前言
模式匹配是數(shù)據(jù)結(jié)構(gòu)需要解決的經(jīng)典問題之一缀辩,由此衍生出許多算法。本文介紹模式匹配算法的復(fù)雜度從o(mn)逐步演化到o(m+n)的過程萤厅。
模式匹配
模式匹配描述了這樣的一個(gè)問題:
字符串
T[1..n]和P[1..m]由字符集∑中的字符組成(m<=n),要求字符串T中和模式P所匹配的索引號(hào)焚刚。
樸素模式匹配算法
這個(gè)問題最簡(jiǎn)單的解決辦法是:
從T的每一個(gè)字符
T[i]{1≤i≤n}開始依次向后比對(duì)P的每一個(gè)字符,如果全部匹配净薛,則輸出i汪榔;重復(fù)之前的操作,直到找到所有符合條件的i肃拜。
代碼如下:
object KMPv1 {
def kmp(source:String,sequence: String):scala.collection.mutable.Seq[Int] = {
val sourceLen = source.length
val sequenceLen = sequence.length
if(sourceLen<sequenceLen)
return scala.collection.mutable.Seq.empty[Int]
var cursor = 0
val cursorMax = sourceLen-sequenceLen+1
var res:scala.collection.mutable.Seq[Int] = scala.collection.mutable.Seq[Int]()
while(cursor<cursorMax){//m-n+1
var isMatch = true
var cursorInner = 0
while(isMatch && cursorInner<sequenceLen){//m
isMatch = source.charAt(cursor+cursorInner) == sequence.charAt(cursorInner)
cursorInner+=1
}
if(isMatch){
res = res.:+(cursor)
}
cursor+=1
}
res
}
}
這個(gè)算法的復(fù)雜度是o(m*(n-m+1))=o(mn),它并沒有利用到曾經(jīng)匹配過的信息雌团。
有限自動(dòng)機(jī)的思想
有限自動(dòng)機(jī)在接受到一個(gè)信號(hào)之后燃领,會(huì)從一個(gè)狀態(tài)轉(zhuǎn)移到另外一種狀態(tài)。
引入有限自動(dòng)機(jī)的概念之后可以對(duì)模式匹配問題作如下變形:
將字符串
T[1..n]中的字符T[i]{1≤i≤n}依次輸入有限自動(dòng)機(jī)锦援,自動(dòng)機(jī)的狀態(tài)q記錄了信號(hào)輸入之后與P[1..m]相匹配的字符數(shù),當(dāng)自動(dòng)機(jī)的狀態(tài)轉(zhuǎn)移到m時(shí)我們接受此時(shí)的索引i-m為匹配索引猛蔽。
