自然語言處理的難題
自然語言處理(Natural Language Processing NLP)是一門涉及到對(duì)學(xué)習(xí)舷礼,理解以及生成人類語言相關(guān)計(jì)算機(jī)技術(shù)進(jìn)行探索的技術(shù)叉弦。 NLP技術(shù)可以協(xié)助人與人之間的溝通(如機(jī)器翻譯)和人機(jī)之間的溝通(如智能助手)肠牲,并可以對(duì)網(wǎng)上大量的文本資料進(jìn)行分析并學(xué)習(xí)玲销。
然而镐捧,這個(gè)等待人們進(jìn)行深度開發(fā)的領(lǐng)域卻存在著幾個(gè)難題遭赂。
第一個(gè)難題是循诉,我們作為人類并不能夠有意識(shí)地去理解語言。
第二個(gè)難題是撇他,人類語言的歧義性茄猫。
語法與概念
計(jì)算機(jī)在處理語法(syntax)方面任務(wù)的能力非常強(qiáng),比如說困肩,計(jì)算一個(gè)單詞在一份120頁文檔中出現(xiàn)的次數(shù)划纽。但它在處理概念方面的能力就非常弱了,事實(shí)上锌畸,計(jì)算機(jī)進(jìn)程幾乎意識(shí)不到概念勇劣。而另一方面,人類的自然語言卻主要是關(guān)于概念的傳遞蹋绽,我們只是用語法作為概念的暫時(shí)載體芭毙。這就使得計(jì)算機(jī)難以處理自然語言。

所以如果能使計(jì)算機(jī)更了解概念維度的東西卸耘,那么就可以減小這方面的制約了。
到這基本上就已經(jīng)是個(gè)哲學(xué)問題了粘咖。在自然語言中蚣抗,語法是一種方法或途徑,而傳遞的概念是目的瓮下。
如果以運(yùn)輸為例的話翰铡,從A點(diǎn)運(yùn)到B點(diǎn)是目的,而之間的路則是途徑讽坏。如果人類滅亡很多年后锭魔,外星文明來到地球,當(dāng)他們看到遍地的道路時(shí)路呜,是否能只通過分析這些道路迷捧,而對(duì)當(dāng)時(shí)的運(yùn)輸有所了解呢?答案應(yīng)該是否定的胀葱!你不能夠只通過分析途徑還有方法漠秋,而完全理解傳輸?shù)牡降资鞘裁础?/p>
語言的模糊性

當(dāng)你想到一個(gè)語言概念,如單詞或句子抵屿,那些看起來像是簡單且很有道理的想法庆锦,實(shí)際上卻有很多邊界情況是難以搞清楚的 。
例如轧葛,英文里“won't”是一個(gè)詞搂抒,還是兩個(gè)詞(大多系統(tǒng)視其為兩個(gè)詞)艇搀?還有在中文或(特別是)泰語中,母語使用者會(huì)對(duì)詞語的邊界有各種不同的看法求晶。而與文本的意義相比中符,詞和句子都還算非常簡單的了。
事實(shí)上誉帅,英文中很多詞語如此淀散。如“ground”就有很多意思,可以作動(dòng)詞蚜锨,更多時(shí)候可能又是名詞档插。要理解一句話,你得先明白各個(gè)詞的含義亚再,這又不是件簡單的任務(wù)郭膛。
/Getty_syntactic_ambiguity-569743119-57a797a63df78cf459475108.jpg)
但讓人抓狂的是,對(duì)人類來說氛悬,這些東西卻極其輕松则剃。當(dāng)你瀏覽網(wǎng)頁時(shí),無論是新創(chuàng)詞語如捅,還是動(dòng)詞化的名詞或是各種諷刺手法棍现,你都能立刻理解它們,甚至想都不用想镜遣。
還有比如說雙關(guān)語這中人們用來娛樂的方式己肮,它又剛好是阻礙NLP系統(tǒng)性能的因素之一。原因是計(jì)算機(jī)的處理方式與人類完全不同悲关,所以一旦處理的文本和用于訓(xùn)練的文本相差很大時(shí)谎僻,NLP系統(tǒng)很有可能會(huì)完全混淆掉,而不是像人類理解出弦外之音寓辱。人們?cè)谖⒉┗蛘逿witter上學(xué)習(xí)各種新的交流規(guī)則時(shí)艘绍,就根本不用考慮這一點(diǎn)。
自然語言處理
如果我們真的能夠搞清楚人是怎么理解語言的話秫筏,那么也就可能讓計(jì)算機(jī)做相同的事情诱鞠。但是,因?yàn)檫@些知識(shí)都被隱藏很深跳昼,再加上人類的無意識(shí)般甲。我們往往只能采用逼近和統(tǒng)計(jì)技術(shù),而這些技術(shù)完全得依賴訓(xùn)練數(shù)據(jù)鹅颊,所以這類系統(tǒng)可能永遠(yuǎn)也不會(huì)像人類這樣靈活使用語言敷存。

