1 數(shù)據(jù)傾斜調(diào)優(yōu)
1.1 調(diào)優(yōu)概述
有的時候,我們可能會遇到大數(shù)據(jù)計算中一個最棘手的問題——數(shù)據(jù)傾斜万俗,此時Spark作業(yè)的性能會比期望差很多湾笛。數(shù)據(jù)傾斜調(diào)優(yōu),就是使用各種技術(shù)方案解決不同類型的數(shù)據(jù)傾斜問題闰歪,以保證Spark作業(yè)的性能嚎研。
2.2 數(shù)據(jù)傾斜發(fā)生時的現(xiàn)象
- 絕大多數(shù)task執(zhí)行得都非常快课竣,但個別task執(zhí)行極慢。比如置媳,總共有1000個task于樟,997個task都在1分鐘之內(nèi)執(zhí)行完了,但是剩余兩三個task卻要一兩個小時拇囊。這種情況很常見迂曲。
- 原本能夠正常執(zhí)行的Spark作業(yè),某天突然報出OOM(內(nèi)存溢出)異常寥袭,觀察異常棧路捧,是我們寫的業(yè)務(wù)代碼造成的关霸。這種情況比較少見。
2.3 數(shù)據(jù)傾斜發(fā)生的原理
數(shù)據(jù)傾斜的原理很簡單:在進行shuffle的時候杰扫,必須將各個節(jié)點上相同的key拉取到某個節(jié)點上的一個task來進行處理队寇,比如按照key進行聚合或join等操作。此時如果某個key對應(yīng)的數(shù)據(jù)量特別大的話章姓,就會發(fā)生數(shù)據(jù)傾斜佳遣。比如大部分key對應(yīng)10條數(shù)據(jù),但是個別key卻對應(yīng)了100萬條數(shù)據(jù)凡伊,那么大部分task可能就只會分配到10條數(shù)據(jù)零渐,然后1秒鐘就運行完了;但是個別task可能分配到了100萬數(shù)據(jù)系忙,要運行一兩個小時诵盼。因此,整個Spark作業(yè)的運行進度是由運行時間最長的那個task決定的银还。
因此出現(xiàn)數(shù)據(jù)傾斜的時候风宁,Spark作業(yè)看起來會運行得非常緩慢,甚至可能因為某個task處理的數(shù)據(jù)量過大導(dǎo)致內(nèi)存溢出见剩。
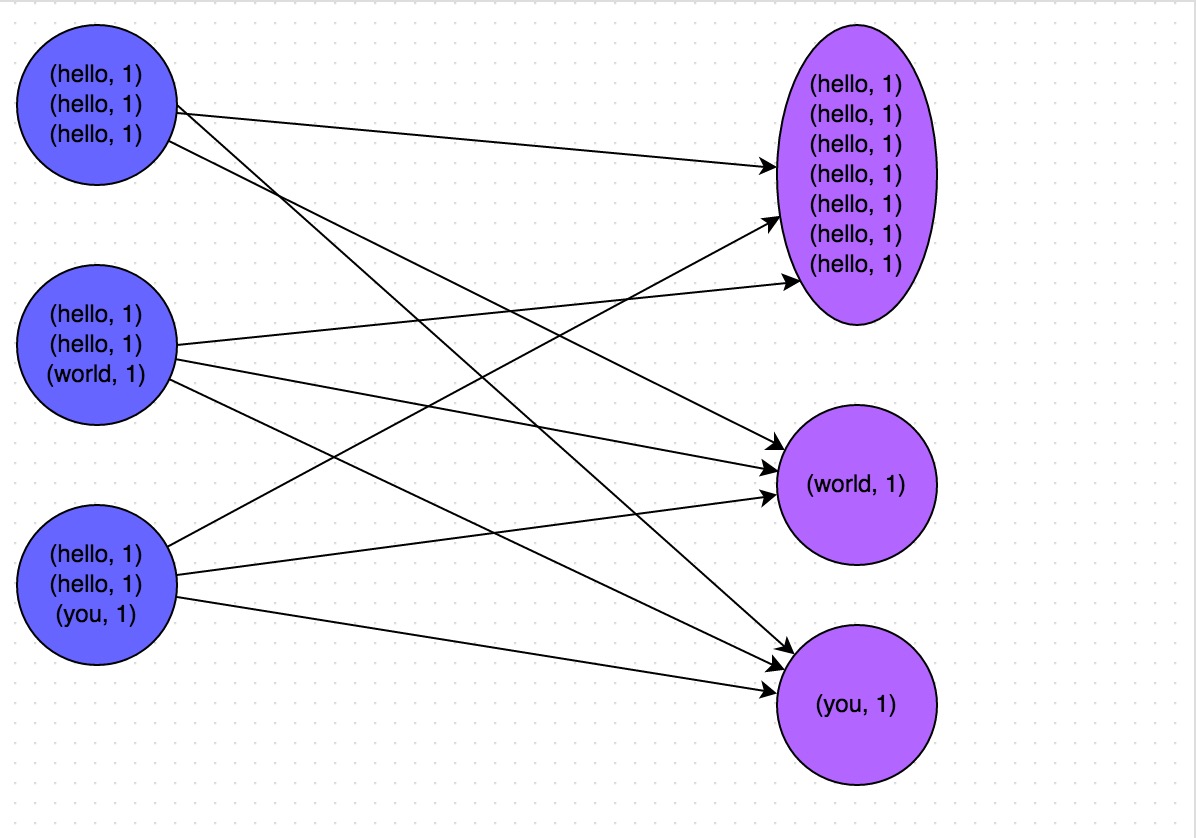
下圖就是一個很清晰的例子:hello這個key杀糯,在三個節(jié)點上對應(yīng)了總共7條數(shù)據(jù),這些數(shù)據(jù)都會被拉取到同一個task中進行處理苍苞;而world和you這兩個key分別才對應(yīng)1條數(shù)據(jù)固翰,所以另外兩個task只要分別處理1條數(shù)據(jù)即可。此時第一個task的運行時間可能是另外兩個task的7倍羹呵,而整個stage的運行速度也由運行最慢的那個task所決定骂际。
2.4 如何定位導(dǎo)致數(shù)據(jù)傾斜的代碼
數(shù)據(jù)傾斜只會發(fā)生在shuffle過程中。這里給大家羅列一些常用的并且可能會觸發(fā)shuffle操作的算子:distinct冈欢、groupByKey歉铝、reduceByKey、aggregateByKey凑耻、join太示、cogroup、repartition等香浩。出現(xiàn)數(shù)據(jù)傾斜時类缤,可能就是你的代碼中使用了這些算子中的某一個所導(dǎo)致的。
某個task執(zhí)行特別慢的情況
首先要看的邻吭,就是數(shù)據(jù)傾斜發(fā)生在第幾個stage中餐弱。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到當(dāng)前運行到了第幾個stage膏蚓;如果是用yarn-cluster模式提交瓢谢,則可以通過Spark Web UI來查看當(dāng)前運行到了第幾個stage。此外驮瞧,無論是使用yarn-client模式還是yarn-cluster模式氓扛,我們都可以在Spark Web UI上深入看一下當(dāng)前這個stage各個task分配的數(shù)據(jù)量,從而進一步確定是不是task分配的數(shù)據(jù)不均勻?qū)е铝藬?shù)據(jù)傾斜剧董。
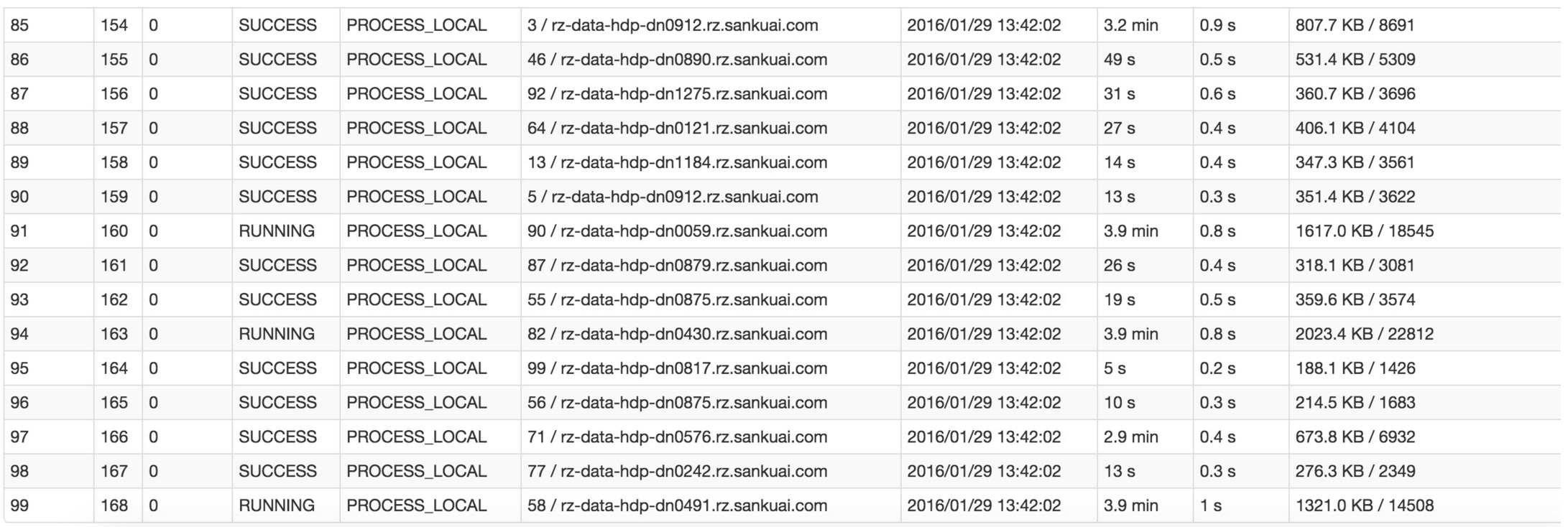
比如下圖中幢尚,倒數(shù)第三列顯示了每個task的運行時間。明顯可以看到翅楼,有的task運行特別快尉剩,只需要幾秒鐘就可以運行完;而有的task運行特別慢毅臊,需要幾分鐘才能運行完理茎,此時單從運行時間上看就已經(jīng)能夠確定發(fā)生數(shù)據(jù)傾斜了。此外管嬉,倒數(shù)第一列顯示了每個task處理的數(shù)據(jù)量皂林,明顯可以看到,運行時間特別短的task只需要處理幾百KB的數(shù)據(jù)即可蚯撩,而運行時間特別長的task需要處理幾千KB的數(shù)據(jù)础倍,處理的數(shù)據(jù)量差了10倍。此時更加能夠確定是發(fā)生了數(shù)據(jù)傾斜胎挎。
知道數(shù)據(jù)傾斜發(fā)生在哪一個stage之后沟启,接著我們就需要根據(jù)stage劃分原理,推算出來發(fā)生傾斜的那個stage對應(yīng)代碼中的哪一部分犹菇,這部分代碼中肯定會有一個shuffle類算子德迹。精準(zhǔn)推算stage與代碼的對應(yīng)關(guān)系,需要對Spark的源碼有深入的理解揭芍,這里我們可以介紹一個相對簡單實用的推算方法:只要看到Spark代碼中出現(xiàn)了一個shuffle類算子或者是Spark SQL的SQL語句中出現(xiàn)了會導(dǎo)致shuffle的語句(比如group by語句)胳搞,那么就可以判定,以那個地方為界限劃分出了前后兩個stage称杨。
這里我們就以Spark最基礎(chǔ)的入門程序——單詞計數(shù)來舉例肌毅,如何用最簡單的方法大致推算出一個stage對應(yīng)的代碼。如下示例姑原,在整個代碼中悬而,只有一個reduceByKey是會發(fā)生shuffle的算子,因此就可以認(rèn)為页衙,以這個算子為界限摊滔,會劃分出前后兩個stage。
- stage0店乐,主要是執(zhí)行從textFile到map操作艰躺,以及執(zhí)行shuffle write操作。shuffle write操作眨八,我們可以簡單理解為對pairs RDD中的數(shù)據(jù)進行分區(qū)操作腺兴,每個task處理的數(shù)據(jù)中,相同的key會寫入同一個磁盤文件內(nèi)廉侧。
- stage1页响,主要是執(zhí)行從reduceByKey到collect操作,stage1的各個task一開始運行段誊,就會首先執(zhí)行shuffle read操作闰蚕。執(zhí)行shuffle read操作的task,會從stage0的各個task所在節(jié)點拉取屬于自己處理的那些key连舍,然后對同一個key進行全局性的聚合或join等操作没陡,在這里就是對key的value值進行累加。stage1在執(zhí)行完reduceByKey算子之后索赏,就計算出了最終的wordCounts RDD盼玄,然后會執(zhí)行collect算子,將所有數(shù)據(jù)拉取到Driver上潜腻,供我們遍歷和打印輸出埃儿。
val conf = new SparkConf()
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://...")
