[TOC]
1. R自帶函數(shù)
1.1 轉(zhuǎn)置
使用函數(shù)t()可對(duì)一個(gè)矩陣或數(shù)據(jù)框進(jìn)行轉(zhuǎn)置终息,對(duì)于數(shù)據(jù)框扮饶,行名將變成變量(列)名具练。
cars <- mtcars(1:5,1:4)
cars
t(cars)
數(shù)列array進(jìn)行維度轉(zhuǎn)換 aperm
x <- array(1:24, 2:4)
xt <- aperm(x, c(2,1,3))
dim(x)
dim(xt)
1.2 整合數(shù)據(jù)aggregate
在R中使用一個(gè)或多個(gè)by變量和一個(gè)預(yù)先定義好的函數(shù)來(lái)折疊(collapse)數(shù)據(jù)。調(diào)用格式為:
aggregate(x,by,FUN)
其中x是待折疊的數(shù)據(jù)對(duì)象甜无,by飾一個(gè)變量名組成的列表扛点,這些變量將被去掉以新的觀測(cè),而FUN則是用來(lái)計(jì)算表述性統(tǒng)計(jì)量的標(biāo)量函數(shù)毫蚓,它將被用來(lái)計(jì)算新觀測(cè)中的值占键。
options(digits=2)
attach(mtcars)
mydata <- aggregate(mtcars, by=list(cyl,gear), FUN=mean, na.rm=TRUE)
mydata
by中的變量必須在一個(gè)列表中(即使只有一個(gè)變量)。也可以在列表中為各組聲明自定義的名稱元潘,例如by=list(Group.cyl=cyl,Group.gears=gear)畔乙。
## example with character variables and NAs
testDF <- data.frame(v1 = c(1,3,5,7,8,3,5,NA,4,5,7,9),
v2 = c(11,33,55,77,88,33,55,NA,44,55,77,99) )
by1 <- c("red", "blue", 1, 2, NA, "big", 1, 2, "red", 1, NA, 12)
by2 <- c("wet", "dry", 99, 95, NA, "damp", 95, 99, "red", 99, NA, NA)
aggregate(x = testDF, by = list(by1, by2), FUN = "mean")
# and if you want to treat NAs as a group
fby1 <- factor(by1, exclude = "")
fby2 <- factor(by2, exclude = "")
aggregate(x = testDF, by = list(fby1, fby2), FUN = "mean")
## Formulas, one ~ one, one ~ many, many ~ one, and many ~ many:
aggregate(weight ~ feed, data = chickwts, mean)
aggregate(breaks ~ wool + tension, data = warpbreaks, mean)
aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, mean)
aggregate(cbind(ncases, ncontrols) ~ alcgp + tobgp, data = esoph, sum)
## Dot notation:
aggregate(. ~ Species, data = iris, mean)
aggregate(len ~ ., data = ToothGrowth, mean)
## Often followed by xtabs():
ag <- aggregate(len ~ ., data = ToothGrowth, mean)
xtabs(len ~ ., data = ag)
## Compute the average annual approval ratings for American presidents.
aggregate(presidents, nfrequency = 1, FUN = mean)
