1 前言
在大數(shù)據(jù)計(jì)算領(lǐng)域眯亦,Spark已經(jīng)成為了越來(lái)越流行伤溉、越來(lái)越受歡迎的計(jì)算平臺(tái)之一。Spark的功能涵蓋了大數(shù)據(jù)領(lǐng)域的離線批處理妻率、SQL類處理乱顾、流式/實(shí)時(shí)計(jì)算、機(jī)器學(xué)習(xí)舌涨、圖計(jì)算等各種不同類型的計(jì)算操作糯耍,應(yīng)用范圍與前景非常廣泛。在美團(tuán)?大眾點(diǎn)評(píng)囊嘉,已經(jīng)有很多同學(xué)在各種項(xiàng)目中嘗試使用Spark温技。大多數(shù)同學(xué)(包括筆者在內(nèi)),最初開始嘗試使用Spark的原因很簡(jiǎn)單扭粱,主要就是為了讓大數(shù)據(jù)計(jì)算作業(yè)的執(zhí)行速度更快舵鳞、性能更高。
然而琢蛤,通過(guò)Spark開發(fā)出高性能的大數(shù)據(jù)計(jì)算作業(yè)蜓堕,并不是那么簡(jiǎn)單的。如果沒(méi)有對(duì)Spark作業(yè)進(jìn)行合理的調(diào)優(yōu)博其,Spark作業(yè)的執(zhí)行速度可能會(huì)很慢套才,這樣就完全體現(xiàn)不出Spark作為一種快速大數(shù)據(jù)計(jì)算引擎的優(yōu)勢(shì)來(lái)。因此慕淡,想要用好Spark背伴,就必須對(duì)其進(jìn)行合理的性能優(yōu)化。
Spark的性能調(diào)優(yōu)實(shí)際上是由很多部分組成的峰髓,不是調(diào)節(jié)幾個(gè)參數(shù)就可以立竿見影提升作業(yè)性能的傻寂。我們需要根據(jù)不同的業(yè)務(wù)場(chǎng)景以及數(shù)據(jù)情況,對(duì)Spark作業(yè)進(jìn)行綜合性的分析携兵,然后進(jìn)行多個(gè)方面的調(diào)節(jié)和優(yōu)化疾掰,才能獲得最佳性能。
筆者根據(jù)之前的Spark作業(yè)開發(fā)經(jīng)驗(yàn)以及實(shí)踐積累徐紧,總結(jié)出了一套Spark作業(yè)的性能優(yōu)化方案静檬。整套方案主要分為開發(fā)調(diào)優(yōu)、資源調(diào)優(yōu)并级、數(shù)據(jù)傾斜調(diào)優(yōu)拂檩、shuffle調(diào)優(yōu)幾個(gè)部分。開發(fā)調(diào)優(yōu)和資源調(diào)優(yōu)是所有Spark作業(yè)都需要注意和遵循的一些基本原則死遭,是高性能Spark作業(yè)的基礎(chǔ);數(shù)據(jù)傾斜調(diào)優(yōu)凯旋,主要講解了一套完整的用來(lái)解決Spark作業(yè)數(shù)據(jù)傾斜的解決方案呀潭;shuffle調(diào)優(yōu)钉迷,面向的是對(duì)Spark的原理有較深層次掌握和研究的同學(xué),主要講解了如何對(duì)Spark作業(yè)的shuffle運(yùn)行過(guò)程以及細(xì)節(jié)進(jìn)行調(diào)優(yōu)钠署。
本文作為Spark性能優(yōu)化指南的基礎(chǔ)篇糠聪,主要講解開發(fā)調(diào)優(yōu)以及資源調(diào)優(yōu)。
2 開發(fā)調(diào)優(yōu)
2.1 調(diào)優(yōu)概述
Spark性能優(yōu)化的第一步谐鼎,就是要在開發(fā)Spark作業(yè)的過(guò)程中注意和應(yīng)用一些性能優(yōu)化的基本原則舰蟆。開發(fā)調(diào)優(yōu),就是要讓大家了解以下一些Spark基本開發(fā)原則狸棍,包括:RDD lineage設(shè)計(jì)身害、算子的合理使用、特殊操作的優(yōu)化等草戈。在開發(fā)過(guò)程中塌鸯,時(shí)時(shí)刻刻都應(yīng)該注意以上原則,并將這些原則根據(jù)具體的業(yè)務(wù)以及實(shí)際的應(yīng)用場(chǎng)景唐片,靈活地運(yùn)用到自己的Spark作業(yè)中丙猬。
2.2 原則一:避免創(chuàng)建重復(fù)的RDD
通常來(lái)說(shuō),我們?cè)陂_發(fā)一個(gè)Spark作業(yè)時(shí)费韭,首先是基于某個(gè)數(shù)據(jù)源(比如Hive表或HDFS文件)創(chuàng)建一個(gè)初始的RDD茧球;接著對(duì)這個(gè)RDD執(zhí)行某個(gè)算子操作,然后得到下一個(gè)RDD星持;以此類推抢埋,循環(huán)往復(fù),直到計(jì)算出最終我們需要的結(jié)果钉汗。在這個(gè)過(guò)程中羹令,多個(gè)RDD會(huì)通過(guò)不同的算子操作(比如map、reduce等)串起來(lái)损痰,這個(gè)“RDD串”福侈,就是RDD lineage,也就是“RDD的血緣關(guān)系鏈”卢未。
我們?cè)陂_發(fā)過(guò)程中要注意:對(duì)于同一份數(shù)據(jù)肪凛,只應(yīng)該創(chuàng)建一個(gè)RDD,不能創(chuàng)建多個(gè)RDD來(lái)代表同一份數(shù)據(jù)辽社。
一些Spark初學(xué)者在剛開始開發(fā)Spark作業(yè)時(shí)伟墙,或者是有經(jīng)驗(yàn)的工程師在開發(fā)RDD lineage極其冗長(zhǎng)的Spark作業(yè)時(shí),可能會(huì)忘了自己之前對(duì)于某一份數(shù)據(jù)已經(jīng)創(chuàng)建過(guò)一個(gè)RDD了滴铅,從而導(dǎo)致對(duì)于同一份數(shù)據(jù)戳葵,創(chuàng)建了多個(gè)RDD。這就意味著汉匙,我們的Spark作業(yè)會(huì)進(jìn)行多次重復(fù)計(jì)算來(lái)創(chuàng)建多個(gè)代表相同數(shù)據(jù)的RDD生蚁,進(jìn)而增加了作業(yè)的性能開銷。
一個(gè)簡(jiǎn)單的例子
//需要對(duì)名為“hello.txt”的HDFS文件進(jìn)行一次map操作邦投,再進(jìn)行一次reduce操作。也就是說(shuō)志衣,需要對(duì)一份數(shù)據(jù)執(zhí)行兩次算子操作。
//錯(cuò)誤的做法:對(duì)于同一份數(shù)據(jù)執(zhí)行多次算子操作時(shí)猛们,創(chuàng)建多個(gè)RDD念脯。
//這里執(zhí)行了兩次textFile方法阅懦,針對(duì)同一個(gè)HDFS文件和二,創(chuàng)建了兩個(gè)RDD出來(lái)耳胎,然后分別對(duì)每個(gè)RDD都執(zhí)行了一個(gè)算子操作惯吕。
//這種情況下,Spark需要從HDFS上兩次加載hello.txt文件的內(nèi)容怕午,并創(chuàng)建兩個(gè)單獨(dú)的RDD;
//第二次加載HDFS文件以及創(chuàng)建RDD的性能開銷郁惜,很明顯是白白浪費(fèi)掉的堡距。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
rdd1.map(...)
val rdd2 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
rdd2.reduce(...)
//正確的用法:對(duì)于一份數(shù)據(jù)執(zhí)行多次算子操作時(shí)兆蕉,只使用一個(gè)RDD。
//這種寫法很明顯比上一種寫法要好多了虎韵,因?yàn)槲覀儗?duì)于同一份數(shù)據(jù)只創(chuàng)建了一個(gè)RDD易稠,然后對(duì)這一個(gè)RDD執(zhí)行了多次算子操作包蓝。
//但是要注意到這里為止優(yōu)化還沒(méi)有結(jié)束驶社,由于rdd1被執(zhí)行了兩次算子操作测萎,第二次執(zhí)行reduce操作的時(shí)候亡电,
//還會(huì)再次從源頭處重新計(jì)算一次rdd1的數(shù)據(jù)硅瞧,因此還是會(huì)有重復(fù)計(jì)算的性能開銷。
//要徹底解決這個(gè)問(wèn)題,必須結(jié)合“原則三:對(duì)多次使用的RDD進(jìn)行持久化”或辖,才能保證一個(gè)RDD被多次使用時(shí)只被計(jì)算一次。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
rdd1.map(...)
rdd1.reduce(...)
