源文件放在github严沥,如有謬誤之處,歡迎指正中姜。原文鏈接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/hash-shuffle.md
正如你所知消玄,spark實(shí)現(xiàn)了多種shuffle方法,通過(guò) spark.shuffle.manager來(lái)確定丢胚。暫時(shí)總共有三種:hash shuffle翩瓜、sort shuffle和tungsten-sort shuffle,從1.2.0開(kāi)始默認(rèn)為sort shuffle携龟。本節(jié)主要介紹hash shuffle兔跌。
spark在1.2前默認(rèn)為hash shuffle(spark.shuffle.manager = hash),但hash shuffle也經(jīng)歷了兩個(gè)發(fā)展階段峡蟋。
第一階段
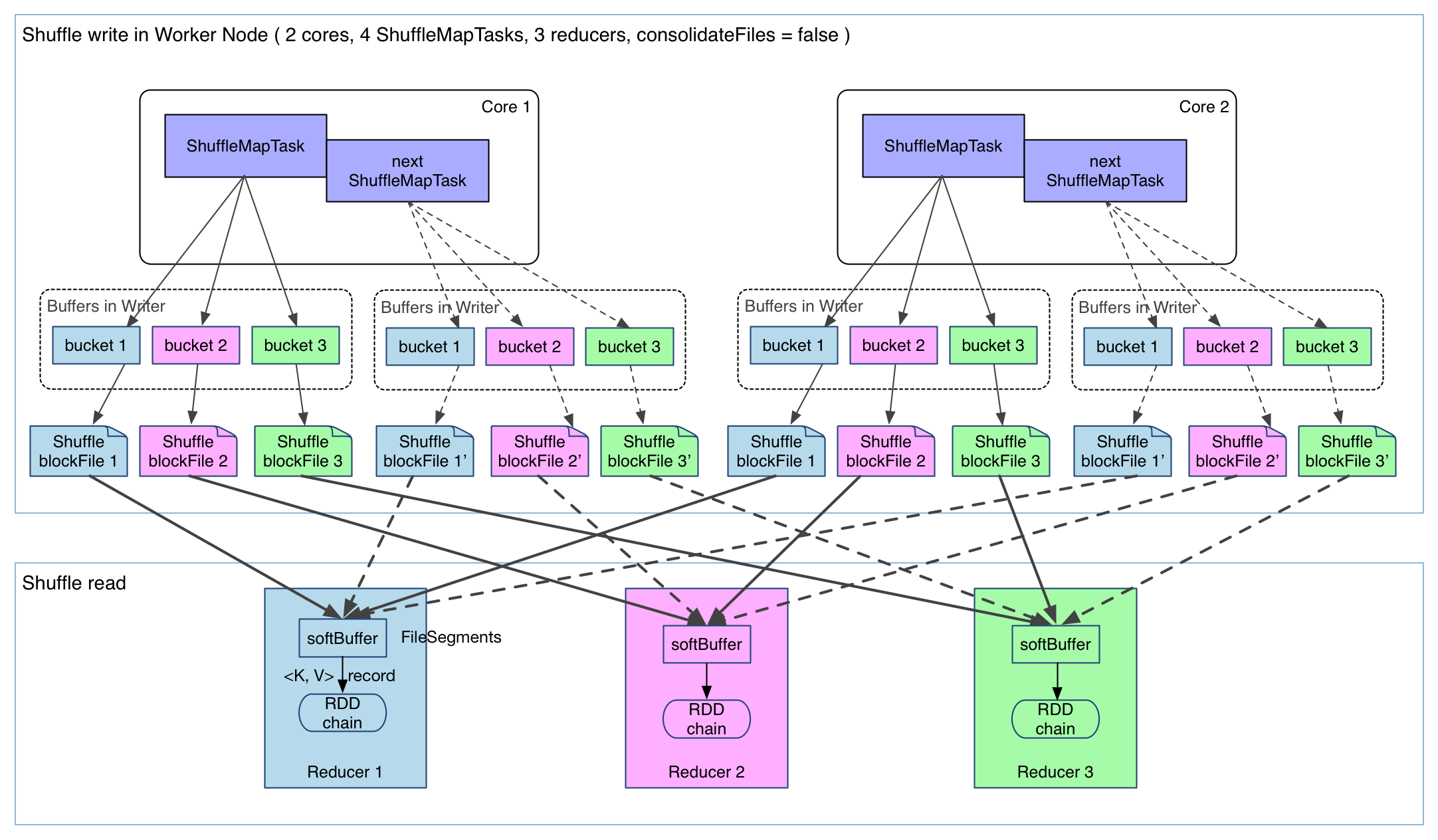
上圖有 4 個(gè) ShuffleMapTask 要在同一個(gè) worker node 上運(yùn)行坟桅,CPU core 數(shù)為 2,可以同時(shí)運(yùn)行兩個(gè) task蕊蝗。每個(gè) task 的執(zhí)行結(jié)果(該 stage 的 finalRDD 中某個(gè) partition 包含的 records)被逐一寫(xiě)到本地磁盤(pán)上仅乓。每個(gè) task 包含 R 個(gè)緩沖區(qū),R = reducer 個(gè)數(shù)(也就是下一個(gè) stage 中 task 的個(gè)數(shù))蓬戚,緩沖區(qū)被稱(chēng)為 bucket夸楣,其大小為spark.shuffle.file.buffer.kb ,默認(rèn)是 32KB(Spark 1.1 版本以前是 100KB)。
第二階段
這樣的實(shí)現(xiàn)很簡(jiǎn)單裕偿,但有幾個(gè)問(wèn)題:
1 產(chǎn)生的 FileSegment 過(guò)多洞慎。每個(gè) ShuffleMapTask 產(chǎn)生 R(reducer 個(gè)數(shù))個(gè) FileSegment,M 個(gè) ShuffleMapTask 就會(huì)產(chǎn)生 M * R 個(gè)文件嘿棘。一般 Spark job 的 M 和 R 都很大,因此磁盤(pán)上會(huì)存在大量的數(shù)據(jù)文件旭绒。
2 緩沖區(qū)占用內(nèi)存空間大鸟妙。每個(gè) ShuffleMapTask 需要開(kāi) R 個(gè) bucket,M 個(gè) ShuffleMapTask 就會(huì)產(chǎn)生 M * R 個(gè) bucket挥吵。雖然一個(gè) ShuffleMapTask 結(jié)束后重父,對(duì)應(yīng)的緩沖區(qū)可以被回收,但一個(gè) worker node 上同時(shí)存在的 bucket 個(gè)數(shù)可以達(dá)到 cores R 個(gè)(一般 worker 同時(shí)可以運(yùn)行 cores 個(gè) ShuffleMapTask)忽匈,占用的內(nèi)存空間也就達(dá)到了cores * R * 32 KB房午。對(duì)于 8 核 1000 個(gè) reducer 來(lái)說(shuō),占用內(nèi)存就是 256MB丹允。
spark.shuffle.consolidateFiles默認(rèn)為false郭厌,如果為true,shuffleMapTask輸出文件可以被合并雕蔽。如圖
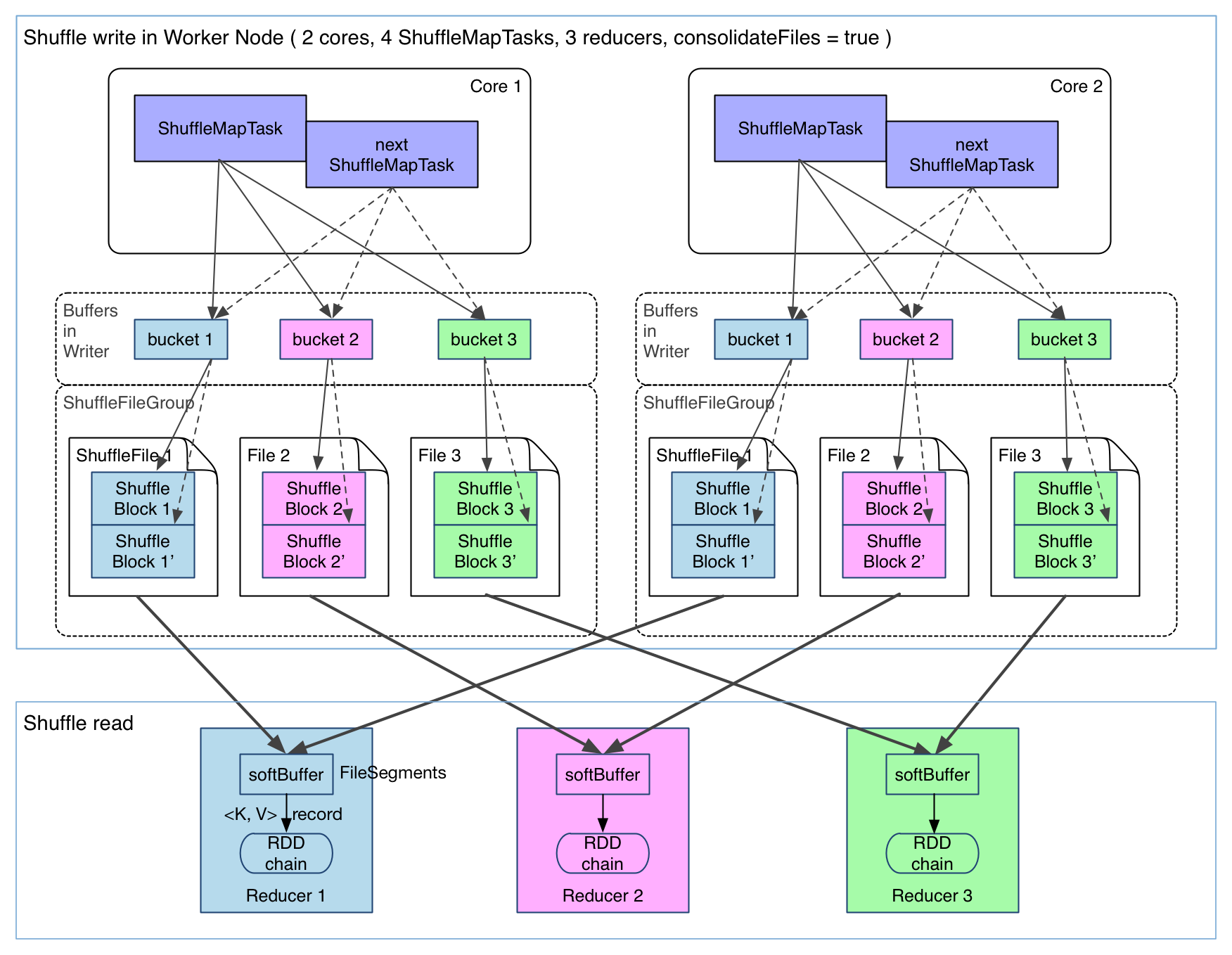
可以明顯看出折柠,在一個(gè) core 上連續(xù)執(zhí)行的 ShuffleMapTasks 可以共用一個(gè)輸出文件 ShuffleFile。先執(zhí)行完的 ShuffleMapTask 形成 ShuffleBlock i批狐,后執(zhí)行的 ShuffleMapTask 可以將輸出數(shù)據(jù)直接追加到 ShuffleBlock i 后面扇售,形成 ShuffleBlock i',每個(gè) ShuffleBlock 被稱(chēng)為 FileSegment嚣艇。