## Give the summer less weight.
aggregate(presidents, nfrequency = 1,
FUN = weighted.mean, w = c(1, 1, 0.5, 1))
1.3 apply
待整理
1.4 union和intersect
x <- c(sort(sample(1:20, 9)), NA)
y <- c(sort(sample(3:23, 7)), NA)
union(x, y)
intersect(x, y)
setdiff(x, y)
setdiff(y, x)
setequal(x, y)
#%in%
(1:10) %in% c(3,7,12)
"%w/o%" <- function(x, y) x[!x %in% y]
(1:10) %w/o% c(3,7,12)
sstr <- c("c","ab","B","bba","c",NA,"@","bla","a","Ba","%")
sstr %in% c(letters, LETTERS)
1.5 合并 cbind和rbind
縱向合并數(shù)據(jù)通常用于向數(shù)據(jù)框中添加觀測(cè)。
- rbind() :縱向合并兩個(gè)數(shù)據(jù)框(數(shù)據(jù)集)
- cbind() :橫向合并兩個(gè)數(shù)據(jù)框(數(shù)據(jù)集)
注:兩個(gè)數(shù)據(jù)框行(列)數(shù)必須相同翩概。如果x中擁有y中沒有的變量牲距,在合并它們之前需做以下處理:
(1)刪除dataframeA中的多余變量;
(2)在dataframeB中創(chuàng)建追加的變量并將其值設(shè)為NA(缺失)钥庇。
x1 <- c(1:5)
x2 <- c(21:25)
x3 <- c(31:35)
r1 <- cbind(x1, x2)
r2 <- rbind(x1, x2)
r31 <- cbind(r1, x3)
r32 <- rbind(r2, x3)
1.6 匹配合并 merge
merge效果同dplyr的join牍鞠,join的效力更高。
- inner_join 等價(jià)于 merge(all=F)
- left_join 等價(jià)于 merge(all.x=T, all.y=F)
- right_join 等價(jià)于 merge(all.x=F, all.y=T)
- full_join 等價(jià)于 merge(all=T)
#authors和books
authors <- data.frame(
surname = I(c("Tukey", "Venables", "Tierney", "Ripley", "McNeil")),
nationality = c("US", "Australia", "US", "UK", "Australia"),
deceased = c("yes", rep("no", 4)))
books <- data.frame(
name = I(c("Tukey", "Venables", "Tierney",
"Ripley", "Ripley", "McNeil", "R Core")),
title = c("Exploratory Data Analysis",
"Modern Applied Statistics ...",
"LISP-STAT",
"Spatial Statistics", "Stochastic Simulation",
"Interactive Data Analysis",
"An Introduction to R"),
other.author = c(NA, "Ripley", NA, NA, NA, NA,
"Venables & Smith"))
m1 <- merge(authors, books, by.x = "surname", by.y = "name")
m2 <- merge(books, authors, by.x = "name", by.y = "surname")
#m1和m2結(jié)果相同评姨,只是結(jié)果的列名不同难述。
#left_join
m3 <- merge(authors, books, by.x = "surname", by.y = "name", all.x = T, all.y = F)
#right_join
m4 <- merge(authors, books, by.x = "surname", by.y = "name", all.x = F, all.y = T)
#full_join
m5 <- merge(authors, books, by.x = "surname", by.y = "name", all = TRUE)
m11 <- inner_join(authors, books, by=c("surname"="name"))
m22 <- inner_join(books, authors, by=c("name"="surname"))
m33 <- left_join(authors, books, by=c("surname"="name"))
m44 <- right_join(authors, books, by=c("surname"="name"))
m55 <- full_join(authors, books, by=c("surname"="name"))
1.7 排除重復(fù)數(shù)據(jù) unique
unique 函數(shù)可以去掉向量、數(shù)據(jù)框或類似數(shù)列的數(shù)據(jù)中重復(fù)的元素吐句。
x <- c(9:20, 1:5, 3:7, 0:8)
y <- unique(x)
#下列方式業(yè)可以胁后,但unique方式效率更高.
#duplicated 函數(shù)返回了元素是否重復(fù)的邏輯值.
