡(jiǎn)單的。他們只是2個(gè)RNNs堆疊而成济锄。輸出基于兩個(gè)RNNs的隱藏層暑椰。
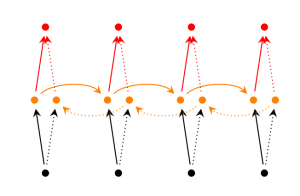
Deep (Bidirectional) RNNs (深度RNNs):類(lèi)似于雙向RNNs,只是現(xiàn)在每一個(gè)時(shí)間步有多個(gè)層荐绝。實(shí)踐中這給我更好的學(xué)習(xí)能力(但是也需要大量的訓(xùn)練數(shù)據(jù))
LSTM network:最近很流行不同于我們上面談?wù)撨^(guò)的模型一汽。LSTMs并不是基礎(chǔ)架構(gòu)上不同于RNNs,而是在計(jì)算隱藏狀態(tài)的不同低滩。LSTMs中的記憶叫做cell召夹,可以把它們看作是一個(gè)使用前一個(gè)狀態(tài)$h_{t-1}$和當(dāng)前輸入$x_t$的一個(gè)黑盒。在內(nèi)部恕沫,cells決定該保留(擦除)那些記憶监憎。然后聯(lián)合前面狀態(tài),當(dāng)前記憶和輸入婶溯。事實(shí)證明這種類(lèi)型的神經(jīng)元能有效處理長(zhǎng)距離問(wèn)題鲸阔。LSTMs一開(kāi)始很讓人困惑,但是如果你有興趣了解更多這是一個(gè)優(yōu)秀的解釋
結(jié)論
到目前為止迄委。我希望你基本明白了關(guān)于什么是RNNs以及他們能做什么褐筛。在下一個(gè)帖子里,我們會(huì)用Python和Theano實(shí)現(xiàn)RNN的第一個(gè)版本跑筝。