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.collect().foreach(println(_))
通過對單詞計數(shù)程序的分析,希望能夠讓大家了解最基本的stage劃分的原理融涣,以及stage劃分后shuffle操作是如何在兩個stage的邊界處執(zhí)行的童番。然后我們就知道如何快速定位出發(fā)生數(shù)據(jù)傾斜的stage對應(yīng)代碼的哪一個部分了。比如我們在Spark Web UI或者本地log中發(fā)現(xiàn)暴心,stage1的某幾個task執(zhí)行得特別慢妓盲,判定stage1出現(xiàn)了數(shù)據(jù)傾斜,那么就可以回到代碼中定位出stage1主要包括了reduceByKey這個shuffle類算子专普,此時基本就可以確定是由educeByKey算子導(dǎo)致的數(shù)據(jù)傾斜問題悯衬。比如某個單詞出現(xiàn)了100萬次,其他單詞才出現(xiàn)10次檀夹,那么stage1的某個task就要處理100萬數(shù)據(jù)筋粗,整個stage的速度就會被這個task拖慢。
某個task莫名其妙內(nèi)存溢出的情況
這種情況下去定位出問題的代碼就比較容易了炸渡。我們建議直接看yarn-client模式下本地log的異常棧娜亿,或者是通過YARN查看yarn-cluster模式下的log中的異常棧。一般來說蚌堵,通過異常棧信息就可以定位到你的代碼中哪一行發(fā)生了內(nèi)存溢出买决。然后在那行代碼附近找找沛婴,一般也會有shuffle類算子,此時很可能就是這個算子導(dǎo)致了數(shù)據(jù)傾斜督赤。
但是大家要注意的是嘁灯,不能單純靠偶然的內(nèi)存溢出就判定發(fā)生了數(shù)據(jù)傾斜。因為自己編寫的代碼的bug躲舌,以及偶然出現(xiàn)的數(shù)據(jù)異常丑婿,也可能會導(dǎo)致內(nèi)存溢出。因此還是要按照上面所講的方法没卸,通過Spark Web UI查看報錯的那個stage的各個task的運行時間以及分配的數(shù)據(jù)量羹奉,才能確定是否是由于數(shù)據(jù)傾斜才導(dǎo)致了這次內(nèi)存溢出。
2.5 查看導(dǎo)致數(shù)據(jù)傾斜的key的數(shù)據(jù)分布情況
知道了數(shù)據(jù)傾斜發(fā)生在哪里之后约计,通常需要分析一下那個執(zhí)行了shuffle操作并且導(dǎo)致了數(shù)據(jù)傾斜的RDD/Hive表诀拭,查看一下其中key的分布情況。這主要是為之后選擇哪一種技術(shù)方案提供依據(jù)煤蚌。針對不同的key分布與不同的shuffle算子組合起來的各種情況炫加,可能需要選擇不同的技術(shù)方案來解決。
此時根據(jù)你執(zhí)行操作的情況不同铺然,可以有很多種查看key分布的方式:
- 如果是Spark SQL中的group by俗孝、join語句導(dǎo)致的數(shù)據(jù)傾斜,那么就查詢一下SQL中使用的表的key分布情況魄健。
- 如果是對Spark RDD執(zhí)行shuffle算子導(dǎo)致的數(shù)據(jù)傾斜赋铝,那么可以在Spark作業(yè)中加入查看key分布的代碼,比如RDD.countByKey()沽瘦。然后對統(tǒng)計出來的各個key出現(xiàn)的次數(shù)革骨,collect/take到客戶端打印一下,就可以看到key的分布情況析恋。
舉例來說良哲,對于上面所說的單詞計數(shù)程序,如果確定了是stage1的reduceByKey算子導(dǎo)致了數(shù)據(jù)傾斜助隧,那么就應(yīng)該看看進行reduceByKey操作的RDD中的key分布情況筑凫,在這個例子中指的就是pairs RDD。如下示例并村,我們可以先對pairs采樣10%的樣本數(shù)據(jù)巍实,然后使用countByKey算子統(tǒng)計出每個key出現(xiàn)的次數(shù),最后在客戶端遍歷和打印樣本數(shù)據(jù)中各個key的出現(xiàn)次數(shù)哩牍。
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
2.6 數(shù)據(jù)傾斜的解決方案
解決方案一:使用Hive ETL預(yù)處理數(shù)據(jù)
方案適用場景:導(dǎo)致數(shù)據(jù)傾斜的是Hive表棚潦。如果該Hive表中的數(shù)據(jù)本身很不均勻(比如某個key對應(yīng)了100萬數(shù)據(jù),其他key才對應(yīng)了10條數(shù)據(jù))膝昆,而且業(yè)務(wù)場景需要頻繁使用Spark對Hive表執(zhí)行某個分析操作丸边,那么比較適合使用這種技術(shù)方案叠必。
方案實現(xiàn)思路:此時可以評估一下,是否可以通過Hive來進行數(shù)據(jù)預(yù)處理(即通過Hive ETL預(yù)先對數(shù)據(jù)按照key進行聚合妹窖,或者是預(yù)先和其他表進行join)挠唆,然后在Spark作業(yè)中針對的數(shù)據(jù)源就不是原來的Hive表了,而是預(yù)處理后的Hive表嘱吗。此時由于數(shù)據(jù)已經(jīng)預(yù)先進行過聚合或join操作了,那么在Spark作業(yè)中也就不需要使用原先的shuffle類算子執(zhí)行這類操作了滔驾。
方案實現(xiàn)原理:這種方案從根源上解決了數(shù)據(jù)傾斜谒麦,因為徹底避免了在Spark中執(zhí)行shuffle類算子,那么肯定就不會有數(shù)據(jù)傾斜的問題了哆致。但是這里也要提醒一下大家绕德,這種方式屬于治標(biāo)不治本。因為畢竟數(shù)據(jù)本身就存在分布不均勻的問題摊阀,所以Hive ETL中進行g(shù)roup by或者join等shuffle操作時耻蛇,還是會出現(xiàn)數(shù)據(jù)傾斜,導(dǎo)致Hive ETL的速度很慢胞此。我們只是把數(shù)據(jù)傾斜的發(fā)生提前到了Hive ETL中臣咖,避免Spark程序發(fā)生數(shù)據(jù)傾斜而已。
方案優(yōu)點:實現(xiàn)起來簡單便捷漱牵,效果還非常好夺蛇,完全規(guī)避掉了數(shù)據(jù)傾斜,Spark作業(yè)的性能會大幅度提升酣胀。
方案缺點:治標(biāo)不治本刁赦,Hive ETL中還是會發(fā)生數(shù)據(jù)傾斜。
方案實踐經(jīng)驗:在一些Java系統(tǒng)與Spark結(jié)合使用的項目中闻镶,會出現(xiàn)Java代碼頻繁調(diào)用Spark作業(yè)的場景甚脉,而且對Spark作業(yè)的執(zhí)行性能要求很高,就比較適合使用這種方案铆农。將數(shù)據(jù)傾斜提前到上游的Hive ETL牺氨,每天僅執(zhí)行一次,只有那一次是比較慢的墩剖,而之后每次Java調(diào)用Spark作業(yè)時波闹,執(zhí)行速度都會很快,能夠提供更好的用戶體驗涛碑。
項目實踐經(jīng)驗:在美團·點評的交互式用戶行為分析系統(tǒng)中使用了這種方案精堕,該系統(tǒng)主要是允許用戶通過Java Web系統(tǒng)提交數(shù)據(jù)分析統(tǒng)計任務(wù),后端通過Java提交Spark作業(yè)進行數(shù)據(jù)分析統(tǒng)計蒲障。要求Spark作業(yè)速度必須要快歹篓,盡量在10分鐘以內(nèi)瘫证,否則速度太慢,用戶體驗會很差庄撮。所以我們將有些Spark作業(yè)的shuffle操作提前到了Hive ETL中背捌,從而讓Spark直接使用預(yù)處理的Hive中間表,盡可能地減少Spark的shuffle操作洞斯,大幅度提升了性能毡庆,將部分作業(yè)的性能提升了6倍以上。