y1 <- x[!duplicated(x)]
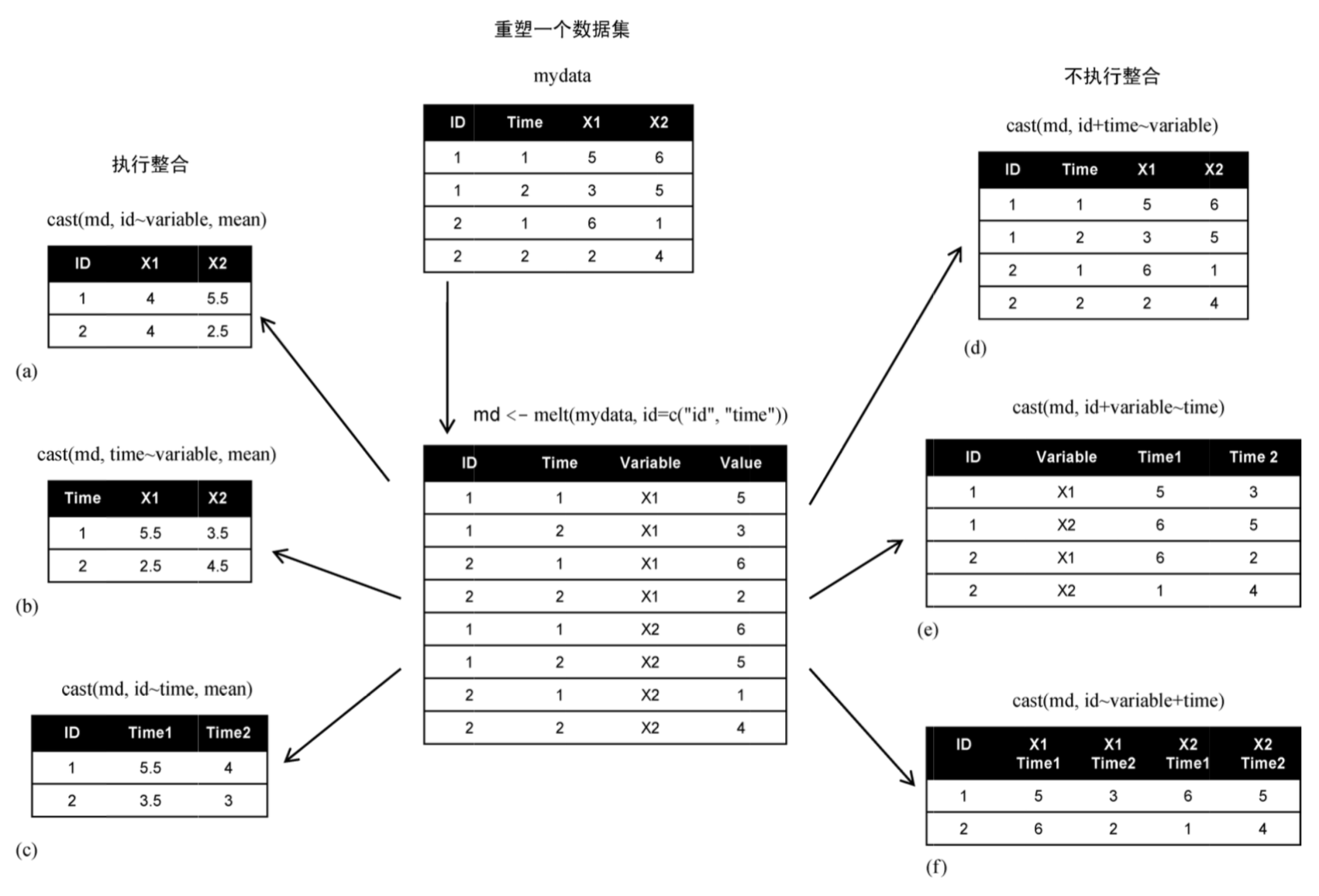
2. reshape2包
首先將數(shù)據(jù)“融合”(melt),以使每一行都是一個(gè)唯一的標(biāo)識(shí)符-變量組合嗦枢。
然后將數(shù)據(jù)“重鑄”(cast)攀芯,可以使用任何函數(shù)對(duì)數(shù)據(jù)進(jìn)行整合成想要的任何形狀。
注:reshape包的重鑄函數(shù)為cast()文虏,reshape2包的重鑄函數(shù)為dcast()和acast()
#數(shù)據(jù)集mydata
ID <- c(1,1,2,2)
Time <- c(1,2,1,2)
X1 <- c(5,3,6,2)
X2 <- c(6,5,1,4)
mydata <- data.frame(ID,Time,X1,X2)
2.1融合-melt
數(shù)據(jù)集的融合是將它重構(gòu)為這樣一種格式:每個(gè)測(cè)量變量獨(dú)占一行侣诺,行中帶有要唯一確定這個(gè)測(cè)量所需的標(biāo)識(shí)符變量。
library(reshape2)
md <- melt(mydata, id=c("ID","Time"))
md <- melt(mydata, id=1:2)
2.2重鑄-dcast和acast
Use acast or dcast depending on whether you want vector/matrix/array output or data frame output. Data frames can have at most two dimensions.