2.3 原則二:盡可能復(fù)用同一個(gè)RDD
除了要避免在開發(fā)過(guò)程中對(duì)一份完全相同的數(shù)據(jù)創(chuàng)建多個(gè)RDD之外孝凌,在對(duì)不同的數(shù)據(jù)執(zhí)行算子操作時(shí)還要盡可能地復(fù)用一個(gè)RDD月腋。比如說(shuō)蟀架,有一個(gè)RDD的數(shù)據(jù)格式是key-value類型的榆骚,另一個(gè)是單value類型的片拍,這兩個(gè)RDD的value數(shù)據(jù)是完全一樣的妓肢。那么此時(shí)我們可以只使用key-value類型的那個(gè)RDD捌省,因?yàn)槠渲幸呀?jīng)包含了另一個(gè)的數(shù)據(jù)碉钠。對(duì)于類似這種多個(gè)RDD的數(shù)據(jù)有重疊或者包含的情況纲缓,我們應(yīng)該盡量復(fù)用一個(gè)RDD喊废,這樣可以盡可能地減少RDD的數(shù)量祝高,從而盡可能減少算子執(zhí)行的次數(shù)污筷。
一個(gè)簡(jiǎn)單的例子
//錯(cuò)誤的做法。
//有一個(gè)<Long, String>格式的RDD瓣蛀,即rdd1陆蟆。
//接著由于業(yè)務(wù)需要惋增,對(duì)rdd1執(zhí)行了一個(gè)map操作叠殷,創(chuàng)建了一個(gè)rdd2器腋,而rdd2中的數(shù)據(jù)僅僅是rdd1中的value值而已,
//也就是說(shuō)纫塌,rdd2是rdd1的子集诊县。
JavaPairRDD<Long, String> rdd1 = ...
JavaRDD<String> rdd2 = rdd1.map(...)
// 分別對(duì)rdd1和rdd2執(zhí)行了不同的算子操作措左。
rdd1.reduceByKey(...)
rdd2.map(...)
//正確的做法依痊。
//上面這個(gè)case中,其實(shí)rdd1和rdd2的區(qū)別無(wú)非就是數(shù)據(jù)格式不同而已胸嘁,rdd2的數(shù)據(jù)完全就是rdd1的子集而已,
//卻創(chuàng)建了兩個(gè)rdd性宏,并對(duì)兩個(gè)rdd都執(zhí)行了一次算子操作。
//此時(shí)會(huì)因?yàn)閷?duì)rdd1執(zhí)行map算子來(lái)創(chuàng)建rdd2毫胜,而多執(zhí)行一次算子操作,進(jìn)而增加性能開銷酵使。
//其實(shí)在這種情況下完全可以復(fù)用同一個(gè)RDD荐吉。
//我們可以使用rdd1口渔,既做reduceByKey操作样屠,也做map操作缺脉。
//在進(jìn)行第二個(gè)map操作時(shí)痪欲,只使用每個(gè)數(shù)據(jù)的tuple._2攻礼,也就是rdd1中的value值,即可秘蛔。
JavaPairRDD<Long, String> rdd1 = ...
rdd1.reduceByKey(...)
rdd1.map(tuple._2...)
//第二種方式相較于第一種方式而言陨亡,很明顯減少了一次rdd2的計(jì)算開銷深员。
//但是到這里為止负蠕,優(yōu)化還沒(méi)有結(jié)束倦畅,對(duì)rdd1我們還是執(zhí)行了兩次算子操作遮糖,rdd1實(shí)際上還是會(huì)被計(jì)算兩次叠赐。
//因此還需要配合“原則三:對(duì)多次使用的RDD進(jìn)行持久化”進(jìn)行使用欲账,才能保證一個(gè)RDD被多次使用時(shí)只被計(jì)算一次芭概。
2.4 原則三:對(duì)多次使用的RDD進(jìn)行持久化
當(dāng)你在Spark代碼中多次對(duì)一個(gè)RDD做了算子操作后,恭喜罢洲,你已經(jīng)實(shí)現(xiàn)Spark作業(yè)第一步的優(yōu)化了踢故,也就是盡可能復(fù)用RDD。此時(shí)就該在這個(gè)基礎(chǔ)之上殿较,進(jìn)行第二步優(yōu)化了,也就是要保證對(duì)一個(gè)RDD執(zhí)行多次算子操作時(shí)淋纲,這個(gè)RDD本身僅僅被計(jì)算一次。
Spark中對(duì)于一個(gè)RDD執(zhí)行多次算子的默認(rèn)原理是這樣的:每次你對(duì)一個(gè)RDD執(zhí)行一個(gè)算子操作時(shí)洽瞬,都會(huì)重新從源頭處計(jì)算一遍玷或,計(jì)算出那個(gè)RDD來(lái)片任,然后再對(duì)這個(gè)RDD執(zhí)行你的算子操作蔬胯。這種方式的性能是很差的氛濒。
因此對(duì)于這種情況,我們的建議是:對(duì)多次使用的RDD進(jìn)行持久化京景。此時(shí)Spark就會(huì)根據(jù)你的持久化策略,將RDD中的數(shù)據(jù)保存到內(nèi)存或者磁盤中鄙皇。以后每次對(duì)這個(gè)RDD進(jìn)行算子操作時(shí)馍惹,都會(huì)直接從內(nèi)存或磁盤中提取持久化的RDD數(shù)據(jù)薪丁,然后執(zhí)行算子皱碘,而不會(huì)從源頭處重新計(jì)算一遍這個(gè)RDD,再執(zhí)行算子操作动雹。
//如果要對(duì)一個(gè)RDD進(jìn)行持久化,只要對(duì)這個(gè)RDD調(diào)用cache()和persist()即可胰蝠。
//正確的做法歼培。
//cache()方法表示:使用非序列化的方式將RDD中的數(shù)據(jù)全部嘗試持久化到內(nèi)存中震蒋。
//此時(shí)再對(duì)rdd1執(zhí)行兩次算子操作時(shí)躲庄,只有在第一次執(zhí)行map算子時(shí)查剖,才會(huì)將這個(gè)rdd1從源頭處計(jì)算一次噪窘。
//第二次執(zhí)行reduce算子時(shí)笋庄,就會(huì)直接從內(nèi)存中提取數(shù)據(jù)進(jìn)行計(jì)算倔监,不會(huì)重復(fù)計(jì)算一個(gè)rdd直砂。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").cache()
rdd1.map(...)
rdd1.reduce(...)
//persist()方法表示:手動(dòng)選擇持久化級(jí)別浩习,并使用指定的方式進(jìn)行持久化静暂。
//比如說(shuō)谱秽,StorageLevel.MEMORY_AND_DISK_SER表示洽蛀,內(nèi)存充足時(shí)優(yōu)先持久化到內(nèi)存中弯院,內(nèi)存不充足時(shí)持久化到磁盤文件中。
//而且其中的_SER后綴表示听绳,使用序列化的方式來(lái)保存RDD數(shù)據(jù),此時(shí)RDD中的每個(gè)partition都會(huì)序列化成一個(gè)大的字節(jié)數(shù)組椅挣,
//然后再持久化到內(nèi)存或磁盤中。
// 序列化的方式可以減少持久化的數(shù)據(jù)對(duì)內(nèi)存/磁盤的占用量塔拳,進(jìn)而避免內(nèi)存被持久化數(shù)據(jù)占用過(guò)多,從而發(fā)生頻繁GC靠抑。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").persist(StorageLevel.MEMORY_AND_DISK_SER)
rdd1.map(...)
rdd1.reduce(...)