解決方案二:過濾少數(shù)導(dǎo)致傾斜的key
方案適用場景:如果發(fā)現(xiàn)導(dǎo)致傾斜的key就少數(shù)幾個烙如,而且對計算本身的影響并不大的話么抗,那么很適合使用這種方案。比如99%的key就對應(yīng)10條數(shù)據(jù)亚铁,但是只有一個key對應(yīng)了100萬數(shù)據(jù)蝇刀,從而導(dǎo)致了數(shù)據(jù)傾斜。
方案實現(xiàn)思路:如果我們判斷那少數(shù)幾個數(shù)據(jù)量特別多的key徘溢,對作業(yè)的執(zhí)行和計算結(jié)果不是特別重要的話吞琐,那么干脆就直接過濾掉那少數(shù)幾個key。比如然爆,在Spark SQL中可以使用where子句過濾掉這些key或者在Spark Core中對RDD執(zhí)行filter算子過濾掉這些key站粟。如果需要每次作業(yè)執(zhí)行時,動態(tài)判定哪些key的數(shù)據(jù)量最多然后再進行過濾曾雕,那么可以使用sample算子對RDD進行采樣卒蘸,然后計算出每個key的數(shù)量,取數(shù)據(jù)量最多的key過濾掉即可翻默。
方案實現(xiàn)原理:將導(dǎo)致數(shù)據(jù)傾斜的key給過濾掉之后缸沃,這些key就不會參與計算了,自然不可能產(chǎn)生數(shù)據(jù)傾斜修械。
方案優(yōu)點:實現(xiàn)簡單趾牧,而且效果也很好,可以完全規(guī)避掉數(shù)據(jù)傾斜肯污。
方案缺點:適用場景不多翘单,大多數(shù)情況下,導(dǎo)致傾斜的key還是很多的蹦渣,并不是只有少數(shù)幾個哄芜。
方案實踐經(jīng)驗:在項目中我們也采用過這種方案解決數(shù)據(jù)傾斜。有一次發(fā)現(xiàn)某一天Spark作業(yè)在運行的時候突然OOM了柬唯,追查之后發(fā)現(xiàn)认臊,是Hive表中的某一個key在那天數(shù)據(jù)異常,導(dǎo)致數(shù)據(jù)量暴增锄奢。因此就采取每次執(zhí)行前先進行采樣失晴,計算出樣本中數(shù)據(jù)量最大的幾個key之后剧腻,直接在程序中將那些key給過濾掉。
解決方案三:提高shuffle操作的并行度
方案適用場景:如果我們必須要對數(shù)據(jù)傾斜迎難而上涂屁,那么建議優(yōu)先使用這種方案书在,因為這是處理數(shù)據(jù)傾斜最簡單的一種方案。
方案實現(xiàn)思路:在對RDD執(zhí)行shuffle算子時拆又,給shuffle算子傳入一個參數(shù)儒旬,比如reduceByKey(1000),該參數(shù)就設(shè)置了這個shuffle算子執(zhí)行時shuffle read task的數(shù)量帖族。對于Spark SQL中的shuffle類語句栈源,比如group by、join等盟萨,需要設(shè)置一個參數(shù),即spark.sql.shuffle.partitions了讨,該參數(shù)代表了shuffle read task的并行度捻激,該值默認(rèn)是200,對于很多場景來說都有點過小前计。
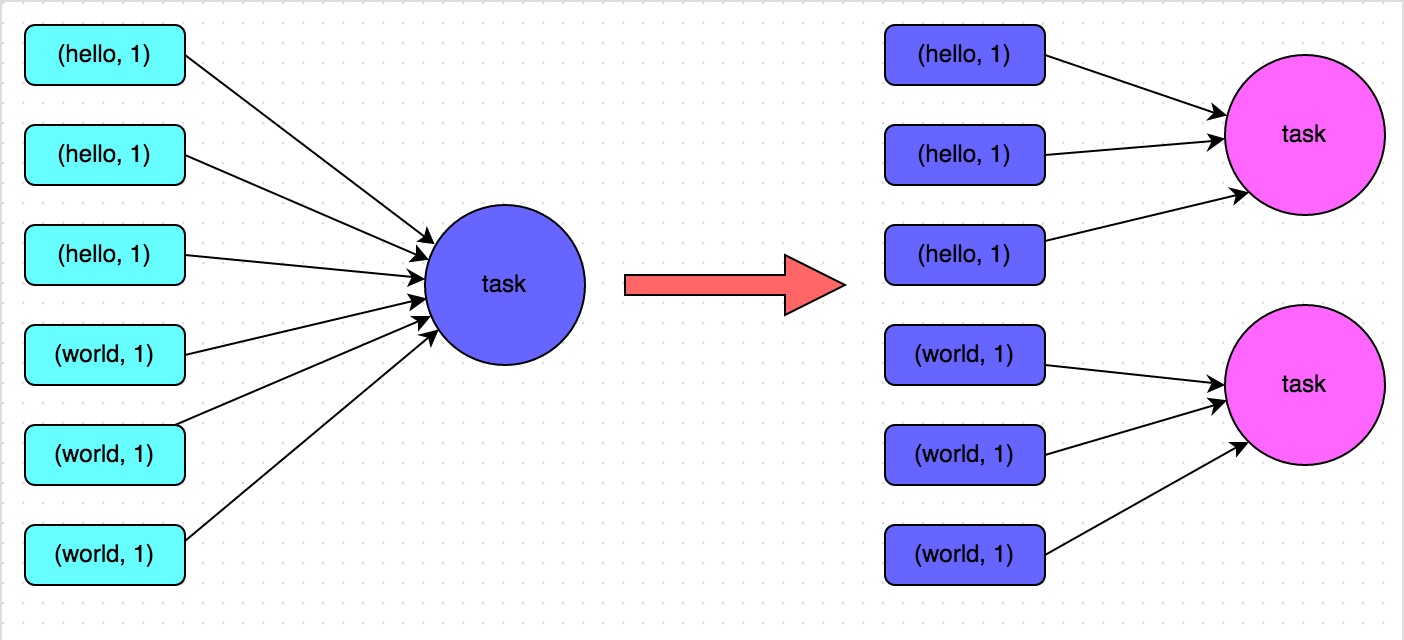
方案實現(xiàn)原理:增加shuffle read task的數(shù)量胞谭,可以讓原本分配給一個task的多個key分配給多個task,從而讓每個task處理比原來更少的數(shù)據(jù)男杈。舉例來說丈屹,如果原本有5個key,每個key對應(yīng)10條數(shù)據(jù)伶棒,這5個key都是分配給一個task的旺垒,那么這個task就要處理50條數(shù)據(jù)。而增加了shuffle read task以后肤无,每個task就分配到一個key先蒋,即每個task就處理10條數(shù)據(jù),那么自然每個task的執(zhí)行時間都會變短了宛渐。具體原理如下圖所示竞漾。
方案優(yōu)點:實現(xiàn)起來比較簡單,可以有效緩解和減輕數(shù)據(jù)傾斜的影響窥翩。
方案缺點:只是緩解了數(shù)據(jù)傾斜而已业岁,沒有徹底根除問題,根據(jù)實踐經(jīng)驗來看寇蚊,其效果有限笔时。
方案實踐經(jīng)驗:該方案通常無法徹底解決數(shù)據(jù)傾斜,因為如果出現(xiàn)一些極端情況仗岸,比如某個key對應(yīng)的數(shù)據(jù)量有100萬糊闽,那么無論你的task數(shù)量增加到多少梳玫,這個對應(yīng)著100萬數(shù)據(jù)的key肯定還是會分配到一個task中去處理,因此注定還是會發(fā)生數(shù)據(jù)傾斜的右犹。所以這種方案只能說是在發(fā)現(xiàn)數(shù)據(jù)傾斜時嘗試使用的第一種手段提澎,嘗試去用嘴簡單的方法緩解數(shù)據(jù)傾斜而已,或者是和其他方案結(jié)合起來使用念链。
解決方案四:兩階段聚合(局部聚合+全局聚合)
方案適用場景:對RDD執(zhí)行reduceByKey等聚合類shuffle算子或者在Spark SQL中使用group by語句進行分組聚合時盼忌,比較適用這種方案。
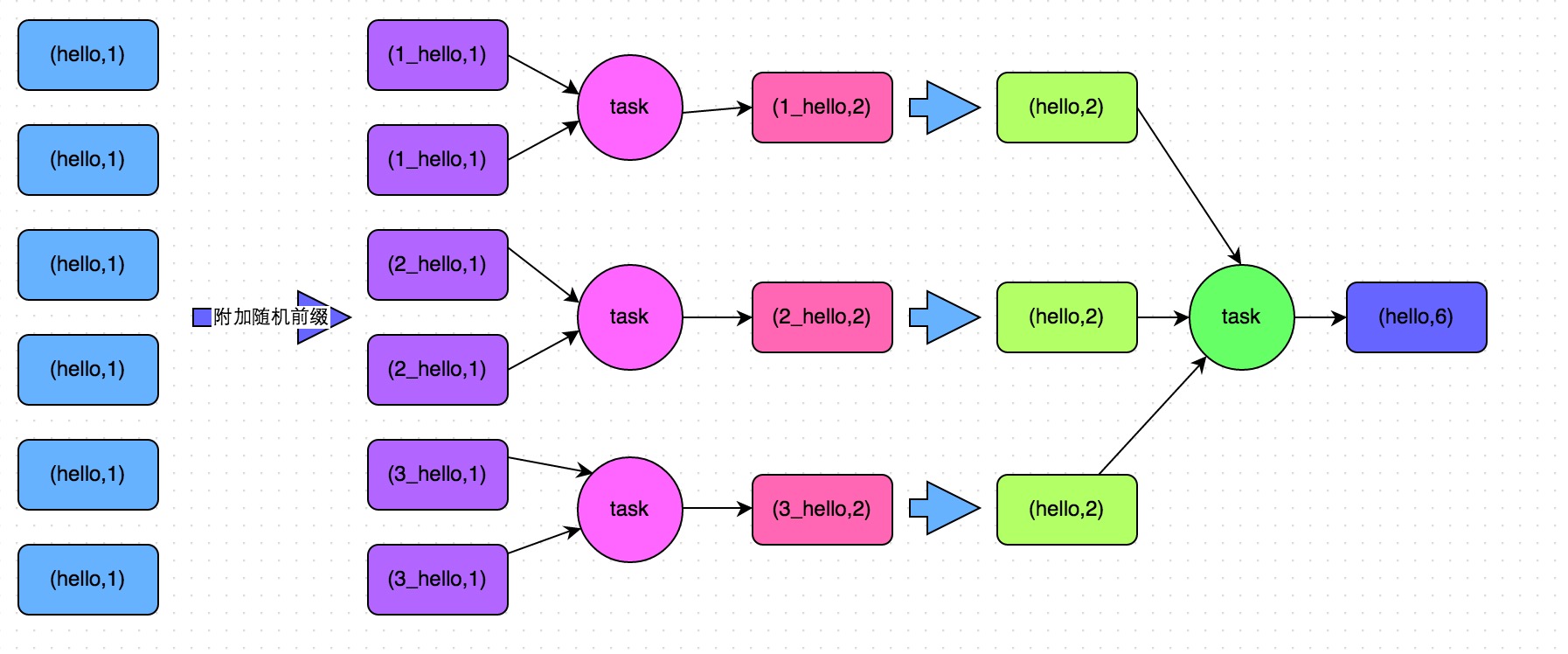
方案實現(xiàn)思路:這個方案的核心實現(xiàn)思路就是進行兩階段聚合掂墓。第一次是局部聚合谦纱,先給每個key都打上一個隨機數(shù),比如10以內(nèi)的隨機數(shù)君编,此時原先一樣的key就變成不一樣的了跨嘉,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)吃嘿。接著對打上隨機數(shù)后的數(shù)據(jù)祠乃,執(zhí)行reduceByKey等聚合操作,進行局部聚合兑燥,那么局部聚合結(jié)果亮瓷,就會變成了(1_hello, 2) (2_hello, 2)。然后將各個key的前綴給去掉降瞳,就會變成(hello,2)(hello,2)嘱支,再次進行全局聚合操作,就可以得到最終結(jié)果了挣饥,比如(hello, 4)除师。
方案實現(xiàn)原理:將原本相同的key通過附加隨機前綴的方式驶睦,變成多個不同的key堤结,就可以讓原本被一個task處理的數(shù)據(jù)分散到多個task上去做局部聚合响蕴,進而解決單個task處理數(shù)據(jù)量過多的問題背零。接著去除掉隨機前綴煮嫌,再次進行全局聚合酒贬,就可以得到最終的結(jié)果糟把。具體原理見下圖皮获。
方案優(yōu)點:對于聚合類的shuffle操作導(dǎo)致的數(shù)據(jù)傾斜搓侄,效果是非常不錯的瞄桨。通常都可以解決掉數(shù)據(jù)傾斜,或者至少是大幅度緩解數(shù)據(jù)傾斜讶踪,將Spark作業(yè)的性能提升數(shù)倍以上芯侥。
方案缺點:僅僅適用于聚合類的shuffle操作,適用范圍相對較窄。如果是join類的shuffle操作柱查,還得用其他的解決方案廓俭。
// 第一步,給RDD中的每個key都打上一個隨機前綴唉工。
JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// 第二步研乒,對打上隨機前綴的key進行局部聚合。
JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// 第三步淋硝,去除RDD中每個key的隨機前綴雹熬。
JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// 第四步,對去除了隨機前綴的RDD進行全局聚合谣膳。
JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
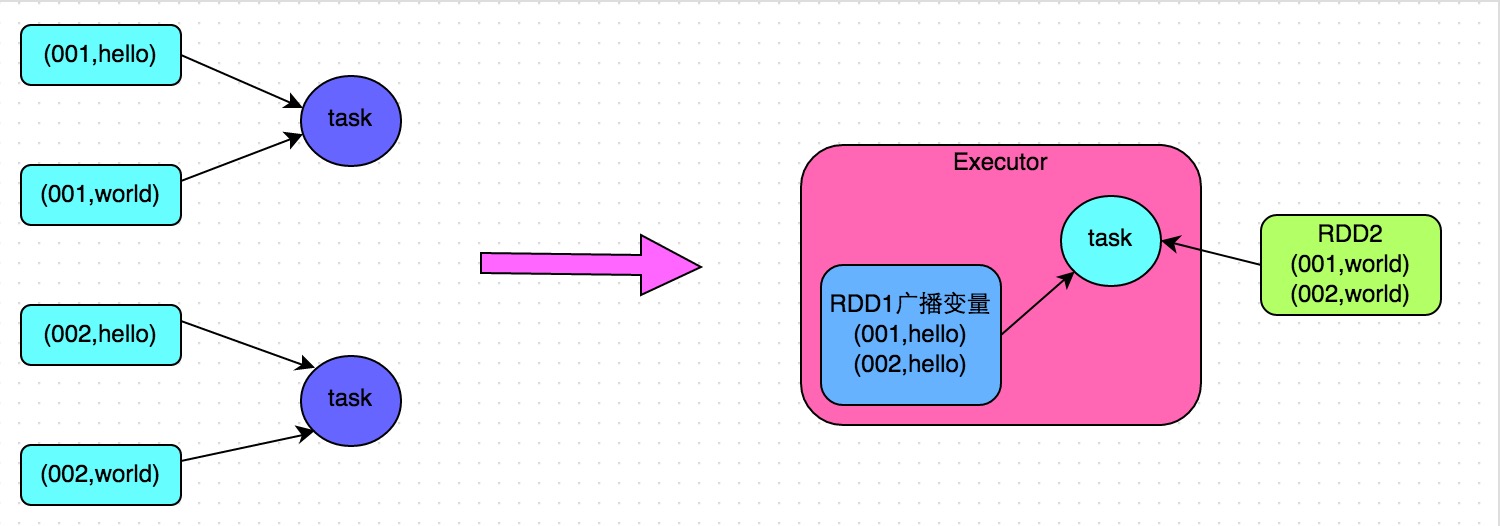
解決方案五:將reduce join轉(zhuǎn)為map join
方案適用場景:在對RDD使用join類操作竿报,或者是在Spark SQL中使用join語句時,而且join操作中的一個RDD或表的數(shù)據(jù)量比較屑萄琛(比如幾百M或者一兩G)烈菌,比較適用此方案。
方案實現(xiàn)思路:不使用join算子進行連接操作花履,而使用Broadcast變量與map類算子實現(xiàn)join操作芽世,進而完全規(guī)避掉shuffle類的操作,徹底避免數(shù)據(jù)傾斜的發(fā)生和出現(xiàn)臭挽。將較小RDD中的數(shù)據(jù)直接通過collect算子拉取到Driver端的內(nèi)存中來捂襟,然后對其創(chuàng)建一個Broadcast變量咬腕;接著對另外一個RDD執(zhí)行map類算子欢峰,在算子函數(shù)內(nèi),從Broadcast變量中獲取較小RDD的全量數(shù)據(jù)涨共,與當(dāng)前RDD的每一條數(shù)據(jù)按照連接key進行比對纽帖,如果連接key相同的話,那么就將兩個RDD的數(shù)據(jù)用你需要的方式連接起來举反。
方案實現(xiàn)原理:普通的join是會走shuffle過程的懊直,而一旦shuffle,就相當(dāng)于會將相同key的數(shù)據(jù)拉取到一個shuffle read task中再進行join火鼻,此時就是reduce join室囊。但是如果一個RDD是比較小的,則可以采用廣播小RDD全量數(shù)據(jù)+map算子來實現(xiàn)與join同樣的效果魁索,也就是map join融撞,此時就不會發(fā)生shuffle操作,也就不會發(fā)生數(shù)據(jù)傾斜粗蔚。具體原理如下圖所示尝偎。
方案優(yōu)點:對join操作導(dǎo)致的數(shù)據(jù)傾斜,效果非常好,因為根本就不會發(fā)生shuffle致扯,也就根本不會發(fā)生數(shù)據(jù)傾斜肤寝。
方案缺點:適用場景較少,因為這個方案只適用于一個大表和一個小表的情況抖僵。畢竟我們需要將小表進行廣播鲤看,此時會比較消耗內(nèi)存資源,driver和每個Executor內(nèi)存中都會駐留一份小RDD的全量數(shù)據(jù)裆针。如果我們廣播出去的RDD數(shù)據(jù)比較大刨摩,比如10G以上,那么就可能發(fā)生內(nèi)存溢出了世吨。因此并不適合兩個都是大表的情況澡刹。
// 首先將數(shù)據(jù)量比較小的RDD的數(shù)據(jù),collect到Driver中來耘婚。
List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
// 然后使用Spark的廣播功能罢浇,將小RDD的數(shù)據(jù)轉(zhuǎn)換成廣播變量,這樣每個Executor就只有一份RDD的數(shù)據(jù)沐祷。
// 可以盡可能節(jié)省內(nèi)存空間嚷闭,并且減少網(wǎng)絡(luò)傳輸性能開銷。
final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
// 對另外一個RDD執(zhí)行map類操作赖临,而不再是join類操作胞锰。
JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
throws Exception {
// 在算子函數(shù)中,通過廣播變量兢榨,獲取到本地Executor中的rdd1數(shù)據(jù)嗅榕。
List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
// 可以將rdd1的數(shù)據(jù)轉(zhuǎn)換為一個Map,便于后面進行join操作吵聪。
Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> data : rdd1Data) {
rdd1DataMap.put(data._1, data._2);
}
// 獲取當(dāng)前RDD數(shù)據(jù)的key以及value凌那。
String key = tuple._1;
String value = tuple._2;
// 從rdd1數(shù)據(jù)Map中,根據(jù)key獲取到可以join到的數(shù)據(jù)吟逝。
Row rdd1Value = rdd1DataMap.get(key);
return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
}
});
// 這里得提示一下帽蝶。
// 上面的做法,僅僅適用于rdd1中的key沒有重復(fù)块攒,全部是唯一的場景励稳。
// 如果rdd1中有多個相同的key,那么就得用flatMap類的操作囱井,
// 在進行join的時候不能用map驹尼,而是得遍歷rdd1所有數(shù)據(jù)進行join。
// rdd2中每條數(shù)據(jù)都可能會返回多條join后的數(shù)據(jù)琅绅。
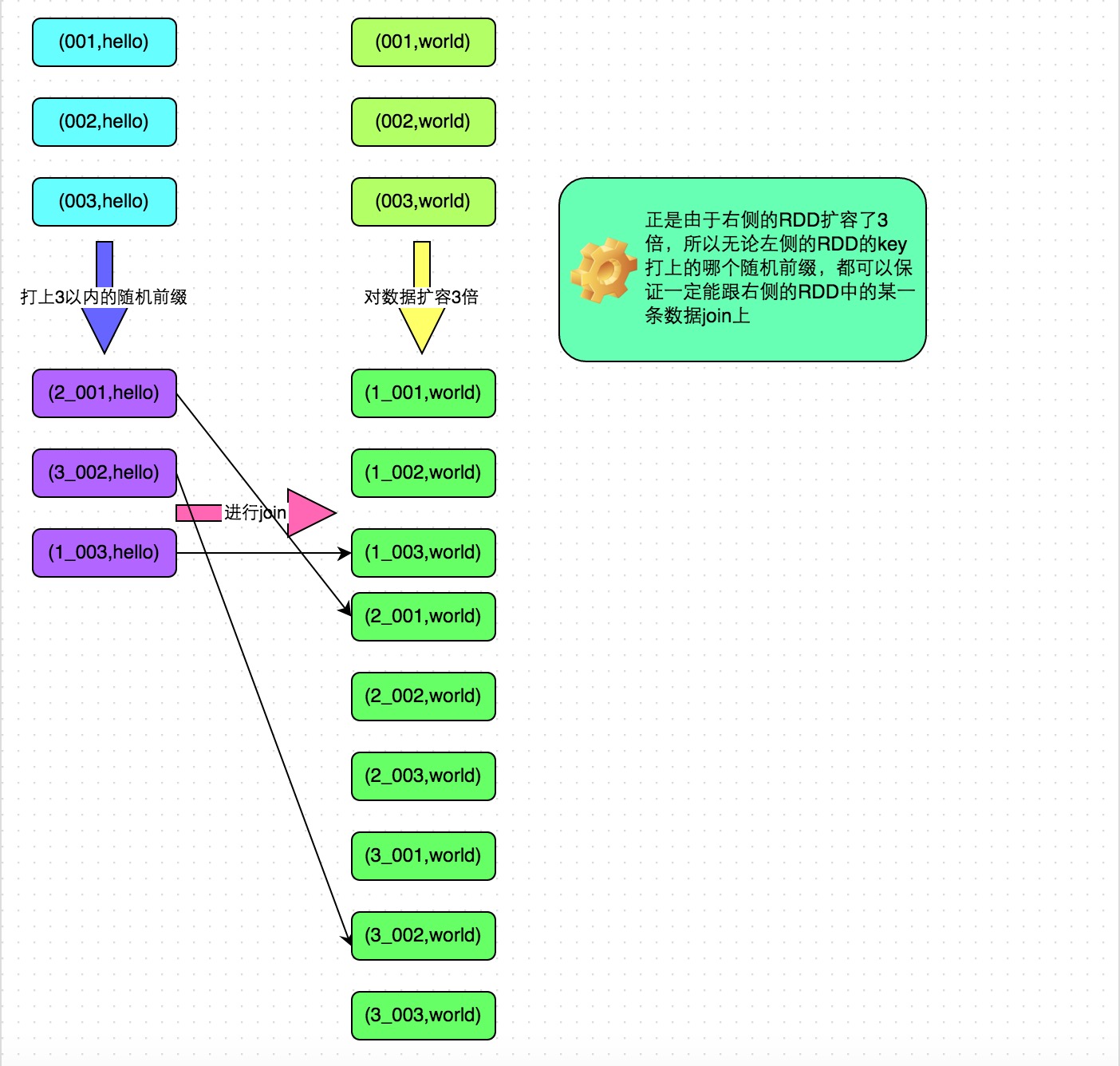
解決方案六:采樣傾斜key并分拆join操作
方案適用場景:兩個RDD/Hive表進行join的時候扶欣,如果數(shù)據(jù)量都比較大,無法采用“解決方案五”,那么此時可以看一下兩個RDD/Hive表中的key分布情況料祠。如果出現(xiàn)數(shù)據(jù)傾斜骆捧,是因為其中某一個RDD/Hive表中的少數(shù)幾個key的數(shù)據(jù)量過大,而另一個RDD/Hive表中的所有key都分布比較均勻髓绽,那么采用這個解決方案是比較合適的敛苇。
方案實現(xiàn)思路:
- 對包含少數(shù)幾個數(shù)據(jù)量過大的key的那個RDD,通過sample算子采樣出一份樣本來顺呕,然后統(tǒng)計一下每個key的數(shù)量枫攀,計算出來數(shù)據(jù)量最大的是哪幾個key。
- 然后將這幾個key對應(yīng)的數(shù)據(jù)從原來的RDD中拆分出來株茶,形成一個單獨的RDD来涨,并給每個key都打上n以內(nèi)的隨機數(shù)作為前綴,而不會導(dǎo)致傾斜的大部分key形成另外一個RDD启盛。
- 接著將需要join的另一個RDD蹦掐,也過濾出來那幾個傾斜key對應(yīng)的數(shù)據(jù)并形成一個單獨的RDD,將每條數(shù)據(jù)膨脹成n條數(shù)據(jù)僵闯,這n條數(shù)據(jù)都按順序附加一個0~n的前綴卧抗,不會導(dǎo)致傾斜的大部分key也形成另外一個RDD。
- 再將附加了隨機前綴的獨立RDD與另一個膨脹n倍的獨立RDD進行join鳖粟,此時就可以將原先相同的key打散成n份社裆,分散到多個task中去進行join了。