事實(shí)上,自然語言處理更多是解決自然語言文本分析與生成等工程問題的學(xué)科。成功標(biāo)準(zhǔn)不在于是否設(shè)計(jì)了更好的科學(xué)理論锚烦,或是證明了X和Y語言在歷史上是相關(guān)的觅闽。相反,衡量標(biāo)準(zhǔn)是你是否在工程問題上獲得了良好的解決方案涮俄。
例如蛉拙,你不會(huì)根據(jù)谷歌翻譯有沒有用“真正正確的翻譯”,或者能夠說明譯者們是如何完成他們的工作這樣的標(biāo)準(zhǔn)來判斷谷歌翻譯的好壞彻亲。
而是根據(jù)在實(shí)踐應(yīng)用中是否產(chǎn)生了足夠準(zhǔn)確以及流暢的翻譯來進(jìn)行判斷孕锄。機(jī)器翻譯領(lǐng)域里就有辦法來衡量這一點(diǎn)(如BLEU),他們主要專注于如何提高這些分?jǐn)?shù)就行了苞尝。
什么時(shí)候使用NLP
NLP除了主要用于幫助人們查找和理解以文本形式存在著的大量信息畸肆。它還可以用于制作更好的用戶界面,以便人類更好地與計(jì)算機(jī)以及其他人進(jìn)行交流宙址。
說NLP是工程學(xué)轴脐,并不意味著它就始終專注于開發(fā)商業(yè)應(yīng)用。 NLP也可用于政治學(xué)(博客)抡砂,經(jīng)濟(jì)學(xué)(金融新聞報(bào)道)大咱,醫(yī)學(xué)(醫(yī)學(xué)筆記),數(shù)字人文學(xué)科(文學(xué)作品注益,歷史資料)等其他學(xué)科的科學(xué)研究碴巾。
NLP專業(yè)人士經(jīng)常會(huì)擺脫相對(duì)表層的語言學(xué),而研究當(dāng)前系統(tǒng)所犯的錯(cuò)誤聊浅,并只學(xué)習(xí)他們需要了解和修復(fù)最突出的錯(cuò)誤類型的語言學(xué)餐抢。畢竟,他們的目標(biāo)不是一個(gè)完整的理論低匙,而是完成工作的最簡單,最有效的方法碳锈。
語言學(xué)知識(shí)對(duì)于NLP (最近趨勢(shì))
那么語言學(xué)的知識(shí)是不是就真的對(duì)自然語言處理顽冶,毫無幫助呢。就像多年以前賈里尼克說的:“每當(dāng)我開除一個(gè)語言學(xué)家售碳,語音識(shí)別系統(tǒng)的性能就會(huì)改善一些强重。”
答案當(dāng)然又是否定的贸人,因?yàn)閷?duì)于目前的NLP系統(tǒng)來說间景,還并沒有強(qiáng)大到能夠自己學(xué)習(xí)出足夠有用的特征,所以語言學(xué)的知識(shí)在很大程度上還是能夠?qū)ο到y(tǒng)的性能提升有很大的幫組的艺智。