對(duì)于persist()方法而言,我們可以根據(jù)不同的業(yè)務(wù)場(chǎng)景選擇不同的持久化級(jí)別颂碧。
Spark的持久化級(jí)別
| 持久化級(jí)別 | 含義解釋 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java對(duì)象格式,將數(shù)據(jù)保存在內(nèi)存中载城。如果內(nèi)存不夠存放所有的數(shù)據(jù)肌似,則數(shù)據(jù)可能就不會(huì)進(jìn)行持久化。那么下次對(duì)這個(gè)RDD執(zhí)行算子操作時(shí)诉瓦,那些沒(méi)有被持久化的數(shù)據(jù)力细,需要從源頭處重新計(jì)算一遍。這是默認(rèn)的持久化策略眠蚂,使用cache()方法時(shí),實(shí)際就是使用的這種持久化策略对雪。 |
| MEMORY_AND_DISK | 使用未序列化的Java對(duì)象格式,優(yōu)先嘗試將數(shù)據(jù)保存在內(nèi)存中瑟捣。如果內(nèi)存不夠存放所有的數(shù)據(jù),會(huì)將數(shù)據(jù)寫入磁盤文件中迈套,下次對(duì)這個(gè)RDD執(zhí)行算子時(shí),持久化在磁盤文件中的數(shù)據(jù)會(huì)被讀取出來(lái)使用桑李。 |
| MEMORY_ONLY_SER | 基本含義同MEMORY_ONLY。唯一的區(qū)別是贵白,會(huì)將RDD中的數(shù)據(jù)進(jìn)行序列化率拒,RDD的每個(gè)partition會(huì)被序列化成一個(gè)字節(jié)數(shù)組禁荒。這種方式更加節(jié)省內(nèi)存猬膨,從而可以避免持久化的數(shù)據(jù)占用過(guò)多內(nèi)存導(dǎo)致頻繁GC呛伴。 |
| MEMORY_AND_DISK_SER | 基本含義同MEMORY_AND_DISK。唯一的區(qū)別是热康,會(huì)將RDD中的數(shù)據(jù)進(jìn)行序列化沛申,RDD的每個(gè)partition會(huì)被序列化成一個(gè)字節(jié)數(shù)組姐军。這種方式更加節(jié)省內(nèi)存铁材,從而可以避免持久化的數(shù)據(jù)占用過(guò)多內(nèi)存導(dǎo)致頻繁GC奕锌。 |
| DISK_ONLY | 使用未序列化的Java對(duì)象格式,將數(shù)據(jù)全部寫入磁盤文件中歇攻。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 | 對(duì)于上述任意一種持久化策略固惯,如果加上后綴_2缴守,代表的是將每個(gè)持久化的數(shù)據(jù)葬毫,都復(fù)制一份副本,并將副本保存到其他節(jié)點(diǎn)上贴捡。這種基于副本的持久化機(jī)制主要用于進(jìn)行容錯(cuò)。假如某個(gè)節(jié)點(diǎn)掛掉烂斋,節(jié)點(diǎn)的內(nèi)存或磁盤中的持久化數(shù)據(jù)丟失了,那么后續(xù)對(duì)RDD計(jì)算時(shí)還可以使用該數(shù)據(jù)在其他節(jié)點(diǎn)上的副本汛骂。如果沒(méi)有副本的話罕模,就只能將這些數(shù)據(jù)從源頭處重新計(jì)算一遍了 |
如何選擇一種最合適的持久化策略
- 默認(rèn)情況下帘瞭,性能最高的當(dāng)然是MEMORY_ONLY,但前提是你的內(nèi)存必須足夠足夠大蝶念,可以綽綽有余地存放下整個(gè)RDD的所有數(shù)據(jù)抛腕。因?yàn)椴贿M(jìn)行序列化與反序列化操作媒殉,就避免了這部分的性能開銷担敌;對(duì)這個(gè)RDD的后續(xù)算子操作廷蓉,都是基于純內(nèi)存中的數(shù)據(jù)的操作全封,不需要從磁盤文件中讀取數(shù)據(jù)苦酱,性能也很高售貌;而且不需要復(fù)制一份數(shù)據(jù)副本疫萤,并遠(yuǎn)程傳送到其他節(jié)點(diǎn)上。但是這里必須要注意的是扯饶,在實(shí)際的生產(chǎn)環(huán)境中,恐怕能夠直接用這種策略的場(chǎng)景還是有限的尾序,如果RDD中數(shù)據(jù)比較多時(shí)(比如幾十億),直接用這種持久化級(jí)別躯砰,會(huì)導(dǎo)致JVM的OOM內(nèi)存溢出異常。
- 如果使用MEMORY_ONLY級(jí)別時(shí)發(fā)生了內(nèi)存溢出琢歇,那么建議嘗試使用MEMORY_ONLY_SER級(jí)別梦鉴。該級(jí)別會(huì)將RDD數(shù)據(jù)序列化后再保存在內(nèi)存中,此時(shí)每個(gè)partition僅僅是一個(gè)字節(jié)數(shù)組而已揭保,大大減少了對(duì)象數(shù)量,并降低了內(nèi)存占用秸侣。這種級(jí)別比MEMORY_ONLY多出來(lái)的性能開銷,主要就是序列化與反序列化的開銷味榛。但是后續(xù)算子可以基于純內(nèi)存進(jìn)行操作,因此性能總體還是比較高的励负。此外藕溅,可能發(fā)生的問(wèn)題同上继榆,如果RDD中的數(shù)據(jù)量過(guò)多的話,還是可能會(huì)導(dǎo)致OOM內(nèi)存溢出的異常略吨。
- 如果純內(nèi)存的級(jí)別都無(wú)法使用集币,那么建議使用MEMORY_AND_DISK_SER策略翠忠,而不是MEMORY_AND_DISK策略鞠苟。因?yàn)榧热坏搅诉@一步秽之,就說(shuō)明RDD的數(shù)據(jù)量很大当娱,內(nèi)存無(wú)法完全放下考榨。序列化后的數(shù)據(jù)比較少,可以節(jié)省內(nèi)存和磁盤的空間開銷河质。同時(shí)該策略會(huì)優(yōu)先盡量嘗試將數(shù)據(jù)緩存在內(nèi)存中冀惭,內(nèi)存緩存不下才會(huì)寫入磁盤掀鹅。
- 通常不建議使用DISK_ONLY和后綴為_2的級(jí)別:因?yàn)橥耆诖疟P文件進(jìn)行數(shù)據(jù)的讀寫散休,會(huì)導(dǎo)致性能急劇降低乐尊,有時(shí)還不如重新計(jì)算一次所有RDD。后綴為_2的級(jí)別扔嵌,必須將所有數(shù)據(jù)都復(fù)制一份副本限府,并發(fā)送到其他節(jié)點(diǎn)上,數(shù)據(jù)復(fù)制以及網(wǎng)絡(luò)傳輸會(huì)導(dǎo)致較大的性能開銷谣殊,除非是要求作業(yè)的高可用性,否則不建議使用姻几。
2.5 原則四:盡量避免使用shuffle類算子
如果有可能的話,要盡量避免使用shuffle類算子蛇捌。因?yàn)镾park作業(yè)運(yùn)行過(guò)程中抚恒,最消耗性能的地方就是shuffle過(guò)程络拌。shuffle過(guò)程俭驮,簡(jiǎn)單來(lái)說(shuō)春贸,就是將分布在集群中多個(gè)節(jié)點(diǎn)上的同一個(gè)key,拉取到同一個(gè)節(jié)點(diǎn)上萍恕,進(jìn)行聚合或join等操作逸嘀。比如reduceByKey允粤、join等算子崭倘,都會(huì)觸發(fā)shuffle操作类垫。
shuffle過(guò)程中司光,各個(gè)節(jié)點(diǎn)上的相同key都會(huì)先寫入本地磁盤文件中悉患,然后其他節(jié)點(diǎn)需要通過(guò)網(wǎng)絡(luò)傳輸拉取各個(gè)節(jié)點(diǎn)上的磁盤文件中的相同key。而且相同key都拉取到同一個(gè)節(jié)點(diǎn)進(jìn)行聚合操作時(shí)购撼,還有可能會(huì)因?yàn)橐粋€(gè)節(jié)點(diǎn)上處理的key過(guò)多跪削,導(dǎo)致內(nèi)存不夠存放迂求,進(jìn)而溢寫到磁盤文件中。因此在shuffle過(guò)程中揩局,可能會(huì)發(fā)生大量的磁盤文件讀寫的IO操作,以及數(shù)據(jù)的網(wǎng)絡(luò)傳輸操作掀虎。磁盤IO和網(wǎng)絡(luò)數(shù)據(jù)傳輸也是shuffle性能較差的主要原因付枫。
因此在我們的開發(fā)過(guò)程中驰怎,能避免則盡可能避免使用reduceByKey阐滩、join县忌、distinct掂榔、repartition等會(huì)進(jìn)行shuffle的算子症杏,盡量使用map類的非shuffle算子。這樣的話厉颤,沒(méi)有shuffle操作或者僅有較少shuffle操作的Spark作業(yè)穴豫,可以大大減少性能開銷逼友。
Broadcast與map進(jìn)行join代碼示例
//傳統(tǒng)的join操作會(huì)導(dǎo)致shuffle操作精肃。
//因?yàn)閮蓚€(gè)RDD中帜乞,相同的key都需要通過(guò)網(wǎng)絡(luò)拉取到一個(gè)節(jié)點(diǎn)上,由一個(gè)task進(jìn)行join操作挖函。
val rdd3 = rdd1.join(rdd2)
//Broadcast+map的join操作状植,不會(huì)導(dǎo)致shuffle操作怨喘。
//使用Broadcast將一個(gè)數(shù)據(jù)量較小的RDD作為廣播變量津畸。
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
//在rdd1.map算子中必怜,可以從rdd2DataBroadcast中肉拓,獲取rdd2的所有數(shù)據(jù)梳庆。
//然后進(jìn)行遍歷暖途,如果發(fā)現(xiàn)rdd2中某條數(shù)據(jù)的key與rdd1的當(dāng)前數(shù)據(jù)的key是相同的膏执,那么就判定可以進(jìn)行join。
//此時(shí)就可以根據(jù)自己需要的方式更米,將rdd1當(dāng)前數(shù)據(jù)與rdd2中可以連接的數(shù)據(jù)欺栗,拼接在一起(String或Tuple)。
val rdd3 = rdd1.map(rdd2DataBroadcast...)