- 而另外兩個普通的RDD就照常join即可向图。
- 最后將兩次join的結(jié)果使用union算子合并起來即可泳秀,就是最終的join結(jié)果。
方案實現(xiàn)原理:對于join導(dǎo)致的數(shù)據(jù)傾斜张漂,如果只是某幾個key導(dǎo)致了傾斜晶默,可以將少數(shù)幾個key分拆成獨立RDD谨娜,并附加隨機前綴打散成n份去進行join航攒,此時這幾個key對應(yīng)的數(shù)據(jù)就不會集中在少數(shù)幾個task上,而是分散到多個task進行join了趴梢。具體原理見下圖漠畜。
方案優(yōu)點:對于join導(dǎo)致的數(shù)據(jù)傾斜,如果只是某幾個key導(dǎo)致了傾斜坞靶,采用該方式可以用最有效的方式打散key進行join憔狞。而且只需要針對少數(shù)傾斜key對應(yīng)的數(shù)據(jù)進行擴容n倍,不需要對全量數(shù)據(jù)進行擴容彰阴。避免了占用過多內(nèi)存瘾敢。
方案缺點:如果導(dǎo)致傾斜的key特別多的話,比如成千上萬個key都導(dǎo)致數(shù)據(jù)傾斜,那么這種方式也不適合簇抵。
// 首先從包含了少數(shù)幾個導(dǎo)致數(shù)據(jù)傾斜key的rdd1中庆杜,采樣10%的樣本數(shù)據(jù)。
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// 對樣本數(shù)據(jù)RDD統(tǒng)計出每個key的出現(xiàn)次數(shù)碟摆,并按出現(xiàn)次數(shù)降序排序晃财。
// 對降序排序后的數(shù)據(jù),取出top 1或者top 100的數(shù)據(jù)典蜕,也就是key最多的前n個數(shù)據(jù)断盛。
// 具體取出多少個數(shù)據(jù)量最多的key,由大家自己決定愉舔,我們這里就取1個作為示范钢猛。
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 從rdd1中分拆出導(dǎo)致數(shù)據(jù)傾斜的key,形成獨立的RDD轩缤。
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 從rdd1中分拆出不導(dǎo)致數(shù)據(jù)傾斜的普通key厢洞,形成獨立的RDD。
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2典奉,就是那個所有key的分布相對較為均勻的rdd躺翻。
// 這里將rdd2中,前面獲取到的key對應(yīng)的數(shù)據(jù)卫玖,過濾出來公你,分拆成單獨的rdd,
// 并對rdd中的數(shù)據(jù)使用flatMap算子都擴容100倍假瞬。
// 對擴容的每條數(shù)據(jù)陕靠,都打上0~100的前綴。
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 將rdd1中分拆出來的導(dǎo)致傾斜的key的獨立rdd脱茉,每條數(shù)據(jù)都打上100以內(nèi)的隨機前綴剪芥。
// 然后將這個rdd1中分拆出來的獨立rdd,與上面rdd2中分拆出來的獨立rdd琴许,進行join税肪。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>,
Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// 將rdd1中分拆出來的包含普通key的獨立rdd,直接與rdd2進行join榜田。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// 將傾斜key join后的結(jié)果與普通key join后的結(jié)果益兄,uinon起來。
// 就是最終的join結(jié)果箭券。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
解決方案七:使用隨機前綴和擴容RDD進行join
方案適用場景:如果在進行join操作時净捅,RDD中有大量的key導(dǎo)致數(shù)據(jù)傾斜,那么進行分拆key也沒什么意義辩块,此時就只能使用最后一種方案來解決問題了蛔六。
方案實現(xiàn)思路:
- 該方案的實現(xiàn)思路基本和“解決方案六”類似荆永,首先查看RDD/Hive表中的數(shù)據(jù)分布情況,找到那個造成數(shù)據(jù)傾斜的RDD/Hive表国章,比如有多個key都對應(yīng)了超過1萬條數(shù)據(jù)屁魏。
- 然后將該RDD的每條數(shù)據(jù)都打上一個n以內(nèi)的隨機前綴。
- 同時對另外一個正常的RDD進行擴容捉腥,將每條數(shù)據(jù)都擴容成n條數(shù)據(jù)氓拼,擴容出來的每條數(shù)據(jù)都依次打上一個0~n的前綴。
- 最后將兩個處理后的RDD進行join即可抵碟。
方案實現(xiàn)原理:將原先一樣的key通過附加隨機前綴變成不一樣的key桃漾,然后就可以將這些處理后的“不同key”分散到多個task中去處理,而不是讓一個task處理大量的相同key拟逮。該方案與“解決方案六”的不同之處就在于撬统,上一種方案是盡量只對少數(shù)傾斜key對應(yīng)的數(shù)據(jù)進行特殊處理,由于處理過程需要擴容RDD敦迄,因此上一種方案擴容RDD后對內(nèi)存的占用并不大恋追;而這一種方案是針對有大量傾斜key的情況,沒法將部分key拆分出來進行單獨處理罚屋,因此只能對整個RDD進行數(shù)據(jù)擴容苦囱,對內(nèi)存資源要求很高。
方案優(yōu)點:對join類型的數(shù)據(jù)傾斜基本都可以處理脾猛,而且效果也相對比較顯著撕彤,性能提升效果非常不錯。
方案缺點:該方案更多的是緩解數(shù)據(jù)傾斜猛拴,而不是徹底避免數(shù)據(jù)傾斜羹铅。而且需要對整個RDD進行擴容,對內(nèi)存資源要求很高愉昆。
方案實踐經(jīng)驗:曾經(jīng)開發(fā)一個數(shù)據(jù)需求的時候职员,發(fā)現(xiàn)一個join導(dǎo)致了數(shù)據(jù)傾斜。優(yōu)化之前跛溉,作業(yè)的執(zhí)行時間大約是60分鐘左右焊切;使用該方案優(yōu)化之后,執(zhí)行時間縮短到10分鐘左右倒谷,性能提升了6倍蛛蒙。
// 首先將其中一個key分布相對較為均勻的RDD膨脹100倍糙箍。
JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 其次渤愁,將另一個有數(shù)據(jù)傾斜key的RDD,每條數(shù)據(jù)都打上100以內(nèi)的隨機前綴深夯。
JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
// 將兩個處理后的RDD進行join即可抖格。
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
解決方案八:多種方案組合使用
