RDD狱从、DataFrame和DataSet的區(qū)別 - 簡書
http://www.reibang.com/p/c0181667daa0
RDD改橘、DataFrame和DataSet是容易產(chǎn)生混淆的概念破花,必須對其相互之間對比谦趣,才可以知道其中異同。
RDD和DataFrame
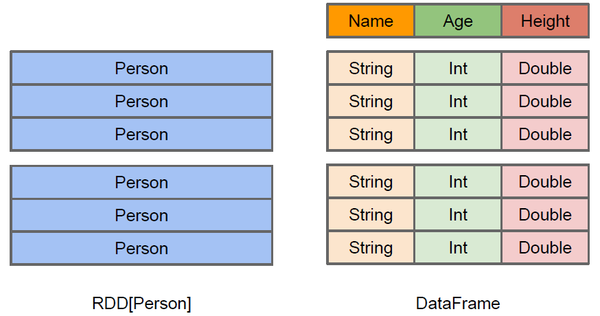
RDD-DataFrame
上圖直觀地體現(xiàn)了DataFrame和RDD的區(qū)別座每。左側(cè)的RDD[Person]雖然以Person為類型參數(shù)前鹅,但Spark框架本身不了解Person類的內(nèi)部結(jié)構(gòu)。而右側(cè)的DataFrame卻提供了詳細的結(jié)構(gòu)信息尺栖,使得Spark SQL可以清楚地知道該數(shù)據(jù)集中包含哪些列嫡纠,每列的名稱和類型各是什么。DataFrame多了數(shù)據(jù)的結(jié)構(gòu)信息延赌,即schema。RDD是分布式的Java對象的集合叉橱。DataFrame是分布式的Row對象的集合挫以。DataFrame除了提供了比RDD更豐富的算子以外,更重要的特點是提升執(zhí)行效率窃祝、減少數(shù)據(jù)讀取以及執(zhí)行計劃的優(yōu)化掐松,比如filter下推、裁剪等。
提升執(zhí)行效率
RDD API是函數(shù)式的大磺,強調(diào)不變性抡句,在大部分場景下傾向于創(chuàng)建新對象而不是修改老對象。這一特點雖然帶來了干凈整潔的API杠愧,卻也使得Spark應(yīng)用程序在運行期傾向于創(chuàng)建大量臨時對象待榔,對GC造成壓力。在現(xiàn)有RDD API的基礎(chǔ)之上流济,我們固然可以利用mapPartitions方法來重載RDD單個分片內(nèi)的數(shù)據(jù)創(chuàng)建方式锐锣,用復用可變對象的方式來減小對象分配和GC的開銷,但這犧牲了代碼的可讀性绳瘟,而且要求開發(fā)者對Spark運行時機制有一定的了解雕憔,門檻較高。另一方面糖声,Spark SQL在框架內(nèi)部已經(jīng)在各種可能的情況下盡量重用對象斤彼,這樣做雖然在內(nèi)部會打破了不變性,但在將數(shù)據(jù)返回給用戶時蘸泻,還會重新轉(zhuǎn)為不可變數(shù)據(jù)琉苇。利用 DataFrame API進行開發(fā),可以免費地享受到這些優(yōu)化效果蟋恬。
減少數(shù)據(jù)讀取
分析大數(shù)據(jù)翁潘,最快的方法就是 ——忽略它。這里的“忽略”并不是熟視無睹歼争,而是根據(jù)查詢條件進行恰當?shù)募糁Α?br>
上文討論分區(qū)表時提到的分區(qū)剪 枝便是其中一種——當查詢的過濾條件中涉及到分區(qū)列時拜马,我們可以根據(jù)查詢條件剪掉肯定不包含目標數(shù)據(jù)的分區(qū)目錄,從而減少IO沐绒。
對于一些“智能”數(shù)據(jù)格 式俩莽,Spark SQL還可以根據(jù)數(shù)據(jù)文件中附帶的統(tǒng)計信息來進行剪枝。簡單來說乔遮,在這類數(shù)據(jù)格式中扮超,數(shù)據(jù)是分段保存的,每段數(shù)據(jù)都帶有最大值蹋肮、最小值出刷、null值數(shù)量等 一些基本的統(tǒng)計信息。當統(tǒng)計信息表名某一數(shù)據(jù)段肯定不包括符合查詢條件的目標數(shù)據(jù)時坯辩,該數(shù)據(jù)段就可以直接跳過(例如某整數(shù)列a某段的最大值為100馁龟,而查詢條件要求a > 200)。
此外漆魔,Spark SQL也可以充分利用RCFile坷檩、ORC却音、Parquet等列式存儲格式的優(yōu)勢,僅掃描查詢真正涉及的列矢炼,忽略其余列的數(shù)據(jù)系瓢。
執(zhí)行優(yōu)化
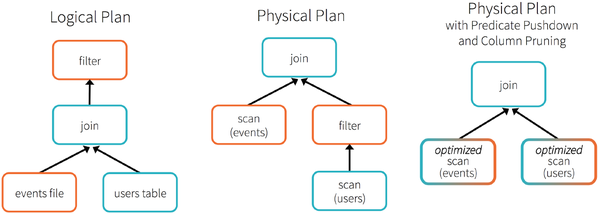
人口數(shù)據(jù)分析示例