舉例來說:
假設(shè)P=ababaca由∑={a,b,c}中的字符組成,有限自動(dòng)機(jī)的初始狀態(tài)是0灵寺,在這個(gè)時(shí)候接受輸入a則轉(zhuǎn)移到狀態(tài)1(因?yàn)檩斎?code>a之后和P有一個(gè)匹配的字符)曼库;在狀態(tài)為1的時(shí)候接受輸入a則狀態(tài)仍然是1,接受b則狀態(tài)轉(zhuǎn)移為2略板,接受c則狀態(tài)轉(zhuǎn)移為0(因?yàn)楦?code>P沒有匹配的字符)毁枯。
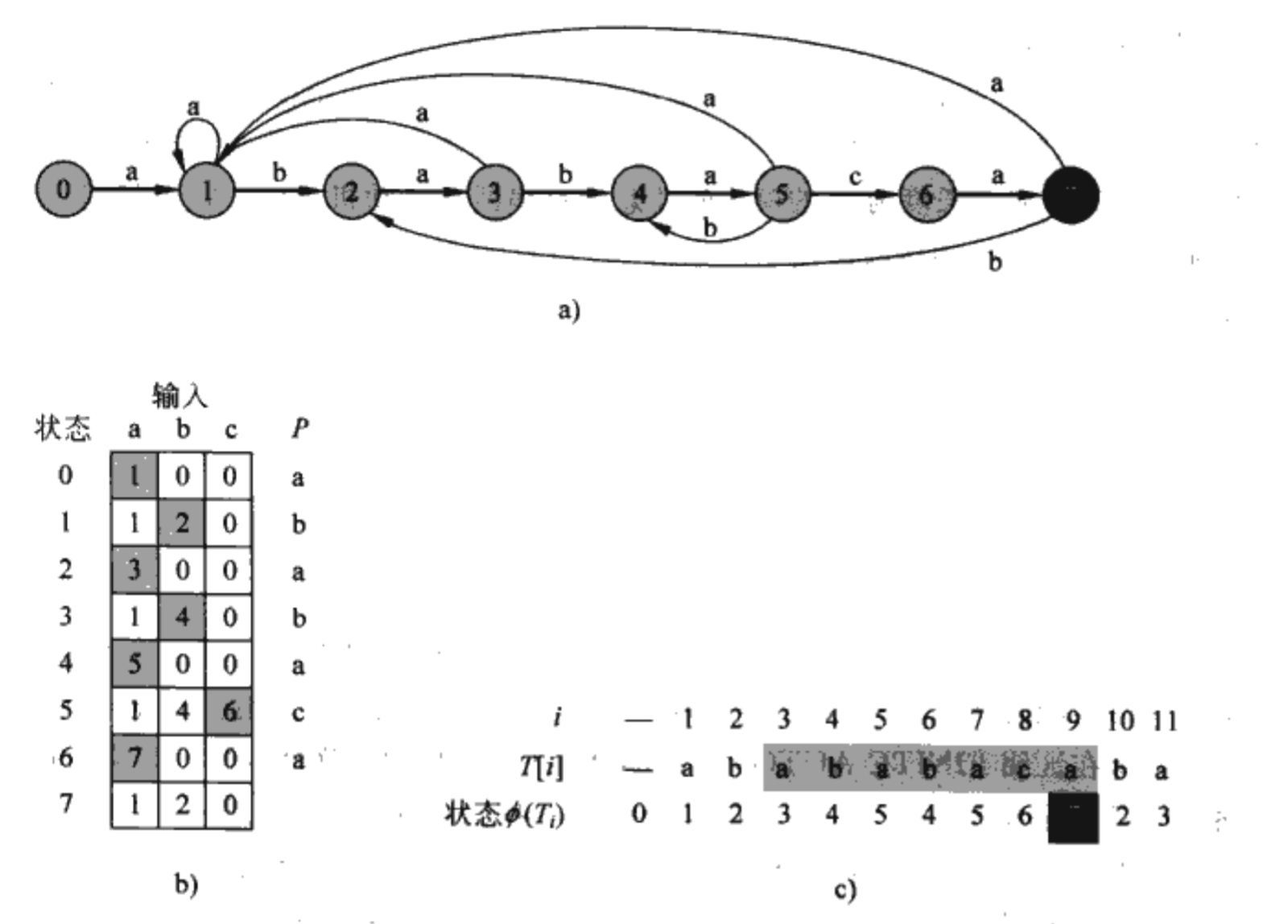
顯然這個(gè)思想的關(guān)鍵在于構(gòu)造出有限自動(dòng)機(jī)的轉(zhuǎn)移函數(shù)?(q,signal)。從上圖b可知叮称,該函數(shù)只與m和|∑|(全集的字符個(gè)數(shù))有關(guān)种玛,該表共有(m+1)|∑|個(gè)狀態(tài)值,計(jì)算每個(gè)狀態(tài)值的復(fù)雜度最多是o(m^2)瓤檐,所以構(gòu)造轉(zhuǎn)移函數(shù)的復(fù)雜度最多達(dá)到o(|∑|m^3)赂韵。之后與T來匹配只需要o(n)的復(fù)雜度。整個(gè)算法的復(fù)雜度最多是o(n+|∑|m^3)挠蛉。
此算法的復(fù)雜度遠(yuǎn)遠(yuǎn)大于樸素模式匹配算法的o(mn)祭示,但是它充分利用曾經(jīng)匹配過的信息(存儲(chǔ)在有限自動(dòng)機(jī)的狀態(tài)中),給了我們另外一種思路來思考這個(gè)問題谴古,如果能將轉(zhuǎn)移函數(shù)的復(fù)雜度優(yōu)化到o(m)质涛,就可以大大降低整體的復(fù)雜度悄窃。
KMP算法
KMP算法在有限自動(dòng)機(jī)的思想上做了一些調(diào)整,同樣引入了狀態(tài)這一概念蹂窖,但是狀態(tài)并不是由狀態(tài)轉(zhuǎn)移函數(shù)計(jì)算得到轧抗,而是通過前綴函數(shù)進(jìn)行邏輯運(yùn)算之后計(jì)算出來的。
舉例來說:
如下圖a瞬测,在輸入T[9]=b之前横媚,整個(gè)匹配過程處于狀態(tài)q=5,即T[4..8]=P[0..4]月趟,此時(shí)輸入T[9]=b灯蝴,發(fā)現(xiàn)和P[5]=c不匹配,此時(shí)通過觀察發(fā)現(xiàn):
將
P向右移動(dòng)2個(gè)位置剛好又有P[0..2]和T[6..8]匹配孝宗,此時(shí)狀態(tài)是q=3穷躁。
輸入T[9]=b之后發(fā)現(xiàn)匹配則狀態(tài)變成q=4。
嘗試將上述的觀察過程理論化因妇,發(fā)現(xiàn)因?yàn)?code>P[0..4]的所有前綴中(除開P[0..4]本身)问潭,與T[4..8]的后綴所匹配的最大長(zhǎng)度是31,所以嘗試將P向右移動(dòng)[當(dāng)前狀態(tài)q=5減去3等于2]個(gè)位置婚被;又由于有T[4..8]=P[0..4]狡忙,所以1處與T[4..8]作匹配等價(jià)于與P[0..4]作匹配。