在實踐中發(fā)現(xiàn)诺苹,很多情況下,如果只是處理較為簡單的數(shù)據(jù)傾斜場景雹拄,那么使用上述方案中的某一種基本就可以解決收奔。但是如果要處理一個較為復(fù)雜的數(shù)據(jù)傾斜場景,那么可能需要將多種方案組合起來使用滓玖。比如說坪哄,我們針對出現(xiàn)了多個數(shù)據(jù)傾斜環(huán)節(jié)的Spark作業(yè),可以先運用解決方案一和二势篡,預(yù)處理一部分?jǐn)?shù)據(jù)翩肌,并過濾一部分?jǐn)?shù)據(jù)來緩解;其次可以對某些shuffle操作提升并行度禁悠,優(yōu)化其性能念祭;最后還可以針對不同的聚合或join操作,選擇一種方案來優(yōu)化其性能碍侦。大家需要對這些方案的思路和原理都透徹理解之后粱坤,在實踐中根據(jù)各種不同的情況,靈活運用多種方案瓷产,來解決自己的數(shù)據(jù)傾斜問題站玄。
2 shuffle調(diào)優(yōu)
2.1 調(diào)優(yōu)概述
大多數(shù)Spark作業(yè)的性能主要就是消耗在了shuffle環(huán)節(jié),因為該環(huán)節(jié)包含了大量的磁盤IO濒旦、序列化蜒什、網(wǎng)絡(luò)數(shù)據(jù)傳輸?shù)炔僮鳌R虼税坦溃绻屪鳂I(yè)的性能更上一層樓灾常,就有必要對shuffle過程進行調(diào)優(yōu)。但是也必須提醒大家的是铃拇,影響一個Spark作業(yè)性能的因素钞瀑,主要還是代碼開發(fā)、資源參數(shù)以及數(shù)據(jù)傾斜慷荔,shuffle調(diào)優(yōu)只能在整個Spark的性能調(diào)優(yōu)中占到一小部分而已雕什。因此大家務(wù)必把握住調(diào)優(yōu)的基本原則,千萬不要舍本逐末显晶。下面我們就給大家詳細(xì)講解shuffle的原理贷岸,以及相關(guān)參數(shù)的說明,同時給出各個參數(shù)的調(diào)優(yōu)建議磷雇。
2.2 ShuffleManager發(fā)展概述
在Spark的源碼中偿警,負(fù)責(zé)shuffle過程的執(zhí)行、計算和處理的組件主要就是ShuffleManager唯笙,也即shuffle管理器螟蒸。而隨著Spark的版本的發(fā)展盒使,ShuffleManager也在不斷迭代,變得越來越先進七嫌。
在Spark 1.2以前少办,默認(rèn)的shuffle計算引擎是HashShuffleManager。該ShuffleManager而HashShuffleManager有著一個非常嚴(yán)重的弊端诵原,就是會產(chǎn)生大量的中間磁盤文件英妓,進而由大量的磁盤IO操作影響了性能。
因此在Spark 1.2以后的版本中绍赛,默認(rèn)的ShuffleManager改成了SortShuffleManager鞋拟。SortShuffleManager相較于HashShuffleManager來說,有了一定的改進惹资。主要就在于贺纲,每個Task在進行shuffle操作時,雖然也會產(chǎn)生較多的臨時磁盤文件褪测,但是最后會將所有的臨時文件合并(merge)成一個磁盤文件猴誊,因此每個Task就只有一個磁盤文件。在下一個stage的shuffle read task拉取自己的數(shù)據(jù)時侮措,只要根據(jù)索引讀取每個磁盤文件中的部分?jǐn)?shù)據(jù)即可懈叹。
2.3 HashShuffleManager運行原理
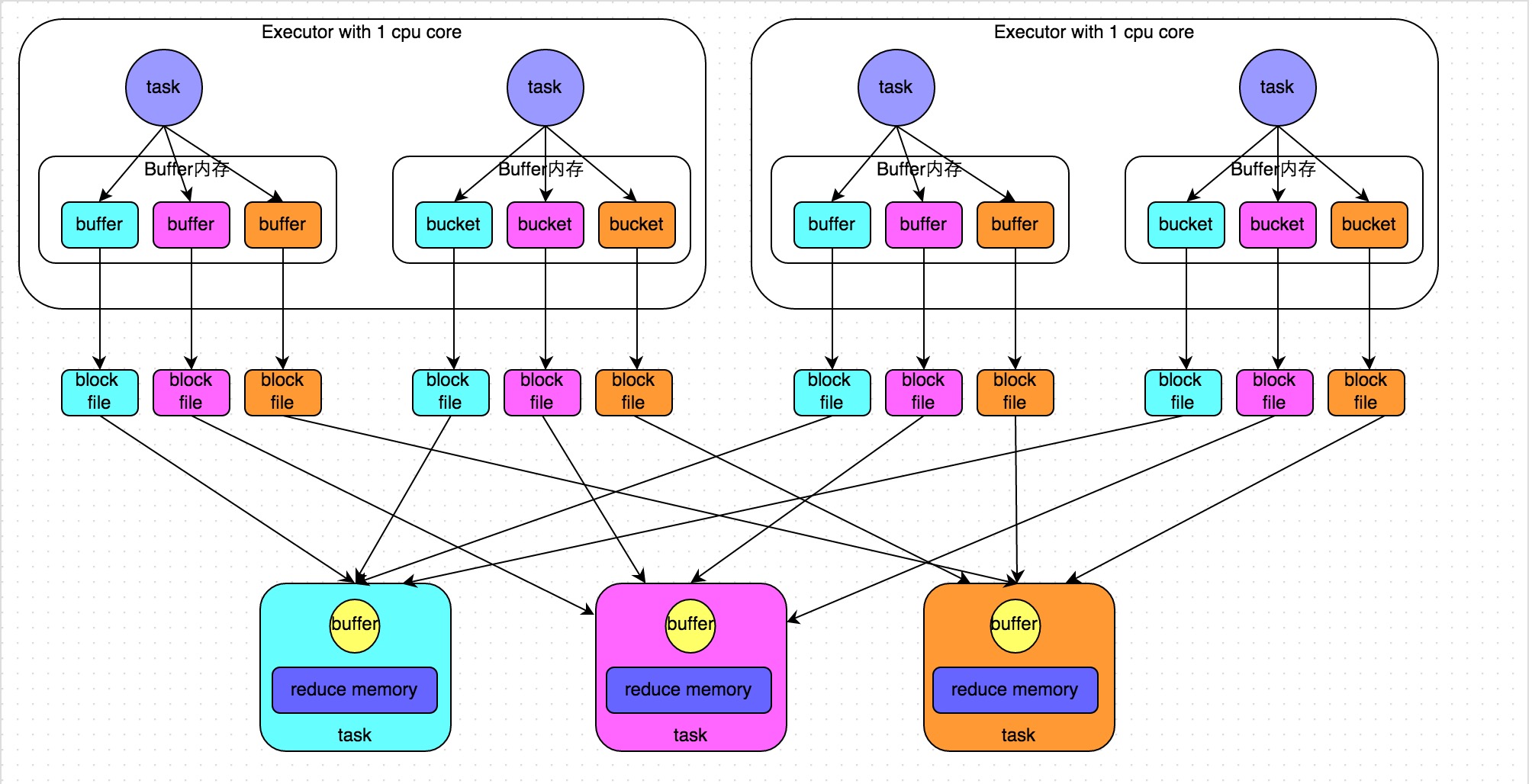
未經(jīng)優(yōu)化的HashShuffleManager
下圖說明了未經(jīng)優(yōu)化的HashShuffleManager的原理。這里我們先明確一個假設(shè)前提:每個Executor只有1個CPU core分扎,也就是說澄成,無論這個Executor上分配多少個task線程,同一時間都只能執(zhí)行一個task線程畏吓。
我們先從shuffle write開始說起墨状。shuffle write階段,主要就是在一個stage結(jié)束計算之后菲饼,為了下一個stage可以執(zhí)行shuffle類的算子(比如reduceByKey)肾砂,而將每個task處理的數(shù)據(jù)按key進行“分類”。所謂“分類”宏悦,就是對相同的key執(zhí)行hash算法镐确,從而將相同key都寫入同一個磁盤文件中,而每一個磁盤文件都只屬于下游stage的一個task饼煞。在將數(shù)據(jù)寫入磁盤之前源葫,會先將數(shù)據(jù)寫入內(nèi)存緩沖中,當(dāng)內(nèi)存緩沖填滿之后砖瞧,才會溢寫到磁盤文件中去息堂。
那么每個執(zhí)行shuffle write的task,要為下一個stage創(chuàng)建多少個磁盤文件呢芭届?很簡單储矩,下一個stage的task有多少個感耙,當(dāng)前stage的每個task就要創(chuàng)建多少份磁盤文件褂乍。比如下一個stage總共有100個task持隧,那么當(dāng)前stage的每個task都要創(chuàng)建100份磁盤文件。如果當(dāng)前stage有50個task逃片,總共有10個Executor屡拨,每個Executor執(zhí)行5個Task,那么每個Executor上總共就要創(chuàng)建500個磁盤文件褥实,所有Executor上會創(chuàng)建5000個磁盤文件呀狼。由此可見,未經(jīng)優(yōu)化的shuffle write操作所產(chǎn)生的磁盤文件的數(shù)量是極其驚人的损离。
接著我們來說說shuffle read哥艇。shuffle read,通常就是一個stage剛開始時要做的事情僻澎。此時該stage的每一個task就需要將上一個stage的計算結(jié)果中的所有相同key貌踏,從各個節(jié)點上通過網(wǎng)絡(luò)都拉取到自己所在的節(jié)點上,然后進行key的聚合或連接等操作窟勃。由于shuffle write的過程中祖乳,task給下游stage的每個task都創(chuàng)建了一個磁盤文件,因此shuffle read的過程中秉氧,每個task只要從上游stage的所有task所在節(jié)點上眷昆,拉取屬于自己的那一個磁盤文件即可。
shuffle read的拉取過程是一邊拉取一邊進行聚合的汁咏。每個shuffle read task都會有一個自己的buffer緩沖亚斋,每次都只能拉取與buffer緩沖相同大小的數(shù)據(jù),然后通過內(nèi)存中的一個Map進行聚合等操作攘滩。聚合完一批數(shù)據(jù)后伞访,再拉取下一批數(shù)據(jù),并放到buffer緩沖中進行聚合操作轰驳。以此類推厚掷,直到最后將所有數(shù)據(jù)到拉取完,并得到最終的結(jié)果级解。
優(yōu)化后的HashShuffleManager
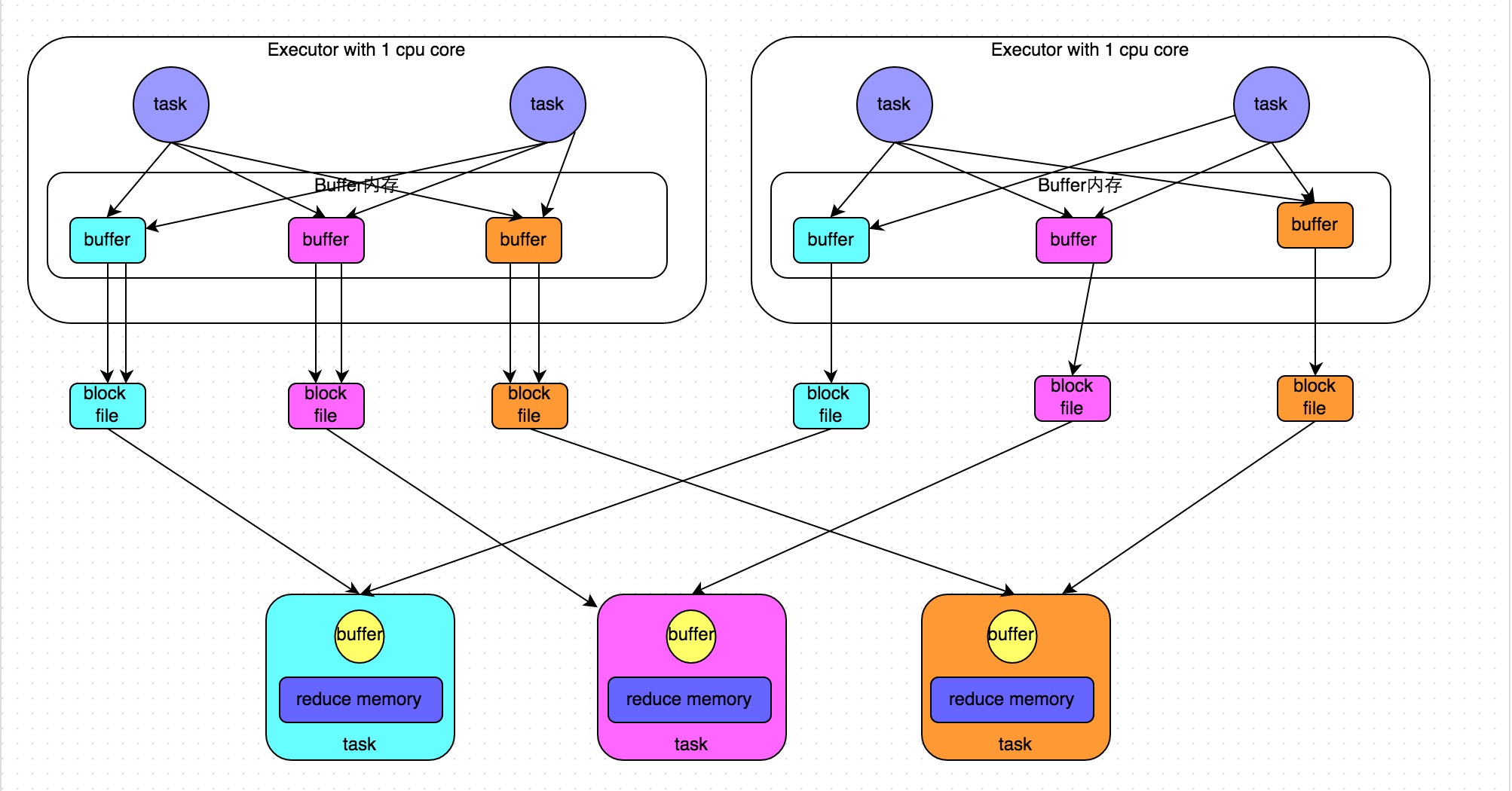
下圖說明了優(yōu)化后的HashShuffleManager的原理冒黑。這里說的優(yōu)化,是指我們可以設(shè)置一個參數(shù)勤哗,spark.shuffle.consolidateFiles抡爹。該參數(shù)默認(rèn)值為false,將其設(shè)置為true即可開啟優(yōu)化機制芒划。通常來說冬竟,如果我們使用HashShuffleManager欧穴,那么都建議開啟這個選項。