dcast——返回的結(jié)果是一個(gè)數(shù)據(jù)框
acast——返回的結(jié)果可以是向量氧秘、矩陣或者數(shù)組
調(diào)用格式為:
newdata <- dcast(data, formula, fun.aggregate = NULL, ...,
margins = NULL, subset = NULL, fill = NULL, drop = TRUE,
value.var = guess_value(data))
newdata <- acast(data, formula, fun.aggregate = NULL, ...,
margins = NULL, subset = NULL, fill = NULL, drop = TRUE,
value.var = guess_value(data))
其中md為已融合的數(shù)據(jù)年鸳,formula描述想要的結(jié)果,FUN是(可選的)數(shù)據(jù)整合函數(shù)丸相。
接受的公式形如:
rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
在這個(gè)公式中搔确,*rowvar1 + rowvar2 + ... 定義了要?jiǎng)澋舻淖兞考希源_定各行的內(nèi)容,而colvar1 + colvar2 + ... *則定義了要?jiǎng)澋舻耐谆⒋_定各列內(nèi)容的變量集合滥酥。
#執(zhí)行整合
acast(md, ID~variable, mean)
dcast(md, ID~variable, mean)
dcast(md, tTime~variable, mean)
dcast(md, ID~Time, mean)
#不執(zhí)行整合
dcast(md, ID+Time~variable)
dcast(md, ID+variable~Time)
dcast(md, ID~variable+Time)
2.3 練習(xí)
library(reshape2)
head(airquality)
mydata <- airquality
mydata1 <- melt(mydata, id=c("Month", "Day"),
variable.name = "type",value.name = "val")
#選定測(cè)量變量為Ozone、Wind
mydata2 <- melt(mydata, id=c("Month", "Day"),
measure = c("Ozone","Wind"),
variable.name = "type",value.name = "val")
str(mydata1)
str(mydata2)
#大寫轉(zhuǎn)換為小寫
names(mydata) <- tolower(names(mydata))
a <- melt(mydata, id=c("month", "day"), na.rm=TRUE)
#數(shù)據(jù)b和原始數(shù)據(jù)airquality一樣畦幢,數(shù)據(jù)復(fù)原了坎吻。
b <- dcast(a , month + day ~variable)
result1 <- dcast(a , month ~variable ,mean)
#查看缺失值數(shù)量的函數(shù)
myfun <- function(x){return(sum(is.na(x)))}
result2 <- dcast(a, month ~variable ,myfun)
result3 <- melt(mydata, id=c("month", "day"))
result4 <- dcast(result3 , month ~variable ,myfun)
result5 <- recast(mydata , month ~ variable ,
id.var = c('month','day') , fun = myfun)
3. dplyr
3.1 基本操作
3.1.1 數(shù)據(jù)類型
將過長(zhǎng)過大的數(shù)據(jù)集轉(zhuǎn)換為顯示更友好的 tbl_df 類型
library(dplyr)
iris_df <- tbl_df(iris)
3.1.2 篩選filter
按給定的邏輯判斷篩選出符合要求的子數(shù)據(jù)集, 類似于 base::subset() 函數(shù)
filter(iris_df, Species == 'setosa' , Sepal.Length >=5)
filter(iris_df, Species == 'setosa' & Sepal.Length >=5)
用R自帶函數(shù)實(shí)現(xiàn):
iris_df[iris_df$Species == 'setosa' & iris_df$Sepal.Length >=5, ]
除了代碼簡(jiǎn)潔外, 還支持對(duì)同一對(duì)象的任意個(gè)條件組合, 如:
filter(iris_df, Species == 'setosa' | Sepal.Length >=5)
注意: 表示 AND 時(shí)要使用 & 而避免 &&
3.1.3 排列 arrange
arrange(iris_df, Sepal.Length, Sepal.Width)
arrange(iris_df, desc(Sepal.Length))