//注意迟几,以上操作,建議僅僅在rdd2的數(shù)據(jù)量比較少(比如幾百M(fèi)类腮,或者一兩G)的情況下使用。
//因?yàn)槊總€(gè)Executor的內(nèi)存中蚜枢,都會(huì)駐留一份rdd2的全量數(shù)據(jù)因宇。
2.6 原則五:使用map-side預(yù)聚合的shuffle操作
如果因?yàn)闃I(yè)務(wù)需要祟偷,一定要使用shuffle操作,無(wú)法用map類的算子來(lái)替代修肠,那么盡量使用可以map-side預(yù)聚合的算子贺辰。
所謂的map-side預(yù)聚合嵌施,說(shuō)的是在每個(gè)節(jié)點(diǎn)本地對(duì)相同的key進(jìn)行一次聚合操作饲化,類似于MapReduce中的本地combiner吗伤。map-side預(yù)聚合之后吃靠,每個(gè)節(jié)點(diǎn)本地就只會(huì)有一條相同的key足淆,因?yàn)槎鄺l相同的key都被聚合起來(lái)了。其他節(jié)點(diǎn)在拉取所有節(jié)點(diǎn)上的相同key時(shí)巧号,就會(huì)大大減少需要拉取的數(shù)據(jù)數(shù)量容为,從而也就減少了磁盤IO以及網(wǎng)絡(luò)傳輸開銷箭启。通常來(lái)說(shuō)缓呛,在可能的情況下靠欢,建議使用reduceByKey或者aggregateByKey算子來(lái)替代掉groupByKey算子。因?yàn)閞educeByKey和aggregateByKey算子都會(huì)使用用戶自定義的函數(shù)對(duì)每個(gè)節(jié)點(diǎn)本地的相同key進(jìn)行預(yù)聚合门怪。而groupByKey算子是不會(huì)進(jìn)行預(yù)聚合的骡澈,全量的數(shù)據(jù)會(huì)在集群的各個(gè)節(jié)點(diǎn)之間分發(fā)和傳輸薪缆,性能相對(duì)來(lái)說(shuō)比較差秧廉。
比如如下兩幅圖拣帽,就是典型的例子,分別基于reduceByKey和groupByKey進(jìn)行單詞計(jì)數(shù)减拭。其中第一張圖是groupByKey的原理圖蔽豺,可以看到拧粪,沒(méi)有進(jìn)行任何本地聚合時(shí)修陡,所有數(shù)據(jù)都會(huì)在集群節(jié)點(diǎn)之間傳輸可霎;第二張圖是reduceByKey的原理圖魄鸦,可以看到癣朗,每個(gè)節(jié)點(diǎn)本地的相同key數(shù)據(jù),都進(jìn)行了預(yù)聚合旷余,然后才傳輸?shù)狡渌?jié)點(diǎn)上進(jìn)行全局聚合绢记。
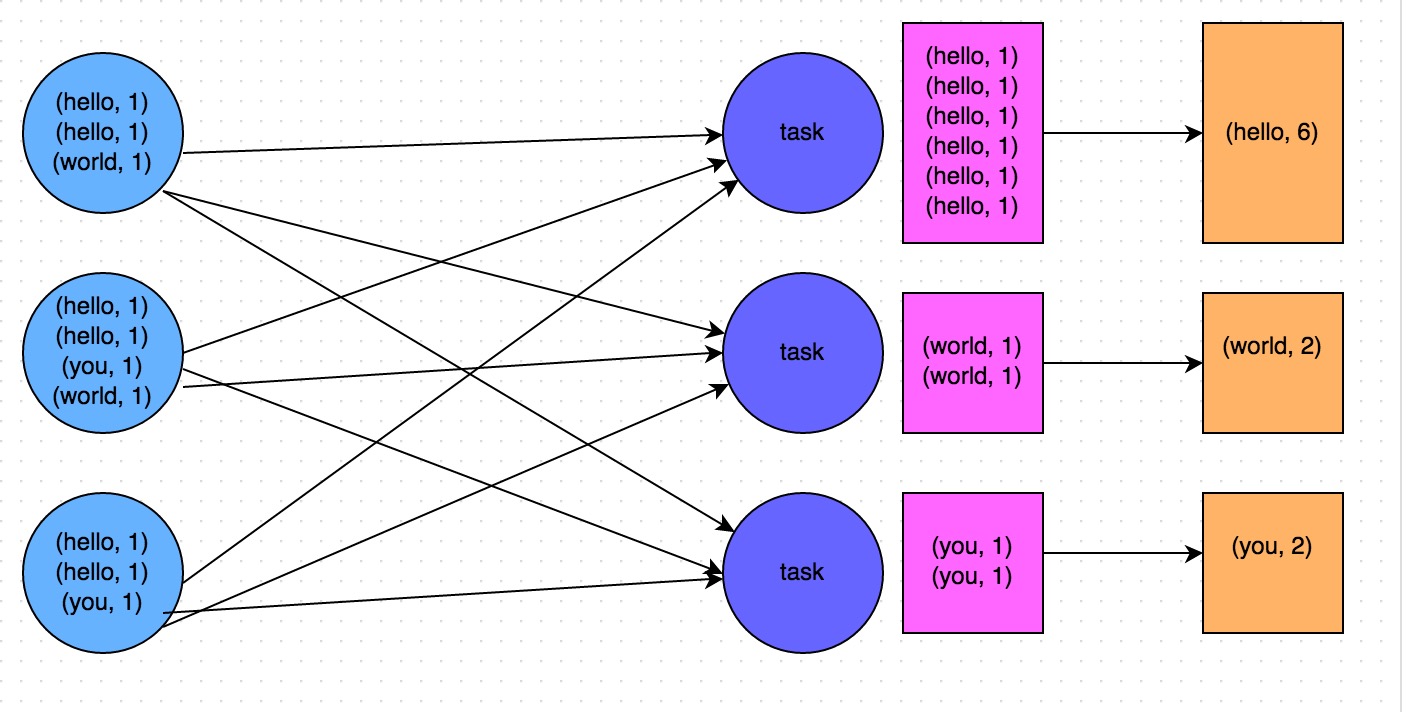
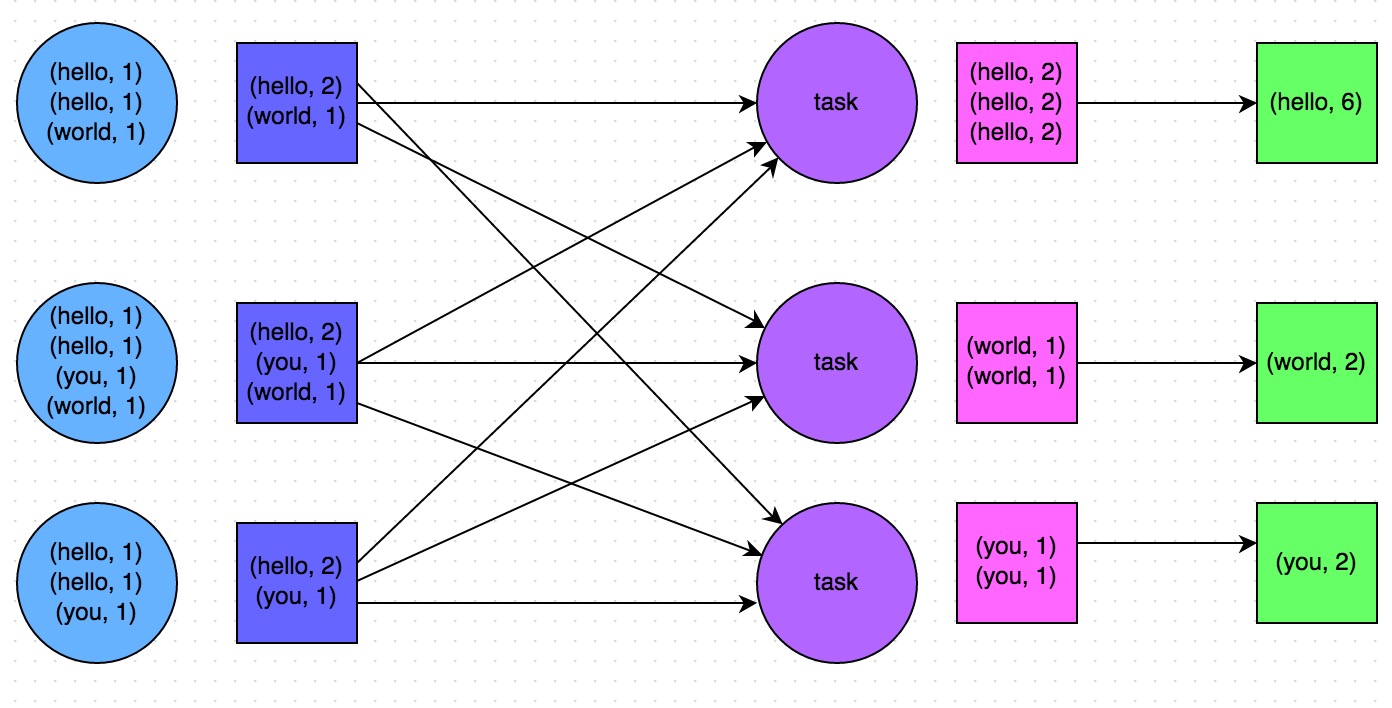
2.7 原則六:使用高性能的算子
除了shuffle相關(guān)的算子有優(yōu)化原則之外正卧,其他的算子也都有著相應(yīng)的優(yōu)化原則。
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
mapPartitions類的算子炉旷,一次函數(shù)調(diào)用會(huì)處理一個(gè)partition所有的數(shù)據(jù)签孔,而不是一次函數(shù)調(diào)用處理一條窘行,性能相對(duì)來(lái)說(shuō)會(huì)高一些骏啰。但是有的時(shí)候抽高,使用mapPartitions會(huì)出現(xiàn)OOM(內(nèi)存溢出)的問(wèn)題。因?yàn)閱未魏瘮?shù)調(diào)用就要處理掉一個(gè)partition所有的數(shù)據(jù)翘骂,如果內(nèi)存不夠壁熄,垃圾回收時(shí)是無(wú)法回收掉太多對(duì)象的碳竟,很可能出現(xiàn)OOM異常草丧。所以使用這類操作時(shí)要慎重莹桅!