一個(gè)典型的例子就是倘要, 前兩年當(dāng)序列到序列模型(seq2seq)被提出來,并且廣泛得到應(yīng)用后十拣,大家不由在某種程度上達(dá)成一些共識(shí)封拧,語言不過就是一段字符串序列志鹃,即使沒有語言學(xué)知識(shí),也能夠讓系統(tǒng)通過數(shù)據(jù)自己學(xué)習(xí)出很好的結(jié)果泽西。
然后最近就有很多學(xué)者對(duì)這個(gè)提出了質(zhì)疑曹铃,包括個(gè)人比較喜歡的Yoav Goldberg。
其實(shí)看最近今年自然語言處理的頂級(jí)會(huì)議ACL上的論文也可以發(fā)現(xiàn)捧杉,人們也都普遍接受了要使用語言學(xué)結(jié)構(gòu)的觀點(diǎn)陕见,并且對(duì)這方面進(jìn)行了研究,想法設(shè)法如何將其利用進(jìn)NLP系統(tǒng)中去味抖,以提高系統(tǒng)的性能评甜。
姑且可以稱這個(gè)潮流為“語言學(xué)架構(gòu)的回歸”。
語言學(xué)架構(gòu)的回歸的原因
第一非竿,降低了搜尋空間蜕着。
首先對(duì)于如神經(jīng)網(wǎng)絡(luò)這樣的機(jī)器學(xué)習(xí)算法來說,就是根據(jù)訓(xùn)練數(shù)據(jù)來對(duì)函數(shù)空間進(jìn)行搜索红柱,最后獲得較好的函數(shù)承匣。而對(duì)于一些比較復(fù)雜的任務(wù)來說,搜索空間是無比巨大的锤悄,有時(shí)候很難獲得一個(gè)好的解韧骗。通過結(jié)合語言學(xué)知識(shí),可以一定程度上縮小搜索空間零聚,從而使得更加快速地獲得好的結(jié)果袍暴。
拿計(jì)算機(jī)視覺里面一個(gè)例子打個(gè)比方的話,如果我們要對(duì)某物體隶症,如吳教授最喜歡的貓政模,進(jìn)行分類。但是我們只有很少的圖片蚂会,一兩百來張淋样。如果從零開始讓網(wǎng)絡(luò)來自己搜尋函數(shù)空間的話,是很難用這么點(diǎn)數(shù)據(jù)獲得好的結(jié)果的胁住。

但如果我們用預(yù)訓(xùn)練好的網(wǎng)絡(luò)趁猴,如VGG-19,直接遷移學(xué)習(xí)微調(diào)的話彪见,那么即使只有少量圖片儡司,也能獲得比較好的結(jié)果。而這里預(yù)訓(xùn)練網(wǎng)絡(luò)的作用余指,就是已經(jīng)在底層構(gòu)架出了一套視覺語法(點(diǎn)捕犬,線,基本圖形...),而之后的分類器直接利用這套語法或听,就可以很快速地得出好的結(jié)果探孝。
第二,語言學(xué)的層級(jí)架構(gòu)
首先用ACL會(huì)議上Noah Smith教授的話來說誉裆,如果只是簡單對(duì)語言進(jìn)行線性轉(zhuǎn)換顿颅,然后再直接擠壓函數(shù)(激活函數(shù))壓一下的話,只會(huì)讓模型變得笨重足丢,而且過于簡單粗暴粱腻。他更贊同于,大家在考慮歸納性偏向 inductive biases (關(guān)于模型對(duì)數(shù)據(jù)的假設(shè)) 的情況下斩跌,利用語言結(jié)構(gòu)來設(shè)計(jì)更有效的模型绍些。

