TensorBoard簡介
TensorFlow 的計(jì)算過程其實(shí)是一個(gè)黑盒過程,為了便于使用者對TensorFlow程序的理解幕袱,調(diào)試和優(yōu)化 ,TensorFlow 提供TensorBoard 這套組件來支持對代碼的可視化理解。TensorBoard 是一組Web應(yīng)用組件访娶;其主要的作用是用可視化的方式展示TensorFlow的計(jì)算過程和計(jì)算圖的形態(tài)矾缓;
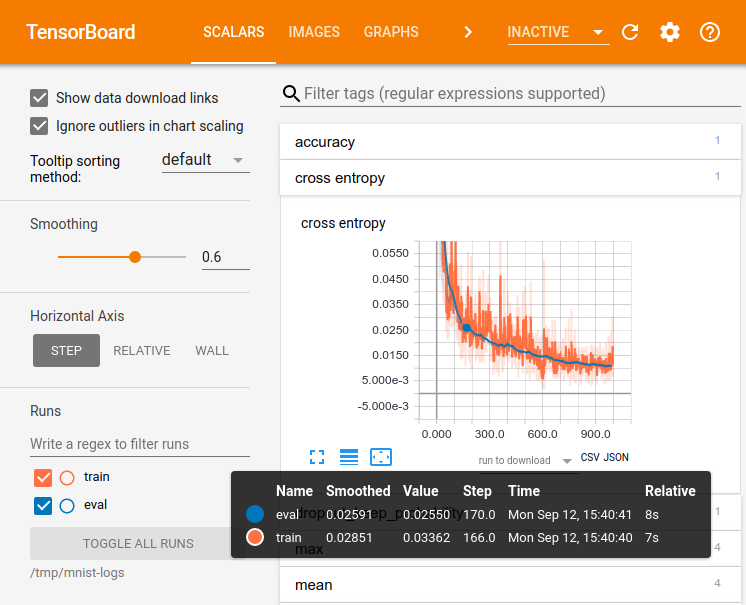
TensorBoard可視化
TensorBoard 是通過讀取TensorFlow的事件文件信息來進(jìn)行可視化的怀酷。TensorFlow的事件文件包含的是tensorflow運(yùn)行時(shí)的summary data。
Summary Operations
Summary Operation提供了這樣一些工具用來記錄computational graph的運(yùn)行信息:
下面兩個(gè)類提供了output 接口嗜闻,用來將summary信息寫到事件文件中去蜕依。
- tf.summary.FileWriter
- tf.summary.FileWriterCache
下面是一些Summary Operation
- tf.summary.tensor_summary: Outputs a Summary protocol buffer with a serialized tensor.proto
- tf.summary.scalar: Outputs a Summary protocol buffer containing a single scalar value
- tf.summary.histogram: Outputs a Summary protocol buffer with a histogram
- tf.summary.audio: Outputs a Summary protocol buffer with audio.
- tf.summary.image: Outputs a Summary protocol buffer with images.
- tf.summary.merge: This op creates a Summary protocol buffer that contains the union of all the values in the input summaries.
- tf.summary.merge_all: Merges all summaries collected in the default graph
生成summary 過程
- 首先創(chuàng)建需要進(jìn)行收集summary data 的 computational graph,并且確定需要觀察的節(jié)點(diǎn)琉雳。
例如:假設(shè)在訓(xùn)練一個(gè)cnn去識別MNIST的數(shù)字的模型中样眠, 你可能需要記錄learning rate, 損失函數(shù)值的變化過程翠肘,這時(shí)你可以給輸出learning rate的值和輸出損失函數(shù)值的節(jié)點(diǎn)分別附加一個(gè)tf.summary.scalar操作吹缔。 - 合并summary Ops:
tensorflow 中的Operation不會做任何事情,直到有人去運(yùn)行它锯茄,或者有其它的運(yùn)行的Operation依賴于它的輸出作為輸入厢塘;而我們在第一步附加給compuatiaonal graph 節(jié)點(diǎn)上的summary operation 是一種相對于目標(biāo)graph 是外圍的節(jié)點(diǎn),他們并不被依賴肌幽,所以需要我們主動的去運(yùn)行summary Operatiton晚碾;當(dāng)然一個(gè)一個(gè)手動的去運(yùn)行summary operation 顯然是很麻煩的,所以這一步需要用tf.summary.merge_all 將所有的summary operation 合并成單個(gè)operation喂急。 - 運(yùn)行合并后的summary operation:
運(yùn)行summary operation將生成序列化的Summary protobuf object, 之后將其傳給 tf.summary.FileWriter 格嘁, FileWrite 會將summary object 寫入到事件文件中去。 - 設(shè)置運(yùn)行的頻次:
在模型的訓(xùn)練過程中往往都要進(jìn)行多步迭代廊移,我們可以在圖每次計(jì)算一次時(shí)運(yùn)行summary糕簿, 但當(dāng)次數(shù)迭代較多時(shí)這就沒必要了探入,一般可以設(shè)置每訓(xùn)練多少步運(yùn)行一次summary operation。
launch Tensorboard
可以用下面兩中方式啟動tensorbord:
python -m tensorflow.tensorboard --logdir=path/to/log-directory-
tensorboard --logdir=path/to/log-directory
這里的logdir 指的是tf.summary.FileWriter 寫的事件文件的文件夾懂诗;如果logdir 文件夾含有子文件夾蜂嗽,且這個(gè)子文件夾中含有不同的事件文件,Tensorboard 也會對其進(jìn)行可視話殃恒。當(dāng)Tensorboard 啟動好后植旧,可以通過瀏覽器訪問 localhost:6006 去查看Tensorboard的可視化結(jié)果。
TensorBoard: Embedding Visualization
前面我們介紹了tensorborad的流程和用法离唐,這里我們介紹Tensorboard另外一個(gè)有用的功能病附,embedding visuaslization, 其實(shí)質(zhì)就是將高維的數(shù)據(jù)按照特定的算法映射到2維或者3維進(jìn)行展示。

TensorBoard 有一個(gè)內(nèi)置的可是話工具叫做 Embedding Projector,主要是為了方便交互式的展示和分析高維數(shù)據(jù)亥鬓, embedding projector 會讀取在模型文件中的embedings, 并且加載模型中任何2維的tensor完沪。
Embedding Projector 默認(rèn)的使用PCA將高維數(shù)據(jù),映射到3維空間嵌戈,但其也提供了t-SNE 用來做映射丽焊。
創(chuàng)建embedding
需要這么三步來可視化embeddings:
- 創(chuàng)建一個(gè)2維的tensor來記錄embedding :
embedding_var = tf.Variable(....) - 周期性的將模型變量保存在logdir 下面的checkpoint文件中
saver = tf.train.Saver()
saver.save(session, os.path.join(LOG_DIR, "model.ckpt"), step)