使用foreachPartitions替代foreach
原理類似于“使用mapPartitions替代map”昌执,也是一次函數(shù)調(diào)用處理一個(gè)partition的所有數(shù)據(jù),而不是一次函數(shù)調(diào)用處理一條數(shù)據(jù)懂拾。在實(shí)踐中發(fā)現(xiàn)煤禽,foreachPartitions類的算子岖赋,對(duì)性能的提升還是很有幫助的。比如在foreach函數(shù)中唐断,將RDD中所有數(shù)據(jù)寫MySQL选脊,那么如果是普通的foreach算子脸甘,就會(huì)一條數(shù)據(jù)一條數(shù)據(jù)地寫恳啥,每次函數(shù)調(diào)用可能就會(huì)創(chuàng)建一個(gè)數(shù)據(jù)庫(kù)連接丹诀,此時(shí)就勢(shì)必會(huì)頻繁地創(chuàng)建和銷毀數(shù)據(jù)庫(kù)連接角寸,性能是非常低下忿墅;但是如果用foreachPartitions算子一次性處理一個(gè)partition的數(shù)據(jù),那么對(duì)于每個(gè)partition疚脐,只要?jiǎng)?chuàng)建一個(gè)數(shù)據(jù)庫(kù)連接即可亿柑,然后執(zhí)行批量插入操作棍弄,此時(shí)性能是比較高的。實(shí)踐中發(fā)現(xiàn)呼畸,對(duì)于1萬(wàn)條左右的數(shù)據(jù)量寫MySQL痕支,性能可以提升30%以上蛮原。
使用filter之后進(jìn)行coalesce操作
通常對(duì)一個(gè)RDD執(zhí)行filter算子過(guò)濾掉RDD中較多數(shù)據(jù)后(比如30%以上的數(shù)據(jù))卧须,建議使用coalesce算子儒陨,手動(dòng)減少RDD的partition數(shù)量花嘶,將RDD中的數(shù)據(jù)壓縮到更少的partition中去蹦漠。因?yàn)閒ilter之后椭员,RDD的每個(gè)partition中都會(huì)有很多數(shù)據(jù)被過(guò)濾掉笛园,此時(shí)如果照常進(jìn)行后續(xù)的計(jì)算侍芝,其實(shí)每個(gè)task處理的partition中的數(shù)據(jù)量并不是很多,有一點(diǎn)資源浪費(fèi)埋同,而且此時(shí)處理的task越多,可能速度反而越慢莺禁。因此用coalesce減少partition數(shù)量窄赋,將RDD中的數(shù)據(jù)壓縮到更少的partition之后哟冬,只要使用更少的task即可處理完所有的partition忆绰。在某些場(chǎng)景下浩峡,對(duì)于性能的提升會(huì)有一定的幫助错敢。
使用repartitionAndSortWithinPartitions替代repartition與sort類操作
repartitionAndSortWithinPartitions是Spark官網(wǎng)推薦的一個(gè)算子翰灾,官方建議稚茅,如果需要在repartition重分區(qū)之后纸淮,還要進(jìn)行排序亚享,建議直接使用repartitionAndSortWithinPartitions算子。因?yàn)樵撍阕涌梢砸贿呥M(jìn)行重分區(qū)的shuffle操作欺税,一邊進(jìn)行排序侈沪。shuffle與sort兩個(gè)操作同時(shí)進(jìn)行晚凿,比先shuffle再sort來(lái)說(shuō)亭罪,性能可能是要高的歼秽。
2.8 原則七:廣播大變量
有時(shí)在開發(fā)過(guò)程中应役,會(huì)遇到需要在算子函數(shù)中使用外部變量的場(chǎng)景(尤其是大變量燥筷,比如100M以上的大集合),那么此時(shí)就應(yīng)該使用Spark的廣播(Broadcast)功能來(lái)提升性能荆责。
在算子函數(shù)中使用到外部變量時(shí)滥比,默認(rèn)情況下做院,Spark會(huì)將該變量復(fù)制多個(gè)副本盲泛,通過(guò)網(wǎng)絡(luò)傳輸?shù)絫ask中,此時(shí)每個(gè)task都有一個(gè)變量副本寺滚。如果變量本身比較大的話(比如100M,甚至1G)村视,那么大量的變量副本在網(wǎng)絡(luò)中傳輸?shù)男阅荛_銷,以及在各個(gè)節(jié)點(diǎn)的Executor中占用過(guò)多內(nèi)存導(dǎo)致的頻繁GC蚁孔,都會(huì)極大地影響性能奶赔。
因此對(duì)于上述情況杠氢,如果使用的外部變量比較大站刑,建議使用Spark的廣播功能鼻百,對(duì)該變量進(jìn)行廣播绞旅。廣播后的變量温艇,會(huì)保證每個(gè)Executor的內(nèi)存中,只駐留一份變量副本勺爱,而Executor中的task執(zhí)行時(shí)共享該Executor中的那份變量副本晃琳。這樣的話,可以大大減少變量副本的數(shù)量邻寿,從而減少網(wǎng)絡(luò)傳輸?shù)男阅荛_銷蝎土,并減少對(duì)Executor內(nèi)存的占用開銷,降低GC的頻率绣否。
廣播大變量的代碼示例
//以下代碼在算子函數(shù)中誊涯,使用了外部的變量。
//此時(shí)沒(méi)有做任何特殊操作蒜撮,每個(gè)task都會(huì)有一份list1的副本暴构。
val list1 = ...
rdd1.map(list1...)
//以下代碼將list1封裝成了Broadcast類型的廣播變量。
//在算子函數(shù)中段磨,使用廣播變量時(shí)取逾,首先會(huì)判斷當(dāng)前task所在Executor內(nèi)存中苹支,是否有變量副本砾隅。
//如果有則直接使用债蜜;如果沒(méi)有則從Driver或者其他Executor節(jié)點(diǎn)上遠(yuǎn)程拉取一份放到本地Executor內(nèi)存中晴埂。
//每個(gè)Executor內(nèi)存中,就只會(huì)駐留一份廣播變量副本儒洛。
val list1 = ...
val list1Broadcast = sc.broadcast(list1)
rdd1.map(list1Broadcast...)