#這個(gè)函數(shù)和 plyr::arrange() 是一樣的, 類似于 order()
用R自帶函數(shù)實(shí)現(xiàn):
iris_df[order(iris_df$Sepal.Length, iris_df$Sepal.Width), ]
iris_df[order(desc(iris_df$Sepal.Length)), ]
3.1.4 選擇select
用列名作參數(shù)來(lái)選擇子數(shù)據(jù)集:
select(iris_df, 5, 1:2)
select(iris_df, Species, Sepal.Length, Sepal.Width)
select(iris, Species, everything())
#重命名列名
select(iris_df, Species, Length=Sepal.Length, Width=Sepal.Width)
select(iris_df, petal = starts_with("Petal"))
排除列名:
select(iris_df, -Petal.Length, -Petal.Width)
select的特殊函數(shù)
- starts_with(x, ignore.case = TRUE): names starts with x
- ends_with(x, ignore.case = TRUE): names ends in x
- contains(x, ignore.case = TRUE): selects all variables whose name contains
- matches(x, ignore.case = TRUE): selects all variables whose name matches the regular expression x
- num_range("x", 1:5, width = 2): selects all variables (numerically) from x01 to x05.
- one_of("x", "y", "z"): selects variables provided in a character vector.
- everything(): selects all variables.
select(iris_df, everything())
select(iris_df, starts_with("Petal"))
select(iris_df, ends_with("Width"))
select(iris_df, contains("etal"))
select(iris_df, matches(".t."))
#選取名稱符合指定表達(dá)式規(guī)則的列
select(iris_df, Sepal.Length:Petal.Width)
select(iris_df, Petal.Length, Petal.Width)
vars <- c("Petal.Length", "Petal.Width")
select(iris_df, one_of(vars))
df <- as.data.frame(matrix(runif(100), nrow = 10))
df <- tbl_df(df)
select(df, V4:V6)
select(df, num_range("V", 4:6))
":" 選擇連續(xù)列,contains來(lái)匹配列名
同樣類似于R自帶的subset() 函數(shù).
subset(iris,select=c(1,2))
subset(iris,select=c(3,4))
subset(iris,select=c(Petal.Length, Petal.Width))
Programming with select 存疑??
select_(iris_df, ~Petal.Length)
select_(iris_df, "Petal.Length")
select_(iris_df, lazyeval::interp(~matches(x), x = ".t."))
select_(iris_df, quote(-Petal.Length), quote(-Petal.Width))
select_(iris_df, .dots = list(quote(-Petal.Length), quote(-Petal.Width)))
3.1.5 添加新變量mutate
對(duì)已有列進(jìn)行數(shù)據(jù)運(yùn)算并添加為新列:
mtcars_df <- tbl_df(mtcars)
mutate(mtcars_df, displ_l = disp / 61.0237)
#transmute結(jié)果只有計(jì)算的字段
transmute(mtcars_df, displ_l = disp / 61.0237)
mutate_each()
對(duì)每一列運(yùn)行窗體函數(shù)宇葱。
mutate_each(iris, funs(min_rank))
plyr::mutate() 與 base::transform() 相似, 優(yōu)勢(shì)在于可以在同一語(yǔ)句中對(duì)剛增加的列進(jìn)行操作瘦真。
mutate(hflights_df,
gain = ArrDelay - DepDelay,
gain_per_hour = gain / (AirTime / 60)
)
#而同樣操作用R自帶函數(shù) transform() 的話就會(huì)報(bào)錯(cuò):