為了說明查詢優(yōu)化,我們來看上圖展示的人口數(shù)據(jù)分析的示例句灌。圖中構(gòu)造了兩個DataFrame夷陋,將它們join之后又做了一次filter操作。如果原封不動地執(zhí)行這個執(zhí)行計劃涯塔,最終的執(zhí)行效率是不高的肌稻。因為join是一個代價較大的操作,也可能會產(chǎn)生一個較大的數(shù)據(jù)集匕荸。如果我們能將filter下推到 join下方爹谭,先對DataFrame進行過濾,再join過濾后的較小的結(jié)果集榛搔,便可以有效縮短執(zhí)行時間诺凡。而Spark SQL的查詢優(yōu)化器正是這樣做的。簡而言之践惑,邏輯查詢計劃優(yōu)化就是一個利用基于關(guān)系代數(shù)的等價變換腹泌,將高成本的操作替換為低成本操作的過程。
得到的優(yōu)化執(zhí)行計劃在轉(zhuǎn)換成物 理執(zhí)行計劃的過程中尔觉,還可以根據(jù)具體的數(shù)據(jù)源的特性將過濾條件下推至數(shù)據(jù)源內(nèi)凉袱。最右側(cè)的物理執(zhí)行計劃中Filter之所以消失不見,就是因為溶入了用于執(zhí)行最終的讀取操作的表掃描節(jié)點內(nèi)侦铜。
對于普通開發(fā)者而言专甩,查詢優(yōu)化 器的意義在于,即便是經(jīng)驗并不豐富的程序員寫出的次優(yōu)的查詢钉稍,也可以被盡量轉(zhuǎn)換為高效的形式予以執(zhí)行涤躲。
RDD和DataSet
DataSet以Catalyst邏輯執(zhí)行計劃表示,并且數(shù)據(jù)以編碼的二進制形式被存儲贡未,不需要反序列化就可以執(zhí)行sorting种樱、shuffle等操作。
DataSet創(chuàng)立需要一個顯式的Encoder俊卤,把對象序列化為二進制嫩挤,可以把對象的scheme映射為SparkSQl類型,然而RDD依賴于運行時反射機制消恍。
通過上面兩點俐镐,DataSet的性能比RDD的要好很多,可以參見[3]
DataFrame和DataSet
Dataset可以認為是DataFrame的一個特例哺哼,主要區(qū)別是Dataset每一個record存儲的是一個強類型值而不是一個Row佩抹。因此具有如下三個特點:
DataSet可以在編譯時檢查類型
并且是面向?qū)ο蟮木幊探涌凇S脀ordcount舉例:
//DataFrame// Load a text file and interpret each line as a java.lang.Stringval ds = sqlContext.read.text("/home/spark/1.6/lines").as[String]val result = ds .flatMap(.split(" ")) // Split on whitespace .filter( != "") // Filter empty words .toDF() // Convert to DataFrame to perform aggregation / sorting .groupBy($"value") // Count number of occurences of each word .agg(count("*") as "numOccurances") .orderBy($"numOccurances" desc) // Show most common words first
//DataSet,完全使用scala編程取董,不要切換到DataFrameval wordCount = ds.flatMap(.split(" ")) .filter( != "") .groupBy(_.toLowerCase()) // Instead of grouping on a column expression (i.e. $"value") we pass a lambda function .count()
后面版本DataFrame會繼承DataSet棍苹,DataFrame是面向Spark SQL的接口。
DataFrame和DataSet可以相互轉(zhuǎn)化茵汰,df.as[ElementType]
這樣可以把DataFrame轉(zhuǎn)化為DataSet枢里,ds.toDF()
這樣可以把DataSet轉(zhuǎn)化為DataFrame。
參考
[1] Spark SQL結(jié)構(gòu)化分析
[2] 解讀2015之Spark篇:新生態(tài)系統(tǒng)的形成
[3] Introducing Spark Datasets
[4] databricks example