2.9 原則八:使用Kryo優(yōu)化序列化性能
在Spark中,主要有三個(gè)地方涉及到了序列化:
- 在算子函數(shù)中使用到外部變量時(shí)琅锻,該變量會(huì)被序列化后進(jìn)行網(wǎng)絡(luò)傳輸(見“原則七:廣播大變量”中的講解)。
- 將自定義的類型作為RDD的泛型類型時(shí)(比如JavaRDD恼蓬,Student是自定義類型)惊完,所有自定義類型對(duì)象滚秩,都會(huì)進(jìn)行序列化专执。因此這種情況下郁油,也要求自定義的類必須實(shí)現(xiàn)Serializable接口。
- 使用可序列化的持久化策略時(shí)(比如MEMORY_ONLY_SER)桐腌,Spark會(huì)將RDD中的每個(gè)partition都序列化成一個(gè)大的字節(jié)數(shù)組。
對(duì)于這三種出現(xiàn)序列化的地方苟径,我們都可以通過(guò)使用Kryo序列化類庫(kù),來(lái)優(yōu)化序列化和反序列化的性能棘街。Spark默認(rèn)使用的是Java的序列化機(jī)制,也就是ObjectOutputStream/ObjectInputStream API來(lái)進(jìn)行序列化和反序列化遭殉。但是Spark同時(shí)支持使用Kryo序列化庫(kù),Kryo序列化類庫(kù)的性能比Java序列化類庫(kù)的性能要高很多险污。官方介紹痹愚,Kryo序列化機(jī)制比Java序列化機(jī)制蛔糯,性能高10倍左右拯腮。Spark之所以默認(rèn)沒(méi)有使用Kryo作為序列化類庫(kù)蚁飒,是因?yàn)镵ryo要求最好要注冊(cè)所有需要進(jìn)行序列化的自定義類型动壤,因此對(duì)于開發(fā)者來(lái)說(shuō)淮逻,這種方式比較麻煩蜒灰。
以下是使用Kryo的代碼示例,我們只要設(shè)置序列化類肩碟,再注冊(cè)要序列化的自定義類型即可(比如算子函數(shù)中使用到的外部變量類型、作為RDD泛型類型的自定義類型等):
//創(chuàng)建SparkConf對(duì)象削祈。
val conf = new SparkConf().setMaster(...).setAppName(...)
//設(shè)置序列化器為KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//注冊(cè)要序列化的自定義類型髓抑。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
2.10 原則九:優(yōu)化數(shù)據(jù)結(jié)構(gòu)
Java中,有三種類型比較耗費(fèi)內(nèi)存:
- 對(duì)象吨拍,每個(gè)Java對(duì)象都有對(duì)象頭褪猛、引用等額外的信息羹饰,因此比較占用內(nèi)存空間伊滋。
- 字符串队秩,每個(gè)字符串內(nèi)部都有一個(gè)字符數(shù)組以及長(zhǎng)度等額外信息笑旺。
- 集合類型馍资,比如HashMap筒主、LinkedList等鸟蟹,因?yàn)榧项愋蛢?nèi)部通常會(huì)使用一些內(nèi)部類來(lái)封裝集合元素乌妙,比如Map.Entry建钥。
因此Spark官方建議藤韵,在Spark編碼實(shí)現(xiàn)中锦针,特別是對(duì)于算子函數(shù)中的代碼荠察,盡量不要使用上述三種數(shù)據(jù)結(jié)構(gòu)奈搜,盡量使用字符串替代對(duì)象,使用原始類型(比如Int馋吗、Long)替代字符串焕盟,使用數(shù)組替代集合類型,這樣盡可能地減少內(nèi)存占用脚翘,從而降低GC頻率,提升性能来农。
但是在筆者的編碼實(shí)踐中發(fā)現(xiàn)鞋真,要做到該原則其實(shí)并不容易沃于。因?yàn)槲覀兺瑫r(shí)要考慮到代碼的可維護(hù)性,如果一個(gè)代碼中繁莹,完全沒(méi)有任何對(duì)象抽象檩互,全部是字符串拼接的方式咨演,那么對(duì)于后續(xù)的代碼維護(hù)和修改闸昨,無(wú)疑是一場(chǎng)巨大的災(zāi)難薄风。同理饵较,如果所有操作都基于數(shù)組實(shí)現(xiàn)村刨,而不使用HashMap告抄、LinkedList等集合類型嵌牺,那么對(duì)于我們的編碼難度以及代碼可維護(hù)性,也是一個(gè)極大的挑戰(zhàn)逆粹。因此筆者建議,在可能以及合適的情況下僻弹,使用占用內(nèi)存較少的數(shù)據(jù)結(jié)構(gòu),但是前提是要保證代碼的可維護(hù)性他嚷。
3 資源調(diào)優(yōu)
3.1 調(diào)優(yōu)概述
在開發(fā)完Spark作業(yè)之后,就該為作業(yè)配置合適的資源了筋蓖。Spark的資源參數(shù),基本都可以在spark-submit命令中作為參數(shù)設(shè)置粘咖。很多Spark初學(xué)者,通常不知道該設(shè)置哪些必要的參數(shù)瓮下,以及如何設(shè)置這些參數(shù)翰铡,最后就只能胡亂設(shè)置,甚至壓根兒不設(shè)置锭魔。資源參數(shù)設(shè)置的不合理,可能會(huì)導(dǎo)致沒(méi)有充分利用集群資源迷捧,作業(yè)運(yùn)行會(huì)極其緩慢战虏;或者設(shè)置的資源過(guò)大党涕,隊(duì)列沒(méi)有足夠的資源來(lái)提供,進(jìn)而導(dǎo)致各種異常膛堤∈秩ぃ總之肥荔,無(wú)論是哪種情況绿渣,都會(huì)導(dǎo)致Spark作業(yè)的運(yùn)行效率低下燕耿,甚至根本無(wú)法運(yùn)行中符。因此我們必須對(duì)Spark作業(yè)的資源使用原理有一個(gè)清晰的認(rèn)識(shí)誉帅,并知道在Spark作業(yè)運(yùn)行過(guò)程中淀散,有哪些資源參數(shù)是可以設(shè)置的蚜锨,以及如何設(shè)置合適的參數(shù)值档插。
3.2 Spark作業(yè)基本運(yùn)行原理
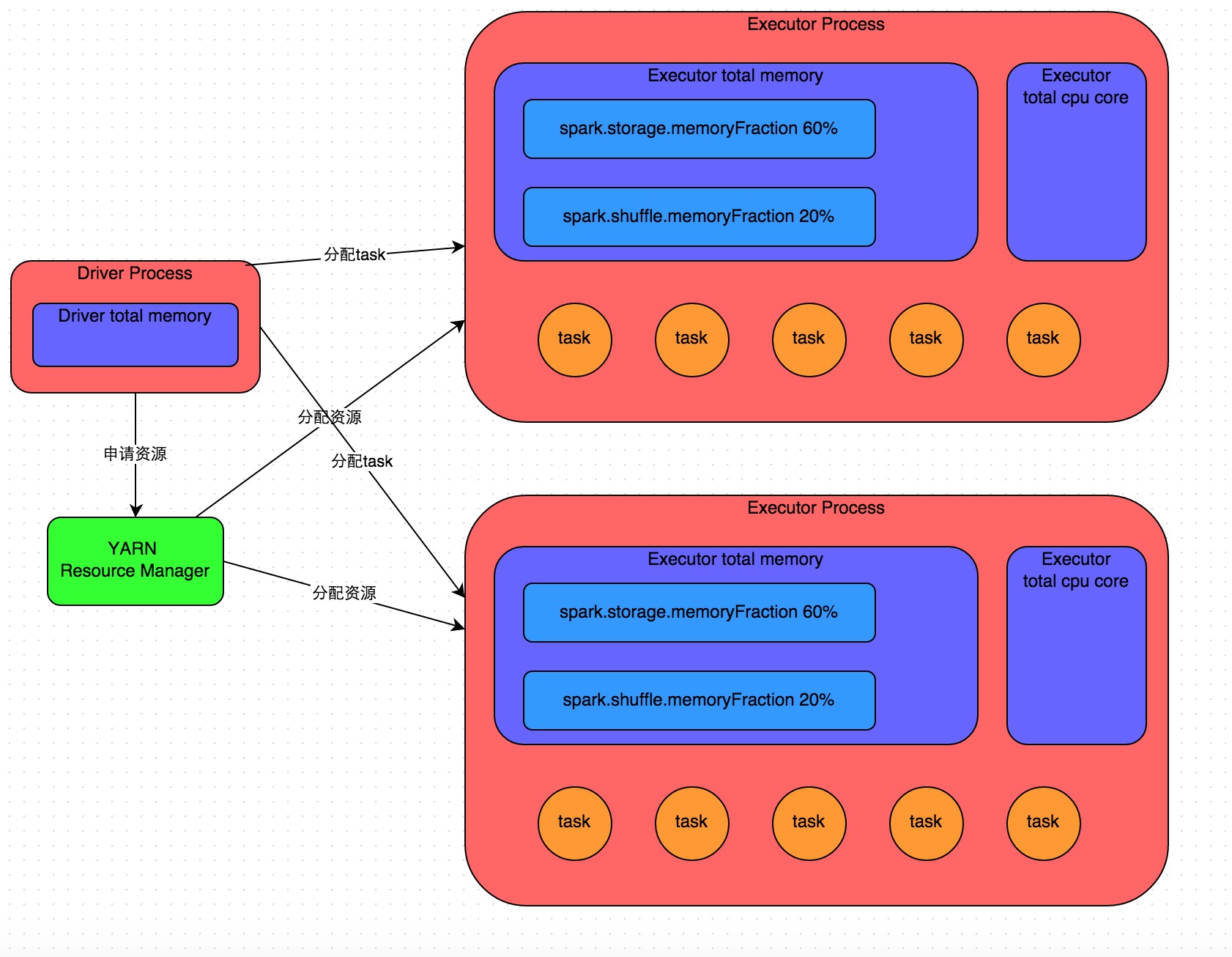
詳細(xì)原理見上圖亚再。我們使用spark-submit提交一個(gè)Spark作業(yè)之后郭膛,這個(gè)作業(yè)就會(huì)啟動(dòng)一個(gè)對(duì)應(yīng)的Driver進(jìn)程氛悬。根據(jù)你使用的部署模式(deploy-mode)不同,Driver進(jìn)程可能在本地啟動(dòng)如捅,也可能在集群中某個(gè)工作節(jié)點(diǎn)上啟動(dòng)棍现。Driver進(jìn)程本身會(huì)根據(jù)我們?cè)O(shè)置的參數(shù)伪朽,占有一定數(shù)量的內(nèi)存和CPU core轴咱。而Driver進(jìn)程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群朴肺,也可以是其他的資源管理集群,美團(tuán)?大眾點(diǎn)評(píng)使用的是YARN作為資源管理集群)申請(qǐng)運(yùn)行Spark作業(yè)需要使用的資源戈稿,這里的資源指的就是Executor進(jìn)程西土。YARN集群管理器會(huì)根據(jù)我們?yōu)镾park作業(yè)設(shè)置的資源參數(shù)鞍盗,在各個(gè)工作節(jié)點(diǎn)上,啟動(dòng)一定數(shù)量的Executor進(jìn)程般甲,每個(gè)Executor進(jìn)程都占有一定數(shù)量的內(nèi)存和CPU core肋乍。