transform(hflights,
gain = ArrDelay - DepDelay,
gain_per_hour = gain / (AirTime / 60)
)
通過data.frame有可以實(shí)現(xiàn)
mtcars_df <- data.frame(mtcars_df,displ_l = mtcars_df$disp / 61.0237)
3.1.6 匯總summarise
summarise(mtcars_df, mean(disp, na.rm = TRUE), n())
summarise(group_by(mtcars_df, cyl), mean(disp), n())
summarise(group_by(mtcars_df, cyl), m = mean(disp), sd = sd(disp))
#對(duì)每?一列運(yùn)?行概述函數(shù)。
summarise_each(iris, funs(mean))
by_species <- iris %>% group_by(Species)
by_species %>% summarise_each(funs(length))
by_species %>% summarise_each(funs(mean))
by_species %>% summarise_each(funs(mean), Petal.Width)
by_species %>% summarise_each(funs(mean), matches("Width"))
count()
#計(jì)算各變量中每?一個(gè)特定值的?行數(shù)(帶權(quán)重或不帶權(quán)重)黍瞧。
count(iris, Species, wt = Sepal.Length)
count(iris, Species, mycount = n())
3.1.7 tally
mtcars %>%
group_by(cyl, vs) %>%
tally(sort = TRUE)
#與下列方式相同
mtcars %>%
group_by(cyl, vs) %>%
summarise(n = n()) %>%
arrange(cyl,vs,n)
3.2 分組group_by
當(dāng)對(duì)數(shù)據(jù)集通過 group_by() 添加了分組信息后,mutate(), arrange() 和 summarise() 函數(shù)會(huì)自動(dòng)對(duì)這些 tbl 類數(shù)據(jù)執(zhí)行分組操作 (R語(yǔ)言泛型函數(shù)的優(yōu)勢(shì)).
summarise(mtcars_df, mean(disp, na.rm = TRUE), n())
summarise(group_by(mtcars_df, cyl), mean(disp), n(),n_distinct(gear))
summarise(group_by(mtcars_df, cyl), m = mean(disp), sd = sd(disp))
#a mutate/rename followed by a simple group_by
group_by(mtcars_df, vsam = vs + am)
group_by(mtcars_df, vs2 = vs)
summarise(group_by(mtcars_df, cyl2=cyl), m = mean(disp), sd = sd(disp))
另: 一些匯總時(shí)的小函數(shù)
n(): 計(jì)算個(gè)數(shù)
n_distinct(x): 計(jì)算 x 中唯一值的個(gè)數(shù)
3.3 鏈?zhǔn)讲僮?管道) %>% 或 %.%
dplyr包還新引進(jìn)了一個(gè)操作符诸尽,讀成then,使用時(shí)把數(shù)據(jù)名作為開頭, 然后依次對(duì)此數(shù)據(jù)進(jìn)行多步操作印颤。比如:
mtcars %>%
group_by(cyl) %>%
summarise(total = sum(disp)) %>%
arrange(desc(total)) %>%
head(5)
(x1-x2)^2%>%sum()%>%sqrt()
按數(shù)據(jù)處理的思路寫代碼, 一步步深入, 既易寫又易讀, 接近于從左到右的自然語(yǔ)言順序您机, 對(duì)比一下用R自帶函數(shù)實(shí)現(xiàn)的.
head(arrange(summarise(group_by(mtcars, cyl), total = sum(disp)) , desc(total)), 5)
x1 <- 1:5
x2 <- 2:6
sqrt(sum((x1-x2)^2))
或者像這篇文章所用的方法:
totals <- aggregate(. ~ cyl, data=mtcars[,c("cyl","disp")], sum)
ranks <- sort.list(-totals$disp)
#ranks <- order(-totals$disp)
totals[ranks[1:5],]
文章里還表示: 通過 %>% 那段代碼比跑上面這段代碼,運(yùn)算速度提升很多倍.
至于這個(gè)新鮮的概念會(huì)不會(huì)和 ggplot2 里的 + 連接號(hào)一樣, 發(fā)揮出種種奇妙的功能呢? 還是在實(shí)際使用中多體驗(yàn)感受吧.