- (可選)對embedding 附加元數(shù)據(jù):
如果你想對embedding 的數(shù)據(jù)添加元數(shù)據(jù)(如標(biāo)簽,圖片),你可以通過在log_dir文件夾下面保存一個(gè)projector_config.pbtxt指定元數(shù)據(jù)信息咕别,或者通過python API
例如:下面的projector_config.pbtxt為word_embedding附加一個(gè)存在logdir/metadata.tsv下的元數(shù)據(jù):
embeddings {
tensor_name: 'word_embedding'
metadata_path: '$LOG_DIR/metadata.tsv'
}
元數(shù)據(jù)
通常技健,embeddings都會有附加元數(shù)據(jù), 元數(shù)據(jù)必須在模型的checkpoint 外面用一個(gè)單獨(dú)的文件保存惰拱。 元數(shù)據(jù)文件的格式是TSV格式的文件雌贱, 即用tab鍵分隔的文件,并且這個(gè)文件必須帶有文件頭偿短;
一個(gè)具體的文件內(nèi)容的例子:
Word\tFrequency
Airplane\t345
Car\t241
...
需要注意的一點(diǎn)是元文件中數(shù)據(jù)的順序必須和embedding tenor的順序一致欣孤;
圖片元數(shù)據(jù)
如果你需要將圖片數(shù)據(jù)附加到embeddings 上去,你需要將每個(gè)數(shù)據(jù)點(diǎn)代表的圖片合成一張整的圖片昔逗,這張圖片叫做sprite image降传。
生成完sprite image后,需要告訴Embedding projector 去加載文件:
embedding.sprite.image_path = PATH_TO_SPRITE_IMAGE
# Specify the width and height of a single thumbnail.
embedding.sprite.single_image_dim.extend([w, h])
Graph的可視化:
TensorFlow 的computation graphs 一般都會比較復(fù)雜. 對其進(jìn)行可視化能幫助人們理解和調(diào)試程序勾怒。
對圖進(jìn)行可視化婆排,只需運(yùn)行TensorBoard命令,并且點(diǎn)擊graph 按件就可以看到了笔链。
這里主要講的一點(diǎn)是name scoping
name scope
由于深度學(xué)習(xí)模型往往有成千上萬個(gè)節(jié)點(diǎn)段只,在有限的空間中展示這么多細(xì)節(jié)是很不友好的,tensorflow 里面有個(gè)name scope 的機(jī)制鉴扫,可以將一些variable 劃到一個(gè)scope中去赞枕, 然后在展示graph的時(shí)候,在同一個(gè)name scope 都會被折疊進(jìn)一個(gè)節(jié)點(diǎn)中去,用戶可以自己去展開炕婶。
另外name scope 也類似java的包一樣姐赡,解決了variable 命名的問題,這里就不細(xì)講了柠掂。
實(shí)戰(zhàn):基于CNN對mnist數(shù)字識別
import os
import tensorflow as tf
import sys
import urllib
if sys.version_info[0] >= 3:
from urllib.request import urlretrieve
else:
from urllib import urlretrieve
LOGDIR = '/tmp/mnist_tutorial/'
GITHUB_URL = 'https://raw.githubusercontent.com/mamcgrath/TensorBoard-TF-Dev-Summit-Tutorial/master/'
### MNIST EMBEDDINGS ###
mnist = tf.contrib.learn.datasets.mnist.read_data_sets(train_dir=LOGDIR + 'data', one_hot=True)
### Get a sprite and labels file for the embedding projector ###
urlretrieve(GITHUB_URL + 'labels_1024.tsv', LOGDIR + 'labels_1024.tsv')
urlretrieve(GITHUB_URL + 'sprite_1024.png', LOGDIR + 'sprite_1024.png')
# Add convolution layer
def conv_layer(input, size_in, size_out, name="conv"):
with tf.name_scope(name):
w = tf.Variable(tf.truncated_normal([5, 5, size_in, size_out], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[size_out]), name="B")
conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding="SAME")
act = tf.nn.relu(conv + b)
tf.summary.histogram("weights", w)
tf.summary.histogram("biases", b)
tf.summary.histogram("activations", act)
return tf.nn.max_pool(act, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# Add fully connected layer
def fc_layer(input, size_in, size_out, name="fc"):
with tf.name_scope(name):
w = tf.Variable(tf.truncated_normal([size_in, size_out], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[size_out]), name="B")
act = tf.nn.relu(tf.matmul(input, w) + b)
tf.summary.histogram("weights", w)
tf.summary.histogram("biases", b)
tf.summary.histogram("activations", act)
return act
def mnist_model(learning_rate, use_two_conv, use_two_fc, hparam):
tf.reset_default_graph()
sess = tf.Session()