在申請(qǐng)到了作業(yè)執(zhí)行所需的資源之后敷存,Driver進(jìn)程就會(huì)開始調(diào)度和執(zhí)行我們編寫的作業(yè)代碼了墓造。Driver進(jìn)程會(huì)將我們編寫的Spark作業(yè)代碼分拆為多個(gè)stage锚烦,每個(gè)stage執(zhí)行一部分代碼片段觅闽,并為每個(gè)stage創(chuàng)建一批task涮俄,然后將這些task分配到各個(gè)Executor進(jìn)程中執(zhí)行蛉拙。task是最小的計(jì)算單元彻亲,負(fù)責(zé)執(zhí)行一模一樣的計(jì)算邏輯(也就是我們自己編寫的某個(gè)代碼片段)孕锄,只是每個(gè)task處理的數(shù)據(jù)不同而已睹栖。一個(gè)stage的所有task都執(zhí)行完畢之后硫惕,會(huì)在各個(gè)節(jié)點(diǎn)本地的磁盤文件中寫入計(jì)算中間結(jié)果野来,然后Driver就會(huì)調(diào)度運(yùn)行下一個(gè)stage踪旷。下一個(gè)stage的task的輸入數(shù)據(jù)就是上一個(gè)stage輸出的中間結(jié)果曼氛。如此循環(huán)往復(fù)令野,直到將我們自己編寫的代碼邏輯全部執(zhí)行完舀患,并且計(jì)算完所有的數(shù)據(jù),得到我們想要的結(jié)果為止聊浅。
Spark是根據(jù)shuffle類算子來(lái)進(jìn)行stage的劃分。如果我們的代碼中執(zhí)行了某個(gè)shuffle類算子(比如reduceByKey、join等)旷痕,那么就會(huì)在該算子處,劃分出一個(gè)stage界限來(lái)欺抗。可以大致理解為强重,shuffle算子執(zhí)行之前的代碼會(huì)被劃分為一個(gè)stage,shuffle算子執(zhí)行以及之后的代碼會(huì)被劃分為下一個(gè)stage间景。因此一個(gè)stage剛開始執(zhí)行的時(shí)候,它的每個(gè)task可能都會(huì)從上一個(gè)stage的task所在的節(jié)點(diǎn)倘要,去通過(guò)網(wǎng)絡(luò)傳輸拉取需要自己處理的所有key秉溉,然后對(duì)拉取到的所有相同的key使用我們自己編寫的算子函數(shù)執(zhí)行聚合操作(比如reduceByKey()算子接收的函數(shù))碗誉。這個(gè)過(guò)程就是shuffle。
當(dāng)我們?cè)诖a中執(zhí)行了cache/persist等持久化操作時(shí)哮缺,根據(jù)我們選擇的持久化級(jí)別的不同弄跌,每個(gè)task計(jì)算出來(lái)的數(shù)據(jù)也會(huì)保存到Executor進(jìn)程的內(nèi)存或者所在節(jié)點(diǎn)的磁盤文件中尝苇。
因此Executor的內(nèi)存主要分為三塊:第一塊是讓task執(zhí)行我們自己編寫的代碼時(shí)使用,默認(rèn)是占Executor總內(nèi)存的20%糠溜;第二塊是讓task通過(guò)shuffle過(guò)程拉取了上一個(gè)stage的task的輸出后淳玩,進(jìn)行聚合等操作時(shí)使用非竿,默認(rèn)也是占Executor總內(nèi)存的20%蜕着;第三塊是讓RDD持久化時(shí)使用红柱,默認(rèn)占Executor總內(nèi)存的60%承匣。
task的執(zhí)行速度是跟每個(gè)Executor進(jìn)程的CPU core數(shù)量有直接關(guān)系的锤悄。一個(gè)CPU core同一時(shí)間只能執(zhí)行一個(gè)線程韧骗。而每個(gè)Executor進(jìn)程上分配到的多個(gè)task零聚,都是以每個(gè)task一條線程的方式些侍,多線程并發(fā)運(yùn)行的。如果CPU core數(shù)量比較充足政模,而且分配到的task數(shù)量比較合理,那么通常來(lái)說(shuō)览徒,可以比較快速和高效地執(zhí)行完這些task線程。
以上就是Spark作業(yè)的基本運(yùn)行原理的說(shuō)明习蓬,大家可以結(jié)合上圖來(lái)理解纽什。理解作業(yè)基本原理躲叼,是我們進(jìn)行資源參數(shù)調(diào)優(yōu)的基本前提芦缰。
3.3 資源參數(shù)調(diào)優(yōu)
了解完了Spark作業(yè)運(yùn)行的基本原理之后枫慷,對(duì)資源相關(guān)的參數(shù)就容易理解了。所謂的Spark資源參數(shù)調(diào)優(yōu)或听,其實(shí)主要就是對(duì)Spark運(yùn)行過(guò)程中各個(gè)使用資源的地方探孝,通過(guò)調(diào)節(jié)各種參數(shù)誉裆,來(lái)優(yōu)化資源使用的效率顿颅,從而提升Spark作業(yè)的執(zhí)行性能足丢。以下參數(shù)就是Spark中主要的資源參數(shù)粱腻,每個(gè)參數(shù)都對(duì)應(yīng)著作業(yè)運(yùn)行原理中的某個(gè)部分斩跌,我們同時(shí)也給出了一個(gè)調(diào)優(yōu)的參考值绍些。
num-executors
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置Spark作業(yè)總共要用多少個(gè)Executor進(jìn)程來(lái)執(zhí)行耀鸦。Driver在向YARN集群管理器申請(qǐng)資源時(shí)柬批,YARN集群管理器會(huì)盡可能按照你的設(shè)置來(lái)在集群的各個(gè)工作節(jié)點(diǎn)上揭糕,啟動(dòng)相應(yīng)數(shù)量的Executor進(jìn)程萝快。這個(gè)參數(shù)非常之重要著角,如果不設(shè)置的話,默認(rèn)只會(huì)給你啟動(dòng)少量的Executor進(jìn)程旋恼,此時(shí)你的Spark作業(yè)的運(yùn)行速度是非常慢的奄容。
- 參數(shù)調(diào)優(yōu)建議:每個(gè)Spark作業(yè)的運(yùn)行一般設(shè)置50~100個(gè)左右的Executor進(jìn)程比較合適,設(shè)置太少或太多的Executor進(jìn)程都不好昂勒。設(shè)置的太少,無(wú)法充分利用集群資源舟铜;設(shè)置的太多的話,大部分隊(duì)列可能無(wú)法給予充分的資源谆刨。
executor-memory
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置每個(gè)Executor進(jìn)程的內(nèi)存。Executor內(nèi)存的大小痊夭,很多時(shí)候直接決定了Spark作業(yè)的性能,而且跟常見的JVM OOM異常她我,也有直接的關(guān)聯(lián)虹曙。
- 參數(shù)調(diào)優(yōu)建議:每個(gè)Executor進(jìn)程的內(nèi)存設(shè)置4G8G較為合適番舆。但是這只是一個(gè)參考值酝碳,具體的設(shè)置還是得根據(jù)不同部門的資源隊(duì)列來(lái)定恨狈∈杌可以看看自己團(tuán)隊(duì)的資源隊(duì)列的最大內(nèi)存限制是多少拴事,num-executors乘以executor-memory,就代表了你的Spark作業(yè)申請(qǐng)到的總內(nèi)存量(也就是所有Executor進(jìn)程的內(nèi)存總和)刃宵,這個(gè)量是不能超過(guò)隊(duì)列的最大內(nèi)存量的衡瓶。此外牲证,如果你是跟團(tuán)隊(duì)里其他人共享這個(gè)資源隊(duì)列哮针,那么申請(qǐng)的總內(nèi)存量最好不要超過(guò)資源隊(duì)列最大總內(nèi)存的1/31/2坦袍,避免你自己的Spark作業(yè)占用了隊(duì)列所有的資源十厢,導(dǎo)致別的同學(xué)的作業(yè)無(wú)法運(yùn)行捂齐。