3.5 數(shù)據(jù)匹配合并join
- inner_join(x, y) :只包含同時(shí)出現(xiàn)在x,y表中的行
- left_join(x, y) :包含所有x中以及y中匹配的行
- semi_join(x, y) :包含x中年局,在y中有匹配的行际看,結(jié)果為x的子集
- anti_join(x, y) :包含x中,不匹配y的行矢否,結(jié)果為x的子集仲闽,與semi_join相反
- full_join(x, y) :包含所以x、y中的行
- right_join(x, y) :包含所有y中以及x中匹配的行
x <- data.frame(name = c("John", "Paul", "George", "Ringo", "Stuart", "Pete"),
instrument = c("guitar", "bass", "guitar", "drums", "bass","drums"))
y <- data.frame(name = c("John", "Paul", "George", "Ringo", "Brian"),
band = c("TRUE", "TRUE", "TRUE", "TRUE", "FALSE"))
inner_join(x, y)
left_join(x, y)
semi_join(x, y)
anti_join(x, y)
full_join(x, y)
right_join(x,y)
3.6 連接數(shù)據(jù)庫(kù)
- dplyr 可以連接數(shù)據(jù)庫(kù)
- 使用與本地?cái)?shù)據(jù)框操作一樣的語(yǔ)法
- 只支持生成SELECT語(yǔ)句
- 支持SQLite, PostgreSQL/Redshift, MySQL/MariaDB, BigQuery, MonetDB
3.7 利用窗體函數(shù)變換數(shù)據(jù)
| 函數(shù) | 說(shuō)明 |
|---|---|
| dplyr::lead | 把除第一個(gè)值以外的所有元素提前僵朗,最后一個(gè)元素為NA |
| dplyr::lag | 把除第一個(gè)值以外的所有元素延后赖欣,第一個(gè)元素為NA |
| dplyr::dense_rank | 無(wú)縫排序 |
| dplyr::min_rank | 排序。并列時(shí)验庙,其他序號(hào)順延 |
| dplyr::percent_rank | 把數(shù)據(jù)在[0,1]中充足并排列 |
| dplyr::row_number | 排序顶吮。并列時(shí),位置在前的并列數(shù)據(jù)序號(hào)在前 |
| dplyr::ntile | 把向量分為n份 |
| dplyr::between | 數(shù)據(jù)是否在a和b之間 |
| dplyr::cume_dist | 累計(jì)分布 |
| dplyr::cumal | 累計(jì)all函數(shù) |
| dplyr::cumany | 累計(jì)any函數(shù) |
| dplyr::cummean | 累計(jì)mean函數(shù) |
| cumsum | 累計(jì)sum函數(shù) |
| cummax | 累計(jì)max函數(shù) |
| cummin | 累計(jì)min函數(shù) |
| cumprod | 累計(jì)prod函數(shù) |
| pmax | 針對(duì)元素的max函數(shù) |
| pmin | 針對(duì)元素的min函數(shù) |
4. tidyr
待整理
5. 字符串處理
5.1 字符個(gè)數(shù) nchar
nchar()能夠獲取字符串的長(zhǎng)度壶谒,它和length()的結(jié)果是有區(qū)別的云矫。
nchar(c("abc", "abcd")) #求字符串中的字符個(gè)數(shù)膳沽,返回向量c(3, 4)
length(c("abc", "abcd")) #返回2汗菜,向量中元素的個(gè)數(shù)
5.2 連接字符 paste
paste()不僅可以連接多個(gè)字符串,還可以將對(duì)象自動(dòng)轉(zhuǎn)換為字符串再相連挑社,另外它還能處理向量陨界,所以功能更強(qiáng)大。
paste("fitbit", month, ".jpg", sep="")
paste("fitbit", 1:12, ".jpg", sep = "")
paste默認(rèn)的分隔符是空格痛阻,必須指定sep=""菌瘪。還有一個(gè)collapse參數(shù),可以把這些字符串拼成一個(gè)長(zhǎng)字符串,而不是放在一個(gè)向量中俏扩。
paste("fitbit", 1:3, ".jpg", sep = "", collapse = "; ")
另外還有一個(gè)paste0函數(shù)糜工,默認(rèn)就是sep=""
5.3 分割字符 strsplit