# Setup placeholders, and reshape the data
x = tf.placeholder(tf.float32, shape=[None, 784], name="x")
x_image = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', x_image, 3)
y = tf.placeholder(tf.float32, shape=[None, 10], name="labels")
if use_two_conv:
conv1 = conv_layer(x_image, 1, 32, "conv1")
conv_out = conv_layer(conv1, 32, 64, "conv2")
else:
conv1 = conv_layer(x_image, 1, 64, "conv")
conv_out = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
flattened = tf.reshape(conv_out, [-1, 7 * 7 * 64])
if use_two_fc:
fc1 = fc_layer(flattened, 7 * 7 * 64, 1024, "fc1")
embedding_input = fc1
embedding_size = 1024
logits = fc_layer(fc1, 1024, 10, "fc2")
else:
embedding_input = flattened
embedding_size = 7*7*64
logits = fc_layer(flattened, 7*7*64, 10, "fc")
with tf.name_scope("xent"):
xent = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=y), name="xent")
tf.summary.scalar("xent", xent)
with tf.name_scope("train"):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(xent)
with tf.name_scope("accuracy"):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("accuracy", accuracy)
summ = tf.summary.merge_all()
embedding = tf.Variable(tf.zeros([1024, embedding_size]), name="test_embedding")
assignment = embedding.assign(embedding_input)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter(LOGDIR + hparam)
writer.add_graph(sess.graph)
config = tf.contrib.tensorboard.plugins.projector.ProjectorConfig()
embedding_config = config.embeddings.add()
embedding_config.tensor_name = embedding.name
embedding_config.sprite.image_path = LOGDIR + 'sprite_1024.png'
embedding_config.metadata_path = LOGDIR + 'labels_1024.tsv'
# Specify the width and height of a single thumbnail.
embedding_config.sprite.single_image_dim.extend([28, 28])
tf.contrib.tensorboard.plugins.projector.visualize_embeddings(writer, config)
for i in range(2001):
batch = mnist.train.next_batch(100)
if i % 5 == 0:
[train_accuracy, s] = sess.run([accuracy, summ], feed_dict={x: batch[0], y: batch[1]})
writer.add_summary(s, i)
if i % 500 == 0:
sess.run(assignment, feed_dict={x: mnist.test.images[:1024], y: mnist.test.labels[:1024]})
saver.save(sess, os.path.join(LOGDIR, "model.ckpt"), i)
sess.run(train_step, feed_dict={x: batch[0], y: batch[1]})
def make_hparam_string(learning_rate, use_two_fc, use_two_conv):
conv_param = "conv=2" if use_two_conv else "conv=1"
fc_param = "fc=2" if use_two_fc else "fc=1"
return "lr_%.0E,%s,%s" % (learning_rate, conv_param, fc_param)
def main():
# You can try adding some more learning rates
for learning_rate in [1E-4]:
# Include "False" as a value to try different model architectures
for use_two_fc in [True]:
for use_two_conv in [True]:
# Construct a hyperparameter string for each one (example: "lr_1E-3,fc=2,conv=2)
hparam = make_hparam_string(learning_rate, use_two_fc, use_two_conv)
print('Starting run for %s' % hparam)
# Actually run with the new settings
mnist_model(learning_rate, use_two_fc, use_two_conv, hparam)
if __name__ == '__main__':
main()
總結(jié)
本文主要介紹了如下內(nèi)容:
- tensorboard 是什么及其左右
- tensorboard 如何進(jìn)行可視化
- tensorboard 進(jìn)行embedding 可視化
- tensorboard 對graph進(jìn)行可視化
- 最后以一個(gè)完整的例子演示了上面所講的內(nèi)容项滑,這個(gè)例子是完整可以運(yùn)行的。