下一個(gè) stage 的 reducer 只需要 fetch 整個(gè) ShuffleFile 就行了承冰。這樣,每個(gè) worker 持有的文件數(shù)降為 cores * R食零。但是緩存空間占用大還沒(méi)有解決困乒。
總結(jié)
優(yōu)點(diǎn)
- 快-不需要排序,也不需要維持hash表
- 不需要額外空間用作排序
- 不需要額外IO-數(shù)據(jù)寫(xiě)入磁盤(pán)只需一次慌洪,讀取也只需一次
缺點(diǎn)
- 當(dāng)partitions大時(shí)顶燕,輸出大量的文件(cores * R),性能開(kāi)始降低
- 大量的文件寫(xiě)入,使文件系統(tǒng)開(kāi)始變?yōu)殡S機(jī)寫(xiě)冈爹,性能比順序?qū)懸档?00倍
- 緩存空間占用比較大
當(dāng)然涌攻,數(shù)據(jù)經(jīng)過(guò)序列化、壓縮寫(xiě)入文件频伤,讀取的時(shí)候恳谎,需要反序列化、解壓縮。reduce fetch的時(shí)候有一個(gè)非常重要的參數(shù)spark.reducer.maxSizeInFlight因痛,這里用 softBuffer 表示婚苹,默認(rèn)大小為 48MB。一個(gè) softBuffer 里面一般包含多個(gè) FileSegment鸵膏,但如果某個(gè) FileSegment 特別大的話膊升,這一個(gè)就可以填滿甚至超過(guò) softBuffer 的界限。如果增大谭企,reduce請(qǐng)求的chunk就會(huì)變大廓译,可以提高性能,但是增加了reduce的內(nèi)存使用量债查。
如果排序在reduce不強(qiáng)制執(zhí)行非区,那么reduce只返回一個(gè)依賴(lài)于map的迭代器。如果需要排序盹廷, 那么在reduce端征绸,調(diào)用ExternalSorter。