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
x <- c(as = "asfef", qu = "qwerty", "yuiop[", "b", "stuff.blah.yech")
strsplit(x,"e")
#需要注意的細(xì)節(jié)
strsplit(paste(c("", "a", "")
strsplit("", " ")[[1]]
strsplit(" ", " ")[[1]]
##倒序運(yùn)用:
strReverse <- function(x)
sapply(lapply(strsplit(x, NULL), rev), paste, collapse = "")
strReverse(c("abc", "Statistics"))
5.4 提取字符 substr與substring
substr(x, start, stop)
substring(text, first, last = 1000000L)
substr(x, start, stop) <- value
substring(text, first, last = 1000000L) <- value
substr("abcdef", 2, 4)
substring("abcdef", 1:6, 1:6)
substr(rep("abcdef", 4), 1:4, 4:5)
x <- c("asfef", "qwerty", "yuiop[", "b", "stuff.blah.yech")
substr(x, 2, 5)
substring(x, 2, 4:6)
substring(x, 2) <- c("..", "+++")
5.5 替換字符 sub和gsub
- sub 只做一次替換(不管有幾次匹配)
- gsub 把滿足條件的匹配都做替換
sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
雖然sub和gsub是用于字符串替換的函數(shù),但嚴(yán)格地說(shuō)R語(yǔ)言沒有字符串替換的函數(shù)录淡,因?yàn)镽語(yǔ)言不管什么操作對(duì)參數(shù)都是傳值不傳址捌木。所以原字符串并沒有改變,要改變?cè)兞课覀冎荒芡ㄟ^再賦值的方式嫉戚。
text <- "Hello Adam!\nHello Ava!"
sub(pattern="Adam", replacement="World", text)
text
sub(pattern="Adam|Ava", replacement="World", text)
gsub(pattern="Adam|Ava", replacement="world", text)
sub和gsub函數(shù)可以使用提取表達(dá)式(轉(zhuǎn)義字符+數(shù)字)讓部分變成全部
sub(pattern=".*(Adam).*", replacement="\\1", text)
str <- "Now is the time "
sub(" +$", "", str)
sub("[[:space:]]+$", "", str)
sub("\\s+$", "", str, perl = TRUE)
txt <- "a test of capitalizing"
gsub("(\\w)(\\w*)", "\\U\\1\\L\\2", txt, perl=TRUE)
gsub("\\b(\\w)", "\\U\\1", txt, perl=TRUE)
5.6 字符查詢匹配 grep
- grep 返回匹配項(xiàng)的下標(biāo)
- grepl 返回所有查詢結(jié)果的邏輯向量
- regexpr
- gregexpr
- regexec
regexpr刨裆、gregexpr和regexec這三個(gè)函數(shù)返回的結(jié)果包含了匹配的具體位置和字符串長(zhǎng)度信息,可以用于字符串的提取操作彬檀。
x <- c("abc","abcdef","def")
grep("def", x)
#grep返回匹配項(xiàng)的下標(biāo)
#grepl返回所有查詢結(jié)果的邏輯向量帆啃。兩者的結(jié)果都可用于提取數(shù)據(jù)子集
grepl("def", x)
regexpr、gregexpr和regexec
5.5 其他
- 大小寫轉(zhuǎn)換 tolower與toupper
- 列表轉(zhuǎn)換為向量unlist
unlist(x, recursive = TRUE, use.names = TRUE) - 重復(fù)輸入rep()
rep(1:4, 2)
rep(1:4, each = 2)
rep(1:4, c(2,2,2,2))
rep(1:4, c(2,1,2,1))
rep(1:4, each = 2, len = 4)
rep(1:4, each = 2, len = 10)
rep(1:4, each = 2, times = 3)
附錄A 正則表達(dá)式
待整理