開啟consolidate機制之后泵殴,在shuffle write過程中涮帘,task就不是為下游stage的每個task創(chuàng)建一個磁盤文件了。此時會出現(xiàn)shuffleFileGroup的概念笑诅,每個shuffleFileGroup會對應(yīng)一批磁盤文件调缨,磁盤文件的數(shù)量與下游stage的task數(shù)量是相同的。一個Executor上有多少個CPU core吆你,就可以并行執(zhí)行多少個task弦叶。而第一批并行執(zhí)行的每個task都會創(chuàng)建一個shuffleFileGroup,并將數(shù)據(jù)寫入對應(yīng)的磁盤文件內(nèi)妇多。
當(dāng)Executor的CPU core執(zhí)行完一批task伤哺,接著執(zhí)行下一批task時,下一批task就會復(fù)用之前已有的shuffleFileGroup者祖,包括其中的磁盤文件立莉。也就是說,此時task會將數(shù)據(jù)寫入已有的磁盤文件中咸包,而不會寫入新的磁盤文件中桃序。因此,consolidate機制允許不同的task復(fù)用同一批磁盤文件烂瘫,這樣就可以有效將多個task的磁盤文件進行一定程度上的合并媒熊,從而大幅度減少磁盤文件的數(shù)量,進而提升shuffle write的性能坟比。
假設(shè)第二個stage有100個task芦鳍,第一個stage有50個task,總共還是有10個Executor葛账,每個Executor執(zhí)行5個task柠衅。那么原本使用未經(jīng)優(yōu)化的HashShuffleManager時,每個Executor會產(chǎn)生500個磁盤文件籍琳,所有Executor會產(chǎn)生5000個磁盤文件的菲宴。但是此時經(jīng)過優(yōu)化之后,每個Executor創(chuàng)建的磁盤文件的數(shù)量的計算公式為:CPU core的數(shù)量 * 下一個stage的task數(shù)量趋急。也就是說喝峦,每個Executor此時只會創(chuàng)建100個磁盤文件,所有Executor只會創(chuàng)建1000個磁盤文件呜达。
2.4 SortShuffleManager運行原理
SortShuffleManager的運行機制主要分成兩種谣蠢,一種是普通運行機制,另一種是bypass運行機制。當(dāng)shuffle read task的數(shù)量小于等于spark.shuffle.sort.bypassMergeThreshold參數(shù)的值時(默認(rèn)為200)眉踱,就會啟用bypass機制挤忙。
普通運行機制
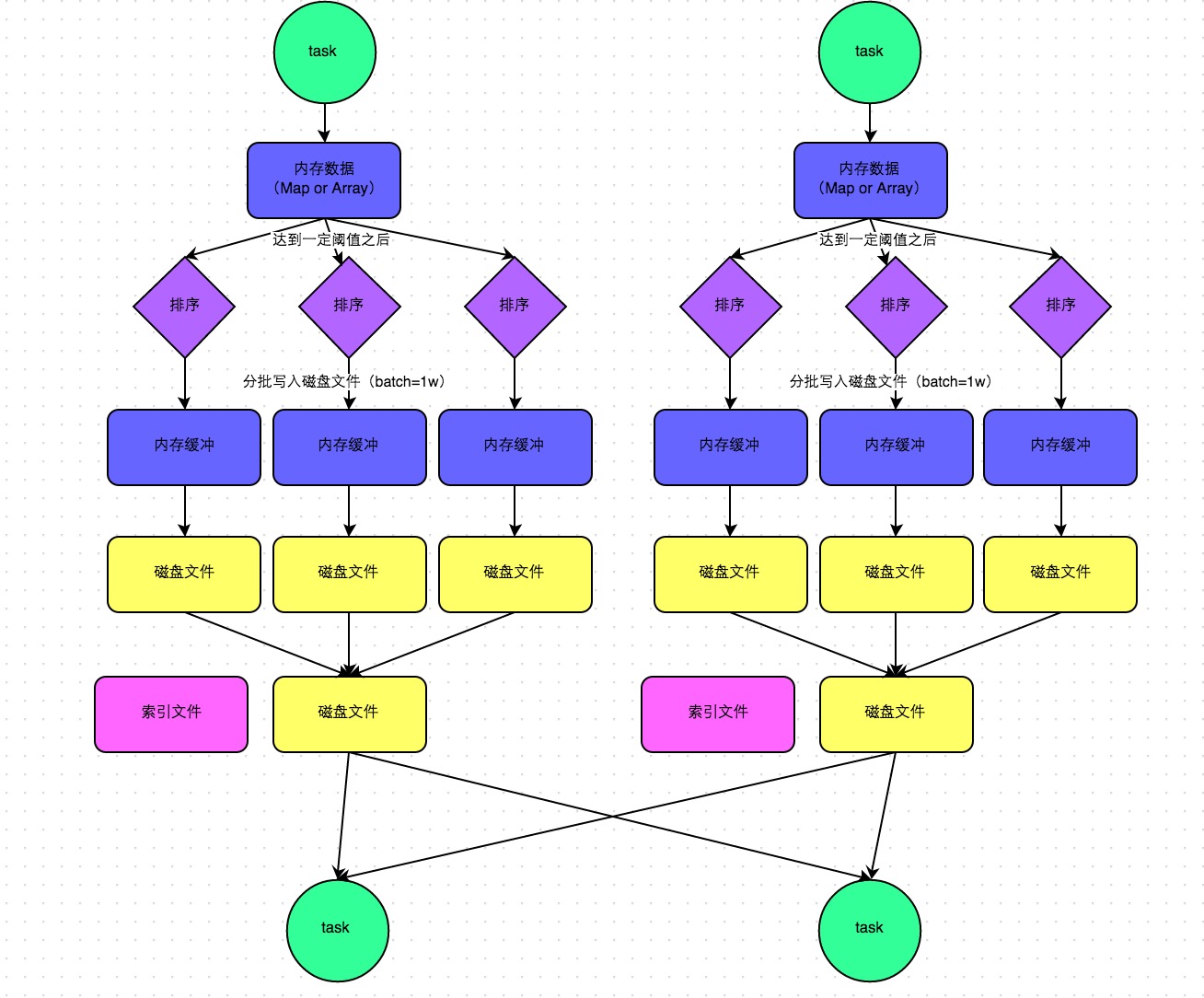
下圖說明了普通的SortShuffleManager的原理。在該模式下谈喳,數(shù)據(jù)會先寫入一個內(nèi)存數(shù)據(jù)結(jié)構(gòu)中册烈,此時根據(jù)不同的shuffle算子,可能選用不同的數(shù)據(jù)結(jié)構(gòu)叁执。如果是reduceByKey這種聚合類的shuffle算子茄厘,那么會選用Map數(shù)據(jù)結(jié)構(gòu)矮冬,一邊通過Map進行聚合,一邊寫入內(nèi)存;如果是join這種普通的shuffle算子码秉,那么會選用Array數(shù)據(jù)結(jié)構(gòu)诱担,直接寫入內(nèi)存。接著琼牧,每寫一條數(shù)據(jù)進入內(nèi)存數(shù)據(jù)結(jié)構(gòu)之后恢筝,就會判斷一下,是否達到了某個臨界閾值巨坊。如果達到臨界閾值的話撬槽,那么就會嘗試將內(nèi)存數(shù)據(jù)結(jié)構(gòu)中的數(shù)據(jù)溢寫到磁盤,然后清空內(nèi)存數(shù)據(jù)結(jié)構(gòu)趾撵。
在溢寫到磁盤文件之前侄柔,會先根據(jù)key對內(nèi)存數(shù)據(jù)結(jié)構(gòu)中已有的數(shù)據(jù)進行排序。排序過后占调,會分批將數(shù)據(jù)寫入磁盤文件暂题。默認(rèn)的batch數(shù)量是10000條,也就是說究珊,排序好的數(shù)據(jù)薪者,會以每批1萬條數(shù)據(jù)的形式分批寫入磁盤文件。寫入磁盤文件是通過Java的BufferedOutputStream實現(xiàn)的剿涮。BufferedOutputStream是Java的緩沖輸出流言津,首先會將數(shù)據(jù)緩沖在內(nèi)存中,當(dāng)內(nèi)存緩沖滿溢之后再一次寫入磁盤文件中取试,這樣可以減少磁盤IO次數(shù)悬槽,提升性能。
一個task將所有數(shù)據(jù)寫入內(nèi)存數(shù)據(jù)結(jié)構(gòu)的過程中想括,會發(fā)生多次磁盤溢寫操作陷谱,也就會產(chǎn)生多個臨時文件。最后會將之前所有的臨時磁盤文件都進行合并,這就是merge過程烟逊,此時會將之前所有臨時磁盤文件中的數(shù)據(jù)讀取出來渣窜,然后依次寫入最終的磁盤文件之中。此外宪躯,由于一個task就只對應(yīng)一個磁盤文件乔宿,也就意味著該task為下游stage的task準(zhǔn)備的數(shù)據(jù)都在這一個文件中,因此還會單獨寫一份索引文件访雪,其中標(biāo)識了下游各個task的數(shù)據(jù)在文件中的start offset與end offset详瑞。
SortShuffleManager由于有一個磁盤文件merge的過程,因此大大減少了文件數(shù)量臣缀。比如第一個stage有50個task坝橡,總共有10個Executor,每個Executor執(zhí)行5個task精置,而第二個stage有100個task计寇。由于每個task最終只有一個磁盤文件,因此此時每個Executor上只有5個磁盤文件脂倦,所有Executor只有50個磁盤文件番宁。
bypass運行機制
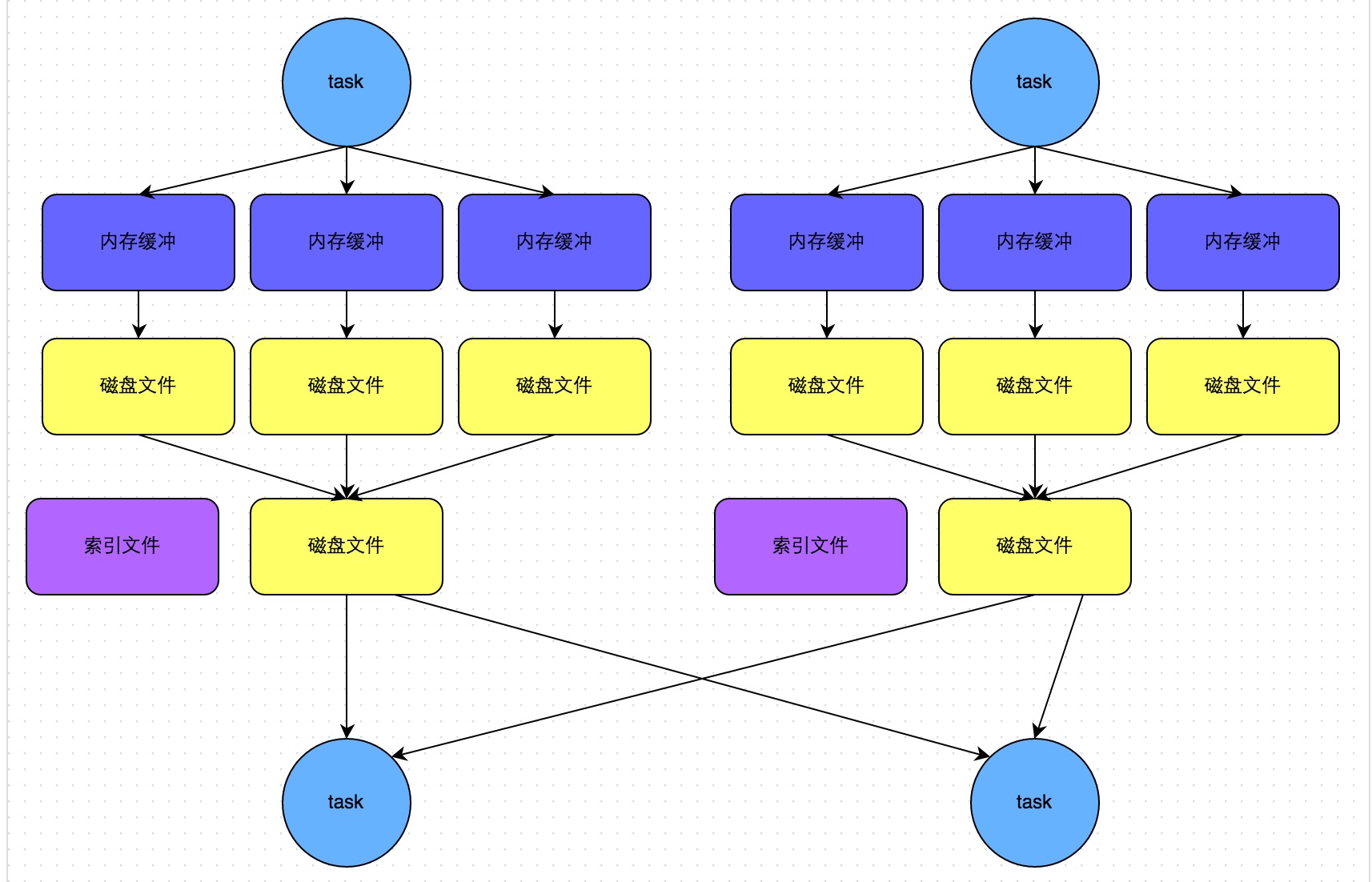
下圖說明了bypass SortShuffleManager的原理。bypass運行機制的觸發(fā)條件如下:
- shuffle map task數(shù)量小于spark.shuffle.sort.bypassMergeThreshold參數(shù)的值赖阻。
- 不是聚合類的shuffle算子(比如reduceByKey)蝶押。
此時task會為每個下游task都創(chuàng)建一個臨時磁盤文件,并將數(shù)據(jù)按key進行hash然后根據(jù)key的hash值火欧,將key寫入對應(yīng)的磁盤文件之中棋电。當(dāng)然,寫入磁盤文件時也是先寫入內(nèi)存緩沖布隔,緩沖寫滿之后再溢寫到磁盤文件的离陶。最后,同樣會將所有臨時磁盤文件都合并成一個磁盤文件衅檀,并創(chuàng)建一個單獨的索引文件招刨。
該過程的磁盤寫機制其實跟未經(jīng)優(yōu)化的HashShuffleManager是一模一樣的,因為都要創(chuàng)建數(shù)量驚人的磁盤文件哀军,只是在最后會做一個磁盤文件的合并而已沉眶。因此少量的最終磁盤文件,也讓該機制相對未經(jīng)優(yōu)化的HashShuffleManager來說杉适,shuffle read的性能會更好谎倔。
而該機制與普通SortShuffleManager運行機制的不同在于:第一,磁盤寫機制不同猿推;第二片习,不會進行排序捌肴。也就是說,啟用該機制的最大好處在于藕咏,shuffle write過程中状知,不需要進行數(shù)據(jù)的排序操作,也就節(jié)省掉了這部分的性能開銷孽查。
2.5 shuffle相關(guān)參數(shù)調(diào)優(yōu)
spark.shuffle.file.buffer
- 默認(rèn)值:32k