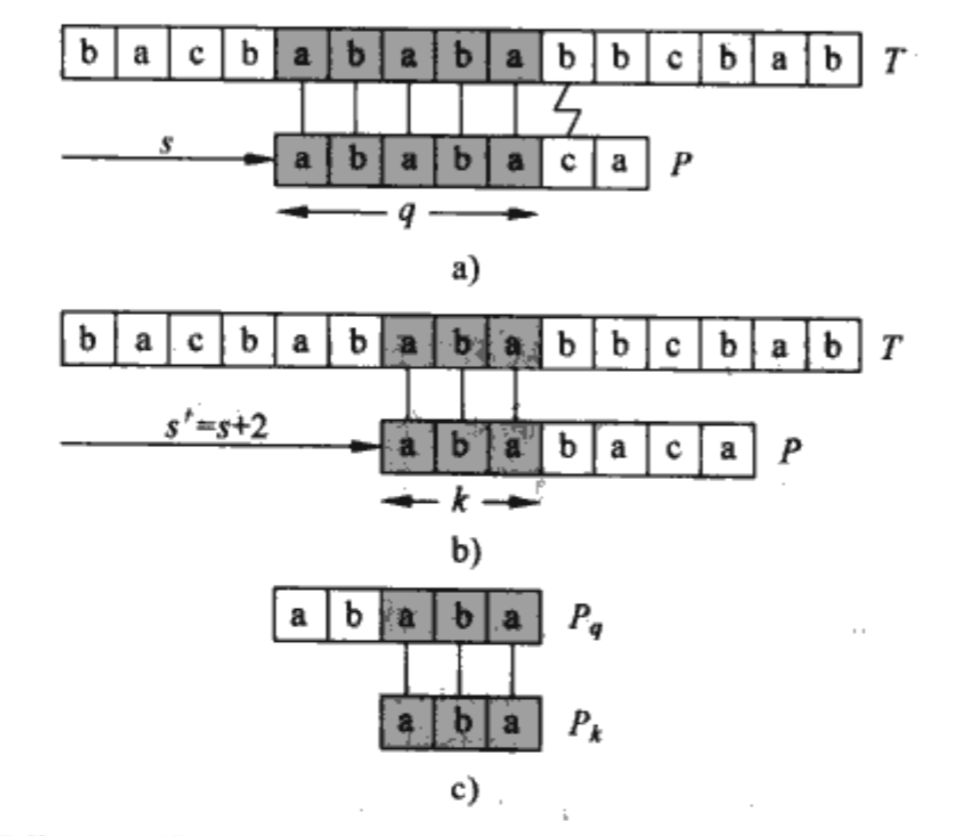
由此址芯,下一個(gè)狀態(tài)可以通過當(dāng)前狀態(tài)q和與P[1..q]的后綴匹配的最長(zhǎng)前綴(除開自身)的函數(shù)來計(jì)算出灾茁。
計(jì)算前綴函數(shù)的偽代碼如下:

匹配函數(shù)的偽代碼如下:

scala實(shí)現(xiàn)如下:
/**
* Created by studyz on 17/3/16.
*/
object KMPv2 {
def kmpMatch(source:String, pattern: String):scala.collection.mutable.Seq[Int] = {
var res = scala.collection.mutable.Seq[Int]()
val statusArr = kmpPrefixFunc(pattern)
var k =0//表示已經(jīng)匹配的個(gè)數(shù)
val n = source.length
val m = pattern.length
for(q <- 0 until n){//n次
while(k>0 && source.charAt(q) != pattern.charAt(k)){
k = statusArr(k-1)
}
if(source.charAt(q) == pattern.charAt(k)){
k+=1
}
if(k == m){
res = res.:+(q-m+1)
k = statusArr(k-1)
}
}
res
}
//pattern字符串第k位前綴的與自身匹配的最長(zhǎng)后綴
//P[1..m],1≤q≤m,0≤k<q,求k使得P[1..k]是P[1..q]的最長(zhǎng)后綴谷炸,kmpPrefixFunc(q)=k
def kmpPrefixFunc(pattern:String):Array[Int]={
val m = pattern.length
val res = new Array[Int](m)
res(0) = 0
var k = res(0)
for(q <- 1 until m){
while(k>0 && pattern.charAt(k) != pattern.charAt(q)){
k = res(k)
}
if(pattern.charAt(k) == pattern.charAt(q)){
k+=1
}
res(q) = k
}
res
}
}
使用平攤分析法可知此算法的復(fù)雜度是o(m+n)北专,其中前綴函數(shù)kmpPrefixFunc的復(fù)雜度是o(m),匹配函數(shù)kmpMatch的復(fù)雜度是o(n)旬陡。(//TODO)
參考文獻(xiàn):
- 算法導(dǎo)論第三版