executor-cores
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置每個(gè)Executor進(jìn)程的CPU core數(shù)量蛮放。這個(gè)參數(shù)決定了每個(gè)Executor進(jìn)程并行執(zhí)行task線程的能力奠宜。因?yàn)槊總€(gè)CPU core同一時(shí)間只能執(zhí)行一個(gè)task線程包颁,因此每個(gè)Executor進(jìn)程的CPU core數(shù)量越多,越能夠快速地執(zhí)行完分配給自己的所有task線程娩嚼。
- 參數(shù)調(diào)優(yōu)建議:Executor的CPU core數(shù)量設(shè)置為2~4個(gè)較為合適。同樣得根據(jù)不同部門的資源隊(duì)列來(lái)定岳悟,可以看看自己的資源隊(duì)列的最大CPU core限制是多少,再依據(jù)設(shè)置的Executor數(shù)量贵少,來(lái)決定每個(gè)Executor進(jìn)程可以分配到幾個(gè)CPU core呵俏。同樣建議春瞬,如果是跟他人共享這個(gè)隊(duì)列柴信,那么num-executors * executor-cores不要超過(guò)隊(duì)列總CPU core的1/3~1/2左右比較合適宽气,也是避免影響其他同學(xué)的作業(yè)運(yùn)行随常。
driver-memory
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置Driver進(jìn)程的內(nèi)存萄涯。
- 參數(shù)調(diào)優(yōu)建議:Driver的內(nèi)存通常來(lái)說(shuō)不設(shè)置,或者設(shè)置1G左右應(yīng)該就夠了涝影。唯一需要注意的一點(diǎn)是枣察,如果需要使用collect算子將RDD的數(shù)據(jù)全部拉取到Driver上進(jìn)行處理燃逻,那么必須確保Driver的內(nèi)存足夠大序目,否則會(huì)出現(xiàn)OOM內(nèi)存溢出的問(wèn)題伯襟。
spark.default.parallelism
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置每個(gè)stage的默認(rèn)task數(shù)量猿涨。這個(gè)參數(shù)極為重要姆怪,如果不設(shè)置可能會(huì)直接影響你的Spark作業(yè)性能叛赚。
- 參數(shù)調(diào)優(yōu)建議:Spark作業(yè)的默認(rèn)task數(shù)量為500~1000個(gè)較為合適稽揭。很多同學(xué)常犯的一個(gè)錯(cuò)誤就是不去設(shè)置這個(gè)參數(shù)俺附,那么此時(shí)就會(huì)導(dǎo)致Spark自己根據(jù)底層HDFS的block數(shù)量來(lái)設(shè)置task的數(shù)量溪掀,默認(rèn)是一個(gè)HDFS block對(duì)應(yīng)一個(gè)task。通常來(lái)說(shuō)揪胃,Spark默認(rèn)設(shè)置的數(shù)量是偏少的(比如就幾十個(gè)task)蛮浑,如果task數(shù)量偏少的話只嚣,就會(huì)導(dǎo)致你前面設(shè)置好的Executor的參數(shù)都前功盡棄沮稚。試想一下册舞,無(wú)論你的Executor進(jìn)程有多少個(gè)蕴掏,內(nèi)存和CPU有多大调鲸,但是task只有1個(gè)或者10個(gè)盛杰,那么90%的Executor進(jìn)程可能根本就沒(méi)有task執(zhí)行藐石,也就是白白浪費(fèi)了資源!因此Spark官網(wǎng)建議的設(shè)置原則是于微,設(shè)置該參數(shù)為num-executors * executor-cores的2~3倍較為合適,比如Executor的總CPU core數(shù)量為300個(gè)株依,那么設(shè)置1000個(gè)task是可以的驱证,此時(shí)可以充分地利用Spark集群的資源恋腕。
spark.storage.memoryFraction
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置RDD持久化數(shù)據(jù)在Executor內(nèi)存中能占的比例抹锄,默認(rèn)是0.6荠藤。也就是說(shuō)伙单,默認(rèn)Executor 60%的內(nèi)存哈肖,可以用來(lái)保存持久化的RDD數(shù)據(jù)。根據(jù)你選擇的不同的持久化策略牡彻,如果內(nèi)存不夠時(shí)扫沼,可能數(shù)據(jù)就不會(huì)持久化庄吼,或者數(shù)據(jù)會(huì)寫入磁盤缎除。
- 參數(shù)調(diào)優(yōu)建議:如果Spark作業(yè)中总寻,有較多的RDD持久化操作器罐,該參數(shù)的值可以適當(dāng)提高一些渐行,保證持久化的數(shù)據(jù)能夠容納在內(nèi)存中轰坊。避免內(nèi)存不夠緩存所有的數(shù)據(jù),導(dǎo)致數(shù)據(jù)只能寫入磁盤中肴沫,降低了性能。但是如果Spark作業(yè)中的shuffle類操作比較多颤芬,而持久化操作比較少,那么這個(gè)參數(shù)的值適當(dāng)降低一些比較合適站蝠。此外汰具,如果發(fā)現(xiàn)作業(yè)由于頻繁的gc導(dǎo)致運(yùn)行緩慢(通過(guò)spark web ui可以觀察到作業(yè)的gc耗時(shí))菱魔,意味著task執(zhí)行用戶代碼的內(nèi)存不夠用留荔,那么同樣建議調(diào)低這個(gè)參數(shù)的值澜倦。
spark.shuffle.memoryFraction
- 參數(shù)說(shuō)明:該參數(shù)用于設(shè)置shuffle過(guò)程中一個(gè)task拉取到上個(gè)stage的task的輸出后,進(jìn)行聚合操作時(shí)能夠使用的Executor內(nèi)存的比例肥隆,默認(rèn)是0.2既荚。也就是說(shuō)栋艳,Executor默認(rèn)只有20%的內(nèi)存用來(lái)進(jìn)行該操作恰聘。shuffle操作在進(jìn)行聚合時(shí)吸占,如果發(fā)現(xiàn)使用的內(nèi)存超出了這個(gè)20%的限制晴叨,那么多余的數(shù)據(jù)就會(huì)溢寫到磁盤文件中去矾屯,此時(shí)就會(huì)極大地降低性能兼蕊。
- 參數(shù)調(diào)優(yōu)建議:如果Spark作業(yè)中的RDD持久化操作較少件蚕,shuffle操作較多時(shí)孙技,建議降低持久化操作的內(nèi)存占比排作,提高shuffle操作的內(nèi)存占比比例牵啦,避免shuffle過(guò)程中數(shù)據(jù)過(guò)多時(shí)內(nèi)存不夠用妄痪,必須溢寫到磁盤上哈雏,降低了性能。此外裳瘪,如果發(fā)現(xiàn)作業(yè)由于頻繁的gc導(dǎo)致運(yùn)行緩慢,意味著task執(zhí)行用戶代碼的內(nèi)存不夠用彭羹,那么同樣建議調(diào)低這個(gè)參數(shù)的值。
資源參數(shù)的調(diào)優(yōu)皆怕,沒(méi)有一個(gè)固定的值毅舆,需要同學(xué)們根據(jù)自己的實(shí)際情況(包括Spark作業(yè)中的shuffle操作數(shù)量愈腾、RDD持久化操作數(shù)量以及spark web ui中顯示的作業(yè)gc情況),同時(shí)參考本篇文章中給出的原理以及調(diào)優(yōu)建議虱黄,合理地設(shè)置上述參數(shù)。