- 參數(shù)說明:該參數(shù)用于設(shè)置shuffle write task的BufferedOutputStream的buffer緩沖大小饥悴。將數(shù)據(jù)寫到磁盤文件之前,會先寫入buffer緩沖中盲再,待緩沖寫滿之后西设,才會溢寫到磁盤。
- 調(diào)優(yōu)建議:如果作業(yè)可用的內(nèi)存資源較為充足的話答朋,可以適當(dāng)增加這個參數(shù)的大写俊(比如64k),從而減少shuffle write過程中溢寫磁盤文件的次數(shù)绿映,也就可以減少磁盤IO次數(shù)擒滑,進而提升性能腐晾。在實踐中發(fā)現(xiàn)叉弦,合理調(diào)節(jié)該參數(shù),性能會有1%~5%的提升藻糖。
spark.reducer.maxSizeInFlight
- 默認(rèn)值:48m
- 參數(shù)說明:該參數(shù)用于設(shè)置shuffle read task的buffer緩沖大小淹冰,而這個buffer緩沖決定了每次能夠拉取多少數(shù)據(jù)。
- 調(diào)優(yōu)建議:如果作業(yè)可用的內(nèi)存資源較為充足的話巨柒,可以適當(dāng)增加這個參數(shù)的大杏K(比如96m),從而減少拉取數(shù)據(jù)的次數(shù)洋满,也就可以減少網(wǎng)絡(luò)傳輸?shù)拇螖?shù)晶乔,進而提升性能。在實踐中發(fā)現(xiàn)牺勾,合理調(diào)節(jié)該參數(shù)正罢,性能會有1%~5%的提升。
spark.shuffle.io.maxRetries
- 默認(rèn)值:3
- 參數(shù)說明:shuffle read task從shuffle write task所在節(jié)點拉取屬于自己的數(shù)據(jù)時驻民,如果因為網(wǎng)絡(luò)異常導(dǎo)致拉取失敗翻具,是會自動進行重試的。該參數(shù)就代表了可以重試的最大次數(shù)回还。如果在指定次數(shù)之內(nèi)拉取還是沒有成功裆泳,就可能會導(dǎo)致作業(yè)執(zhí)行失敗。
- 調(diào)優(yōu)建議:對于那些包含了特別耗時的shuffle操作的作業(yè)柠硕,建議增加重試最大次數(shù)(比如60次)工禾,以避免由于JVM的full gc或者網(wǎng)絡(luò)不穩(wěn)定等因素導(dǎo)致的數(shù)據(jù)拉取失敗。在實踐中發(fā)現(xiàn),對于針對超大數(shù)據(jù)量(數(shù)十億~上百億)的shuffle過程闻葵,調(diào)節(jié)該參數(shù)可以大幅度提升穩(wěn)定性糙捺。
spark.shuffle.io.retryWait
- 默認(rèn)值:5s
- 參數(shù)說明:具體解釋同上,該參數(shù)代表了每次重試?yán)?shù)據(jù)的等待間隔笙隙,默認(rèn)是5s洪灯。
- 調(diào)優(yōu)建議:建議加大間隔時長(比如60s),以增加shuffle操作的穩(wěn)定性竟痰。
spark.shuffle.memoryFraction
- 默認(rèn)值:0.2
- 參數(shù)說明:該參數(shù)代表了Executor內(nèi)存中签钩,分配給shuffle read task進行聚合操作的內(nèi)存比例,默認(rèn)是20%坏快。
- 調(diào)優(yōu)建議:在資源參數(shù)調(diào)優(yōu)中講解過這個參數(shù)铅檩。如果內(nèi)存充足,而且很少使用持久化操作莽鸿,建議調(diào)高這個比例昧旨,給shuffle read的聚合操作更多內(nèi)存,以避免由于內(nèi)存不足導(dǎo)致聚合過程中頻繁讀寫磁盤祥得。在實踐中發(fā)現(xiàn)兔沃,合理調(diào)節(jié)該參數(shù)可以將性能提升10%左右。
spark.shuffle.manager
- 默認(rèn)值:sort
- 參數(shù)說明:該參數(shù)用于設(shè)置ShuffleManager的類型级及。Spark 1.5以后乒疏,有三個可選項:hash、sort和tungsten-sort饮焦。HashShuffleManager是Spark 1.2以前的默認(rèn)選項怕吴,但是Spark 1.2以及之后的版本默認(rèn)都是SortShuffleManager了。tungsten-sort與sort類似县踢,但是使用了tungsten計劃中的堆外內(nèi)存管理機制转绷,內(nèi)存使用效率更高。
- 調(diào)優(yōu)建議:由于SortShuffleManager默認(rèn)會對數(shù)據(jù)進行排序硼啤,因此如果你的業(yè)務(wù)邏輯中需要該排序機制的話议经,則使用默認(rèn)的SortShuffleManager就可以;而如果你的業(yè)務(wù)邏輯不需要對數(shù)據(jù)進行排序丙曙,那么建議參考后面的幾個參數(shù)調(diào)優(yōu)爸业,通過bypass機制或優(yōu)化的HashShuffleManager來避免排序操作,同時提供較好的磁盤讀寫性能亏镰。這里要注意的是扯旷,tungsten-sort要慎用,因為之前發(fā)現(xiàn)了一些相應(yīng)的bug索抓。
spark.shuffle.sort.bypassMergeThreshold
- 默認(rèn)值:200
- 參數(shù)說明:當(dāng)ShuffleManager為SortShuffleManager時钧忽,如果shuffle read task的數(shù)量小于這個閾值(默認(rèn)是200)毯炮,則shuffle write過程中不會進行排序操作,而是直接按照未經(jīng)優(yōu)化的HashShuffleManager的方式去寫數(shù)據(jù)耸黑,但是最后會將每個task產(chǎn)生的所有臨時磁盤文件都合并成一個文件桃煎,并會創(chuàng)建單獨的索引文件。
- 調(diào)優(yōu)建議:當(dāng)你使用SortShuffleManager時大刊,如果的確不需要排序操作为迈,那么建議將這個參數(shù)調(diào)大一些,大于shuffle read task的數(shù)量缺菌。那么此時就會自動啟用bypass機制葫辐,map-side就不會進行排序了,減少了排序的性能開銷伴郁。但是這種方式下耿战,依然會產(chǎn)生大量的磁盤文件,因此shuffle write性能有待提高焊傅。
spark.shuffle.consolidateFiles
- 默認(rèn)值:false
- 參數(shù)說明:如果使用HashShuffleManager剂陡,該參數(shù)有效。如果設(shè)置為true狐胎,那么就會開啟consolidate機制鸭栖,會大幅度合并shuffle write的輸出文件,對于shuffle read task數(shù)量特別多的情況下顽爹,這種方法可以極大地減少磁盤IO開銷纤泵,提升性能。
- 調(diào)優(yōu)建議:如果的確不需要SortShuffleManager的排序機制镜粤,那么除了使用bypass機制,還可以嘗試將spark.shffle.manager參數(shù)手動指定為hash玻褪,使用HashShuffleManager肉渴,同時開啟consolidate機制。在實踐中嘗試過带射,發(fā)現(xiàn)其性能比開啟了bypass機制的SortShuffleManager要高出10%~30%同规。