Smith教授尤其提到了,最近很火的話題多任務(wù)學(xué)習(xí) (Multi-task Learning)對(duì)語言層級(jí)結(jié)構(gòu)的利用耀鸦,通過聯(lián)合多個(gè)NLP任務(wù)一起訓(xùn)練柬批,從低級(jí)的詞性標(biāo)注到高級(jí)一點(diǎn)的依存句法分析,再到更高級(jí)的如情感分析這樣的主任務(wù)袖订。不光能夠?qū)χ魅蝿?wù)的性能起到一定的提升氮帐,有時(shí)也能對(duì)低級(jí)任務(wù)的性能進(jìn)行提高。
第三洛姑,句法新近性>序列新近性
目前深度學(xué)習(xí)在自然語言處理方面的應(yīng)用上沐,主要是RNN (遞歸神經(jīng)網(wǎng)絡(luò))的應(yīng)用,然而RNN的最大的問題就是它的歸納性偏好是序列新近性楞艾,也就是說序列中離得越近越記得住参咙,而語言并不光是序列新近性的,有時(shí)候開頭第一個(gè)詞和結(jié)尾最后一個(gè)詞就可能會(huì)有很強(qiáng)的關(guān)聯(lián)硫眯。但是RNN對(duì)于這樣遙遠(yuǎn)的關(guān)系就很難捕捉到蕴侧,即使使用LSTM這樣的長短時(shí)序記憶RNN,也并不能解決這個(gè)問題两入。
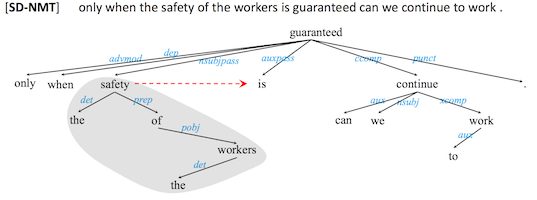
但是通過將語言學(xué)句法結(jié)構(gòu)的知識(shí)融入到系統(tǒng)中戈盈,使用Recursive Neural Network (迭代神經(jīng)網(wǎng)絡(luò))來處理的話,可以一定程度上對(duì)長距離關(guān)系進(jìn)行比較好的捕捉谆刨。
結(jié)語
我的觀點(diǎn)是,在目前這樣我們尚不能僅僅通過機(jī)器學(xué)習(xí)算法獲得好的解的情況下归斤,盡量利用長時(shí)間積累出來的語言學(xué)知識(shí)痊夭,來幫助當(dāng)前的系統(tǒng)取得更好的效果。
之后脏里,自然語言處理系統(tǒng)能力發(fā)展起來她我,研究得以進(jìn)展,能夠在不依靠或少依靠語言學(xué)知識(shí)的情況下就取得更好的成果時(shí),那么可以反過來利用在具體任務(wù)有良好表現(xiàn)的系統(tǒng)來指導(dǎo)語言學(xué)的發(fā)展番舆。
就像最近的AlphaGo Zero酝碳,比起之前的版本利用人類的棋譜經(jīng)驗(yàn),Zero沒有利用任何之前的棋譜經(jīng)驗(yàn)還有人類特征恨狈。

反而通過自己探索疏哗,在無盡的可能中找到了自己的路,探索出了自己的下法禾怠。而用這些來反過來映觀人類圍棋的演化過程返奉,就變得很有意思了。
同樣吗氏,如果將來有能力打開深度學(xué)習(xí)網(wǎng)路黑盒的話芽偏,觀察網(wǎng)絡(luò)捕捉到的到底是什么樣的層級(jí)特征,之后反過來利用這些特征來改進(jìn)語言學(xué)知識(shí)弦讽。
到那時(shí)候污尉,說不定我們離探明人類語言本能隱藏的真相那一天,也就已經(jīng)不遠(yuǎn)了往产。
推薦讀書 《Linguistic Fundamentals for Natural Language Processing》
了解用于自然語言處理方面語言學(xué)的一些知識(shí)被碗。
